能力
關于卡夫卡
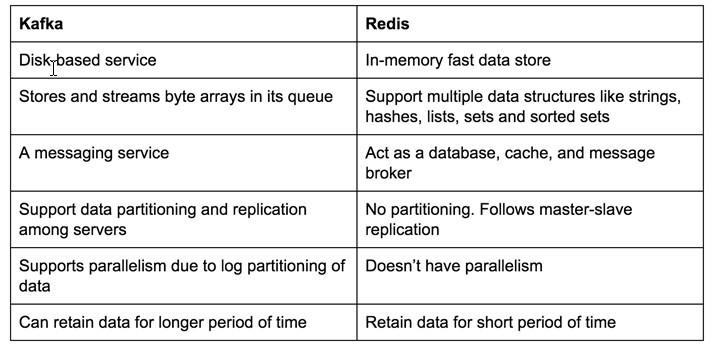
Kafka是一種分布式,磁區和復制的提交日志服務,它提供訊息傳遞功能以及獨特的設計。我們可以在日志聚合程序中使用此功能。
Kafka使用的基本訊息傳遞術語是:
主題:這些是發布訊息的類別。
生產者:這是將訊息發布到Kafka主題中的程序。
使用者:此程序訂閱主題并處理訊息。使用者是使用者組的一部分,該使用者組由許多使用者實體組成,以實作可伸縮性和容錯能力。
代理:Kafka群集中的每個服務器都稱為代理。
從不同來源獲取的日志可以通過幾個生產者流程輸入到各種Kafka主題中,然后由消費者使用。
Kafka提供了多種將資料推送到主題的方法:
從命令列客戶端:Kafka有一個命令列客戶端,用于從特定檔案或標準輸入中獲取輸入,并將它們作為訊息推送到Kafka集群中。
使用Kafka Connect:Kafka提供了一種工具,該工具使用連接器來實作自定義邏輯,以將資料匯入/匯出到集群。
通過撰寫自定義集成代碼:最后一種方法是使用Java生產者API撰寫用于將資料源與Kafka集成的代碼。
在Kafka中,每個主題都有由服務器管理的日志資料磁區:
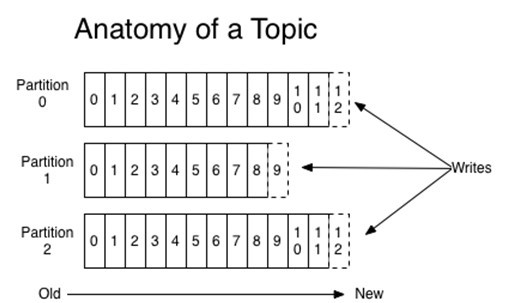
Kafka在一個分布式系統中的多個服務器之間分配磁區日志。 每個磁區都跨多個服務器復制,以實作容錯功能。 由于采用了這種磁區系統,Kafka在處理中提供了并行性。 一個消費者組中的一個以上消費者可以按照存盤訊息的相同順序同時檢索資料。
此外,Kafka允許使用所需數量的服務器。 它使用磁盤進行存盤,因此加載可能會變慢。 但是,由于磁盤存盤容量的原因,它可以存盤大量資料(即以TB為單位),而保留時間更長。
關于Redis
Redis在存盤和各種功能方面與Kafka有點不同。 Redis的核心是一個記憶體中的資料存盤,可用作高性能資料庫,快取和訊息代理。非常適合實時資料處理。
Redis支持的各種資料結構是字串,哈希,串列,集合和排序集合。 Redis還具有以多種語言撰寫的各種客戶端,可用于撰寫用于插入和檢索資料的自定義程式。兩者之間的主要相似之處在于它們都提供訊息傳遞服務。但是出于日志聚合的目的,我們可以使用Redis的各種資料結構來更高效地進行操作。
性能
在測驗Redis和Kafka的性能時,結果非常有趣。
卡夫卡
Kafka流行的訊息佇列系統經過Linkedin等主要公司的大量測驗,實際上,其工程師實際上是在撰寫Kafka的第一版。 在他們的測驗中,LinkedIn在群集模式下將Kafka與六臺計算機一起使用,每臺計算機均具有Intel Xeon 2.5 GHz處理器,六個內核,32 GB RAM和六個7200 RPM SATA驅動器。
生產者
對于第一個測驗,創建了一個具有六個磁區且沒有復制的主題。 使用單個生產者在單個執行緒中生成了5000萬條記錄。 每個訊息大小為100位元組。使用此設定產生的峰值吞吐量超過800K記錄/秒或78 MB /秒。 在不同的測驗中,他們使用相同的基本設定,三個生產者在三臺不同的計算機上運行。 在這種情況下,我們看到該峰值更高,大約為2,000條記錄/秒或193.0 MB /秒。
異步復制與同步復制
第二批測驗涉及復制方法。 使用相同數量的記錄和訊息大小,并且使用與先前測驗相似的單個生成器,就有三個副本。 復制以異步方式進行,其吞吐量峰值約為766K記錄/秒或75 MB /秒。
但是,當復制是同步的時-這意味著主服務器正在等待來自副本的確認-吞吐量峰值很低,約為420K記錄/秒或40 MB /秒。 盡管這是一種可靠的設定,因為它可以確保所有訊息都到達,但由于主服務器確認訊息接收所花費的時間,因此吞吐量會大大降低。
消費者
在這種情況下,他們使用了完全相同的訊息數量和大小以及6個磁區和3個副本。 他們通過增加消費者數量來應用相同的方法。 在第一個使用單個使用者的測驗中,最高吞吐量為940K記錄/秒或89 MB /秒。 但是,不足為奇的是,當使用三個使用者時,吞吐量達到每秒處理2615K條記錄或249.5 MB /秒。
Kafka的吞吐量性能基于生產者數量,使用者數量和復制方法的結合。 為此,其中的測驗之一是單個生產者,單個使用者和異步模式下的三個副本。 該測驗中達到的峰值是處理的795K記錄/秒或75.8 MB /秒。
訊息處理量
如下所示,隨著記錄大小的增加,我們可以預期每秒記錄的減少:
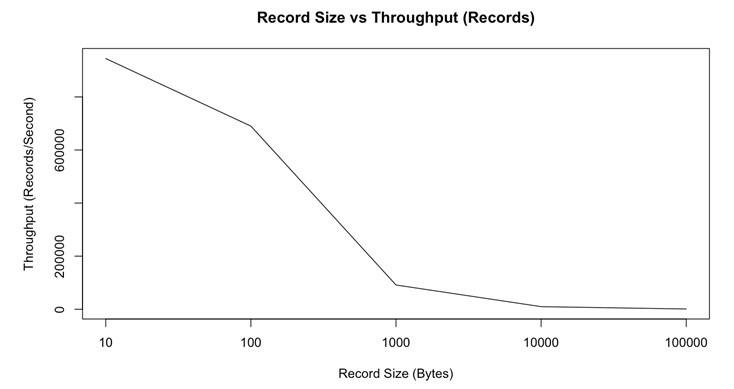
訊息大小與吞吐量(記錄/秒)(源)
但是,正如我們在下圖中所看到的,隨著記錄大小(以位元組為單位)的增長,吞吐量也會隨之增長。 較小的訊息將導致低吞吐量。 這是由于排隊訊息的開銷會影響計算機性能:
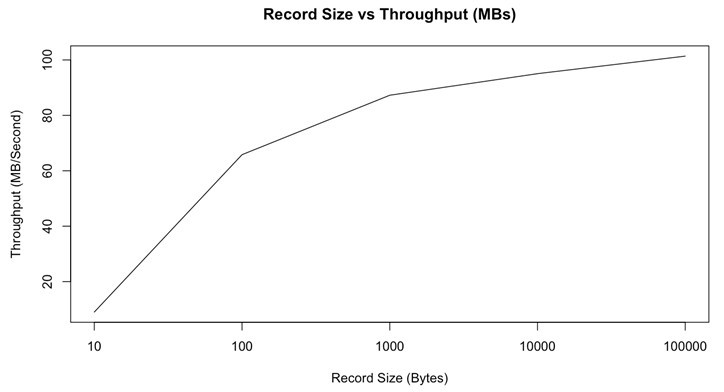
訊息大小與吞吐量(MB /秒)(源)
另外,如下圖所示,已使用的資料量不會影響Kafka的性能。
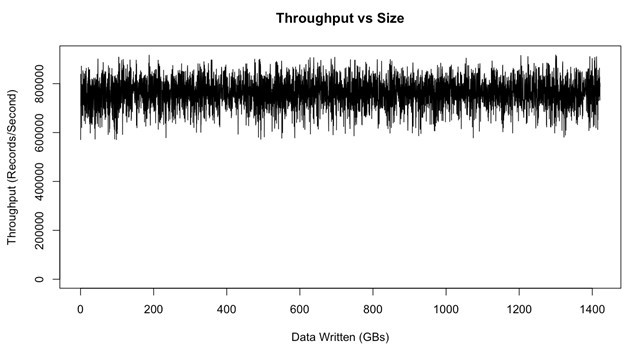
吞吐量與大小(來源)
Kafka嚴重依賴于機器記憶體(RAM)。 如上圖所示,利用記憶體和存盤是維持穩定吞吐量的最佳方法。 其性能取決于資料消耗率。 如果使用者沒有足夠快地使用資料,Kafka將不得不從磁盤而不是記憶體中讀取資料,這會降低其性能。
Redis吞吐量
讓我們檢查一下Redis在訊息處理速率方面的性能。 我們使用了非常基本的Redis命令來幫助我們評估其性能:SET,GET,LPUSH和LPOP。 這些是常用的Redis命令,用于存盤和檢索Redis值和串列。
在此測驗中,我們生成了2M個請求。 密鑰長度設定為0到999999之間,單個值大小為100位元組。 使用Redis基準命令測驗了Redis。
Redis管道
如下所示,在我們的第一個測驗中,我們發現使用Redis流水線時在性能改進方面存在顯著差異。 原因是,通過管道,我們可以將多個請求發送到服務器,而無需等待答復,最后一步即可檢查答復。
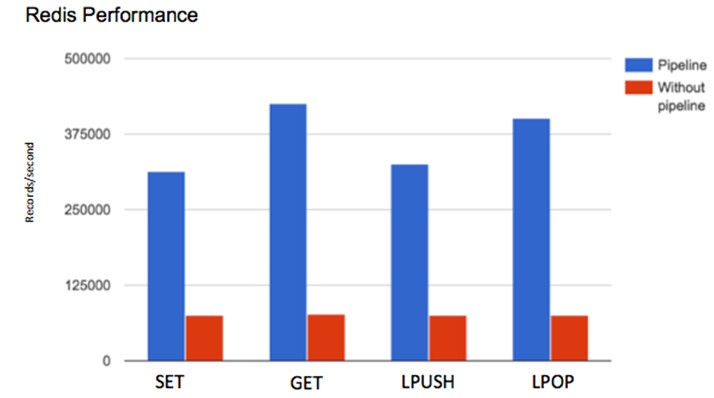
帶或不帶Redis管線(2.6 GHz Intel Core i5,8GB RAM)的吞吐量與命令
Redis上的資料大小可能會有所不同。 如您所見,下圖顯示了具有不同值(訊息)大小的吞吐量。 在圖表中,很容易看出,當訊息大小增加時,吞吐量(以每秒的請求數表示)會降低。 如下所示,此行為與所有四個命令一致。
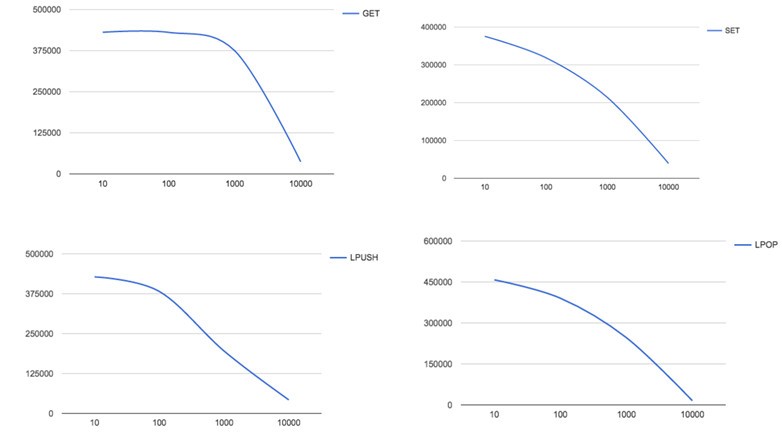
吞吐量與不同訊息大小(位元組)
另外,如下所示,我們以位元組為單位測量了寫入資料。 我們看到,隨著記錄數量的增加,Redis中的寫入位元組數也隨之增加,這在某種程度上是直觀的,與我們在Kafka中注意到的相同。
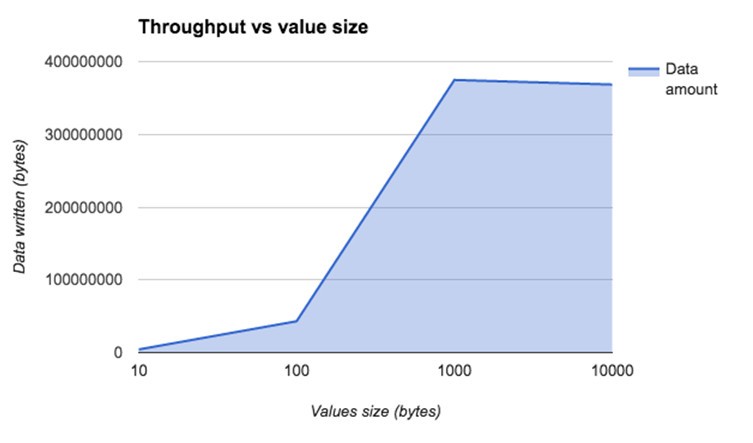
GET命令的吞吐量與值大小
Redis快照支持Redis持久性模式。 它會根據用戶的喜好生成時間點快照,例如,包括從上次快照經過的時間或寫入次數。 但是,例如,如果Redis實體重新啟動或崩潰,則連續快照之間的所有資料都將丟失。 在這種情況下,Redis持久性不支持持久性,并且僅限于那些近期資料不重要的應用程式。
Kafka vs.Redis:摘要
如上所述,Redis是一個記憶體存盤。這意味著它使用其主記憶體進行存盤和處理,這使其比基于磁盤的Kafka快得多。 Redis記憶體中存盤的唯一問題是我們不能長時間存盤大量資料。
由于主記憶體小于磁盤,因此我們必須定期清除資料,方法是自動將資料從記憶體中移動到磁盤并為新資料騰出空間。 Redis是持久性的,它允許我們在必要時將資料集轉儲到磁盤中。 Redis也遵循主從架構,復制僅在主服務器中啟用持久性時才有用。
此外,Redis不像Kafka那樣具有并行性的概念,在并行性中,多個行程可以同時使用資料。
基于這兩種工具的功能,盡管上述針對Kafka與Redis的測驗并不完全相同,但我們仍然可以總結出,在以最小延遲處理實時訊息處理時,您應該首先嘗試Redis。但是,如果訊息很大并且應該重用資料,則應首先考慮使用Kafka。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231665.html
標籤:其他開發語言