一行代碼實作從彩色圖提取素描線稿
- 一、前言:初識PaddleHub
- 預訓練模型(Pre-Trained Models)
- 二、構建Module的大框架
- 1.將模型檔案存放在infer_model下
- 2.創建必要的檔案__init__.py
- 3.創建必要的檔案module.py
- 匯入必要的包
- 填寫module的基本資訊
- 實作預測功能
- 實作命令列呼叫的介面
- 三、測驗及呼叫
- 1.安裝并查看Module基本資訊
- 2.通過API的方式呼叫
- 3.通過命令列的方式呼叫——一行代碼實作從彩色圖提取素描線稿
- 4.效果展示
- 原圖
- 線稿圖
- 四、個人介紹
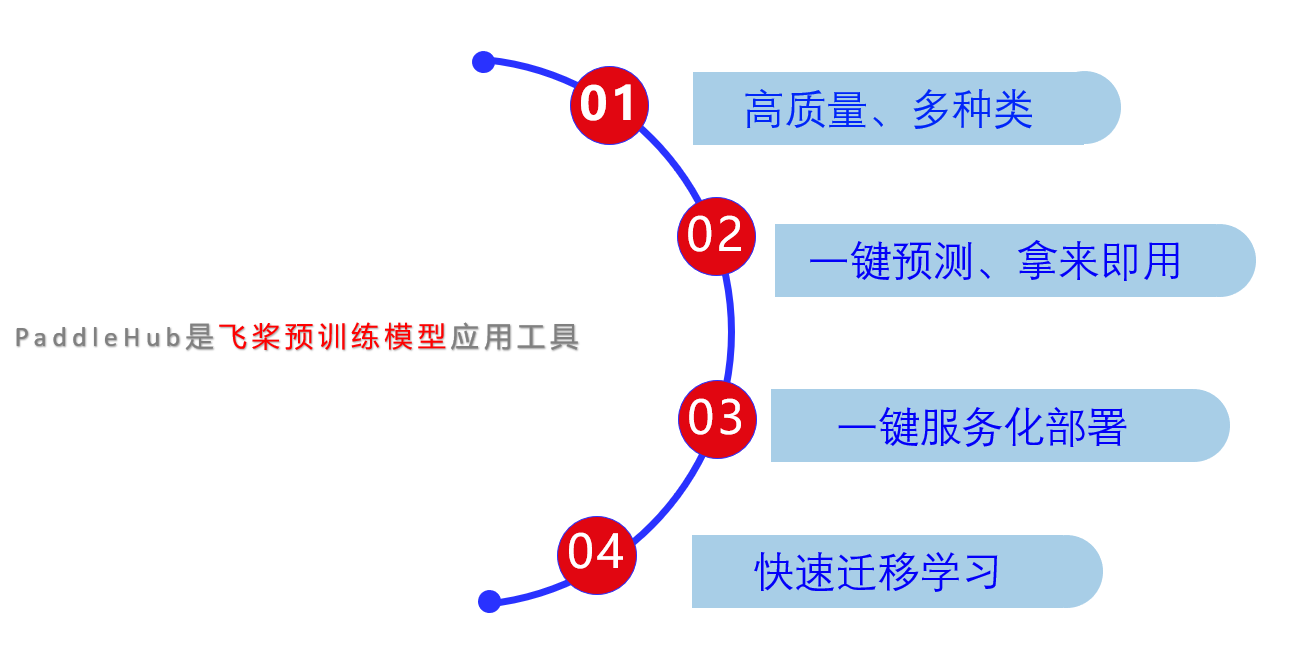
PaddleHub是飛槳預訓練模型應用工具,能拿來即用,一鍵預測,本專案以開發者七年期限的專案——PaddlePaddle之視頻轉線稿篇為基礎,將該模型貢獻到PaddleHub的模型庫里,并用一行代碼實作快速加載,
一、前言:初識PaddleHub
PaddleHub官方Github地址(歡迎star~):
https://github.com/PaddlePaddle/PaddleHub
PaddleHub旨在為開發人員提供豐富,高質量,可直接使用的預訓練模型,開發者無需深度學習背景,便可以快速使用PaddleHub內置的AI模型,其模型涵蓋影像,文本,音頻和視頻的4個主要類別,并支持一鍵式預測,輕松的服務部署和遷移學習,另外,所有模型都是開源的,可以在離線情況下免費下載和使用,
預訓練模型(Pre-Trained Models)
預訓練模型是一個已經訓練好的保存下來的網路,該網路之前已經在一個大型的資料集上進行了訓練(如影像相關類的網路在ImageNet資料上進行了訓練)

二、構建Module的大框架
PaddleHub Module是使用PaddleHub的基礎,其可以通過指定名稱即可方便地完成一鍵加載,如加載預訓練模型ERNIE僅需一行代碼即可完成,hub.Module(name=‘ernie’),省去了復雜的網路結構代碼以及引數加載的繁瑣程序,
將模型貢獻到PaddleHub的模型庫之前,我們必須搭好這一框架,
1.將模型檔案存放在infer_model下
# 創建必要的檔案夾
!mkdir -p Extract_Line_Draft/assets/infer_model
# 將準備好的模型檔案解壓
!unzip work/inference_model.zip
# 將模型檔案復制到Module指定目錄下
!cp -r inference_model/* Extract_Line_Draft/assets/infer_model
2.創建必要的檔案__init__.py
init = open("Extract_Line_Draft/__init__.py", "w")
KaTeX parse error: Expected group after '_' at position 1: _?_init__.py是一個空檔案,直接創建即可,
3.創建必要的檔案module.py
module = open("Extract_Line_Draft/module.py", "w")
匯入必要的包
import argparse
import ast
import os
import math
import six
from pathlib import Path
from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
from paddlehub.module.module import runnable, serving, moduleinfo
from paddlehub.io.parser import txt_parser
import numpy as np
import paddle.fluid as fluid
import paddlehub as hub
from Extract_Line_Draft.function import *
填寫module的基本資訊
@moduleinfo(
name="Extract_Line_Draft",
version="1.0.0",
type="cv/segmentation",
summary=
"Import the color picture and generate the line draft of the picture",
author="彭兆帥,鄭博培",
author_email="1084667371@qq.com,2733821739@qq.com")
實作預測功能
class ExtractLineDraft(hub.Module):
def _initialize(self):
"""
Initialize with the necessary elements
"""
# 加載模型路徑
self.pretrained_model_path = os.path.join(self.directory, "assets","infer_model")
# 模型加載函式
def load_model(self, modelpath, use_gpu, use_mkldnn, combined):
# 加載模型引數
if combined:
model = os.path.join(modelpath, "__model__")
params = os.path.join(modelpath, "__params__")
config = AnalysisConfig(model, params)
else:
config = AnalysisConfig(modelpath)
# 設定引數
if use_gpu:
config.enable_use_gpu(100, 0)
else:
config.disable_gpu()
if use_mkldnn:
config.enable_mkldnn()
config.disable_glog_info()
config.switch_ir_optim(True)
config.enable_memory_optim()
config.switch_use_feed_fetch_ops(False)
config.switch_specify_input_names(True)
# 通過引數加載模型預測器
predictor = create_paddle_predictor(config)
# 回傳預測器
return predictor
# 模型預測函式
def predict(self, input_datas):
outputs = []
# 遍歷輸入資料進行預測
for input_data in input_datas:
inputs = input_data.copy()
self.input_tensor.copy_from_cpu(inputs)
self.predictor.zero_copy_run()
output = self.output_tensor.copy_to_cpu()
outputs.append(output)
# 預測結果合并
outputs = np.concatenate(outputs, 0)
# 回傳預測結果
return outputs
def ExtractLine(self, image_path, use_gpu=False):
"""
Get the input and program of the infer model
Args:
image_path(str): Path to the folder containing the input picture
use_gpu(bool): Weather to use gpu
"""
for home, dirs, files in os.walk(image_path):
for filename in files:
fullname = os.path.join(home, filename)
from_mat = cv2.imread(fullname)
width = float(from_mat.shape[1])
height = float(from_mat.shape[0])
new_width = 0
new_height = 0
if (width > height):
from_mat = cv2.resize(from_mat, (512, int(512 / width * height)), interpolation=cv2.INTER_AREA)
new_width = 512
new_height = int(512 / width * height)
else:
from_mat = cv2.resize(from_mat, (int(512 / height * width), 512), interpolation=cv2.INTER_AREA)
new_width = int(512 / height * width)
new_height = 512
from_mat = from_mat.transpose((2, 0, 1))
light_map = np.zeros(from_mat.shape, dtype=np.float)
for channel in range(3):
light_map[channel] = get_light_map_single(from_mat[channel])
light_map = normalize_pic(light_map)
light_map = resize_img_512_3d(light_map)
light_map = light_map.astype('float32')
# 加載模型預測器
self.predictor = self.load_model(self.pretrained_model_path, use_gpu, use_mkldnn=True, combined=False)
# 獲取模型的輸入輸出
self.input_names = self.predictor.get_input_names()
self.output_names = self.predictor.get_output_names()
self.input_tensor = self.predictor.get_input_tensor(self.input_names[0])
self.output_tensor = self.predictor.get_output_tensor(self.output_names[0])
line_mat = self.predict(np.expand_dims(light_map, axis=0).astype('float32'))
# 去除 batch 維度 (512, 512, 3)
line_mat = line_mat.transpose((3, 1, 2, 0))[0]
# 裁剪 (512, 384, 3)
line_mat = line_mat[0:int(new_height), 0:int(new_width), :]
line_mat = np.amax(line_mat, 2)
# 保存圖片
if Path('./output/').exists():
show_active_img_and_save_denoise(line_mat, './output/' + filename)
else:
os.makedirs('./output/')
show_active_img_and_save_denoise(line_mat, './output/' + filename)
print('圖片' + filename + '已經完成')
print('全部圖片轉換成功,')
實作命令列呼叫的介面
@runnable
def run_cmd(self, argvs):
"""
Run as a command.
"""
self.parser = argparse.ArgumentParser(
description='Run the %s module.' % self.name,
prog='hub run %s' % self.name,
usage='%(prog)s',
add_help=True)
self.arg_input_group = self.parser.add_argument_group(
title="Input options", description="Input data. Required")
self.arg_config_group = self.parser.add_argument_group(
title="Config options",
description=
"Run configuration for controlling module behavior, not required.")
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
try:
input_data = self.check_input_data(args)
except RuntimeError:
self.parser.print_help()
return None
use_gpu = args.use_gpu
self.ExtractLine(image_path=input_data, use_gpu=use_gpu)
def add_module_input_arg(self):
"""
Add the command input options
"""
self.arg_input_group.add_argument(
'--input_path',
type=str,
default=None,
help="file contain input data")
self.arg_input_group.add_argument(
'--use_gpu',
type=str,
default=None,
help="weather to use gpu")
def check_input_data(self, args):
input_data = []
if args.input_path:
if not os.path.exists(args.input_path):
raise RuntimeError("Path %s is not exist." % args.input_path)
path = "{}".format(args.input_path)
# print(path)
return path
三、測驗及呼叫
1.安裝并查看Module基本資訊
# 安裝Module
!hub install Extract_Line_Draft
# 查看該Module的基本資訊
!hub show Extract_Line_Draft

2.通過API的方式呼叫
import paddlehub as hub
Extract_Line_Draft_test = hub.Module(name="Extract_Line_Draft")
test_img_path = "testImage"
# execute predict and print the result
t the result
Extract_Line_Draft_test.ExtractLine(test_img_path, use_gpu=True)
[32m[2020-12-08 02:29:43,474] [ INFO] - Installing Extract_Line_Draft module[0m
[32m[2020-12-08 02:29:43,524] [ INFO] - Module Extract_Line_Draft already installed in /home/aistudio/.paddlehub/modules/Extract_Line_Draft[0m
圖片2.jpg已經完成
圖片1.jpg已經完成
圖片3.jpg已經完成
全部圖片轉換成功,
3.通過命令列的方式呼叫——一行代碼實作從彩色圖提取素描線稿
!hub run Extract_Line_Draft --input_path "testImage" --use_gpu True
圖片2.jpg已經完成
圖片1.jpg已經完成
圖片3.jpg已經完成
全部圖片轉換成功,
4.效果展示
原圖


線稿圖


四、個人介紹
北京聯合大學機器人學院自動化專業2018級本科生 鄭博培
百度飛槳開發者技術專家 PPDE
深圳柴火創客空間 認證會員
百度大腦 智能對話訓練師
來AI Studio互粉吧,等你哦~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231971.html
標籤:AI
上一篇:演算法筆記:判斷機器人在二位平面上行走的路徑是否相交
下一篇:阿菊的OpenCv(一)——imshow()無法彈出視窗,imshow()彈出視窗無法顯示圖片且一直顯示未回應...盤點自己一路的辛酸歷程!