今天cv調包俠嘗試了使用TensorRT 做YOLO的加速,先概述我這邊實作的速度和精度對比:
精度上對比:
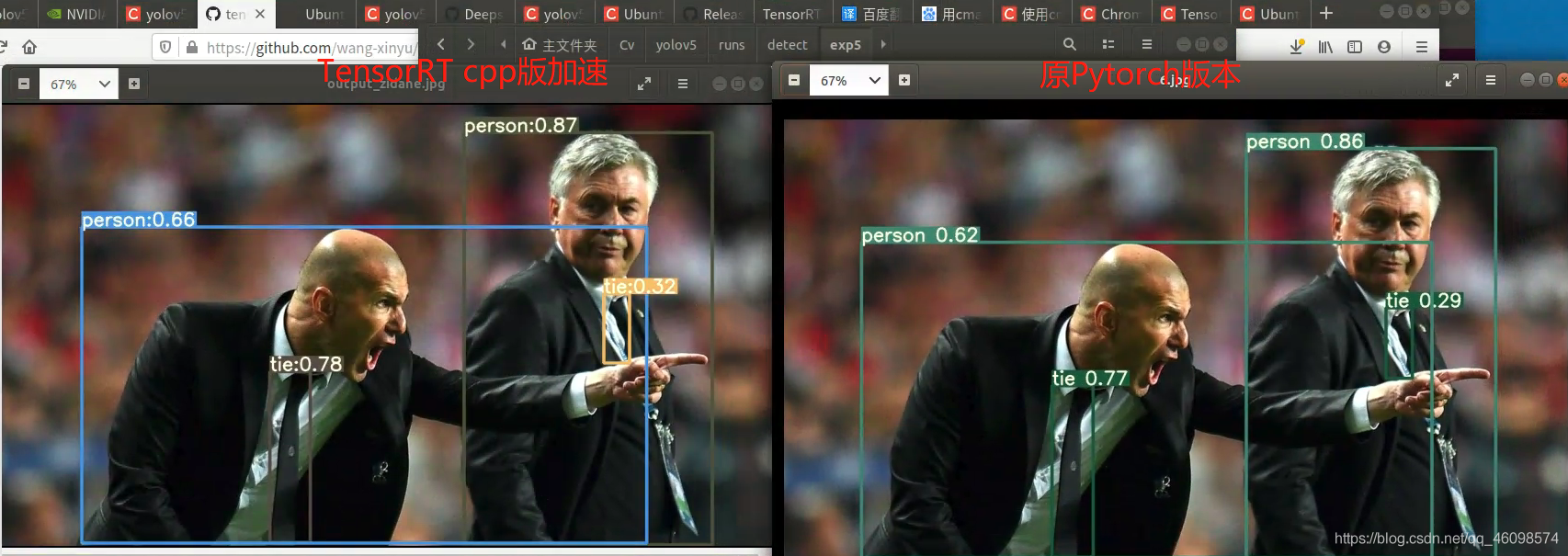
可以看到,精度上使用TensorRT 精度不掉,反而略微上升了一些些(具體情況未知,還在摸索)

TensorRT 速度上的對比:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-brzkenlt-1607327705984)(D:\CSDN\pic\TensorRT\1607274607525.png)]](https://img.uj5u.com/2020/12/08/202340081206523.png)
另外值得注意的是,我使用的TensorRT的作者介紹說:YOLOV5 s小模型原本已經很快了,使用python版的tensorRT加速反而慢了一些,使用cpp版快了3倍,如果是使用YOLOV5 X的大模型,加速效果會更明顯,
下面開始手把手教學,先大致說說思路:
1:配置cuda cudnn 和TensorRT ,先配置適合你的電腦的cuda cudnn,以及到Nvidia官網下載適合你cuda 和cudnn呃tensorRT版本,
2:再分別下載tensorRT 原始碼;YOlov5原始碼,以及YOLOv5模型
3:編譯tensorRT-v5生成engine
4:測驗模型
官方的介紹是 Ubuntu16.04 / cuda10.0 / cudnn7.6.5 / tensorrt7.0.0 / opencv3.3 的配置:
1. Install CUDA 安裝cuda,cudnn
Go to cuda-10.0-download. Choose Linux -> x86_64 -> Ubuntu -> 16.04 -> deb(local) and download the .deb package.
Then follow the installation instructions.
sudo dpkg -i cuda-repo-ubuntu1604-10-0-local-10.0.130-410.48_1.0-1_amd64.deb
sudo apt-key add /var/cuda-repo-<version>/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda
2. Install TensorRT 安裝tensorRT
Go to nvidia-tensorrt-7x-download. You might need login.
Choose TensorRT 7.0 and TensorRT 7.0.0.11 for Ubuntu 1604 and CUDA 10.0 DEB local repo packages
Install with following commands, after apt install tensorrt, it will automatically install cudnn, nvinfer, nvinfer-plugin, etc.
sudo dpkg -i nv-tensorrt-repo-ubuntu1604-cuda10.0-trt7.0.0.11-ga-20191216_1-1_amd64.deb
sudo apt update
sudo apt install tensorrt
3. Install OpenCV 安裝opencv
sudo add-apt-repository ppa:timsc/opencv-3.3
sudo apt-get update
sudo apt install libopencv-dev
4. Check your installation
dpkg -l | grep cuda
dpkg -l | grep nvinfer
dpkg -l | grep opencv
5. Run tensorrtx
It is recommanded to go through the getting started guide, lenet5 as a demo. first.
But if you are proficient in tensorrt, please check the readme of the model you want directly.
我的配置是cuda 10.1 cudnn 7 ,用同樣的方式配置好自己的版本,下載了tensorRT 6.0.1 的deb包,并且安裝了,
然后將TensorRT/yolov5/CMakeLists.txt 修改一下剛剛安裝的TensorRT的include和lib,如圖:
1. generate yolov5s.wts from pytorch with yolov5s.pt, or download .wts from model zoo
git clone https://github.com/wang-xinyu/tensorrtx.git
git clone https://github.com/ultralytics/yolov5.git
// download its weights 'yolov5s.pt'
// copy tensorrtx/yolov5/gen_wts.py into ultralytics/yolov5
// ensure the file name is yolov5s.pt and yolov5s.wts in gen_wts.py
// go to ultralytics/yolov5
python gen_wts.py
// a file 'yolov5s.wts' will be generated.
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-WXCfeO1d-1607327705987)(D:\CSDN\pic\TensorRT\1607319257772.png)]](https://img.uj5u.com/2020/12/08/202340081206524.png)
接下來可以編譯生成yolov5s.engine了:
2. build tensorrtx/yolov5 and run
// put yolov5s.wts into tensorrtx/yolov5
// go to tensorrtx/yolov5
// ensure the macro NET in yolov5.cpp is s
mkdir build
cd build
cmake ..
make
sudo ./yolov5 -s // serialize model to plan file i.e. 'yolov5s.engine'
sudo ./yolov5 -d ../samples // deserialize plan file and run inference, the images in samples will be processed.
3. check the images generated, as follows. _zidane.jpg and _bus.jpg
4. optional, load and run the tensorrt model in python
// install python-tensorrt, pycuda, etc.
// ensure the yolov5s.engine and libmyplugins.so have been built
python yolov5_trt.py
其中:sudo ./yolov5 -d …/samples命令中…/samples 就是你測驗圖片的檔案夾路徑,我們可以自己修改路徑來推理,然后
就可以推理了,如果有什么報錯的話,可以通過公眾號咨詢我~
另外tensroRT 默認使用的是固定尺寸(默認尺寸),而pytorch 版的使用的是等比例縮放到640X 640 所以如果要做消融對比的實驗,建議同一個size做對比,我文章開頭部分的對比圖片,是將pytorch版的img-size改成了608 來推理,所以速度會快一些,對比下來實際上使用cpp版yolov5s 速度還是快了很多,大家可以嘗試使用yolov5x 來加速嘗試一下,如果你想改tensorRT 為640x640 ,那么可以修改yololayer.h 中的20行左右input_H,input_W = 608為640,但是我沒有實際測驗~
另外對于訓練自己的資料集,使用tensorRT加速,需要修改一下一些地方:
將yolov5.cpp 中的第七行:改成 #define USE_FP16 改成自己的FP32 正常我們的模型訓練出來是FP32的,
我建議還是使用yolov5_trt來做推理,main函式中修改一下類別,等等,
另外,使用Openvino加速
cpu(i5 )下原yolov5s 下640X 640是 380ms每幀,使用Openvino是300ms以下,gpu我沒測驗,應該也是稍微快一些,大家可以根據我另一篇文章測驗一下~
另外,CV調包俠自己做了個目標檢測中必備地一個工具~ 使用我的工具,可以方便快捷地做資料標注!哦不,你什么也不用干,工具來標注~ 可以讓你一分鐘就獲取大量資料,并且獲取xml標注檔案,獲取labels歸一化標簽,直接可以使用yolo訓練,關注公眾號,星標一下,過幾天開源出來~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231538.html
標籤:AI