因為防止作業重復,以及我抄我自己的情況出現,所以這里暫時只提供思路,不附代碼,
賣菜(100分)
思路
這題沒啥難的,注意兩端計算方式是 ( a 1 + a 2 ) / 2 (a_1+a_2)/2 (a1?+a2?)/2、 ( a n + a n ? 1 ) / 2 (a_n+a_{n-1})/2 (an?+an?1?)/2,而其他部分計算方式位 ( a i ? 1 + a i + a i + 1 ) / 3 (a_{i-1}+a_i+a_{i+1})/3 (ai?1?+ai?+ai+1?)/3
買菜(100分)
思路
不能想當然地將兩人時間段一對一地比較,要考慮極端情況,假如一個人的某個時段的結束時間比另一個人的結束時間要短,那么說明這個人的下一個時段也可能存在與另一個人同一段時間的交疊部分,因此繼續將這個人的下一個時間段與另一個人的同一段時間相比,如此重復,直到其中一人的時間段都比較完了,時間復雜度最好情況O(n),最壞情況O(n^2),
元素選擇器(100分)
思路
對于單個的標簽或者id查詢是很容易實作的,難點在于如何處理后代選擇器,這里有兩個思路,
第一種思路構造樹形結構,如圖所示,這樣很容易就能查到與當前點相關的子孫,按照深度遍歷次序搜索后代即可;
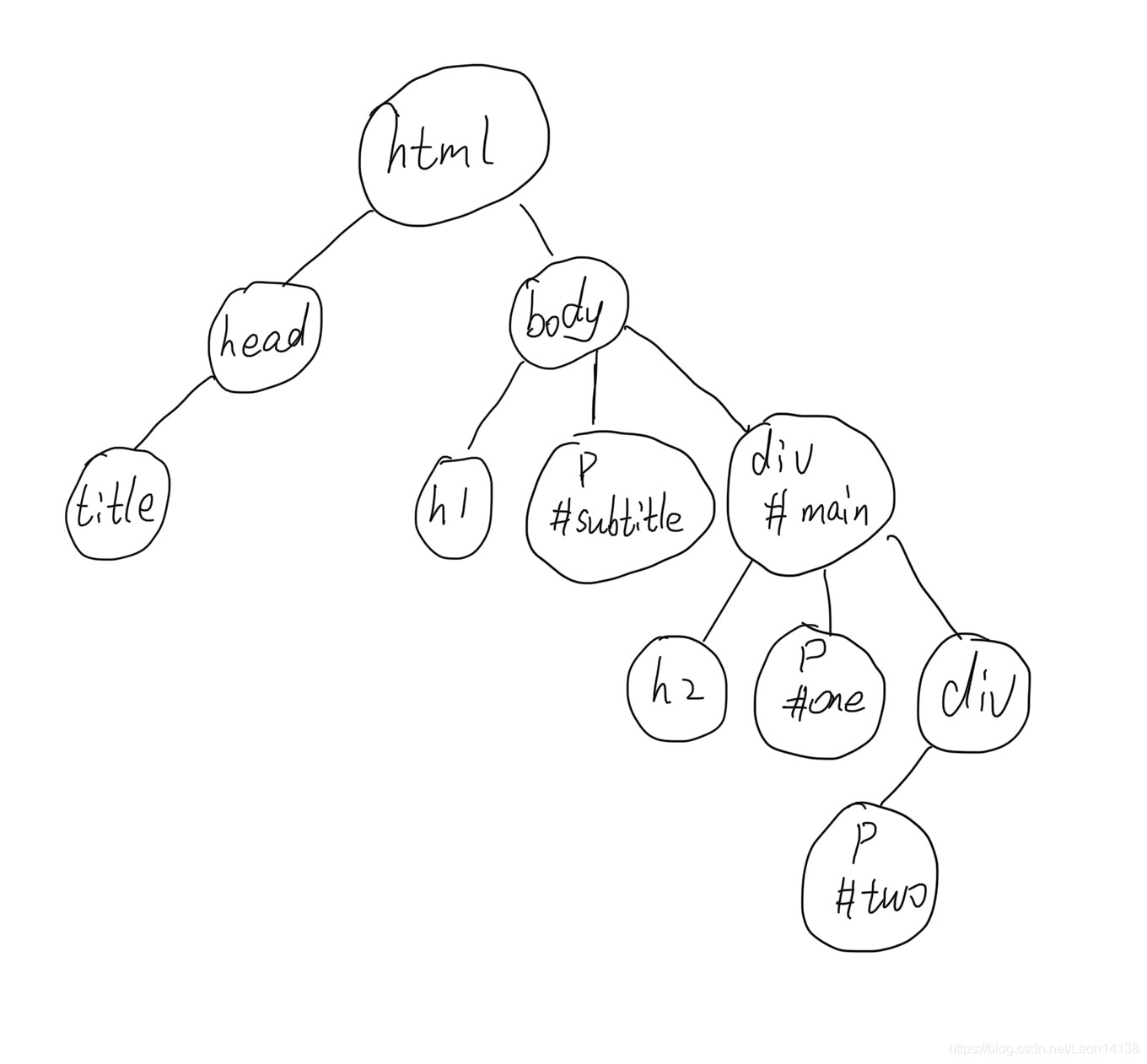
我采用的是第二種思路貪心策略,首構造一個檔案每行內容的一個資料結構,要包含三個屬性(級別、標簽和id),根據題目提示的貪心策略,對于當前行,其后級別不大于他的都是他的子孫,按照這個思路我設定了一個答案ans陣列和緩沖buf陣列,遍歷每一級查詢,buf中存的是當前級別上一級查詢的結果,逐個取出buf中的行號,從這個行號可是遍歷查詢他的子孫是否有當前要查詢的東西,
注意查詢和檔案的標簽要全部轉換為小寫(大寫),此外,利用這種貪心的策略(樹形結構思路也一樣)會出現查詢 div p 時會將 div div p 認為是兩個 div p,這樣就會出現重復,要注意去重,
再賣菜(80分)
思路
用 a 表示第一天的價格,b 表示第二天的價格,
暴力方法:遍歷所有商鋪 a 的可能價格,進行驗證,必定會TLE,
該題看似狀態眾多,但是除了縮小邊界外,還可以根據數學關系以及已知的數來縮小狀態數,這樣就可以用dfs進行搜素了
我們首先分析題目,加上整除的計算方式,可以得到兩端的關系式
2 ? b 1 < = a 1 + a 2 < = 2 ? b 1 + 1 2*b_1<=a_1+a_2<=2*b_1+1 2?b1?<=a1?+a2?<=2?b1?+1
2 ? b n < = a n ? 1 + a n < = 2 ? b n + 1 2*b_n<=a_{n-1}+a_n<=2*b_n+1 2?bn?<=an?1?+an?<=2?bn?+1
其他部分的關系式為
3 ? b i < = a i ? 1 + a i + a i + 1 < = 3 ? b i + 2 3*b_i<=a_{i-1}+a_i+a_{i+1}<=3*b_i+2 3?bi?<=ai?1?+ai?+ai+1?<=3?bi?+2
對于兩端關系式(以起始端為例),假如我們已經知道了 a 1 a_1 a1?的值,那么 a 2 a_2 a2?的值就會被限制在有限的兩種可能中,即 2 ? b 1 ? a 1 2*b_1-a_1 2?b1??a1?和 2 ? b 1 + 1 ? a 1 2*b_1+1-a_1 2?b1?+1?a1?;
同樣地,對于其他部分關系式,如果我們已經知道了 a i ? 1 a_{i-1} ai?1?和 a i a_i ai?的值,那么 a i + 1 a_{i+1} ai+1?的值就會被限制在有限的三種可能中,即 3 ? b i ? a i ? 1 ? a i 3*b_i-a_{i-1}-a_i 3?bi??ai?1??ai?、 3 ? b i + 1 ? a i ? 1 ? a i 3*b_i+1-a_{i-1}-a_i 3?bi?+1?ai?1??ai?和 3 ? b i + 2 ? a i ? 1 ? a i 3*b_i+2-a_{i-1}-a_i 3?bi?+2?ai?1??ai?,
這樣,我們可以遍歷 a 1 a_1 a1?的所有可能,然后來搜索后續可能狀態,這樣可以保證之后每個點的狀態都不會超過三種,只需要搜索到倒數第二個點即可得到 a 的序列,然后用末尾端的關系式進行驗證,
這樣的dfs搜索策略可以拿到80分,當 n 很大時,搜索狀態依然很多,還是會超時,
PS:這里有一個優化策略,即剪枝,我們已經知道,后一個值是有前兩個值確定,那么當遍歷到i點時,且訪問了某種 a i ? 1 a_{i-1} ai?1?和 a i a_i ai?的值的組合,那么不管其他值怎么變化,再次在i點時,這種組合必然也不可能成功,所以沒必要對這種狀態搜索下去,
使用這種剪枝策略實作的C++代碼,能達到100分,但是,不知道為什么,Java剪枝后的時間效率反而不如不剪枝的,我猜測可能是因為使用了較大的vis陣列,使得Java的gc機制耗時更多了,
線性遞推式(20分)
思路
乍一看 l 可以很大,以為是陣列記憶體不夠的問題,再一看樣例,好家伙還要考慮乘法溢位的問題,感覺巨難,沒啥思路,只能暴力20分,這個代碼不怕抄,可以附代碼,
代碼(20分)
import java.util.*;
public class q5 {
private static Scanner sc;
public static void main(String[] args) {
sc=new Scanner(System.in);
int m=sc.nextInt(),l=sc.nextInt(),r=sc.nextInt();
sc.nextLine();
long[] a=new long[r+1];
long[] k=new long[100010];
for(int i=1;i<=m;i++) {
k[i]=sc.nextLong();;
}
a[0]=1;
for(int i=1;i<=r;i++) {
int min=(i<m ? i : m);
for(int j=1;j<=min;j++) {
a[i]=(a[i]+k[j]*a[i-j]%998244353)%998244353;
}
}
for(int i=l;i<=r;i++) {
System.out.println(a[i]);
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232538.html
標籤:其他