寫在前面:博主是一只經過實戰開發歷練后投身培訓事業的“小山豬”,昵稱取自影片片《獅子王》中的“彭彭”,總是以樂觀、積極的心態對待周邊的事物,本人的技術路線從Java全堆疊工程師一路奔向大資料開發、資料挖掘領域,如今終有小成,愿將昔日所獲與大家交流一二,希望對學習路上的你有所助益,同時,博主也想通過此次嘗試打造一個完善的技術圖書館,任何與文章技術點有關的例外、錯誤、注意事項均會在末尾列出,歡迎大家通過各種方式提供素材,
- 對于文章中出現的任何錯誤請大家批評指出,一定及時修改,
- 有任何想要討論和學習的問題可聯系我:zhuyc@vip.163.com,
- 發布文章的風格因專欄而異,均自成體系,不足之處請大家指正,
Hadoop全分布式部署 - CentOS
本文關鍵字:Hadoop、全分布式、安裝部署、CentOS
文章目錄
- Hadoop全分布式部署 - CentOS
- 一、Hadoop介紹
- 1. Hadoop發展史及生態圈
- 2. Hadoop核心功能及優勢
- 3. 部署方式介紹
- 二、Hadoop下載
- 1. 下載地址
- 2. 版本選擇
- 3. 安裝包下載
- 三、安裝步驟
- 1. 前置環境
- 2. Hadoop安裝
- 3. Hadoop配置
- 4. SSH相關操作
- 5. 集群啟動及確認
一、Hadoop介紹
Hadoop軟體庫是一個計算框架,可以使用簡單的編程模型以集群的方式對大型資料集進行分布式處理,
1. Hadoop發展史及生態圈
- Hadoop起源于Apache Nutch專案,始于2002年,是Apache Lucene的子專案之一,
- 2006年2月,成為一套完整而獨立的軟體,并被命名為Hadoop,
- 2008年1月,Hadoop成為Apache頂級專案,
- 2009年7月,MapReduce和HDFS成為Hadoop的獨立子專案,
- 2010年5月,Avro脫離Hadoop專案,成為Apache頂級專案,
- 2010年5月,HBase脫離Hadoop專案,成為Apache頂級專案,
- 2010年9月,Hive脫離Hadoop專案,成為Apache頂級專案,
- 2010年9月,Pig脫離Hadoop專案,成為Apache頂級專案,
- 2011年1月,Zookeeper脫離Hadoop專案,成為Apache頂級專案,
- 2011年12月,Hadoop 1.0.0版本發布,
- 2012年10月,Impala加入Hadoop生態圈,
- 2013年10月,Hadoop 2.0.0版本發布,
- 2014年2月,Spark成為Apache頂級專案,
- 2017年12月,Hadoop 3.0.0版本發布,
2. Hadoop核心功能及優勢
- 分布式存盤系統:HDFS
HDFS是Hadoop分布式檔案系統(Hadoop Distributed File System)的簡稱,是Hadoop生態系統中的核心專案之一,也是分布式計算中資料存盤管理的基礎,
- 分布式計算框架:MR
MapReduce是一種計算模型,核心思想就是“分而治之”,可以用于TB級的大規模并行計算,Map階段處理后形成鍵值對形式的中間結果;Reduce對中間結果相同的“鍵”對應的“值”進行處理,得到最終結果,
- 資源管理平臺:YARN
YARN(Yet Another Resource Negotiator)是Hadoop的資源管理器,可以為上層應用提供統一的資源管理和調度,為集群的資源利用率、統一管理、資料共享等方面提供了便利,
- 高擴展
Hadoop是一個高度可擴展的存盤平臺,可以存盤和分發超數百個并行操作的廉價的服務器集群,能夠打破傳統的關系資料庫無法處理大量資料的限制,Hadoop能夠提供TB級別資料的運算能力,
- 成本低
Hadoop可以將廉價的機器組成服務器集群來分發處理資料,成本較低,學習者及普通用戶也能夠很方便的在自己的PC上部署Hadoop環境,
- 高效率
Hadoop能夠并發的處理資料任務,并且能夠在不同的節點之間移動資料,可以保證各個節點的動態平衡,
- 容錯性
Hadoop可以自動維護多份資料的副本,如果計算任務失敗,Hadoop能夠針對失敗的節點重新處理,
3. 部署方式介紹
- 單機模式
單機模式是一個最簡的安裝模式,因為Hadoop本身是基于Java撰寫的,所以只要配置好Java的環境變數就可以運行了,在這種部署方式中我們不需要修改任何的組態檔,也不需要啟動任何的服務,只需要解壓縮、配置環境變數,
雖然配置很簡單,但是能做的事情也是很少的,因為沒有各種守護行程,所以分布式資料存盤以及資源調度等等服務都是不能使用的,但是我們可以很方便的測驗MapReduce程式,
- 偽分布模式
偽分布模式是學習階段最常用的模式,可以將行程都運行在同一臺機器上,在這種模式下,可以模擬全分布模式下的運行狀態,基本上可以完成全分布模式下的所有操作,偽分布模式是全分布模式的一個特例,
- 全分布模式
在全分布模式下,會在組態檔中體現出主節點與分節點,可以指定哪些機器上運行哪些服務以達到的成本與效率的平衡,在企業中主要采用的都是全分布式模式,節點從數十個到上百個不等,在學習階段,如果個人PC的性能足夠強勁,也可以使用多臺虛擬機代替,
二、Hadoop下載
作為一個軟體的學習者和開發者,大家一定要培養自己:去官網、查資料的好習慣,擺脫各種一鍵安裝、軟體管家之類的東西,把一切掌控在自己手中,用嚴謹的態度來要求自己,加油!
1. 下載地址
在百度中搜索Hadoop,前兩條就會顯示我們需要的網站,目前Hadoop屬于Apache基金會,所以我們打開網址時注意一下是apache.org,
進入后來到Hadoop的官網,點擊Download就可以打開下載界面:https://hadoop.apache.org/releases.html,
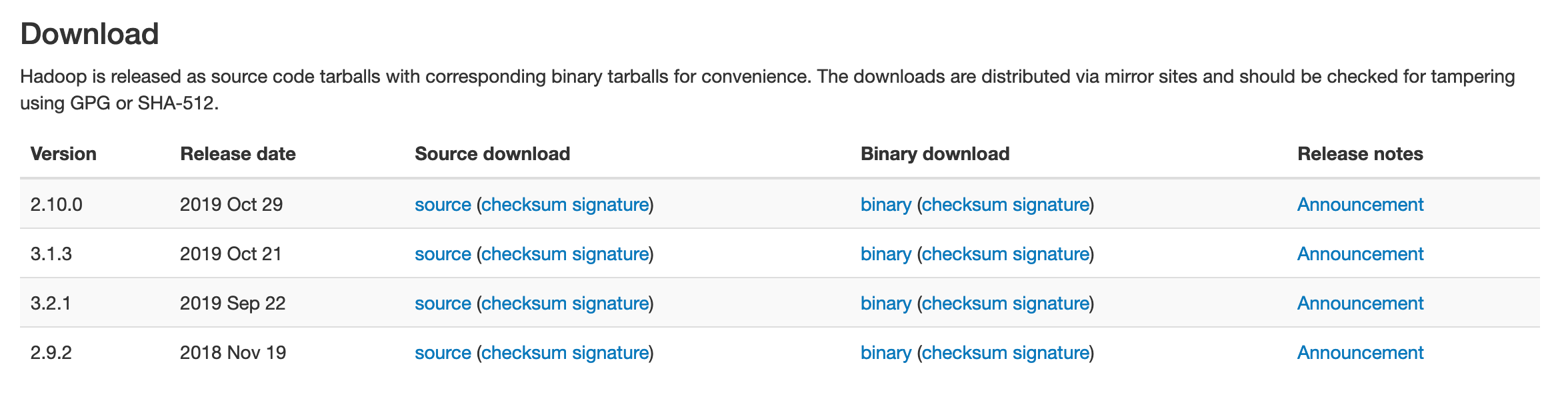
2. 版本選擇
現在我們使用的是開源社區版,目前的主流版本為2.x.y和3.x.y,
在選擇Hadoop的版本時,我們應該考慮到與其他生態圈軟體的兼容問題,通常的組建方式有兩種:
- 根據各組件的兼容性要求手動選擇版本并搭建
- 使用CDH(Cloudera’s Distribution Including Apache Hadoop)自動選擇版本并解決兼容問題
在學習階段,由于進行的操作比較簡單,不需要特別的在意版本的兼容問題,但是建議兩種方式大家都能夠去進行了解和實踐,
3. 安裝包下載
本文選擇2.9.2版本進行演示,Source為原始碼,Binary為我們所需要的軟體包,點擊對應版本的binary進入下載界面,
點擊任意一個鏡像地址開始下載,直擊鏈接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz,
三、安裝步驟
1. 前置環境
- 機器準備
由于是全分布式模式,一定會是由多臺虛擬機或物理機組成的集群,本文將以三臺機器為例,整體搭建步驟如下:
準備三臺虛擬機 -> 完成系統安裝和網路配置 -> 選擇其中一臺機器為主節點進行Hadoop核心配置 -> 將配置后的Hadoop軟體分發到其他機器 -> 啟動測驗
- 系統安裝
本文以在CentOS系統下部署Hadoop為例,對于CentOS的版本沒有大的要求,在網卡配置時會稍有差別,對于系統安裝有問題的小伙伴可以參考以下文章:
VMware安裝CentOS 6.x(結尾附視頻)
VMware安裝CentOS 7.x(結尾附視頻)
有些教程會推薦大家使用虛擬機克隆的方式快速獲得多臺已經安裝配置好的Linux虛擬機,但是一方面這不會是企業中使用的方式,另外一方面同樣需要處理好網卡、主機名等方面的沖突,所以還是推薦大家全新安裝好三臺機器,畢竟占用的空間都是一樣的,
在安裝時可以直接將主機名改為帶有01、02、03編號的名稱,便于記憶和區分,同時需要將網路設定為動態ip,以免自動分配的ip發生變化,如果在安裝系統時沒有完成這兩個步驟也可以在安裝完成后進行修改,
- 修改主機名
在CentOS 6中直接使用root用戶修改**/etc/sysconfig/network檔案中的HOSTNAME屬性(重啟永久生效),

在CentOS 7中直接使用root用戶執行hostnamectl**命令修改,重啟后永久生效,
hostnamectl set-hostname NewHostName
- 配置靜態IP
使用root用戶修改當前啟用的網卡組態檔,所在路徑為**/etc/sysconfig/network-scripts**,CentOS 6系統默認為ifcfg-eth0,CentOS 7系統默認為ifcfg-ens33,組態檔中需要修改的內容基本相同:
# 原值為dhcp,修改為static
BOOTPROTO=static
# 添加IPADDR,對應的值要與原ip在同一網段
IPADDR=xxx.xxx.xxx.xxx
# 添加NETMASK,指定子網掩碼,默認為255.255.255.0
NETMASK=255.255.255.0
# 添加GATEWAY,要與虛擬機網卡的設定一致,默認僅主機模式為1,NAT模式為2
GATEWAY=xxx.xxx.xxx.1/2
# 如果需要連入外網,則可以添加DNS1和DNS2配置,通常會將DNS1指定為網關地址
配置完成后保存退出,使用service network restart命令重啟網卡服務,并使用ifconfig命令查看配置是否正確,
- 配置hosts映射
由于是全分布式,為了方便各節點的互動,也為了盡量減少配置的修改,通常在組態檔中都會使用主機名,這就需要正確的建立主機名與ip的映射,我們目前已經有了三臺配置好網路的機器(要保證在同一虛擬網路模式下,即:同為NAT、僅主機、橋接等,這樣才能保證每臺機器都處在同一個網段,能夠正常通信),現在我們有這樣三臺機器(Master為主節點):
| 主機名稱 | ip地址 |
|---|---|
| Master | 192.168.251.130 |
| Slave01 | 192.168.251.131 |
| Slave02 | 192.168.251.132 |
則需要使用root用戶修改**/etc/hosts**檔案,在結尾直接追加內容(每臺機器):
192.168.251.130 Master
192.168.251.131 Slave01
192.168.251.132 Slave02
配置完成后可以使用ping命令一一測驗,看看是夠能夠正確決議出ip地址,得到目標機器的回應(可以每臺機器都測驗一下:使用Ctrl + C結束),
ping Master
ping Slave01
ping Slave02
2. Hadoop安裝
對于Hadoop軟體,通常會新建一個單獨的用戶來管理,下面以普通用戶hadoop為例來進行操作,
# 新建hadoop用戶
useradd hadoop
# 為hadoop用戶設定密碼
passwd hadoop
# 切換至hadoop用戶
su - hadoop
在配置Hadoop前,需要先配置好JDK,在安裝先需要先卸載歷史版本,詳細的步驟可以參考我的另一篇文章:JDK的解壓安裝 - CentOS,
- 查詢歷史版本(如沒有可跳過卸載步驟)
rpm -qa|grep java
rpm -qa|grep jdk
- 卸載歷史版本(使用root用戶操作)
rpm -e --nodeps 軟體包全稱(從查詢處獲得)
以上步驟需要在每一臺機器上完成,剩余步驟只需要在主節點上進行,最后進行分發
從此為分界,以下所有操作均使用hadoop用戶來操作
- 解壓縮JDK
將JDK的安裝包使用hadoop用戶上傳至自己的家目錄**/home/hadoop**下:
tar -zvxf jdk-8u251-linux-x64.tar.gz
- 配置JDK環境變數(在hadoop用戶下)
vi /home/hadoop/.bash_profile
# 在檔案結尾添加以下內容
JAVA_HOME=/home/hadoop/jdk1.8.0_251
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export JAVA_HOME
export PATH
- 重繪環境變數
source /home/hadoop/.bash_profile
- 使用命令測驗
java -version

- 解壓縮Hadoop
使用hadoop用戶上傳Hadoop軟體包,
tar -zxvf hadoop-2.9.2.tar.gz
- 配置環境變數(在hadoop用戶下)
vi /home/hadoop/.bash_profile
# 在檔案結尾添加以下內容
HADOOP_HOME=/home/hadoop/hadoop-2.9.2
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME
export PATH
- 重繪環境變數
source /home/hadoop/.bash_profile
- 使用命令測驗
hadoop version

3. Hadoop配置
如果以全分布模式運行Hadoop需要先進行相關配置,此步驟也是只需要在主節點上做一次即可,
- 組態檔所在路徑
需要修改的組態檔所在路徑在Hadoop的安裝目錄下的etc檔案夾中,

- hadoop-env.sh
在Hadoop啟動時會呼叫執行該檔案,需要在其中設定JAVA_HOME,即依賴的Java環境安裝位置(25行),確保export前沒有井號,
export JAVA_HOME=/home/hadoop/jdk1.8.0_251
- core-site.xml
Hadoop的核心組態檔,全部配置項可參考官方檔案:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml,
<configuration>
<!-- Hadoop臨時檔案存放路徑,默認在/tmp目錄下 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.9.2/data</value>
</property>
<!-- NameNode結點的URI(包括協議、主機名稱、埠號) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 設定檔案檔案洗掉后,被完全清空的時間,默認為0,單位為分鐘 -->
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>
</configuration>
- hdfs-site.xml
HDFS核心組態檔,全部配置項可參考官方檔案:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml,
<configuration>
<!-- 塊存盤份數,默認為3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 關閉權限校驗,開發學習時可開啟,默認為true -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- namenode的http訪問地址和埠 -->
<property>
<name>dfs.namenode.http-address</name>
<value>Master:50070</value>
</property>
</configuration>
- mapred-site.xml(重命名mapred-site.xml.template)
Hadoop計算功能模塊相關組態檔,全部配置項可參考官方檔案:https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml,
<configuration>
<!-- 設定運行MapReduce任務方式為yarn,默認為local,可選項還有classic -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
Yarn資源調度相關組態檔,全部配置項可參考官方檔案:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml,
<configuration>
<!-- resourcemanager的主機名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!-- 分配給容器的物理記憶體量,單位是MB,設定為-1則自動分配,默認8192MB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<!-- NodeManager上運行的服務串列,可以配置成mapreduce_shuffle,多個服務使用逗號隔開 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- slaves
從節點組態檔,這里填入另外兩臺機器的主機名,如果希望主節點本身也提供資料存盤和計算服務,則可以將主節點主機名也填寫上,如下:
Master
Slave01
Slave02
4. SSH相關操作
至此,Hadoop的安裝配置已經全部完成,接下來只要將JDK解壓后的檔案夾、Hadoop解壓后的檔案夾、環境變陣列態檔同步到另外兩臺機器上就可以了,換句話說,三臺機器的內容完全一樣,
在CentOS系統中已經默認安裝并啟動了SSH服務,首先需要先配置免密碼登錄,這樣可以使發送檔案和Hadoop的使用更加方便,
- 生成密鑰
# 整個程序一直回車即可
ssh-keygen -t rsa
- 配置免密碼登錄
# @前為用戶名,@后為主機名,在主節點上執行以下命令
ssh-copy-id hadoop@Master
ssh-copy-id hadoop@Slave01
ssh-copy-id hadoop@Slave02
# 輸入一次hadoop用戶的密碼即可通過驗證
配置完成后,可以從主節點免密碼登錄到自己以及兩個從節點,如果希望三臺機器之間都可以互相免密碼登錄,則可以在另外兩臺機器都執行一下上述命令,
- 使用遠程登錄命令驗證
# 第一次登錄可能會出現驗證提示,輸入yes后回車
ssh hadoop@Master
# 登錄成功后使用exit命令結束會話
exit
ssh hadoop@Slave01
exit
ssh hadoop@Slave02
exit
如果以上登錄程序要求輸入hadoop用戶的密碼,則證明配置成功,可以進行最后一步,
- 將檔案分發至另外兩個節點
在配置好免密碼登錄后,可以直接使用scp命令拷貝檔案至其它機器,-r為遞回操作,不需要輸入密碼,
# 拷貝JDK
scp -r /home/hadoop/jdk1.8.0_251 hadoop@Slave01:/home/hadoop
scp -r /home/hadoop/jdk1.8.0_251 hadoop@Slave02:/home/hadoop
# 拷貝Hadoop
scp -r /home/hadoop/hadoop-2.9.2 hadoop@Slave01:/home/hadoop
scp -r /home/hadoop/hadoop-2.9.2 hadoop@Slave02:/home/hadoop
# 拷貝環境變陣列態檔,同名檔案會自動覆寫
scp -r /home/hadoop/.bash_profile hadoop@Slave01:/home/hadoop
scp -r /home/hadoop/.bash_profile hadoop@Slave02:/home/hadoop
5. 集群啟動及確認
- 格式化namenode
第一次使用Hadoop時需要進行初始化,該操作只需要在主節點執行一次,完成后會根據core-site.xml中的配置,在對應的目錄下自動創建相應的檔案夾,
hdfs namenode -format
- 啟動Hadoop行程
由于已經配置了環境變數,可以直接執行sbin目錄下的腳本:start-all.sh,如果需要停止可以執行stop-all.sh,
start-all.sh
- jps命令驗證
jps為安裝JDK環境后的命令,可以查看到當前用戶下的Java行程,如果無法使用需檢查JDK的環境變數配置,
jps
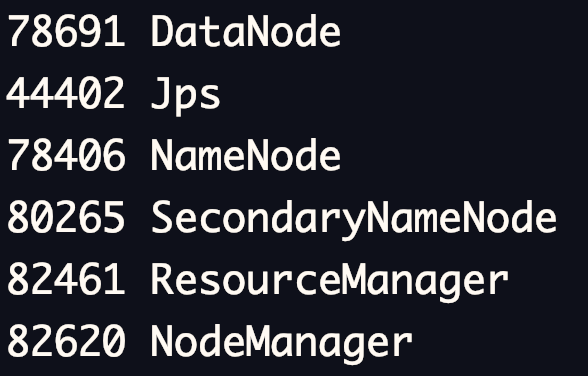
如果在slaves檔案中填寫了主節點,則在主節點中應該出現5個行程(不包括jps本身),否則為3個:NameNode、SecondaryNameNode、ResourceManager,
從節點上會出現兩個行程:DataNode、NodeManager,如果以上行程都成功啟動,那么祝賀你,你的集群配置已經完成了,

 CSDN認證博客專家
全堆疊開發工程師
大資料高級開發
大資料金牌講師
CSDN認證博客專家
全堆疊開發工程師
大資料高級開發
大資料金牌講師
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233614.html
標籤:其他