序
在(一)中我介紹了GA、NSGA以及NSGA-II演算法以及他們之間的關系,據完成(一)已經差不多10個月了,當初的愿望實作了嗎,事到如今只好祭奠嗎?任歲月風干了…,心中不由一首老男孩送給自己,面臨畢業,最后一塊還沒有搞完,折騰了小半年,我又回來了,回到了最初的起點😂,從頭開始,未來雖不可期,但我還是得不卑不亢的繼續下去,心靈雞湯要喝,萬一夢想實作了呢,況且無心插柳柳都成蔭了,我還是有心地去種樹呢🙃,
廢話不多說,有關NSGA-II演算法的請參考第一篇文章:多目標非支配排序遺傳演算法-NSGA-II(一),本文主要是繼續上次我們提到的關于決策偏好的演算法原理及實作,然后順便再定個小計劃:把NSGA-III搞一下,
文章目錄
- 序
- 參考資料
- 擁擠度選擇缺陷 or 基于參考點選擇方法提出背景
- 傳統參考點方法
- 新參考點方法
- 代碼實作
- 實作結果
參考資料
首先,參考之前博客樣式,我們先列出參考的文獻、博客及原始碼,
文獻:Reference Point Based Multi-Objective Optimization Using Evolutionary Algorithms
博客:多目標非支配排序遺傳演算法-NSGA-II(一)
原始碼:NGPM Song Lin
擁擠度選擇缺陷 or 基于參考點選擇方法提出背景
NSGA-II演算法采用擁擠度選擇策略,通過非支配等級以及擁擠度距離來實作對于Pareto解集的選擇,這種選擇方式通過二元錦標賽方法確實實作了兩兩解的對比,但是當我們回歸現實時,卻發現決策者的選擇看起來并不像我們之前解釋的那么簡單,僅給予Pareto前沿并不是決策者所想要的,貌似仍然有一種“給你飯你吃”的趕腳,怎么辦?最簡單的方式是讓決策者參與到決策中,這種參與不僅僅是選擇方案,而且還應給予一定的需求建議,換句話說,制定者在設定問題,構建模型的時候,決策者會給予一些基于偏好或者經驗性的指導意見,這些指導意見進而轉化為一些目標點,我們這里稱之為 “參考點”,通過這些參考點,然后再進行建模、求解、決策(邪性制圖如下),
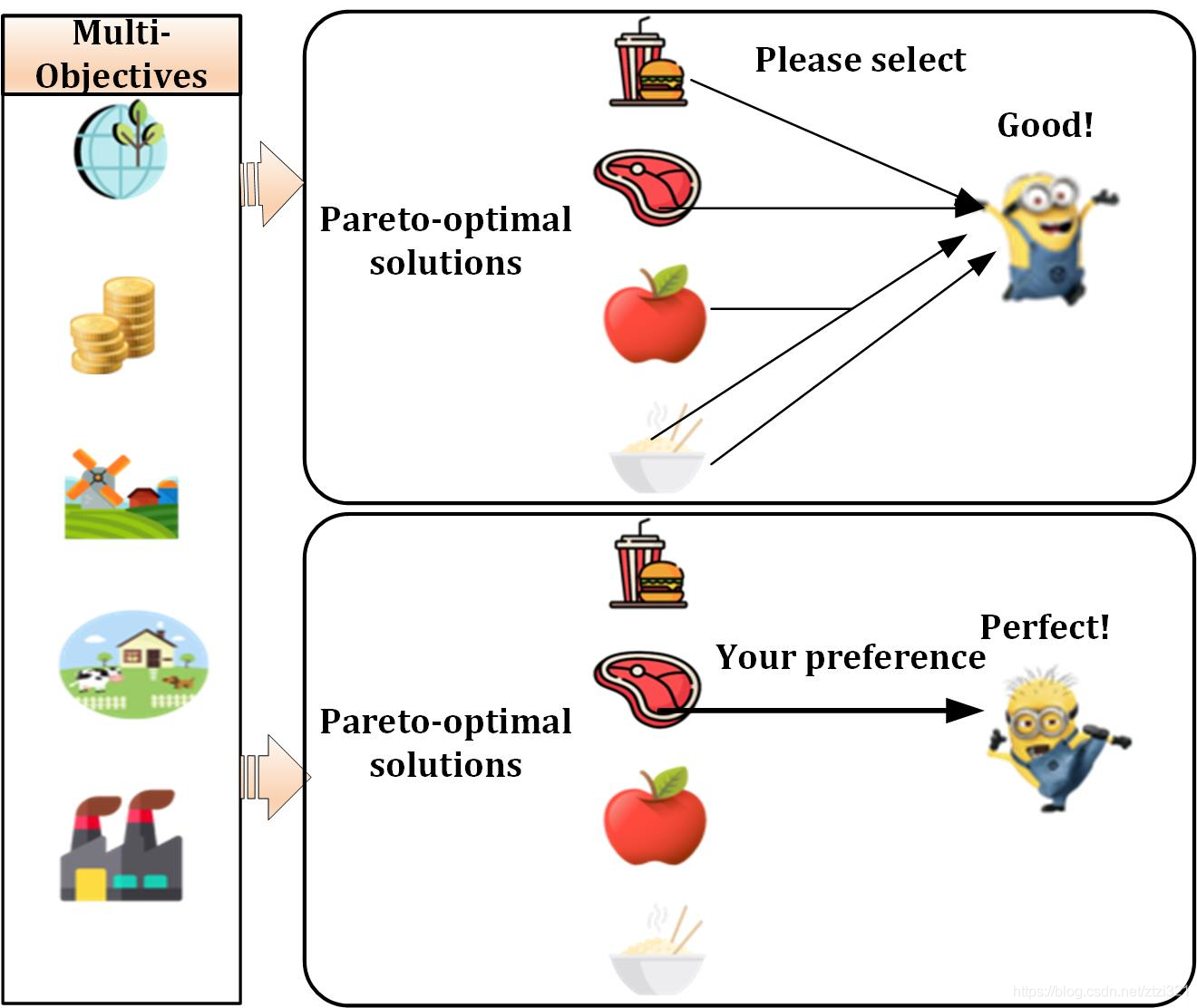 可能有同學會說有互動式多目標Pareto解集也會給予基于偏好的解,但那種傳統的偏好方法往往將多目標轉換為單目標并給予一個偏好解,這種單偏好解的方法往往并不可靠,而本文所介紹的方法則是給予一組基于偏好的解集,從而提高決策的可靠性,接下來,我們詳細了解下傳統和新的參考方法的原理及區別,
可能有同學會說有互動式多目標Pareto解集也會給予基于偏好的解,但那種傳統的偏好方法往往將多目標轉換為單目標并給予一個偏好解,這種單偏好解的方法往往并不可靠,而本文所介紹的方法則是給予一組基于偏好的解集,從而提高決策的可靠性,接下來,我們詳細了解下傳統和新的參考方法的原理及區別,
傳統參考點方法
相關學者對基于參考點的進化多目標演算法(EMO)進行了較多探究,并形成了所謂的傳統參考點方法,Wierzbicki 對參考點的定義如下:
The reference point approach in which the goal is to achieve a weakly, ε-properly or Pareto-optimal solution closest to a supplied reference point of aspiration level based on solving an achievement scalarizing problem.
對于多目標優化問題,通過設定權重將多目標轉換為單目標問題,對于每個目標都給予目標函式方向的參考點向量,當獲取的參考點與Pareto優化前沿點距離最小,即優化前沿點最接近于參考點時,那么獲取的的優化點將是在考慮參考點的基礎上獲得的最終結果,其運算式如下:
M
i
n
∑
i
M
[
w
i
?
(
f
i
(
x
)
?
z
 ̄
i
)
]
s
.
t
.
x
∈
S
(1)
Min \sum{^M_i[w_i*(f_i(\bf x)-\overline z_i)]} s.t. \bf x∈S \tag 1
Min∑iM?[wi??(fi?(x)?zi?)]s.t.x∈S(1) 其中,
z
 ̄
i
\bf \overline z_i
zi? 是參考點,
f
i
f_i
fi?是目標函式,
w
i
w_i
wi?表示權重,
注:原文公式是
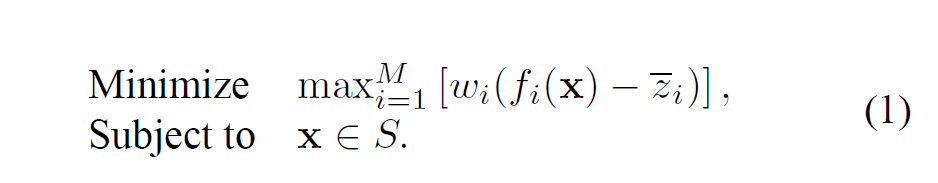
感覺是有問題的,因此做了修改,
為了讓參考點方法有效,Wierzbicki 對該程序進行了如下操作:
1、先確定參考點
z
 ̄
\overline z
z的最近優化點
z
′
z'
z′
2、重新創建M個參考點
3、獲取各個目標函式的最優點
z
i
=
z
 ̄
+
(
z
′
?
z
 ̄
)
?
e
i
(2)
\bf z_i=\overline z+(z'-\overline z)*e_i \tag 2
zi?=z+(z′?z)?ei?(2)
其中
e
i
\bf e_i
ei?為方向向量,原理如圖所示:
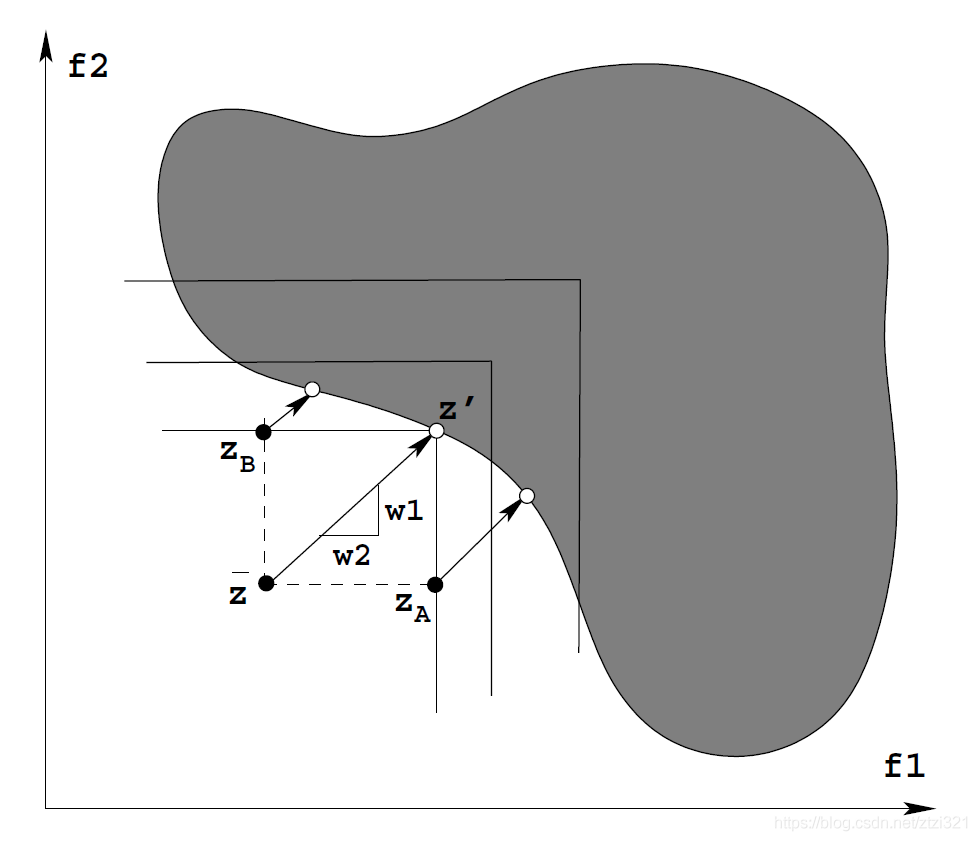
z
A
和
z
B
\bf z_A和z_B
zA?和zB?是新生成的兩個參考點,需要注意的是,若決策者對于結果不滿意,上述程序將會重復進行,
因此,參考點提供了關于要關注的區域的更高層次的資訊,而權值向量提供了關于要收斂帕累托最優前沿上哪個點的更詳細的資訊,
新參考點方法
那么這種傳統參考點方式有什么缺陷,我想大家很容易就從公式中看出來,沒錯,一看到賦權這東西,搞多目標優化的人就很謹慎,這種主觀賦權方式詬病很大,盡管是模型制定者或決策者給予了經驗性的賦權,但這種多目標轉單目標方式有時會因此產生較大的風險,此外,這種方式每次只能使用一個參考點,當決策者給予多個參考點時,這種方法就無能為力了,怎么辦呢?
是的,主角上場了,EMO方法可以解決以上這些問題,本文介紹的EMO是基于NSGA-II方法之上的參考點方法,改方法的思路如下:

具體細節我先直接上原文,如下:


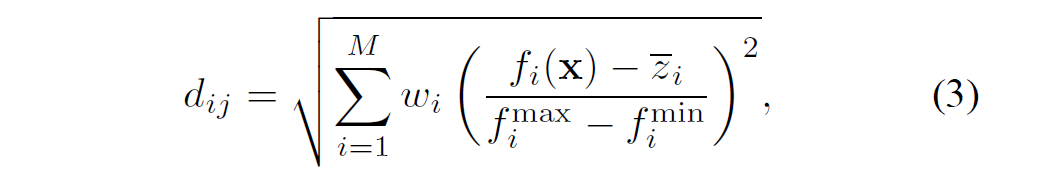
第一步比較好理解,意思就是求前沿點與參考點的距離;
第二步和第三步說實話,我看了半天沒搞明白啥意思,最侄訓是通過代碼才搞明白了這兩步的具體含義,其實這兩步是為了將與前沿點最近的參考點距離設定為其preDistance, 與此同時,為了種群多樣性,在第三步首先隨機選擇一個前沿點作為新的的 “前沿參考點”,然后設定約束限制,凡是距離之間相近或者小于ε-clearing的前沿點,將與前沿參考點相近的那個preDistance增大,進而實作種群的多樣性,避免區域收斂或者收斂過快的問題,
代碼實作
原始碼實作程序,主要是在非支配排序和選擇部分體現,上述思想程序主要是在非支配排序中實作,具體實作代碼如下:
function [opt, pop] = calcPreferenceDistance(opt, pop, front)
% Function: [opt, pop] = calcPreferenceDistance(opt, pop, front)
% Description: Calculate the 'preference distance' used in R-NSGA-II.
% Return:
% opt : This structure may be modified only when opt.refUseNormDistance=='ever'.
%
% Copyright 2011 by LSSSSWC
% Revision: 1.1 Data: 2011-07-26
%*************************************************************************
%*************************************************************************
% 1. Initialization
%*************************************************************************
numObj = length( pop(1).obj ); % number of objectives
refPoints = opt.refPoints;
refWeight = opt.refWeight; % weight factor of objectives
if(isempty(refWeight))
refWeight = ones(1, numObj);
end
epsilon = opt.refEpsilon;
numRefPoint = size(refPoints, 1);
% Determine the normalized factors
bUseFrontMaxMin = false; % bUseFrontMaxMin : If use the maximum and minimum value in the front as normalized factor.
if( strcmpi(opt.refUseNormDistance, 'ever') )
% 1) Find possiable (not current population) maximum and minimum value
% of each objective.
obj = vertcat(pop.obj);
if( ~isfield(opt, 'refObjMax_tmp') )
opt.refObjMax_tmp = max(obj);
opt.refObjMin_tmp = min(obj);
else
objMax = max(obj);
objMin = min(obj);
for i = 1:numObj
if(opt.refObjMax_tmp(i) < objMax(i))
opt.refObjMax_tmp(i) = objMax(i);
end
if(opt.refObjMin_tmp(i) > objMin(i))
opt.refObjMin_tmp(i) = objMin(i);
end
end
clear objMax objMin
end
objMaxMin = opt.refObjMax_tmp - opt.refObjMin_tmp;
clear obj
elseif( strcmpi(opt.refUseNormDistance, 'front') )
% 2) Do not use normalized Euclidean distance.
bUseFrontMaxMin = true;
elseif( strcmpi(opt.refUseNormDistance, 'no') )
% 3) Do not use normalized Euclidean distance.
objMaxMin = ones(1,numObj);
else
% 3) Error
error('NSGA2:ParamError', ...
'No support parameter: options.refUseNormDistance="%s", only "yes" or "no" are supported',...
opt.refUseNormDistance);
end
%*************************************************************************
% 2. Calculate preference distance pop(:).prefDistance
%*************************************************************************
for fid = 1:length(front)
% Step1: Calculate the weighted Euclidean distance in each front
idxFront = front(fid).f; % idxFront : index of individuals in current front
numInd = length(idxFront); % numInd : number of individuals in current front
popFront = pop(idxFront); % popFront : individuals in front fid
objFront = vertcat(popFront.obj); % objFront : the whole objectives of all individuals
if(bUseFrontMaxMin)
objMaxMin = max(objFront) - min(objFront); % objMaxMin : the normalized factor in current front
end
% normDistance : weighted normalized Euclidean distance
normDistance = calcWeightNormDistance(objFront, refPoints, objMaxMin, refWeight);
% Step2: Assigned preference distance
prefDistanceMat = zeros(numInd, numRefPoint);
for ipt = 1:numRefPoint
[~,ix] = sort(normDistance(:, ipt));%升序排序,選擇距離小的
prefDistanceMat(ix, ipt) = 1:numInd;%排序位置
end
prefDistance = min(prefDistanceMat, [], 2); % 2表示計算每行min 對于參考點距離的rank位置,rank的值當作參考距離
clear ix
% Step3: Epsilon clearing strategy
idxRemain = 1:numInd; % idxRemain : index of individuals which were not processed
while(~isempty(idxRemain))
% 1. Select one individual from remains
objRemain = objFront( idxRemain, :);
selIdx = randi( [1,length(idxRemain)] );
selObj = objRemain(selIdx, :);
% 2. Calc normalized Euclidean distance
% distanceToSel : normalized Euclidean distance to the selected points
distanceToSel = calcWeightNormDistance(objRemain, selObj, objMaxMin, refWeight);
% 3. Process the individuals within a epsilon-neighborhood
idx = find( distanceToSel <= epsilon ); % idx : index in idxRemain
if(length(idx) == 1) % the only individual is the selected one
idxRemain(selIdx)=[];
else
for i=1:length(idx)
if( idx(i)~=selIdx )
idInIdxRemain = idx(i); % idx is the index in idxRemain vector
id = idxRemain(idInIdxRemain);
% *Increase the preference distance to discourage the individuals
% to remain in the selection.
prefDistance(id) = prefDistance(id) + round(numInd/2);
end
end
idxRemain(idx) = [];
end
end
% Save the preference distance
for i=1:numInd
id = idxFront(i);
pop(id).prefDistance = prefDistance(i);
end
end
參考點距離計算:
function pop = calcCrowdingDistance(opt, pop, front)
% Function: pop = calcCrowdingDistance(opt, pop, front)
% Description: Calculate the 'crowding distance' used in the original NSGA-II.
% Syntax:
% Parameters:
% Return:
%
% Copyright 2011 by LSSSSWC
% Revision: 1.0 Data: 2011-07-11
%*************************************************************************
numObj = length( pop(1).obj ); % number of objectives
for fid = 1:length(front)
idx = front(fid).f;
frontPop = pop(idx); % frontPop : individuals in front fid
numInd = length(idx); % nInd : number of individuals in current front
obj = vertcat(frontPop.obj);
obj = [obj, idx']; % objctive values are sorted with individual ID
% 獲取每個rank下每個個體不同目標函式下的擁擠度距離,個體擁擠度為個目標函式擁擠度之和s
for m = 1:numObj
obj = sortrows(obj, m); %Sort the rows of A based on the values in the second column. When the specified column has repeated elements,
%the corresponding rows maintain their original order.
%對于每一個目標函式排序后的第一個和最后一個個體的距離設定為inf
colIdx = numObj+1;
pop( obj(1, colIdx) ).distance = Inf; % the first one
pop( obj(numInd, colIdx) ).distance = Inf; % the last one
minobj = obj(1, m); % the minimum of objective m
maxobj = obj(numInd, m); % the maximum of objective m
for i = 2:(numInd-1)
id = obj(i, colIdx);
pop(id).distance = pop(id).distance + (obj(i+1, m) - obj(i-1, m)) / (maxobj - minobj); %均一化
end
end
end
在選擇程序中也做了簡單的修改,距離改成了preDistance,修改代碼如下:
function result = preferenceComp(guy1, guy2)
% Function: result = preferenceComp(guy1, guy2)
% Description: Preference operator used in R-NSGA-II
% Return:
% 1 = guy1 is better than guy2
% 0 = other cases
%
% Copyright 2011 by LSSSSWC
% Revision: 1.0 Data: 2011-07-11
%*************************************************************************
if( (guy1.rank < guy2.rank) || ...
((guy1.rank == guy2.rank) && (guy1.prefDistance < guy2.prefDistance)) )
result = 1;
else
result = 0;
end
實作結果
可以看出,從圖中可以找到參考點較近的Pareto 優化解,
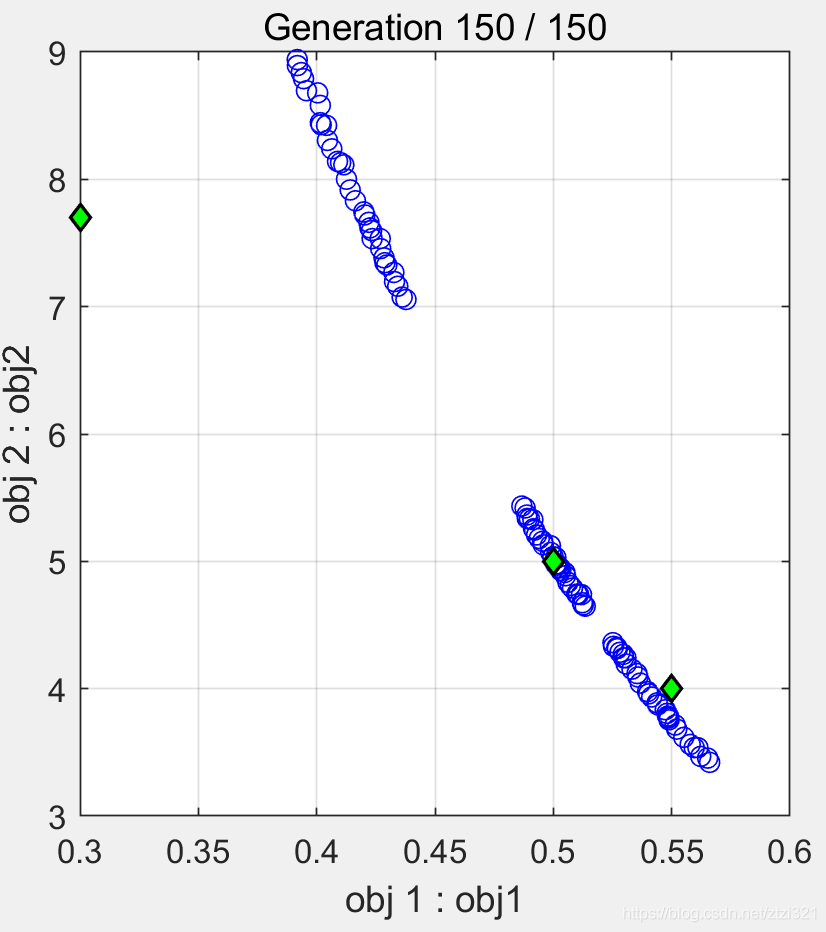
需要注意的是,Pareto 前沿可以根據ε的值變化而變化,如下圖,因此,在選擇ε值時需要根據決策者的需求尋找合適的前沿,
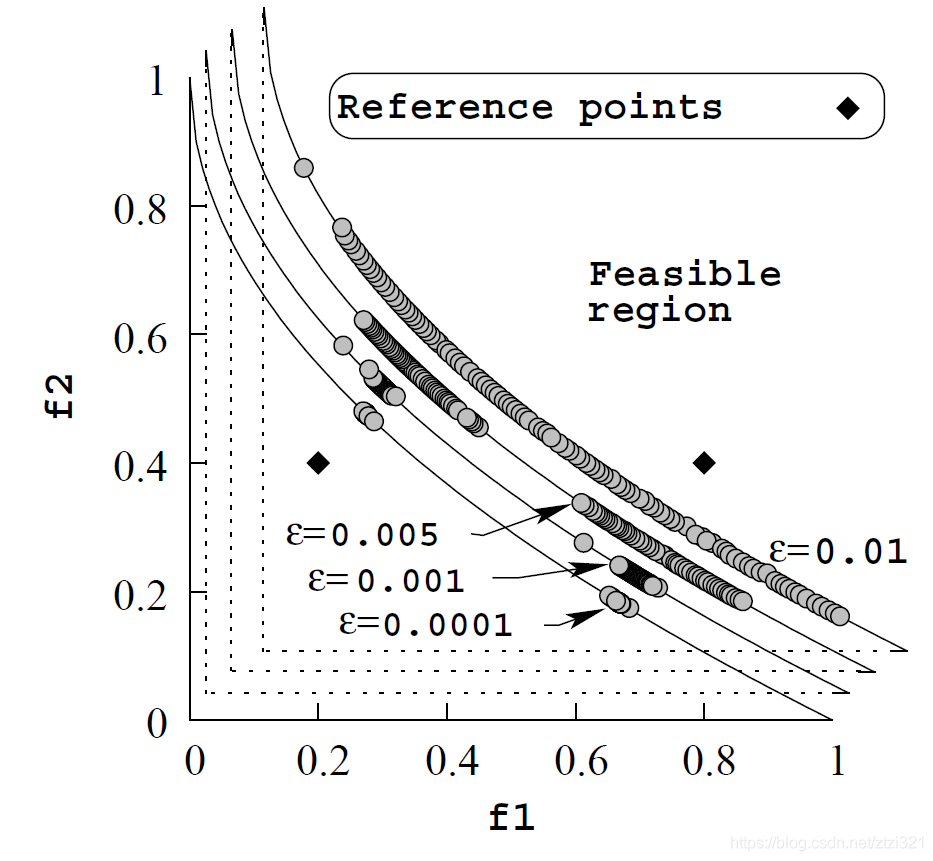

我們不妨將ε理解為寬松度或者是一種期望水平誤差,當ε越小時,也就是我們的期望水平要求誤差越小,那么將會看到Pareto前沿點更加的逼近參考點,通過下圖對比更容易理解這個意思,如下圖所示
ε=0.01
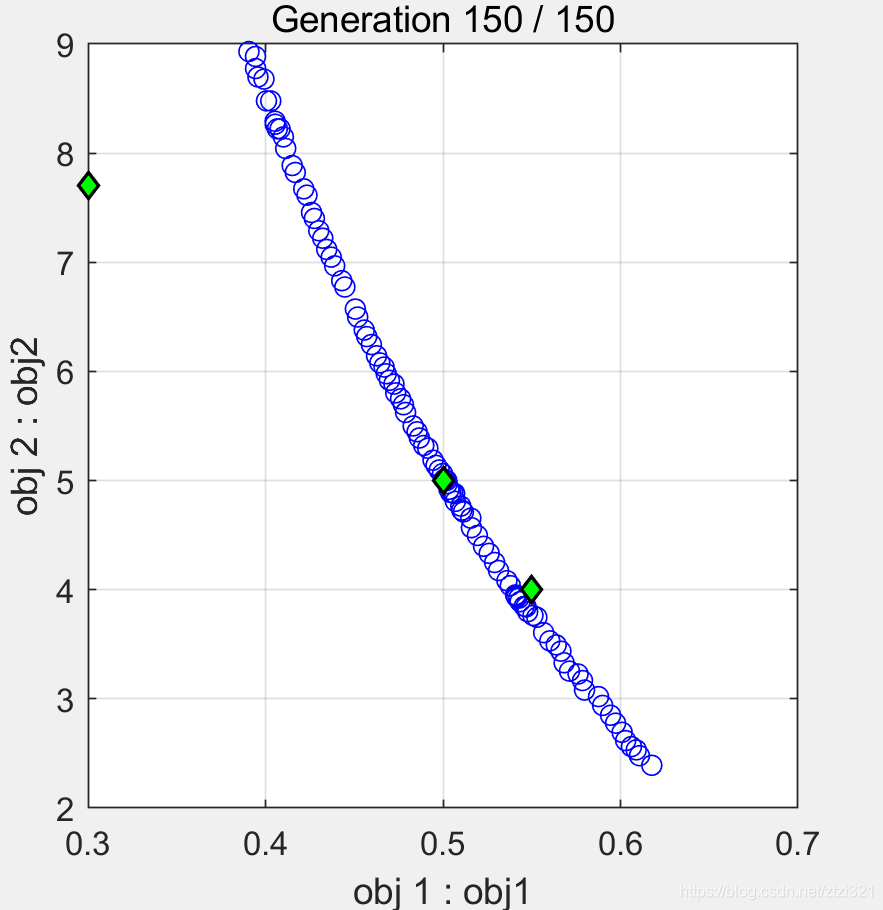
ε=0.0001
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231974.html
標籤:AI