Python的排序演算法由Peter Tim提出,因此稱為TimSort,它最先被使用于Python語言,后被多種語言作為默認的排序演算法,TimSort實際上可以看作是mergeSort+binarySort,它主要是針對歸并排序做了一系列優化,如果想看Python的TimSort原始碼,在Cpython的Github倉庫能找到,這里面還包含一個List物件的PyList_Sort函式,這篇文章為了方便借用JAVA對TimSort的實作原始碼來說明其原理,
一.binarySort函式
TimSort非常適合大量資料的排序,對于少量資料的排序,TimSort選擇使用binarySort來實作,因此我想先介紹一下binarySort的程序,
我們知道插入排序的思路是通過交換元素位置的方式依次插入元素(如果不太了解插入排序可以先去熟悉一下),當要插入元素時,從已排序的部分的最后一位開始,依次比較其與待插入的元素的值,這樣來找到待插入元素的位置,顯然,在插入排序的程序中,始終是有一個在增長的有序部分和在縮短的無序部分,排序程序見下圖(圖源自RainySouL1994的博客):
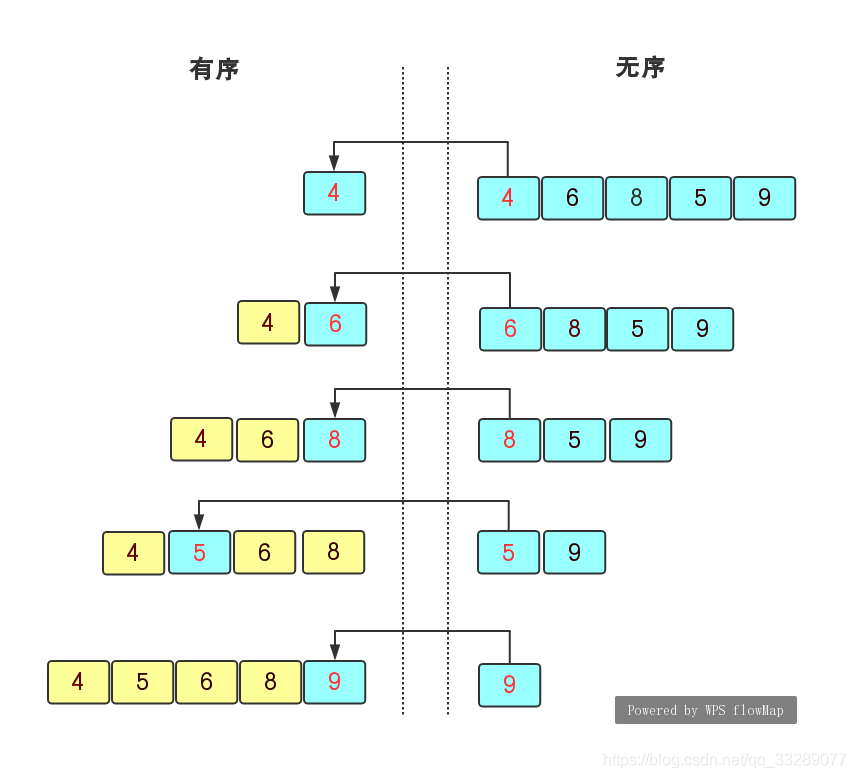
但是插入排序有個很明顯的問題,在找當前元素的位置時它是一步一步地在有序部分往前推進的,而有序串列的插入可以通過二分法來減少比較次數,這和二分查找的目的不同但是思路相同(可以自己嘗試一下實作它),我們稱其為二分插入,通過二分插入實作的排序就是二分排序(binarySort),我們可以看一下它的Java原始碼:
//a是陣列,lo是待排序部分(有序部分+無序部分)的最低位(包含),hi是最高位(不包含),start是無序部分的最低位,c是比較函式即排序的依據 private static <T> void binarySort(T[] a, int lo, int hi, int start, Comparator<? super T> c) { assert lo <= start && start <= hi; if (start == lo) start++; for ( ; start < hi; start++) {//接下來就是二分插入的程序 T pivot = a[start]; int left = lo; int right = start; assert left <= right; while (left < right) { int mid = (left + right) >>> 1; if (c.compare(pivot, a[mid]) < 0) right = mid; else left = mid + 1; } assert left == right; int n = start - left;//n表示要移動的元素數量 //優化插入程序,當要移動的元素數量為1或2時,可以直接交換元素位置; //否則將left后的元素往后挪一位再插入,方式是通過arraycopy函式復制 switch (n) { case 2: a[left + 2] = a[left + 1]; case 1: a[left + 1] = a[left]; break; default: System.arraycopy(a, left, a, left + 1, n); } a[left] = pivot; } }
二.run
這是TimSort中最重要的一個概念,實在找不到合適的翻譯(無奈臉),run實際上就是一個連續上升(包含相等)或者下降(不包含相等)的子串,比如對于陣列[1,3,2,4,6,4,7,7,3,2],其中有四個run,第一個是[1,3],第二個是[2,4,6],第三個是[4,7,7],第四個是[3,2],在函式中對于單調遞減的run會被反轉成遞增的序列,原始碼中通過countRunAndMakeAscending()函式來得到run:
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi, Comparator<? super T> c) { assert lo < hi; int runHi = lo + 1; if (runHi == hi) return 1; //找到run的結束位置,如果是下降的序列將其反轉 if (c.compare(a[runHi++], a[lo]) < 0) { while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0) runHi++; reverseRange(a, lo, runHi); } else { while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0) runHi++; } return runHi - lo;//回傳值為run的長度 }
三.TimSort排序程序
直接上原始碼分析,可以參考代碼注釋和下面的解釋來閱讀:
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c, T[] work, int workBase, int workLen) { assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length; int nRemaining = hi - lo;//待排序的陣列長度 if (nRemaining < 2) return; //長度為0或1的陣列無需排序 // 如果陣列長度小于32(即MIN_MERGE,TimSort的Python版本里這個值為64),直接用binarySort排序 if (nRemaining < MIN_MERGE) { int initRunLen = countRunAndMakeAscending(a, lo, hi, c);//找到第一個run,回傳其長度 binarySort(a, lo, hi, lo + initRunLen, c);//第一個run已排好序,因此binarySort的引數start=lo+initRunLen return; } TimSort<T> ts = new TimSort<>(a, c, work, workBase, workLen); int minRun = minRunLength(nRemaining);//最小run長度,見解釋A do { // 找run int runLen = countRunAndMakeAscending(a, lo, hi, c); // 如果run長度小于minRun,將其擴展為min(nRemaining,minRun) if (runLen < minRun) { int force = nRemaining <= minRun ? nRemaining : minRun; binarySort(a, lo, lo + force, lo + runLen, c);//擴展run到長度force runLen = force; } ts.pushRun(lo, runLen);// 將run保存到堆疊中,見解釋B ts.mergeCollapse();// 根據規則合并相鄰的run,見解釋C // 繼續尋找run lo += runLen; nRemaining -= runLen; } while (nRemaining != 0); // Merge all remaining runs to complete sort assert lo == hi; ts.mergeForceCollapse();//最后收尾,將堆疊中所有run從堆疊頂開始依次鄰近合并,得到一個run assert ts.stackSize == 1; }
解釋A:在執行排序演算法之前,會計算minRun的值,minRun會從[16,32]區間中選擇一個數字,使得陣列的長度除以minRun等于或者略小于2的冪次方,比如長度是65,那么minrun的值就是17;如果長度是174,minrun就是22,minRunLength()函式代碼如下:
private static int minRunLength(int n) { assert n >= 0; int r = 0; // 如果n的低位有任何一位為1,r就會置1 while (n >= 32) { r |= (n & 1); n >>= 1; } return n + r; }
解釋B:存run是通過兩個堆疊,分別保存run的起始位置和長度,可以看pushRun()函式代碼:
private int stackSize = 0; // 堆疊中run的數量 private final int[] runBase; private final int[] runLen; private void pushRun(int runBase, int runLen) { this.runBase[stackSize] = runBase; this.runLen[stackSize] = runLen; stackSize++; }
解釋C:這里的合并規則如下:假設堆疊頂三個run依次為X,Y,Z,X為堆疊頂run,要求它們的長度滿足X+Y<Z及X<Y兩個條件,其實這就是TimSort演算法的精髓所在了,它通過這樣的方式盡力保證合并的平衡性,即讓待合并的兩個陣列盡可能長度接近,從而提高合并的效率,通過這兩個條件限制,保證了堆疊中的run從堆疊底到堆疊頂是從大到小排列的,并且合并的收斂速度與斐波那契數列一樣,可以看mergeCollapse()函式代碼:
private void mergeCollapse() { while (stackSize > 1) { int n = stackSize - 2; if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {//條件一不滿足的話,Y就會和X、Z中較小的run合并 if (runLen[n - 1] < runLen[n + 1]) n--; mergeAt(n); } else if (runLen[n] <= runLen[n + 1]) {//條件二不滿足的話,Y就和X合并 mergeAt(n); } else { break; // Invariant is established } } }
四.合并的方式
到這里我們就把整個流程講完了,還有最后一個問題沒有講--如何合并run?合并兩個run需要額外空間(可以不用,但是效率太低),額外空間大小我們可以設為較小的run的長度,假設我們有前后X、Y兩個run需要合并,X較小,那么X可以放入臨時記憶體中,然后從小到大合并;如果Y較小,那么把Y放入臨時記憶體,然后從大到小排序,這個流程其實也比較簡單(圖源自佛西先森的博客):

并且,由于兩個run都是已經排好序的序列,我們可以在run合并之前計算A中最后一個元素在B中的位置i,那么B中i之后的元素都不需要參與合并;同理,我們也可以計算B中第一個元素在A中位置j,A中j之前的元素都不需要參與合并,
在歸并排序演算法中合并兩個陣列就是一一比較每個元素,把較小的放到相應的位置,然后比較下一個,這樣有一個缺點就是如果A中如果有大量的元素A[i...j]是小于B中某一個元素B[k]的,程式仍然會持續的比較A[i...j]中的每一個元素和B[k],增加合并程序中的時間消耗,
為了優化合并的程序,TimSort設定了一個閾值MIN_GALLOP,如果A中連續MIN_GALLOP個元素比B中某一個元素要小,則通過二分搜索找到A[0]在B中的位置i0,把B中i0之前的元素直接放入合并的空間中,然后再在A中找到B[i0]所在的位置j0,把A中j0之前的元素直接放入合并空間中,如此回圈直至在A和B中每次找到的新的位置和原位置的差值是小于MIN_GALLOP的,這才停止然后繼續進行一對一的比較,
五.總結
總結一下上面的排序的程序:
- 如果長度小于32直接進行二分插入排序
- 遍歷陣列組成一個
run - 得到一個
run之后會把他放入堆疊中 - 如果堆疊頂部幾個的
run符合合并條件,就會合并相鄰的兩個run - 合并會使用盡量小的記憶體空間和GALLOP模式來加速合并
參考資料:1.世界上最快的排序演算法——Timsort
2.JDK8官方原始碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233444.html
標籤:其他
上一篇:手寫玩具 - 快速排序