本文已收錄至 Github(MD-Notes),若博客中圖片模糊或打不開,可以來我的 Github 倉庫,包含了完整圖文:https://github.com/HanquanHq/MD-Notes,涵蓋了互聯網大廠面試必問的知識點,講解透徹,長期更新中,歡迎一起學習探討 ~
更多內容,可以訪問:
面試必會系列專欄:https://blog.csdn.net/sinat_42483341/category_10300357.html
作業系統系列專欄:https://blog.csdn.net/sinat_42483341/category_10519484.html
目錄
- MySQL
- MySQL 基本架構
- 連接器
- 查詢快取
- 分析器
- 優化器
- 執行器
- 存盤引擎
- 零碎知識點
- 區域性原理
- 時間、空間區域性
- 磁盤預讀
- MySQL 日志有多少種?
- Undolog 回滾日志
- Redolog 物理日志
- undolog 的原理?是否需要落盤?
- MySQL有多少種鎖?
- 使用自定義變數
- 磁區表
- 存盤引擎
- 事務
- 事務的 ACID
- 事務的實作原理
- Atomicity 原子性:undolog
- Consistency 一致性(資料庫的根本追求)
- Isolation 隔離性
- Durability 持久性:redolog + binlog
- 思想:WAL日志(Write Ahead Log,預寫日志)
- 采用 redo log 的好處?
- 三種資料溢寫到磁盤的程序
- 資料更新的流程?redo的兩階段提交
- 資料更新的執行流程
- 鎖
- MyIsam
- Innodb
- OLTP,OLAP
- MySQL 索引實作原理
- 不同存盤引擎的資料檔案
- 聚簇索引就是主鍵索引嗎?
- Innodb 采用自適應哈希:
- 擾動函式(Java HashMap相關的,自己看一下吧)
- MySQL B+ 樹資料結構推導
- 哈希表
- 普通二叉樹
- BST Tree(二叉排序樹)
- AVL 樹(二叉平衡樹)
- RBTree (紅黑樹)
- 為什么使用 B / B+ 樹?
- 為什么推薦使用自增的 int 型別作為主鍵?
- 不同存盤引擎的資料結構
- B 樹
- B+ 樹
- 索引分類
- 1、按照索引的存盤來劃分:簇族索引、非簇族索引
- 2、按照使用來分:
- 回表 & 覆寫索引
- 索引下推
- 1、沒有索引下推的情況
- 2、有索引下推的情況
- 3、總結
MySQL
MySQL 基本架構
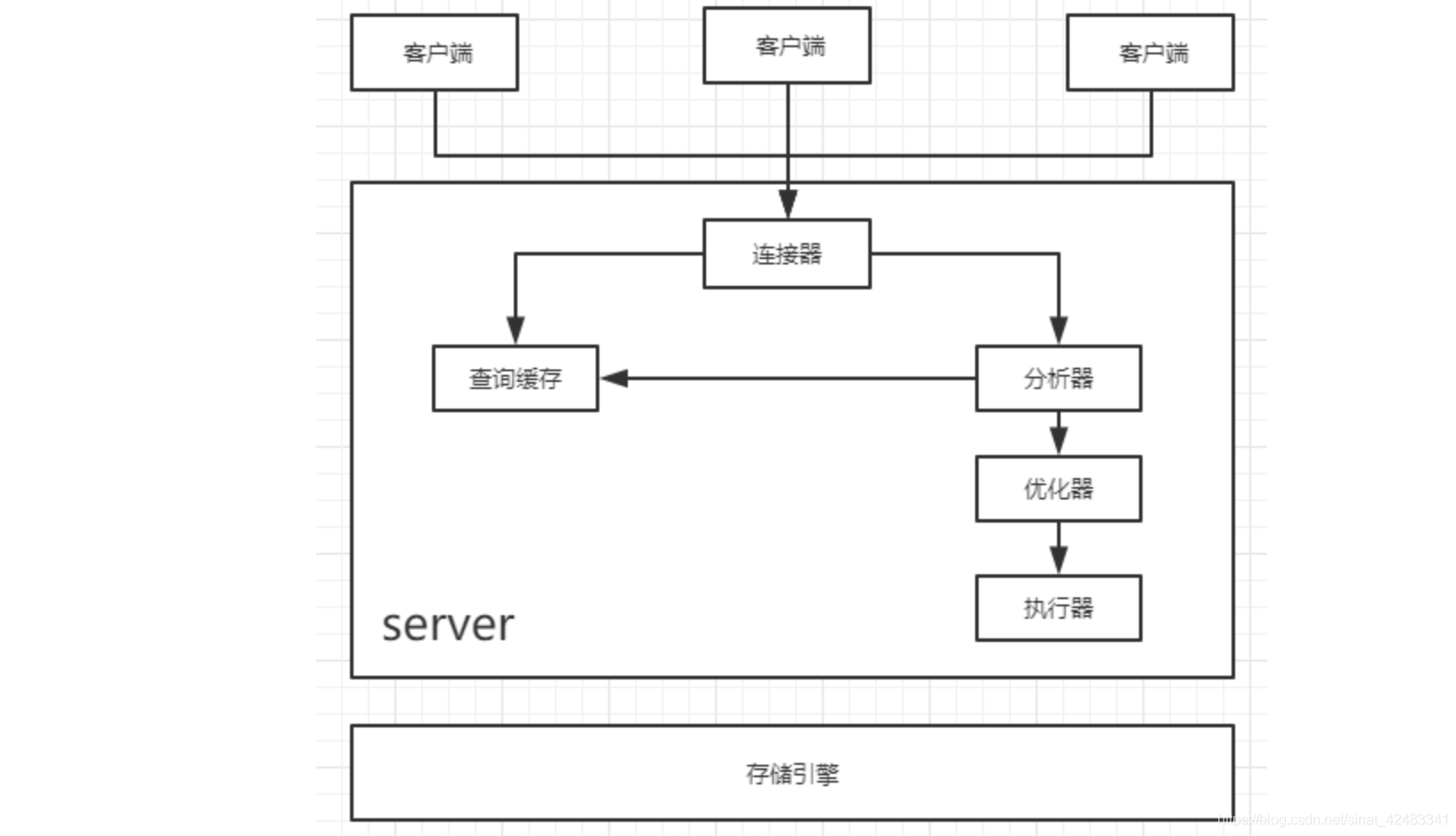
連接器
-
負責和客戶端建立連接,獲取權限,維持和管理連接
- 用戶名密碼驗證
- 查詢權限資訊,分配對應的權限
- 可以使用show processlist查看現有的連接
- wait_timeout默認8小時,超時會斷開連接
-
連接分為兩類
- 長連接:推薦使用,但是要周期性的斷開長連接
- 短鏈接:一次執行完畢就關閉,比較消耗資源
查詢快取
- 當執行查詢陳述句的時候,會先去查看快取中的結果,之前執行過的SQL陳述句會以類似于key-value的形式存在快取中,如果能找到就回傳,找不到繼續執行,
- 不推薦使用快取:
- 查詢快取失效比較頻繁,只要表更新,快取就會清空
- 快取對應更新的市局命中率低
分析器
- 詞法分析:Mysql需要把輸入的字串進行識別和翻譯
- 語法分析:語法決議,并判斷是否符合規范
優化器
-
執行具體的SQL之前先進行優化
- 索引優化
- 條件順序優化
- 關聯表順序優化
- …
-
不同的執行方式對效率影響很大
- RBO:基于規則的優化
- CBO:基于成本的優化
執行器
操作引擎,回傳結果
存盤引擎
存盤資料,提供讀寫介面
零碎知識點
區域性原理
時間、空間區域性
資料和程式的存盤,都有聚集成群的傾向,相關關聯的資料可能被放在一起,同時,之前查詢過的資料,短時間內可能再次被查詢,
磁盤預讀
當記憶體和磁盤發生互動的時候,是以一個邏輯單元 “頁” 為單位進行互動的,“頁”是磁盤和記憶體互動的最小單位,一般是 4k 或 8k,讀取的時候可以以頁為單位,也可以是頁的整數倍,
SSD 4K 對齊,能夠加快查詢效率
MySQL 日志有多少種?
binlog, undolog, redolog, relaylog(主從復制), errorlog, slowlog 等
-
所有存盤引擎,都有 binlog,errorlog,relaylog,slowlog
-
Innodb 存盤引擎,有 binlog, undolog, redolog
-
MyISAM 不支持事務,沒有 undolog, redolog,只有 binlog
Undolog 回滾日志
Redolog 物理日志
innodb存盤引擎的日志檔案,
-
redolog是物理日志,記錄的是在某個資料頁上做了什么修改
- 當發生資料修改的時候,innodb存盤引擎會先將記錄寫到redo_log中,并更新記憶體,此時更新就算是完成了,同時INNODB會在合適的時機將記錄存盤操做到磁盤中,
- redo_log是由固定大小的,是一個回圈寫的程序
- 有了redo_log之后,innodb可以保證資料庫例外之后重啟,之前的資料記錄不會丟失,叫做crash-safe
-
binlog是邏輯日志,記錄的是這個陳述句的原始邏輯,比如給ID=2這一行的c欄位加1;
有且僅有兩個檔案,是一個回圈寫的程序,

不知道你是否記得《孔乙己》這篇文章,酒店掌柜有一個粉板,專門記錄客人的賒賬記錄,如果賒賬的人不多,他可以將賒賬的人姓名和賬目寫在板上,但是如果賒賬的人太多,粉板總會有記不下的時候,這時候掌柜還有一個專門記錄賒賬的賬本,
如果有人要賒賬或者還賬的時候,掌柜一般有兩種方法:
1、一種直接將賬本翻出來,把這次賬加上或者洗掉
2、先在粉板上記下這次賬,等打烊后再把賬本翻出來核算
在生意很忙時,掌柜應該選擇后者,第一種方法實在太麻煩了,極大的影響作業效率,
同樣,在MySQL里也有這個問題,如果每一次更新操作都寫進磁盤,然后磁盤找到對應的那條記錄,然后再更新,整個程序的IO成本,查找成本都很高,為了解決這個問題,MySQL的設計者就用了類似酒店掌柜粉板的思路來提升作業效率,
粉板和賬本配合的程序,其實就是MySQL里面經常說到的WAL技術,WAL技術全稱是Write-Ahead Logging.他的關鍵點就是先寫日志,再寫磁盤,
具體來說,當有一條日志需要更新的時候,InnoDB 會先把日志寫到 redo log(粉板)中,并更新記憶體,這個時候更新就算完成了,同時,InnoDB 會在適當的時候將這個操作記錄到磁盤中,這個更新往往實在系統比較空閑的時候,這就像打樣以后掌柜做的事,
如果今天賒賬的不多,掌柜可以打烊后再整理,但是某天賒賬的非常多,粉板寫滿了,又怎么辦呢?這個時候掌柜只好放下手中的事,將粉板上的賬整理到賬本上,再將粉板擦掉,為記錄新的賒賬騰出空間,
與此類似,InnoDB 的 redo log 是固定大小的,比如可以配置為一組四個檔案,每個檔案的大小是1G,那么這塊粉板共有4G的空間,從頭開始寫,寫到末尾又回到開頭回圈寫,如下圖所示:
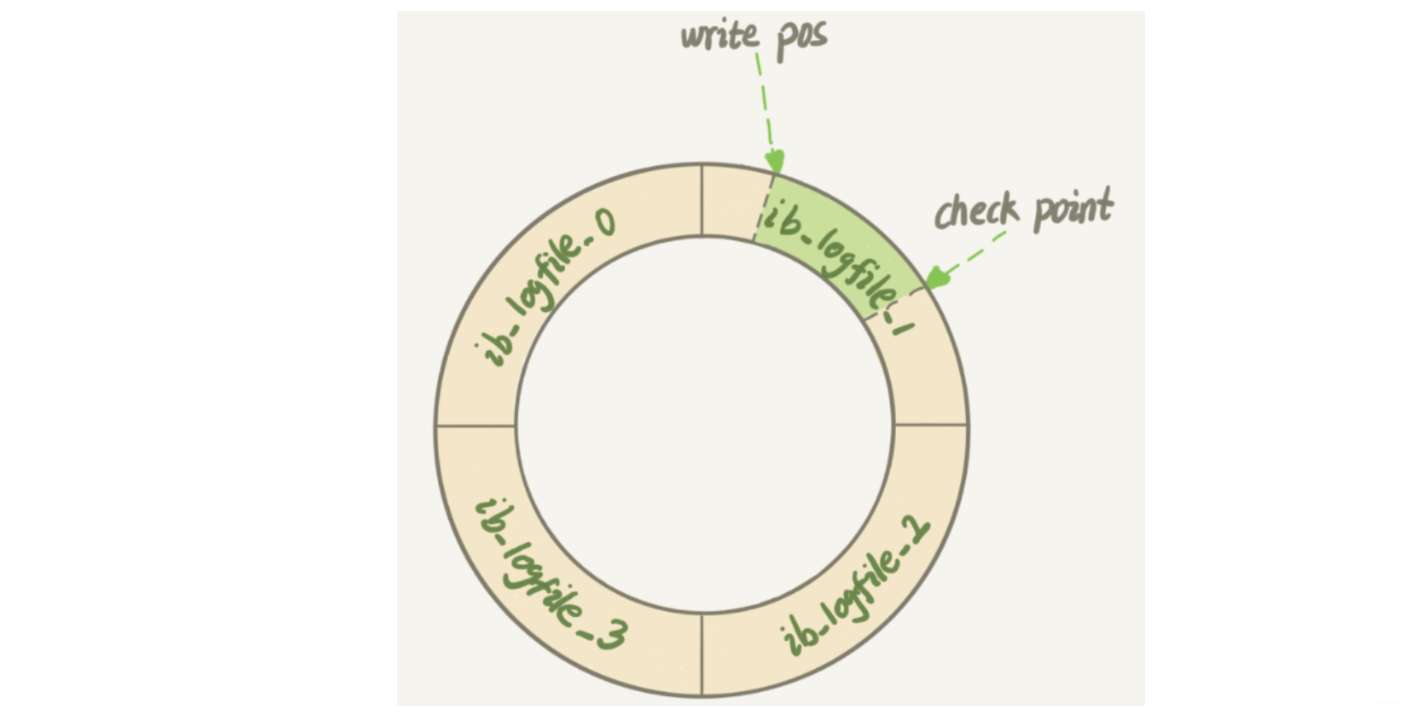
write pos 是當前記錄的位置,一邊寫一邊后移,寫到第3號檔案的末尾就回到0號檔案開頭,checkpoint 是當前要擦除的位置,也是往后推移并且魂環的,擦除記錄前要將記錄更新到資料檔案,
wirte 和 checkpoint 之間是粉板空著的部分,可以用來記錄新的操作,如果 write pos 追上 checkpoint,表示粉板滿了,這個時候就不能執行新的更新操作,要先停下來擦掉一些記錄,把checkpoint推進一下,
有了redo-log,InnoDB就可以保證即使資料庫發生例外重啟,之前提交的記錄就不會丟失,這個能力成為crash-safe,
要理解crash-safe這個概念,可以想想賒賬的例子,只要賒賬記錄記在粉板上或者寫在賬本上,之后即使掌柜忘記了,比如停業幾天,恢復生意后依然可以通過賬本和粉板上的資料明確賒賬數目,
undolog 的原理?是否需要落盤?
innodb通過force log at commit機制實作事務的持久性,即在事務提交的時候,必須先將該事務的所有事務日志寫入到磁盤上的 redo log file 和 undo log file 中,進行持久化,
undo日志會記錄事務執行程序中,每次修改的資料的原始值,
x = 5, y = 8
t1 begin:
// undo日志記錄x=5
x = x - 1;
// undo日志記錄y=8
y = y - 2;
// 事務執行臨近結束,將 undolog 寫入到磁盤
// 將資料寫入到磁盤
commit
每次進行事務修改之前,把未修改之前的值存盤到 undo 日志中,提交的時候,先將 undo 寫到磁盤,再把修改后的資料寫到磁盤,
若undo寫入磁盤之前發生了例外,根本就不需要做任何操作,這時候事務是被認為執行失敗的,也不需要回滾,因為undo日志沒有寫入磁盤,資料庫被認為處于沒有執行事務的狀態,
MySQL有多少種鎖?
共享鎖,排它鎖,獨占鎖,間隙鎖,臨鍵鎖,自增鎖,意向鎖
MVCC:multi version concurrency control 多版本并發控制,通過保存資料在某個時間點的快照來實作的,在同一個事務里能夠看到資料一致的視圖,
排它鎖怎么加?query for update
共享鎖怎么加?lock in share mode
WAL:Write Ahead Log 溢寫日志
使用自定義變數
在給一個變數賦值的同時,使用這個變數
select actor_id, @rounum:=@rownum+1 as rownum from actor limit 10;
磁區表
創建表時使用 partition by 子句定義每個磁區存放的資料,在執行查詢的時候,優化器會根據磁區定義過濾那些沒有我們需要資料的磁區,這樣查詢就無須掃描所有磁區,
存盤引擎
- innodb
- 有 redolog, undolog
- 簇族索引
- myisam
- 非簇族索引
- 不支持事務
- memory
- 資料在記憶體中,有持久化檔案
- 默認使用哈希索引
事務
- 資料庫事務
- spring 宣告式事務:spring 提供了一個類,由這個類以 AOP 的方式管理,只需要
@Transactional即可 - 分布式事務
事務的 ACID
事務的實作原理
事務的原子性,是通過 undo log 來實作的
事務的持久性,是通過 redo log 來實作的
事務的隔離性,是通過 (讀寫鎖+MVCC)來實作的
事務的一致性,是通過原子性,持久性,隔離性來實作的!!!
Atomicity 原子性:undolog
innodb 默認頁 16k
-
事務中的所有操作作為一個整體,像原子一樣不可分割(原子性),要么全部執行成功,要么全部失敗
-
使用 undolog 邏輯日志實作回滾
-
Undo Log 是為了實作事務的原子性,在 MySQL 資料庫 InnoDB 存盤引擎中,還用 Undo Log 來實作 MVCC 多版本并發控制,記錄原來資料的歷史版本
-
在操作任何資料之前,首先將資料備份到一個地方(這個存盤資料備份的地方稱為Undo Log),然后進行資料的修改,如果出現了錯誤或者用戶執行了ROLLBACK陳述句,系統可以利用Undo Log中的備份將資料恢復到事務開始之前的狀態
注意:undo log 是邏輯日志,可以理解為(僅理解,實際并不是這樣的):
(區分邏輯日志、物理日志,只需要看頁是否被修改,邏輯日志 是只對當前的 sql 陳述句做一條記錄,而 物理日志 是對日志所在物理頁 page 做修改)當delete一條記錄時,undo log中會記錄一條對應的insert記錄
當insert一條記錄時,undo log中會記錄一條對應的delete記錄
當update一條記錄時,它記錄一條對應相反的update記錄如果某一次操作失敗了,就去執行這些相反的邏輯陳述句,將資料恢復到上一次的一致性狀態,
-
Consistency 一致性(資料庫的根本追求)
一致性分類:強一致性、弱一致性、最終一致性
在事務的四個特點中,一致性是事務的根本追求,事務執行的結果必須使資料庫從 一個永久的一致性狀態 轉變到 另一個永久的一致性狀態,如果事務被迫中斷,不應該有一部分被寫入物理資料庫,例如,轉賬前后,兩個賬戶的總金額應該保持不變,而在某些情況下,會對事務的一致性造成破壞:
-
事務的并發執行
-
事務故障或系統故障
資料庫系統通過并發控制技術和日志恢復技術,來避免這種情況的發生
-
并發控制技術保證了事務的隔離性,使資料庫的一致性狀態不會因為并發執行的操作被破壞,
-
日志恢復技術保證了事務的原子性,使一致性狀態不會因事務或系統故障被破壞,同時使已提交的對資料庫的修改不會因系統崩潰而丟失,保證了事務的持久性,
Isolation 隔離性
-
使用 鎖機制 實作
-
并發環境中,并發的事務是相互隔離的,并發執行的事務之間不能相互干擾
-
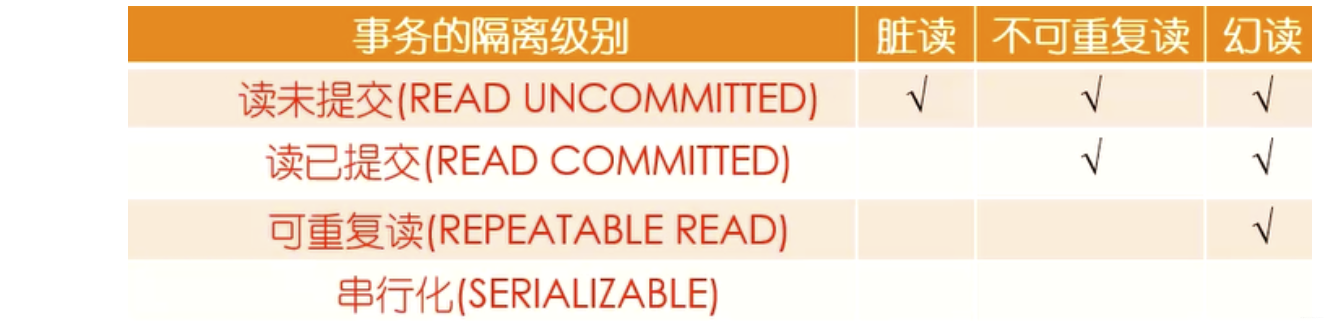
隔離級別:假設 A,B 都開啟了事務
- 讀未提交(未授權讀取):即使A事務未提交,B事務也能看到A的修改
- 讀已提交(授權讀取):A事務提交后,B事務中才能看到A的修改
- 可重復讀:無論A怎么修改,事務B在事務期間都不會看到A的修改
- 串行化:所有事物只能一個接一個處理,不能并發執行
(要能夠模擬臟讀、幻讀、不可重復讀的情況)
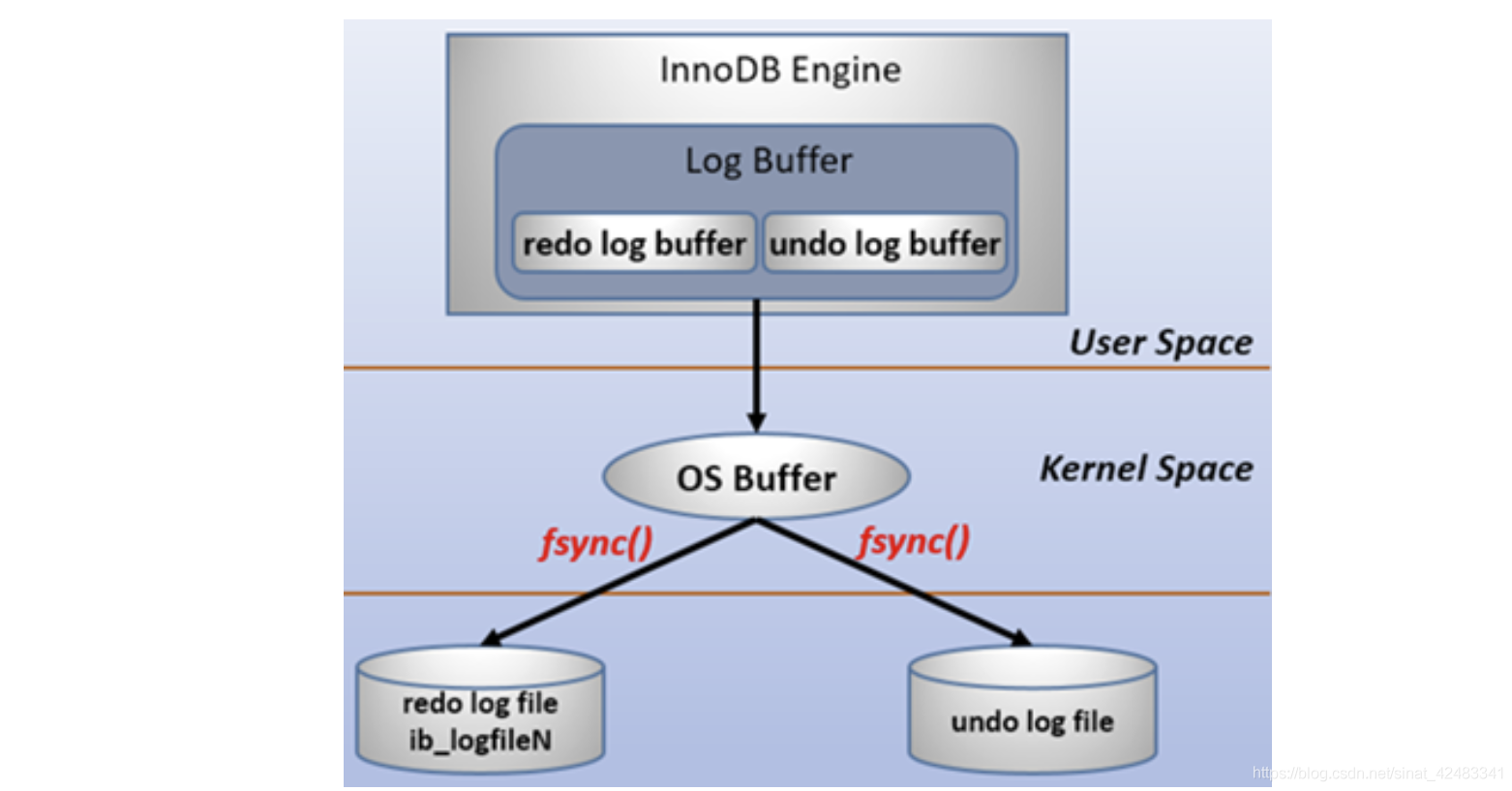
Durability 持久性:redolog + binlog
我們知道,寫資料的時候,資料會先存在用戶空間記憶體中,然后由作業系統內核呼叫 fsync,才真正寫入到磁盤,如果此時突然宕機,記憶體中的資料就會丟失,怎么解決這個問題?
事務提交前直接把資料寫入磁盤就行啊,這么做有什么問題?只修改一個頁面里的一個位元組,就要將整個頁面刷入磁盤,太浪費資源了,畢竟一個頁面16kb大小,你只改其中一點點東西,就要將16kb的內容刷入磁盤,聽著也不合理,畢竟一個事務里的SQL可能牽涉到多個資料頁的修改,而這些資料頁可能不是相鄰的,也就是屬于隨機IO,顯然操作隨機IO,速度會比較慢,
思想:WAL日志(Write Ahead Log,預寫日志)
采用 redo log 解決上面的問題,當做資料修改的時候,不僅在記憶體中操作,還會在redo log中記錄這次操作,當事務提交的時候,將redo log日志進行刷盤持久化即可(redo log一部分在記憶體中,一部分在磁盤上),不需要將資料持久化,當資料庫宕機重啟的時候,雖然資料沒有持久化,但是可以根據 redo log 中的內容,將資料恢復到資料庫中,再根據 undo log 和 binlog 內容決定回滾資料還是提交資料,
采用 redo log 的好處?
redo log 進行刷盤比對資料頁刷盤效率高
- redo log體積小,畢竟只記錄了哪一頁修改了啥,因此體積小,刷盤快,
- redo log是一直往末尾進行追加,屬于順序IO,效率顯然比隨機IO來的快,
- 事務一旦提交,資料必須永久保存,即使宕機,重啟后也能恢復到事務成功結束時的狀態
- 使用 redolog 兩階段提交實作,事務提交前,需要將 redolog 持久化,系統崩潰時,雖然資料沒有持久化,但是可以根據 redolog 的內容,將資料恢復到最新的狀態,
- redolog 大小是固定的,相當于一個增量存盤,redolog 滿了之后,會進行持久化的同步歸檔,然后將redolog清空,
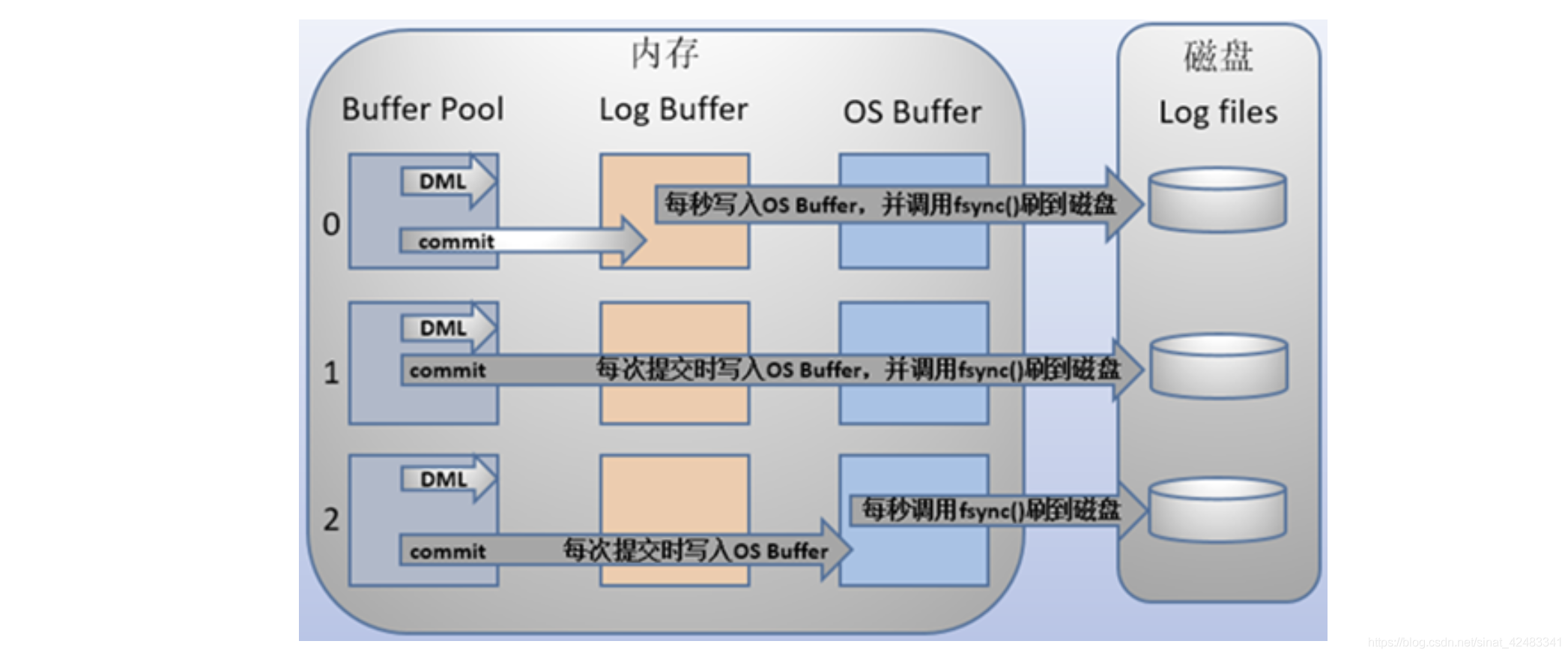
三種資料溢寫到磁盤的程序
- 效率最高,只要 redolog 寫成功了,斷電也沒關系
- 最安全
- 與 1 相比更安全,如果 MySQL 行程掛了,資料不會丟失,作業系統會繼續處理寫資料
資料更新的流程?redo的兩階段提交
事實分析先寫redolog后寫binlog和先寫binlog后寫redolog都會有資料不一致的風險,
因此,采用兩階段提交,具體流程如下:
資料更新的執行流程
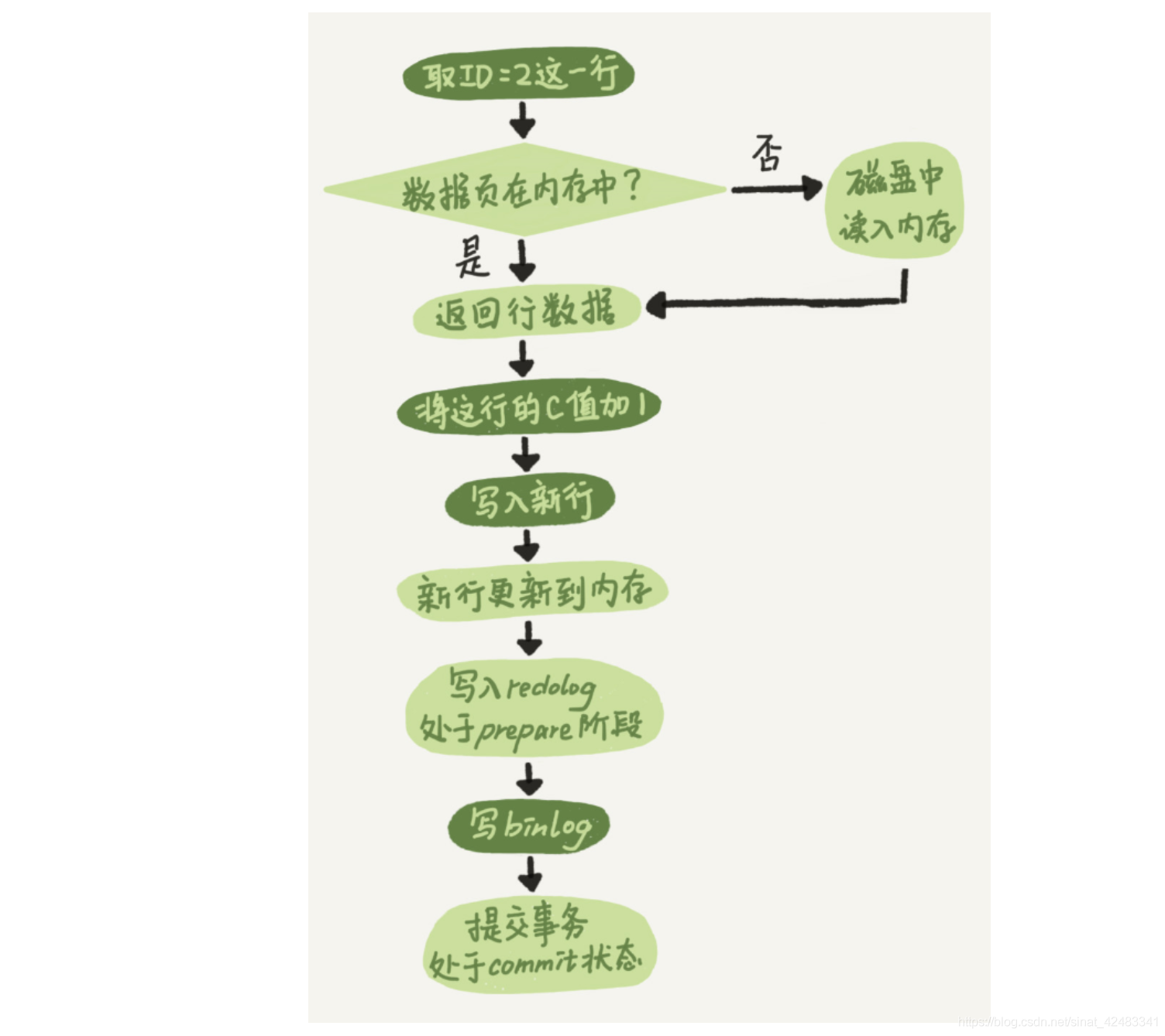
-
執行器先從存盤引擎找到資料,如果在記憶體中直接回傳,不在記憶體中查詢回傳
-
執行器拿到資料后會先修改資料,然后呼叫引擎介面重新吸入資料
-
引擎將資料更新到記憶體,同時寫資料到redo中,此時處于prepare階段,并通知執行器執行完成
-
執行器生成這個操作的binlog
-
執行器呼叫引擎的事務提交介面,引擎把剛寫完的redo改為commit狀態
-
更新完成
使用 兩階段提交的優勢 是:可以保證 binlog 和 redolog 的資料一致(先寫 redolog 或者先寫 binlog 都無法保證突然宕機時的資料一致性),如果資料庫發生了意外情況,宕機、斷點、重啟等等,可以保證使用 BinLog 恢復資料和當時資料狀態一致,具體情況下的策略如下:
- binlog有記錄,redolog狀態commit:正常完成的事務,不需要恢復
- binlog有記錄,redolog狀態prepare:在binlog寫完提交事務之前的crash,恢復操作:提交事務
- binlog無記錄,redolog狀態prepare:在binlog寫完之前的crash,恢復操作:回滾事務
- binlog無記錄,redolog無記錄:在redolog寫之前crash,恢復操作:回滾事務
鎖
- 共享鎖
- 排它鎖
- 獨占鎖
- 臨鍵鎖
- 間隙鎖
- 自增鎖
- 意向鎖
MyIsam
只能鎖表
- 共享讀鎖
- 獨占寫鎖
Innodb
支持表鎖,行鎖,實質上鎖的是索引,如果沒有索引的話,退化成為表鎖,
- 共享鎖(s),又稱讀鎖
- 排它鎖(x),又稱寫鎖
OLTP,OLAP
OLTP:聯機事務處理,在盡可能短的時間內回傳對應的結果值,例如我們常用的關系型資料庫,
OLAP:聯機分析處理,Hive,主要是對歷史資料的分析,用于做出決策;常用于資料倉庫,不支持范圍查詢,插入新資料要重排?
區別在于時效性,在很短的時間內回傳結果,
MySQL 索引實作原理
索引是和存盤引擎相關聯的,所謂存盤引擎,指的是資料在磁盤上的不同組織形式,
Memory 存盤引擎使用 Hash 索引,
不同存盤引擎的資料檔案
I nnodb:包括 frm(表結構),ibd(索引+資料放在一起,聚簇索引) 檔案
MyISAM:包括 frm,myd,myi 檔案,非聚簇索引
聚簇索引就是主鍵索引嗎?
不一定是,
- 如果你建表時不指定主鍵,innodb會選擇 唯一鍵 創建索引,
- 如果沒有唯一鍵的話,會生成一個 6 位元組的 row_id 作為主鍵,
Innodb 采用自適應哈希:
當給 colA 建 立B+tree 索引的時候,這棵 B+ tree 會有個三四層,通過 colA = ‘xxx’ 會在樹里查詢 3、4 次才能查到,所以這里如果開啟了自適應索引,就利用 buffer pool 來給 colA 建立一個哈希索引,這樣就只用在哈希索引里查 1 次,不用在 B+ tree 里查詢 3、4 次,加快了速度,
擾動函式(Java HashMap相關的,自己看一下吧)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
目的是為了減少hash沖突,
MySQL B+ 樹資料結構推導
哈希表
哈希演算法應該你可能多的案列,讓資料分布均勻,使用擾動函式,減少hash沖突;對記憶體占用比較高;檢索時無法進行范圍查詢,如果范圍查詢,必須逐個對比,相當耗費時間,
MySQL用到了哈希表嗎?Memory 存盤引擎使用的索引資料結構就是哈希表;Innodb使用自適應哈希,
普通二叉樹
查詢效率太低,需要遍歷整個樹
BST Tree(二叉排序樹)
有序,左子樹<根節點<右子樹,遞增插入會退化成鏈表,是因為樹不夠平衡
AVL 樹(二叉平衡樹)
最短子樹和最長子樹高度之差不能超過1,是嚴格意義上的平衡樹,在插入資料的時候要進行旋轉操作來保證平衡,會損失部分插入性能,從而帶來查詢性能的提升
RBTree (紅黑樹)
非嚴格的平衡樹,最長路徑不超過最短路徑的兩倍,近似取得了插入和查詢性能的平衡,
為什么使用 B / B+ 樹?
以上的“二叉”樹都會越來越深,每一個節點中只能存一個元素,如果資料節點很多,查找的時候,需要進行多次 IO 互動,應該盡量在 4k 中存盤盡可能多的資料節點,
B / B+ 樹的每一個節點中可以有多個元素,采用有序、多分支的方式,解決二叉樹的這些弊端,
為什么推薦使用自增的 int 型別作為主鍵?
int 型別 相比 varchar,占用的索引空間比較小
自增可以直接追加在最后面,減少樹的頁分裂、合并帶來的維護成本
不同存盤引擎的資料結構
Innodb 默認使用 B-tree,根據官網檔案,Memory tables 也支持哈希索引,
Hash劣勢:rehash,哈希沖突問題,不好的hash演算法導致散列不均勻,浪費磁盤空間,
jdk 1.8 的哈希函式演算法使用了擾動函式,也是為了讓散列更均勻
| 索引 | MyISAM引擎 | InnoDB引擎 | Memory引擎 |
|---|---|---|---|
| B-Tree索引 | 支持 | 支持 | 支持 |
| HASH索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 支持 | 不支持 | 不支持 |
| Full-text索引 | 支持 | 不支持 | 不支持 |
B 樹
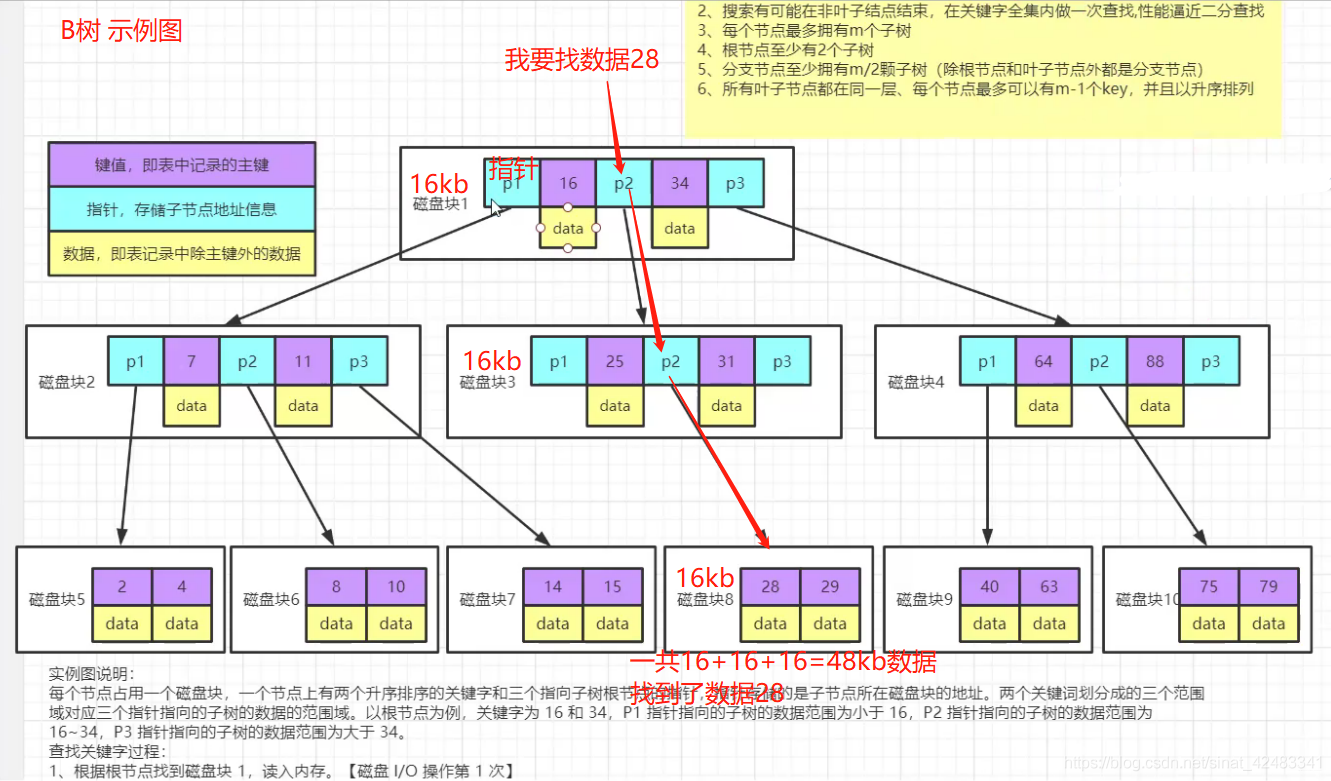
實體圖說明:

B+ 樹
每個節點可以包含多個元素,有 n 棵子樹的節點中含有 n 個關鍵字,每個關鍵字不保存資料,只用來索引,
非葉子結點只存盤 key,不存盤資料,所有 資料都放在葉子結點 中存盤,是為檔案系統而生的,
B+Tree是在B Tree的基礎之上做的一種優化,變化如下:
- B+Tree每個節點可以包含更多的節點,這么做的原因有兩個,一個原因是為了降低樹的高度,第二個原因是將資料范圍變為多個區間,區間越多,資料檢索越快
- 非葉子節點存盤key,葉子節點存盤key和資料
- 葉子節點兩兩指標相互連接(符合磁盤預讀性),順序查詢性能更高
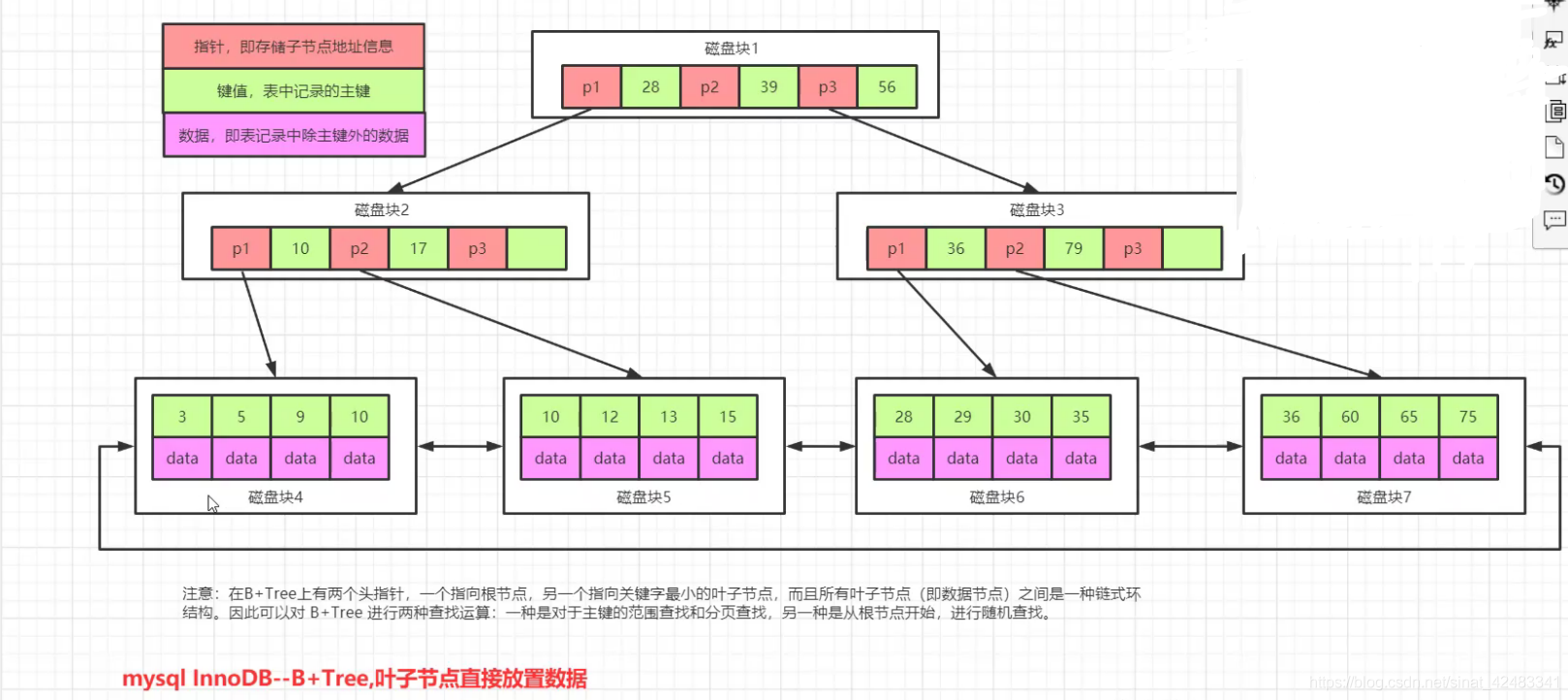
索引分類
1、按照索引的存盤來劃分:簇族索引、非簇族索引
聚簇索引:innodb 資料和索引放在一起,如果不設主鍵,innodb 會選擇一個唯一鍵,如果沒有唯一鍵,innodb會生成一個 6 位元組的 rowid 存盤,對用戶是不可見的,因此,聚簇索引不一定是主鍵索引,
非聚簇索引:資料和索引不放在一起,myisam
2、按照使用來分:
主鍵索引:主鍵所關聯的資料
唯一索引:mysql 默認會給唯一鍵添加索引
普通索引:用來加速資料訪問速度而建立的索引,多建立在經常出現在查詢條件的欄位和經常用于排序的欄位,普通索引是非聚簇索引,葉子存放的是對應主鍵id值,
另外,如果主鍵是創建表之河駁加的,新建立的主鍵的索引使用的不是主鍵索引,而是在葉子上去關聯原來默認的 rowid,因此,innodb 的主鍵索引也不一定是聚簇索引,
回表 & 覆寫索引
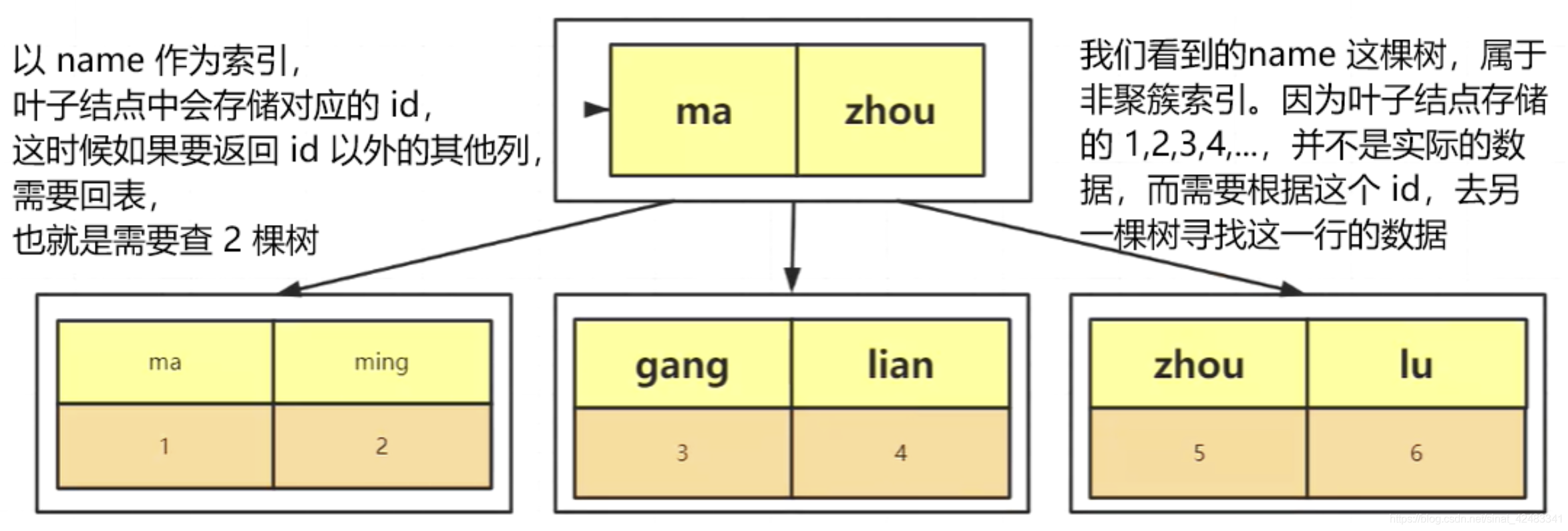
回表:通過普通索引去樹中查找,會 回傳主鍵值,再 **根據主鍵 **去索引樹查找資料,
select id, age from test where name = '張三';
覆寫索引:執行計劃能看到 using index,通過檢索索引就可以讀取想要的資料,那就不需要再到資料表中讀取行了,也就是不需要回表,
select id, name from test where name = '張三';
索引下推
假設有這么個需求,查詢表中“名字第一個字是張,性別男,年齡為10歲的所有記錄”,那么,查詢陳述句是這么寫的:
mysq> select * from tuser where name like '張%' and age=10 and ismale=1;
根據前面說的“最左前綴原則”,該陳述句在搜索索引樹的時候,只能匹配到名字第一個字是‘張’的記錄(即記錄ID3),接下來是怎么處理的呢?當然就是從ID3開始,逐個回表,到主鍵索引上找出相應的記錄,再比對age和ismale這兩個欄位的值是否符合,
但是!MySQL 5.6引入了索引下推優化,可以在索引遍歷程序中,對索引中包含的欄位先做判斷,過濾掉不符合條件的記錄,減少回表字數,
1、沒有索引下推的情況
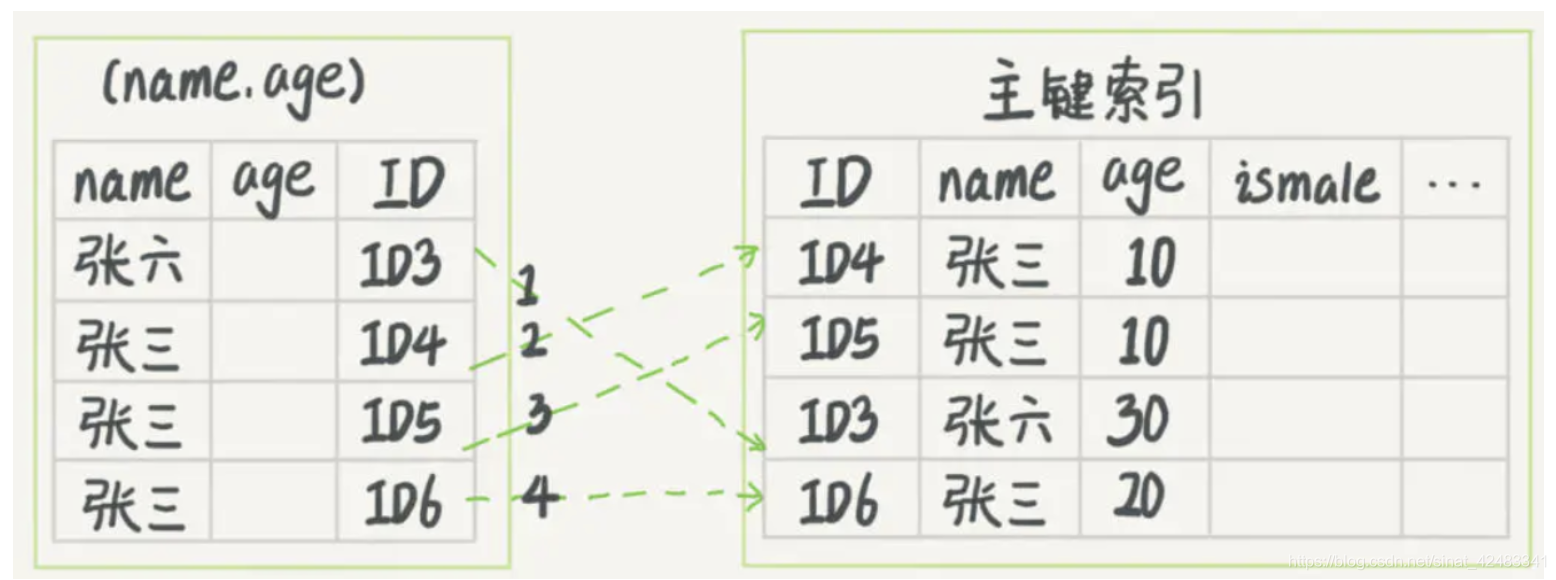
圖 1 中,在 (name,age) 索引里面,我特意去掉了 age 的值,因為 這個程序 InnoDB 并不會去看 age 的值,只是按順序把“name 第一個字是’張’”的記錄一條條取出來回表,因此,需要回表 4 次,
2、有索引下推的情況
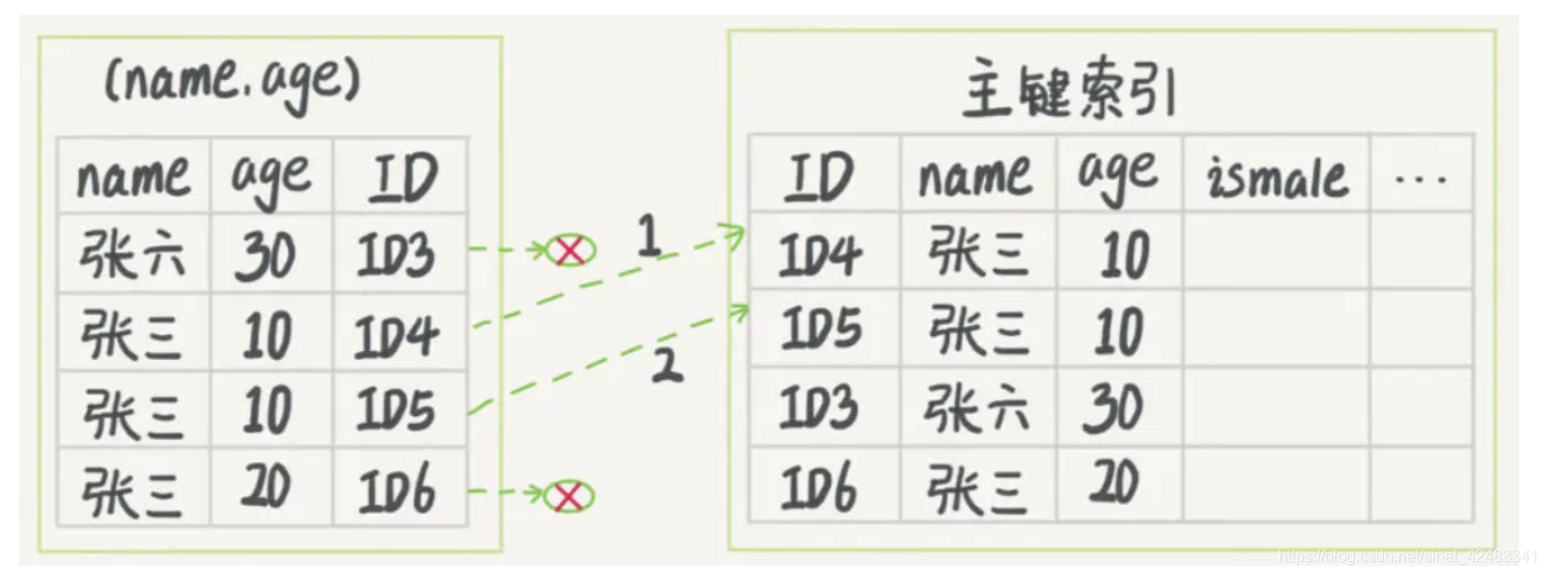
圖 2 跟圖 1 的區別是,InnoDB 在 (name,age) 索引內部就判斷了 age 是否等于 10,對于不等于 10 的記錄,直接判斷并跳過,在我們的這個例子中,只需要對 ID4、ID5 這兩條記錄回表取資料判斷,就只需要回表 2 次,
3、總結
如果沒有索引下推優化(或稱ICP優化),當進行索引查詢時,首先根據索引來查找記錄,然后再根據where條件來過濾記錄;在支持ICP優化后,MySQL會在取出索引的同時,判斷是否可以進行where條件過濾再進行索引查詢,也就是說提前執行where的部分過濾操作,在某些場景下,可以大大減少回表次數,從而提升整體性能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233608.html
標籤:其他
下一篇:k8s集群搭建步驟(全)