視頻教程第二彈,快速理清TDengine中的抽象概念,并學會規劃生產場景中的資料模型,
點擊鏈接,獲取視頻教程,
歡迎來到物聯網的資料世界
在典型的物聯網場景中,一般有多種不同型別的采集設備,采集多種不同的物理量,同一種采集設備型別,往往有多個設備分布在不同的地點,系統需對各種采集的資料匯總,進行計算和分析對于同一類設備,其采集的資料都是很規則的,
本文我們以智能電表(采集量為電流、電壓)為例,探討如何在TDengine中建庫、建超級表、建表,
假設每個智能電表采集電流、電壓兩個量,其采集的資料如下圖所示,
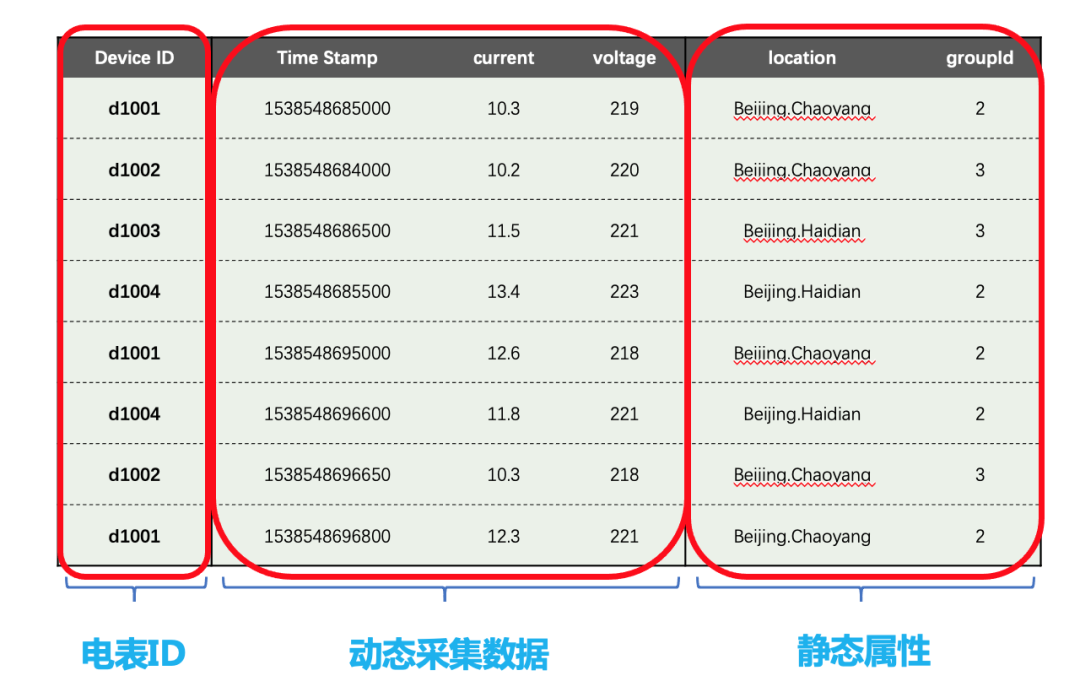
每一條記錄都有設備ID,時間戳,采集的物理量(如上圖中的電流、電壓),還有與每個設備相關的靜態標簽(如上圖中的位置Location和分組groupId),每個設備是受外界的觸發,或按照設定的周期采集資料,采集的資料點是時序的,是一個資料流,
那么TDengine如何抽象這些物聯網資料呢?
這里,需要提到TDengine的關鍵創新點——一個采集點一張表,同一型別的采集點用一個超級表來描述,也就是一個表結構Schema和靜態標簽Schema ,就上圖來說,電表ID作為子表名(d1001, d1002, d1003, d1004等),動態采集的物理量作為各欄位,靜態屬性(Location和groupId)作為子表標簽,利用超級表作為模板,生成子表 – 對應各采集點,有了超級表,極大地方便了同類采集點的資料檢索、查詢、聚合,
這種設計有幾大優點:
-
能保證一個采集點的資料在存盤介質上是以塊為單位連續存盤的,如果讀取一個時間段的資料,它能大幅減少隨機讀取操作,成數量級的提升讀取和查詢速度,
-
由于不同采集設備產生資料的程序完全獨立,每個設備的資料源是唯一的,一張表也就只有一個寫入者,這樣就可采用無鎖方式來寫,寫入速度就能大幅提升,
-
對于一個資料采集點而言,其產生的資料是時序的,因此寫的操作可用追加的方式實作,進一步大幅提高資料寫入速度,
如果采用傳統的方式,將多個設備的資料寫入一張表,由于網路延時不可控,不同設備的資料到達服務器的時序是無法保證的,寫入操作是要有鎖保護的,而且一個設備的資料是難以保證連續存盤在一起的,采用一個資料采集點一張表的方式,能最大程度的保證單個資料采集點的插入和查詢的性能是最優的,
資料建模的基本方法
TDengine采用關系型資料模型,需要建庫、建表,因此對于一個具體的應用場景,需要考慮庫的設計,超級表和普通表的設計,
CREATE DATABASE dbnameUSE dbnameCREATE TABLE stbname (ts timestamp, other fields…) tags ( tag fields)CREATE TABLE tbname using stbname tags(具體標簽值)INSERT INTO tbname VALUES(now, values…)
創建庫
不同型別的資料采集點往往具有不同的資料特征,包括資料采集頻率的高低,資料保留時間的長短,副本的數目,資料塊的大小等,為讓各種場景下TDengine都能最大效率的作業,建議將不同資料特征的表創建在不同的庫里,因為每個庫可以配置不同的存盤策略,
創建一個庫時,除SQL標準的選項外,應用還可以指定保留時長、副本數、記憶體塊個數、時間精度、檔案塊里最大最小記錄條數、是否壓縮、一個資料檔案覆寫的天數等多種引數,比如建議為資料特征相同的表創建一個庫,每個庫可以配置不同的存盤策略,
CREATE DATABASE power KEEP 365;上述將創建一個名為power的庫,這個庫的資料將保留365天,更多引數及語法見:
https://www.taosdata.com/cn/documentation20/taos-sql/創建庫之后,需要使用SQL命令USE將當前庫切換過來,例如:
USE power;將當前操作庫換為power,還可使用“庫名.表名”來指定操作的庫、表的名字,
引入超級表
一個資料采集點一張表, 意味著1000萬智能電表對應1000萬張表,一個物聯網系統,往往存在海量同型別的資料采集點,如何對這么多張表進行操作就是一個巨大的挑戰,為方便對同型別多表的操作,TDengine引入超級表,
創建超級表時,需提供:表名、表結構Schema、標簽Schema,
CREATE TABLE meters (ts timestamp, current float, voltage int) TAGS (location binary(64), groupdId int);超級表的列分兩部分:動態部分,靜態部分,
動態部分是采集的資料,第一列為時間戳(ts),其他列為采集的物理量(current, voltage),
靜態部分指采集點的靜態屬性,一般作為標簽,如采集點的地理位置、設備型號、設備組、管理員ID等,
標簽可以事后增加、洗掉、修改,
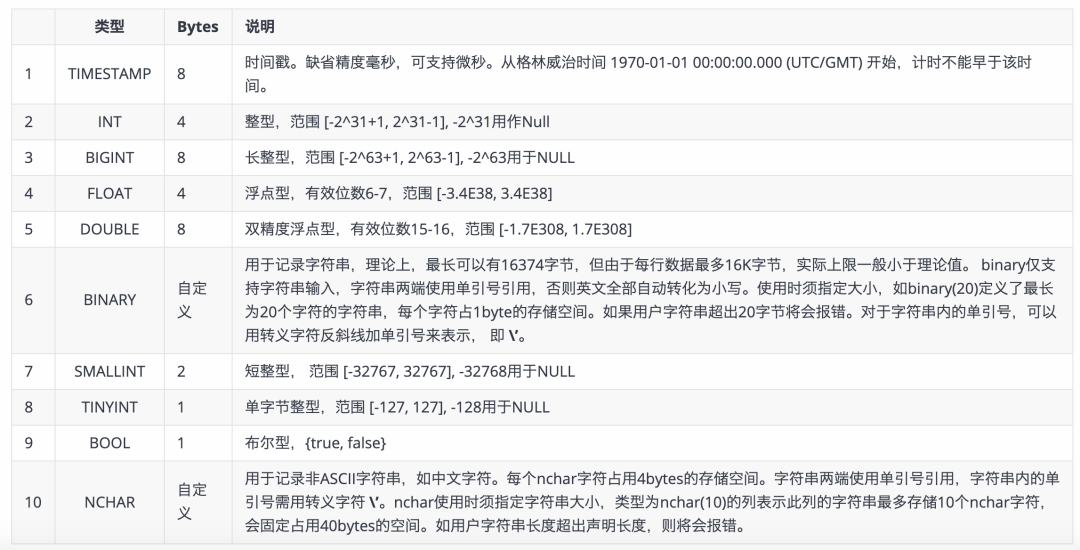
TDengine支持以下資料型別,
深入理解超級表
同時采集同表:一張超級表里,包含的采集物理量必須是同時采集的,也就是說時間戳都是相同的,
對一個型別的設備,可能存在多組物理量,每組物理量并不是同時采集的,則需要為每組物理量單獨建一個超級表,因此一個型別的設備,可能需要建立多個超級表,
系統有N個不同型別的設備,就需要建立至少N個超級表,
一個系統可以有多個DB庫,一個DB庫里可以有一到多個超級表,
創建表/子表
TDengine對每個資料采集點需要獨立建表;因為源于超級表(meters)創建而成,也稱子表(d1001);創建時,需要使用超級表做模板,同時指定標簽的具體值;一個超級表,可包含若干子表,子表數量沒有限制,
CREATE TABLE d1001 USING meters TAGS ("Beijing.Chaoyang", 2);d1001是子表名,meters是超級表名,緊跟Location的標簽值”Beijing.Chaoyang",groupId的標簽值2,在創建表/子表時,需指定標簽值,事后也可修改;建議將資料采集點的全域唯一ID作為子表名(如設備序列號),
子表自動建表
在某些特殊場景中,用戶在寫資料時,并不確定某個子表是否存在,此時,可使用自動建表語法來創建不存在的表,若該表已存在則不會建立新表,
INSERT INTO d1001 USING meters TAGS ("Beijng.Chaoyang", 2) VALUES (now, 10.2, 219);上述SQL陳述句將記錄(now, 10.2, 219) 插入進表d1001,如果表d1001還未創建,則使用超級表meters做模板自動創建,同時打上標簽值“Beijing.Chaoyang", 2,
多列模型 vs 單列模型
TDengine既支持多列模型,也支持單列模型,
-
多列模型:只要物理量是同一資料采集點同時采集的,這些量就可以作為不同列放在一張超級表里,
-
單列模型:每個物理量都單獨建表,比如電流、電壓兩個量,就建兩張超級表,
我們建議:盡可能采用多列模型,因為插入效率以及存盤效率更高;對于有些場景,一個采集點的物理量的種類經常變化,這時可采用單列模型,
新能源汽車示例
場景及建模分析
-
某車企擬對其生產、銷售的新能源汽車進行追蹤分析;
-
每輛車配置了遠程采集終端,采集車輛狀態資訊:位置(經緯度)、車速、電池溫度、電池電流、環境溫度、輪胎胎壓;
-
后臺統計分析需要按:車型、銷售區域、銷售員、電池包容量、電機功率進行分類聚合;
-
6個采集量中前4個為同時采集,將其放入一張超級表 – vehicle_main, 其余2個測點,溫度與胎壓采集的頻率完全不一樣,分別創建2個超級表 – vehicle_temp, vehicle_tire;
-
每輛車有唯一編碼VIN,采用該編碼與超級表的表名前綴作為唯一表名,
SQL陳述句示例
CREATE DATABASE nev KEEP 3650;USE nev;CREATE TABLE vehicle_main (ts timestamp, longitude double, latitude double, vspeed int, btemp int, bcurrent int) TAGS (vin binary(30), model binary(20), szone binary(30), sales int, bcapacity float, mpower float);CREATE TABLE vmTS8392EGV062192009 USING vehicle_main TAGS ("TS8392EGV062192009", "GTS7180", "Beijing.haidian", "10060089", 86.0, 125.5);
CREATE TABLE vehicle_temp (ts timestamp, vtemp int) TAGS (vin binary(30));CREATE TABLE vtpTS8392EGV062192009 USING vehicle_vtemp TAGS ("TS8392EGV062192009");CREATE TABLE vehicle_tire (ts timestamp, vpressure int) TAGS (vin binary(30));CREATE TABLE vtrTS8392EGV062192009 USING vehicle_vtire TAGS ("TS8392EGV062192009");//查詢指定車輛最近10天的運行軌跡SELECT ts, longtitude, latitude FROM vtrTS8392EGV062192009 where ts >now -10d//按車型查詢平均車速、平均動力電池溫度、平均放電電流SELECT AVG(vspeed), AVG(btemp), AVG(bcurrent) FROM vehicle_main GROUP BY model
相信到這里,你已經完全理清了TDengine中庫、表、超級表的概念,可以上手操作了!
關注公眾號TDengine,后臺回復“1203”,獲取本教程對應PPT,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232610.html
標籤:其他