目錄
- 第1章 消費者詳解
- 1.1 概念入門
- 1.1.1 消費者和消費組
- 1.2 訊息接收
- 1.2.1 必要引數設定
- 1.2.2 訂閱主題和磁區
- 1.2.2 反序列化
- 1.2.3 位移提交
- 1.2.4 指定位移消費
- 1.2.4 再均衡監聽器
- 1.2.5 消費者攔截器
- 1.2.6 消費者引數補充
- 總結
第1章 消費者詳解
tips 學完這一章你可以、
深入學習Kafka資料消費大致流程
如何創建并使用Kafka消費者
Kafka消費者常用配置
1.1 概念入門
1.1.1 消費者和消費組
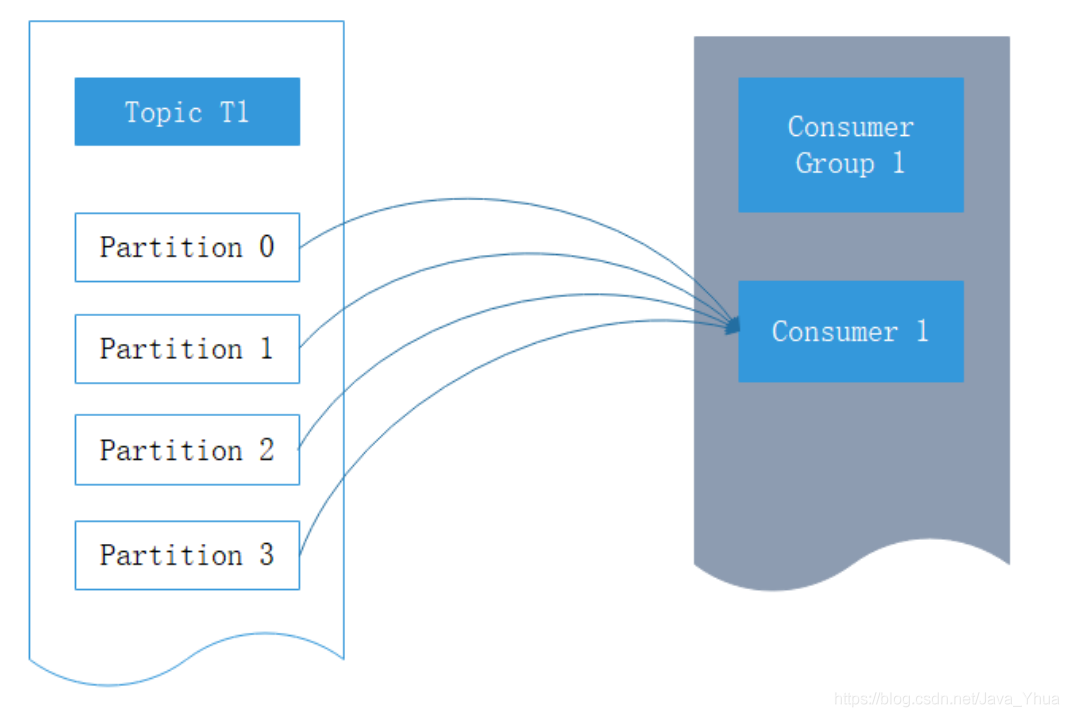
Kafka消費者是消費組的一部分,當多個消費者形成一個消費組來消費主題時,每個消費者會收到不同磁區的訊息,假設有一個T1主題,該主題有4個磁區;同時我們有一個消費組G1,這個消費組只有一個消費者C1,那么消費者C1將會收到這4個磁區的訊息,如下所示:
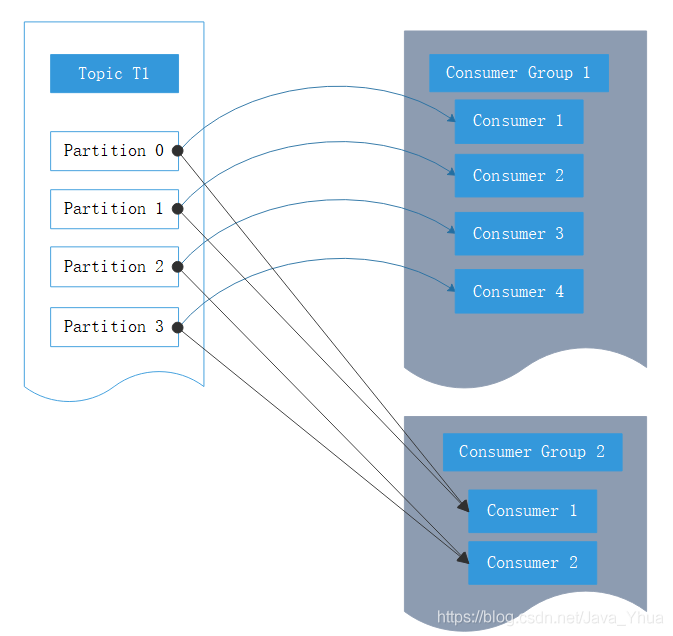
Kafka一個很重要的特性就是,只需寫入一次訊息,可以支持任意多的應用讀取這個訊息,換句話說,每個應用都可以讀到全量的訊息,為了使得每個應用都能讀到全量訊息,應用需要有不同的消費組,對于上面的例子,假如我們新增了一個新的消費組G2,而這個消費組有兩個消費者,那么會是這樣的:
1.2 訊息接收
見代碼庫:com.heima.kafka.chapter3.KafkaConsumerAnalysis
1.2.1 必要引數設定
KafkaConsumer實體中引數眾多,后續會深入講解
public static Properties initConfig() {
Properties props = new Properties();
// 與KafkaProducer中設定保持一致
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 必填引數,該引數和KafkaProducer中的相同,制定連接Kafka集群所需的broker地址清 單,可以設定一個或者多個
props.put("bootstrap.servers", brokerList);
// 消費者隸屬于的消費組,默認為空,如果設定為空,則會拋出例外,這個引數要設定成具有一 定業務含義的名稱
props.put("group.id", groupId);
// 指定KafkaConsumer對應的客戶端ID,默認為空,如果不設定KafkaConsumer會自動生成 一個非空字串
props.put("client.id", "consumer.client.id.demo");
return props;
}
1.2.2 訂閱主題和磁區
創建完消費者后我們便可以訂閱主題了,只需要通過呼叫subscribe()方法即可,這個方法接收一個主題串列
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
另外,我們也可以使用正則運算式來匹配多個主題,而且訂閱之后如果又有匹配的新主題,那么這個消費組會立即對其進行消費,正則運算式在連接Kafka與其他系統時非常有用,比如訂閱所有的測驗主題:
consumer.subscribe(Pattern.compile("heima*"));
指定訂閱的磁區
// 指定訂閱的磁區
consumer.assign(Arrays.asList(new TopicPartition("topic0701", 0)));
1.2.2 反序列化
// 與KafkaProducer中設定保持一致
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 必填引數,
1.2.3 位移提交
對于Kafka中的磁區而言,它的每條訊息都有唯一的offset,用來表示訊息在磁區中的位置,當我們呼叫poll()時,該方法會回傳我們沒有消費的訊息,當訊息從broker回傳消費者時,broker并不跟蹤這些訊息是否被消費者接收到;Kafka讓消費者自身來管理消費的位移,并向消費者提供更新位移的介面,這種更新位移方式稱為提交(commit),
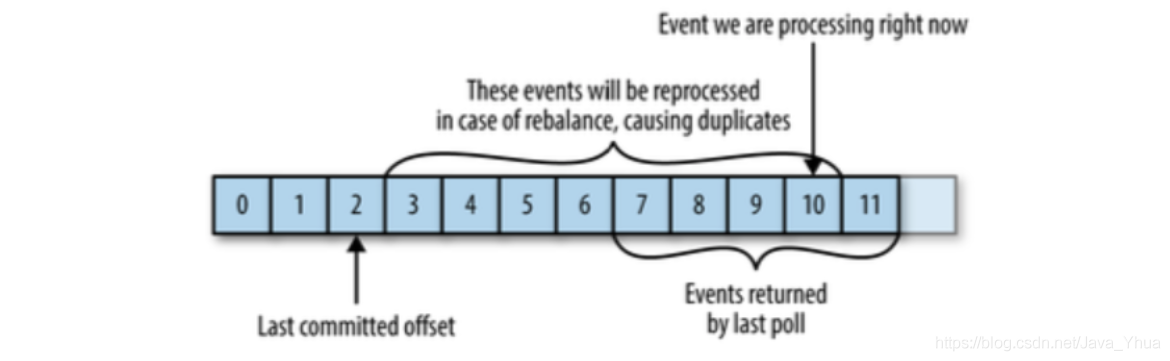
重復消費
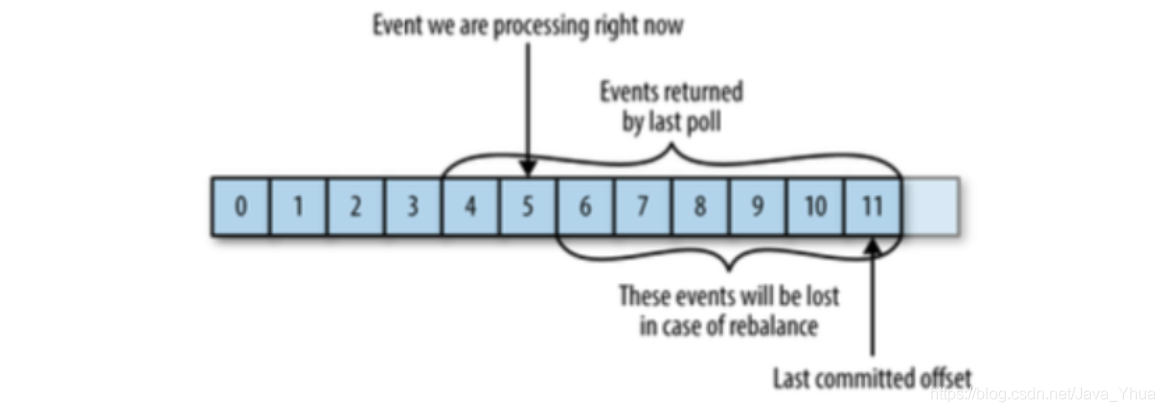
訊息丟失
自動提交
這種方式讓消費者來管理位移,應用本身不需要顯式操作,當我們將enable.auto.commit設定為true,
那么消費者會在poll方法呼叫后每隔5秒(由auto.commit.interval.ms指定)提交一次位移,和很多其他操作一樣,自動提交也是由poll()方法來驅動的;在呼叫poll()時,消費者判斷是否到達提交時間,如果是則提交上一次poll回傳的最大位移,
需要注意到,這種方式可能會導致訊息重復消費,假如,某個消費者poll訊息后,應用正在處理訊息,在3秒后Kafka進行了重平衡,那么由于沒有更新位移導致重平衡后這部分訊息重復消費,
同步提交
見代碼庫:com.heima.kafka.chapter3.CheckOffsetAndCommit
public static Properties initConfig() {
Properties props = new Properties(); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 手動提交開啟 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); return props;
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
if (records.isEmpty()) {
break;
}
List<ConsumerRecord<String, String>> partitionRecords = records.records(tp);
lastConsumedOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync();//同步提交消費位移 }
異步提交
手動提交有一個缺點,那就是當發起提交呼叫時應用會阻塞,當然我們可以減少手動提交的頻率,但這個會增加訊息重復的概率(和自動提交一樣),另外一個解決辦法是,使用異步提交的API,
見代碼:com.heima.kafka.chapter3.OffsetCommitAsyncCallback
但是異步提交也有個缺點,那就是如果服務器回傳提交失敗,異步提交不會進行重試,相比較起來,同步提交會進行重試直到成功或者最后拋出例外給應用,異步提交沒有實作重試是因為,如果同時存在多個異步提交,進行重試可能會導致位移覆寫,舉個例子,假如我們發起了一個異步提commitA,此時的提交位移為2000,隨后又發起了一個異步提交commitB且位移3000;commitA提交失敗但commitB提交成功,此時commitA進行重試并成功的話,會將實際上將已經提交的位移從3000回滾到2000,導致訊息重復消費,
異步回呼
try {
while (running.get()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//do some logical processing.
}
// 異步回呼
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets,
Exception exception) {
if(exception==null){
System.out.println(offsets);
}else {log.error("fail to commit offsets {}", offsets,
exception);
}
}
});
}
} finally {
consumer.close();
}
1.2.4 指定位移消費
到目前為止,我們知道訊息的拉取是根據poll()方法中的邏輯來處理的,但是這個方法對于普通開發人
員來說就是個黑盒處理,無法精確掌握其消費的起始位置,
seek()方法正好提供了這個功能,讓我們得以追蹤以前的消費或者回溯消費,
見代碼庫:com.heima.kafka.chapter3.SeekDemo
/***
指定位移消費
*/
public class SeekDemo extends ConsumerClientConfig {
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic));
// timeout引數設定多少合適?太短會使磁區分配失敗,太長又有可能造成一些不必要的等待
consumer.poll(Duration.ofMillis(2000));
// 獲取消費者所分配到的磁區
Set<TopicPartition> assignment = consumer.assignment(); System.out.println(assignment);
for (TopicPartition tp : assignment) {
// 引數partition表示磁區,offset表示指定從磁區的哪個位置開始消費
consumer.seek(tp, 10);
}
// consumer.seek(new TopicPartition(topic,0),10);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
//consume the record.
for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value());
}
}
}
增加判斷是否分配到了磁區,見代碼庫:com.heima.kafka.chapter3.SeekDemoAssignment
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
long start = System.currentTimeMillis();
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(assignment);
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10);
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
//consume the record.
for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value());
}
}
}
- 指定從磁區末尾開始消費 ,見代碼庫:com.heima.kafka.chapter3.SeekToEnd
// 指定從磁區末尾開始消費
Map<TopicPartition, Long> offsets = consumer.endOffsets(assignment);
for (TopicPartition tp : assignment) {
consumer.seek(tp, offsets.get(tp));
}
- 演示位移越界操作,修改代碼如下:
for (TopicPartition tp : assignment) {
//consumer.seek(tp, offsets.get(tp));
consumer.seek(tp, offsets.get(tp) + 1);
}
會通過auto.offset.reset引數的默認值將位置重置,效果如下:
INFO [Consumer clientId=consumer-1, groupId=group.heima] Fetch offset 1 is out
of range for partition heima-0, resetting offset
(org.apache.kafka.clients.consumer.internals.Fetcher:967)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Fetch offset 10 is out
of range for partition heima-1, resetting offset
(org.apache.kafka.clients.consumer.internals.Fetcher:967)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Resetting offset for
partition heima-0 to offset 0.
(org.apache.kafka.clients.consumer.internals.Fetcher:583)
INFO [Consumer clientId=consumer-1, groupId=group.heima] Resetting offset for
partition heima-1 to offset 9.
(org.apache.kafka.clients.consumer.internals.Fetcher:583)
1.2.4 再均衡監聽器
再均衡是指磁區的所屬從一個消費者轉移到另外一個消費者的行為,它為消費組具備了高可用性和伸縮性提供了保障,使得我們既方便又安全地洗掉消費組內的消費者或者往消費組內添加消費者,不過再均衡發生期間,消費者是無法拉取訊息的,
見代碼庫:com.heima.kafka.chapter3.CommitSyncInRebalance
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
consumer.subscribe(Arrays.asList(topic),newConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition>
partitions) {
// 勁量避免重復消費
consumer.commitSync(currentOffsets);
}@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
//do nothing.
}
});
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value());
// 異步提交消費位移,在發生再均衡動作之前可以通過再均衡監聽器的 onPartitionsRevoked回呼執行commitSync方法同步提交位移, currentOffsets.put(new TopicPartition(record.topic(),
record.partition()),
new OffsetAndMetadata(record.offset() + 1)); }consumer.commitAsync(currentOffsets, null);
}
} finally {
consumer.close(); }
}
1.2.5 消費者攔截器
之前章節講了生產者攔截器,對應的消費者也有相應的攔截器概念,消費者攔截器主要是在消費到訊息或者在提交消費位移時進行的一些定制化的操作,
使用場景
對消費訊息設定一個有效期的屬性,如果某條訊息在既定的時間視窗內無法到達,那就視為無效,不需要再被處理,
見代碼庫:com.heima.kafka.chapter3.ConsumerInterceptorTTL
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String>
records) {
System.out.println("before:" + records);
long now = System.currentTimeMillis();
Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords = new HashMap<>();
for (TopicPartition tp : records.partitions()) {
List<ConsumerRecord<String, String>> tpRecords =
records.records(tp);
List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<> ();
for (ConsumerRecord<String, String> record : tpRecords) {
if (now - record.timestamp() < EXPIRE_INTERVAL) { newTpRecords.add(record);
}
}
if (!newTpRecords.isEmpty()) {
newRecords.put(tp, newTpRecords);
}
}
return new ConsumerRecords<>(newRecords);
}
實作自定義攔截器之后,需要在KafkaConsumer中配置指定這個攔截器,如下
// 指定消費者攔截器 props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,ConsumerInterceptorTTL.class .getName());
效果演示
發送端同時發送兩條訊息,其中一條修改timestamp的值來使其變得超時,如下:
com.heima.kafka.chapter3.ProducerFastStart
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo-
001", "hello, Kafka!"); ProducerRecord<String, String>
record2 = new ProducerRecord<>(topic, 0, System.currentTimeMillis() - 10 * 1000,
"Kafka-demo-001", "hello, Kafka!->超時");
啟動消費端運行如下,只收到了未超時的訊息:

1.2.6 消費者引數補充
fetch.min.bytes
這個引數允許消費者指定從broker讀取訊息時最小的資料量,當消費者從broker讀取訊息時,如果資料量小于這個閾值,broker會等待直到有足夠的資料,然后才回傳給消費者,對于寫入量不高的主題來說,這個引數可以減少broker和消費者的壓力,因為減少了往返的時間,而對于有大量消費者的主題來說,則可以明顯減輕broker壓力,
fetch.max.wait.ms
上面的fetch.min.bytes引數指定了消費者讀取的最小資料量,而這個引數則指定了消費者讀取時最長等待時間,從而避免長時間阻塞,這個引數默認為500ms,
max.partition.fetch.bytes
這個引數指定了每個磁區回傳的最多位元組數,默認為1M,也就是說,KafkaConsumer.poll()回傳記錄串列時,每個磁區的記錄位元組數最多為1M,如果一個主題有20個磁區,同時有5個消費者,那么每個消費者需要4M的空間來處理訊息,實際情況中,我們需要設定更多的空間,這樣當存在消費者宕機時,其他消費者可以承擔更多的磁區.
max.poll.records
這個引數控制一個poll()呼叫回傳的記錄數,這個可以用來控制應用在拉取回圈中的處理資料量,
總結
本章主要講解了消費者和消費組的概念,以及如何正確的使用KafkaConsumer,其中重點講解了引數的配置,訂閱、反序列化、位移提交、再均衡、攔截器等知識點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233113.html
標籤:其他
上一篇:win10安裝CAD+CASS程序中出現的錯誤問題及解決辦法集錦
下一篇:遺傳演算法詳解與改良遺傳演算法