性能指標
老規矩,我們先來回顧一下,描述 I/O 的性能指標有哪些?你可以先回想一下檔案系統和磁盤 I/O 的原理,結合下面這張 Linux 系統的 I/O 堆疊圖,憑著記憶和理解自己寫一寫,或者,你也可以打開前面的文章,挨個復習總結一下,
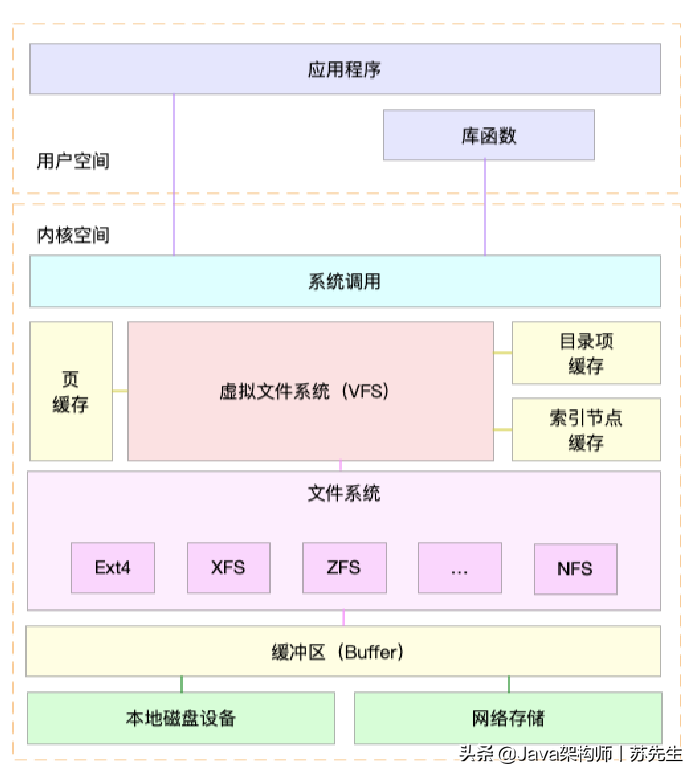
說了這么久的 I/O 性能知識,一說起 I/O 指標,你應該首先會想到分類描述,我們要區分開檔案系統和磁盤,分別用不同指標來描述它們的性能,
檔案系統I/O性能指標
我們先來看檔案系統的情況,
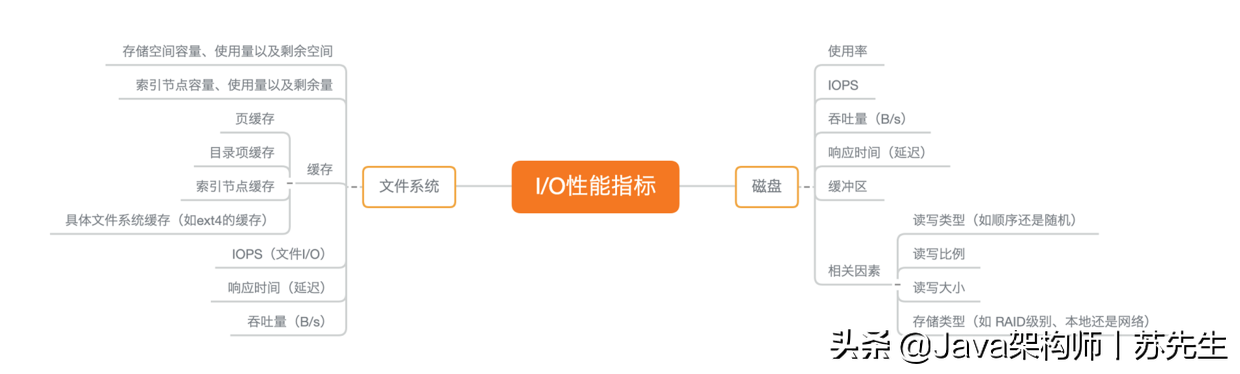
首先,最容易想到的是存盤空間的使用情況,包括容量、使用量以及剩余空間等,我們通常也稱這些為磁盤空間的使用量,因為檔案系統的資料最侄訓是存盤在磁盤上,
不過要注意,這些只是檔案系統向外展示的空間使用,而非在磁盤空間的真實用量,因為檔案系統的元資料也會占用磁盤空間,
而且,如果你配置了 RAID,從檔案系統看到的使用量跟實際磁盤的占用空間,也會因為RAID 級別的不同而不一樣,比方說,配置 RAID10 后,你從檔案系統最多也只能看到所有磁盤容量的一半,
除了資料本身的存盤空間,還有一個容易忽略的是索引節點的使用情況,它也包括容量、使用量以及剩余量等三個指標,如果檔案系統中存盤過多的小檔案,就可能碰到索引節點容量已滿的問題,
其次,你應該想到的是前面多次提到過的快取使用情況,包括頁快取、目錄項快取、索引節點快取以及各個具體檔案系統(如 ext4、XFS 等)的快取,這些快取會使用速度更快的記憶體,用來臨時存盤檔案資料或者檔案系統的元資料,從而可以減少訪問慢速磁盤的次數,
除了以上這兩點,檔案 I/O 也是很重要的性能指標,包括 IOPS(包括 r/s 和 w/s)、回應時間(延遲)以及吞吐量(B/s)等,在考察這類指標時,通常還要考慮實際檔案的讀寫情況,比如,結合檔案大小、檔案數量、I/O 型別等,綜合分析檔案 I/O 的性能,
誠然,這些性能指標非常重要,但不幸的是,Linux 檔案系統并沒提供,直接查看這些指標的方法,我們只能通過系統呼叫、動態跟蹤或者基準測驗等方法,間接進行觀察、評估,不過,實際上,這些指標在我們考察磁盤性能時更容易見到,因為 Linux 為磁盤性能提供了更詳細的資料,
磁盤I/O性能指標
接下來,我們就來具體看看,哪些性能指標可以衡量磁盤 I/O 的性能,
在磁盤 I/O 原理的文章中,我曾提到過四個核心的磁盤 I/O 指標,
- 使用率,是指磁盤忙處理 I/O 請求的百分比,過高的使用率(比如超過 60%)通常意味著磁盤 I/O 存在性能瓶頸,
- IOPS(Input/Output Per Second),是指每秒的 I/O 請求數,
- 吞吐量,是指每秒的 I/O 請求大小,
- 回應時間,是指從發出 I/O 請求到收到回應的間隔時間,
考察這些指標時,一定要注意綜合 I/O 的具體場景來分析,比如讀寫型別(順序還是隨機)、讀寫比例、讀寫大小、存盤型別(有無 RAID 以及 RAID 級別、本地存盤還是網路存盤)等,
不過,這里有個大忌,就是把不同場景的 I/O 性能指標,直接進行分析對比,這是很常見的一個誤區,你一定要避免,
除了這些指標外,在前面 Cache 和 Buffer 原理的文章中,我曾多次提到,緩沖區(Buffer)也是要重點掌握的指標,它經常出現在記憶體和磁盤問題的分析中,
檔案系統和磁盤 I/O 的這些指標都很有用,需要我們熟練掌握,所以我總結成了一張圖,幫你分類和記憶,你可以保存并列印出來,方便隨時查看復習,也可以把它當成 I/O 性能分析的“指標篩選”清單使用,
性能工具
掌握檔案系統和磁盤 I/O 的性能指標后,我們還要知道,怎樣去獲取這些指標,也就是搞明白工具的使用問題,
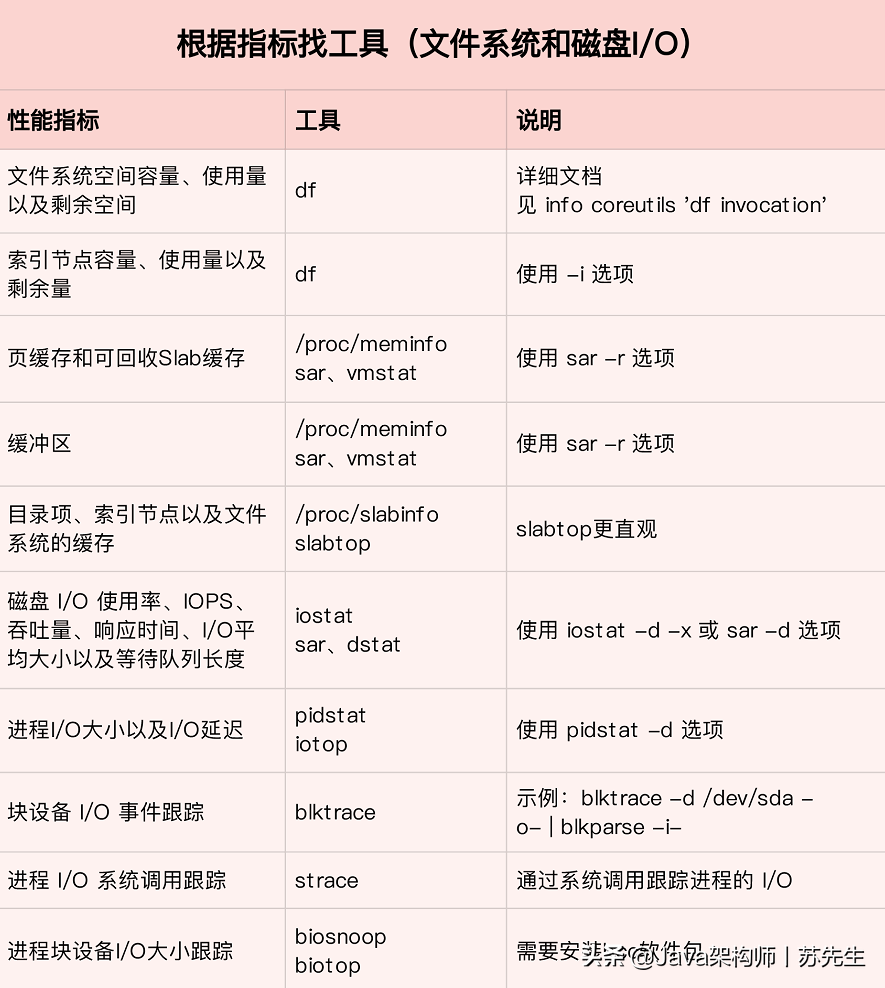
第一,在檔案系統的原理中,我介紹了查看檔案系統容量的工具 df,它既可以查看檔案系統資料的空間容量,也可以查看索引節點的容量,至于檔案系統快取,我們通過/proc/meminfo、/proc/slabinfo 以及 slabtop 等各種來源,觀察頁快取、目錄項快取、索引節點快取以及具體檔案系統的快取情況,
第二,在磁盤 I/O 的原理中,我們分別用 iostat 和 pidstat 觀察了磁盤和行程的 I/O 情況,它們都是最常用的 I/O 性能分析工具,通過 iostat ,我們可以得到磁盤的 I/O 使用率、吞吐量、回應時間以及 IOPS 等性能指標;而通過 pidstat ,則可以觀察到行程的 I/O吞吐量以及塊設備 I/O 的延遲等,
第三,在狂打日志的案例中,我們先用 top 查看系統的 CPU 使用情況,發現 iowait 比較高;然后,又用 iostat 發現了磁盤的 I/O 使用率瓶頸,并用 pidstat 找出了大量 I/O 的行程;最后,通過 strace 和 lsof,我們找出了問題行程正在讀寫的檔案,并最終鎖定性能問題的來源——原來是行程在狂打日志,
第四,在磁盤 I/O 延遲的單詞熱度案例中,我們同樣先用 top、iostat ,發現磁盤有 I/O瓶頸,并用 pidstat 找出了大量 I/O 的行程,可接下來,想要照搬上次操作的我們失敗了,在隨后的 strace 命令中,我們居然沒看到 write 系統呼叫,于是,我們換了一個思路,用新工具 filetop 和 opensnoop ,從內核中跟蹤系統呼叫,最終找出瓶頸的來源,
最后,在 MySQL 和 Redis 的案例中,同樣的思路,我們先用 top、iostat 以及 pidstat ,確定并找出 I/O 性能問題的瓶頸來源,它們正是 mysqld 和 redis-server,隨后,我們又用 strace+lsof 找出了它們正在讀寫的檔案,
關于 MySQL 案例,根據 mysqld 正在讀寫的檔案路徑,再結合 MySQL 資料庫引擎的原理,我們不僅找出了資料庫和資料表的名稱,還進一步發現了慢查詢的問題,最終通過優化索引解決了性能瓶頸,
至于 Redis 案例,根據 redis-server 讀寫的檔案,以及正在進行網路通信的 TCPSocket,再結合 Redis 的作業原理,我們發現 Redis 持久化選項配置有問題;從 TCPSocket 通信的資料中,我們還發現了客戶端的不合理行為,于是,我們修改 Redis 配置選項,并優化了客戶端使用 Redis 的方式,從而減少網路通信次數,解決性能問題,
性能指標和工具的聯系
同前面 CPU 和記憶體板塊的學習一樣,我建議從指標和工具兩個不同維度出發,整理記憶,
從 I/O 指標出發,你更容易把性能工具同系統作業原理關聯起來,對性能問題有宏觀的認識和把握,而從性能工具出發,可以讓你更快上手使用工具,迅速找出我們想觀察的性能指標,特別是在工具有限的情況下,我們更要充分利用好手頭的每一個工具,少量工具也要盡力挖掘出大量資訊,
第一個維度,從檔案系統和磁盤 I/O 的性能指標出發,換句話說,當你想查看某個性能指標時,要清楚知道,哪些工具可以做到,
根據不同的性能指標,對提供指標的性能工具進行分類和理解,這樣,在實際排查性能問題時,你就可以清楚知道,什么工具可以提供你想要的指標,而不是毫無根據地挨個嘗試,撞運氣,
雖然你不需要把所有相關的工具背下來,但如果能記清楚每個指標對應的工具特性,實際操作起來,一定能更高效、靈活,
這里,我把提供 I/O 性能指標的工具做成了一個表格,方便你梳理關系和理解記憶,你可以把它保存并列印出來,隨時記憶,當然,你也可以把它當成一個“指標工具”指南來使用,
下面,我們再來看第二個維度,
第二個維度,從工具出發,也就是當你已經安裝了某個工具后,要知道這個工具能提供哪些指標,
這在實際環境中,特別是生產環境中也是非常重要的,因為很多情況下,你并沒有權限安裝新的工具包,只能最大化地利用好系統已有的工具,而這就需要你對它們有足夠的了解,
具體到每個工具的使用方法,一般都支持豐富的配置選項,不過不用擔心,這些配置選項并不用背下來,你只要知道有哪些工具,以及這些工具的基本功能是什么就夠了,真正要用到的時候, 通過 man 命令,查它們的使用手冊就可以了,
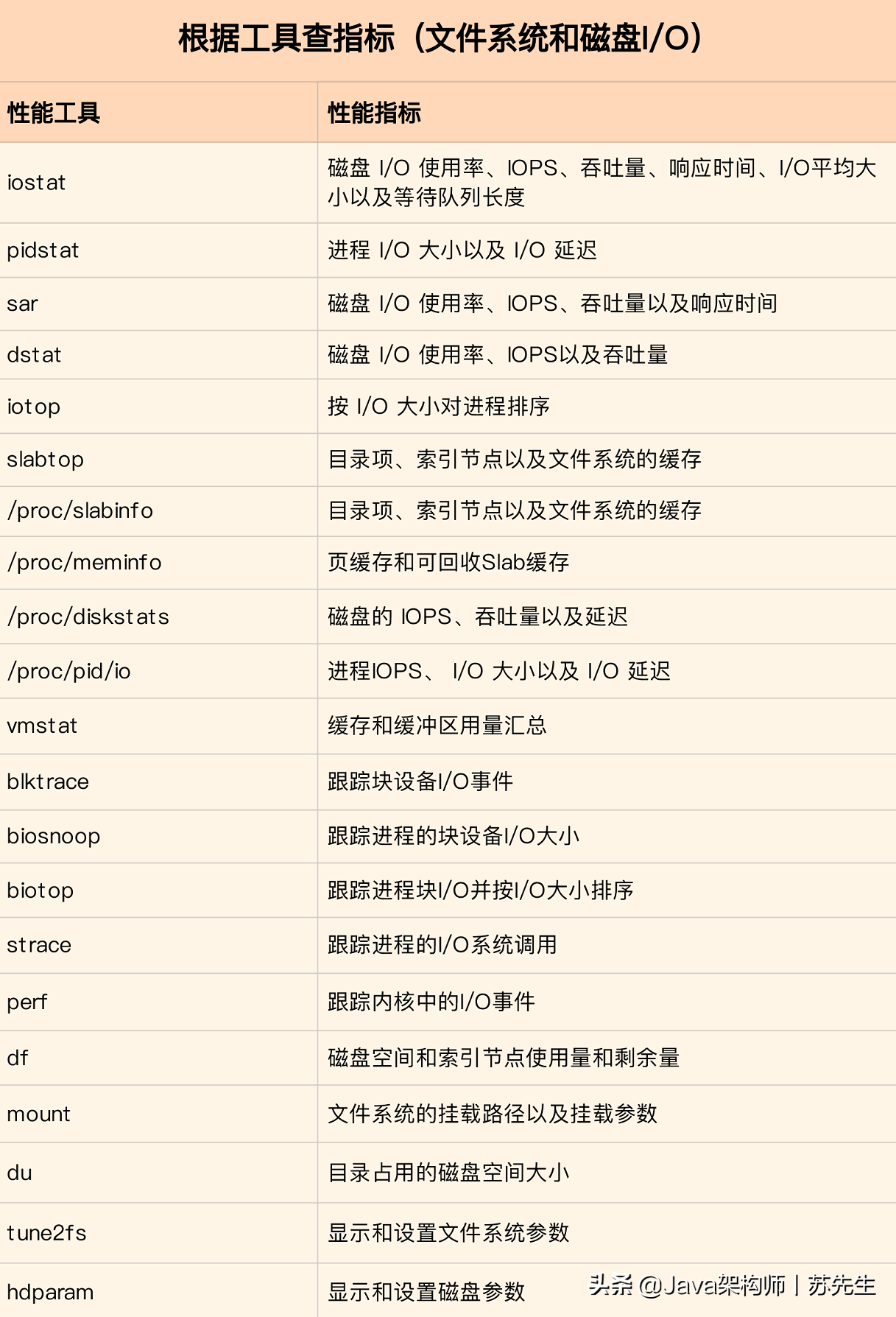
同樣的,我也將這些常用工具匯總成了一個表格,方便你區分和理解,自然,你也可以當成一個“工具指標”指南使用,需要時查表即可,
如何迅速分析I/O的性能瓶頸
到這里,相信你對記憶體的性能指標已經非常熟悉,也清楚每種性能指標分別能用什么工具來獲取,
你應該發現了,比起前兩個板塊,雖然檔案系統和磁盤的 I/O 性能指標仍比較多,但核心的性能工具,其實就是那么幾個,熟練掌握它們,再根據實際系統的現象,并配合系統和應用程式的原理, I/O 性能分析就很清晰了,
不過,不管怎么說,如果每次一碰到 I/O 的性能問題,就把上面提到的所有工具跑一遍,肯定是不現實的,
在實際生產環境中,我們希望的是,盡可能快地定位系統的瓶頸,然后盡可能快地優化性能,也就是要又快又準地解決性能問題,
那有沒有什么方法,可以又快又準地找出系統的 I/O 瓶頸呢?答案是肯定的,
還是那句話,找關聯,多種性能指標間都有一定的關聯性,不要完全孤立的看待他們,想弄清楚性能指標的關聯性,就要通曉每種性能指標的作業原理,這也是為什么我在介紹每個性能指標時,都要穿插講解相關的系統原理,再次希望你能記住這一點,
以我們前面幾期的案例為例,如果你仔細對比前面的幾個案例,從 I/O 延遲的案例到MySQL 和 Redis 的案例,就會發現,雖然這些問題千差萬別,但從 I/O 角度來分析,最開始的分析思路基本上類似,都是:
- 先用 iostat 發現磁盤 I/O 性能瓶頸;
- 再借助 pidstat ,定位出導致瓶頸的行程;
- 隨后分析行程的 I/O 行為;
- 最后,結合應用程式的原理,分析這些 I/O 的來源,
所以,為了縮小排查范圍,我通常會先運行那幾個支持指標較多的工具,如 iostat、vmstat、pidstat 等,然后再根據觀察到的現象,結合系統和應用程式的原理,尋找下一步的分析方向,我把這個程序畫成了一張圖,你可以保存下來參考使用,
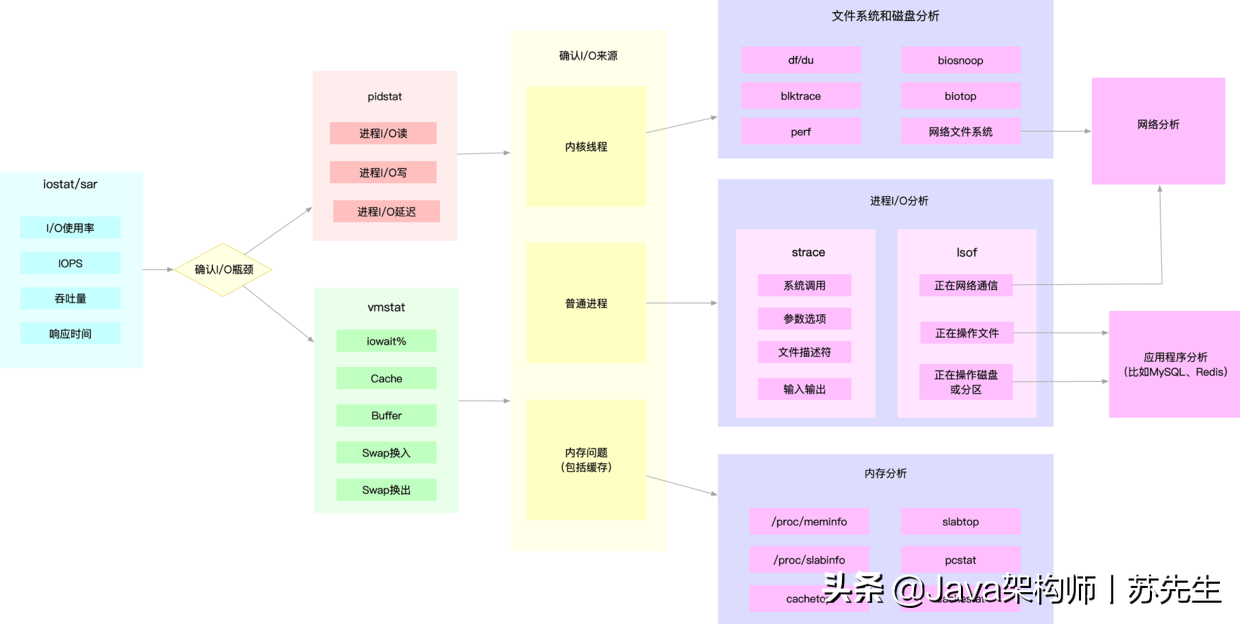
圖中列出了最常用的幾個檔案系統和磁盤 I/O 性能分析工具,以及相應的分析流程,箭頭則表示分析方向,這其中,iostat、vmstat、pidstat 是最核心的幾個性能工具,它們也提供了最重要的 I/O 性能指標,舉幾個例子你可能更容易理解,
例如,在前面講過的 MySQL 和 Redis 案例中,我們就是通過 iostat 確認磁盤出現 I/O 性能瓶頸,然后用 pidstat 找出 I/O 最大的行程,接著借助 strace 找出該行程正在讀寫的檔案,最后結合應用程式的原理,找出大量 I/O 的原因,
再如,當你用 iostat 發現磁盤有 I/O 性能瓶頸后,再用 pidstat 和 vmstat 檢查,可能會發現 I/O 來自內核執行緒,如 Swap 使用大量升高,這種情況下,你就得進行記憶體分析了,先找出占用大量記憶體的行程,再設法減少記憶體的使用,
另外注意,我在這個圖中只列出了最核心的幾個性能工具,并沒有列出前面表格中的所有工具,這么做,一方面是不想用大量的工具串列嚇到你,在學習之初就接觸所有核心或小眾的工具,不見得是好事,另一方面,也是希望你能先把重心放在核心工具上,畢竟熟練掌握它們,就可以解決大多數問題,
所以,你可以保存下這張圖,作為檔案系統和磁盤 I/O 性能分析的思路圖譜,從最核心的這幾個工具開始,通過我提供的那些案例,自己在真實環境里實踐,拿下它們,
總結
本文,我們一起復習了常見的檔案系統和磁盤 I/O 性能指標,梳理了常見的 I/O 性能觀測工具,并建立了性能指標和工具的關聯,最后,我們還總結了快速分析 I/O 性能問題的思路,
還是那句話,雖然 I/O 的性能指標很多,相應的性能分析工具也有不少,但熟悉了各指標含義后,你就會自然找到它們的關聯,順著這個思路往下走,掌握常用的分析套路也并不難,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231123.html
標籤:其他