?? 基于體素的形態學方法(voxel-based morphometry, VBM),是分析大腦解剖學(結構)差異最常用方法之一, 其通過給大腦volume逐體素打標簽(分類)的方式來進行組織分割(segmentation),程序高度自動化,比傳統的基于ROI先驗假設的分析方式(manual ROI tracing)得到的結果,更加具有 穩定性和可重復性,
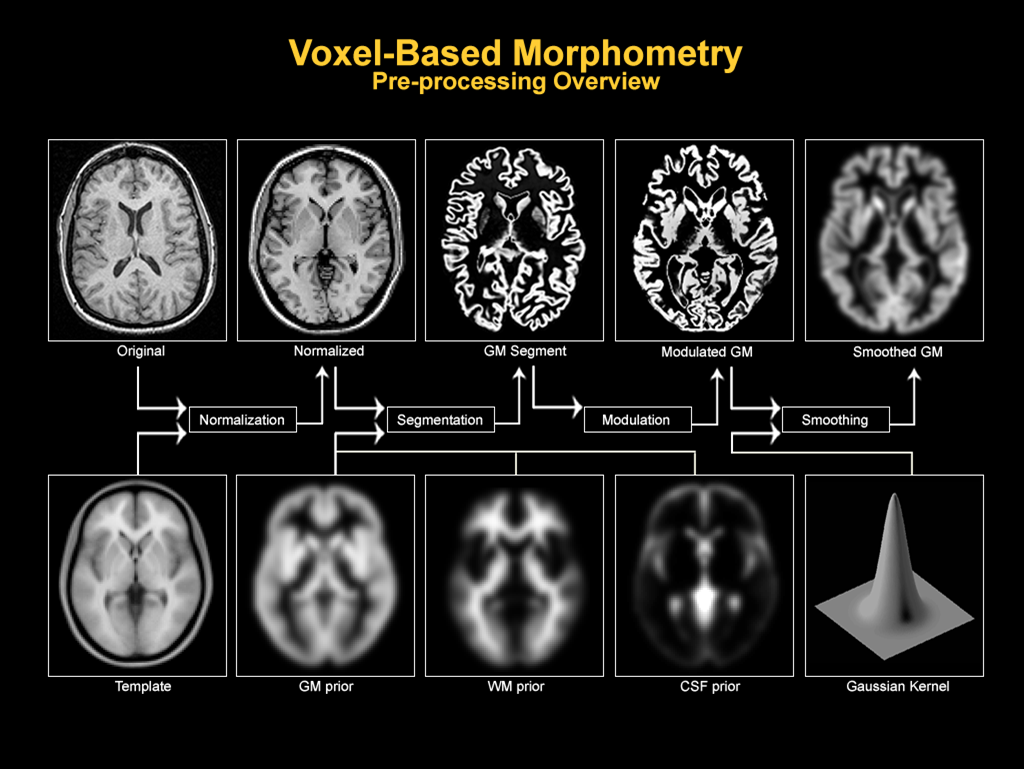
??VBM分析基于(高解析度)MRI腦部掃描影像(一般用T1加權影像),涉及的預處理步驟主要包括:空間歸一化(spatial normalisation——分割和組間比較的前提),偏置場校正(bias correction——降低相同組織的亮度值差異),分割( segmentation),調制(modulation——把空間歸一化程序中產生的形變矩陣( Jacobian determinants)作用到分割結果上,使得其亮度值可以代表體素濃度(voxel concentration))平滑(smoothing ——去噪,便于統計分析),如上圖,圖源1,
??以下內容,主要源于筆者對NBAlab盧家峰老師的教學視頻和PPT的理解性整理和大量的閱讀拓展,初學小白一枚,如有錯誤之處,還望不吝指出,
??原創不易,轉載請注明出處,
copyright?意疏:
空間歸一化(spatial normalisation)
-
為什么要空間歸一化——哲學
??1、VBM組織分割時,需要使用不同組織的組織概率圖(Tissue probability maps,TPM)來作為分割的先驗,具體細節見后文,而這些TPMs都是被歸一化(配準)到了標準模板上了的,所以使用VBM來進行組織分割前提就是,將被試的腦袋歸一化到標準模板上,另外,單樣本統計分析常常是和一個標準進行比較,而這些標準也是配準到了標準模板的,
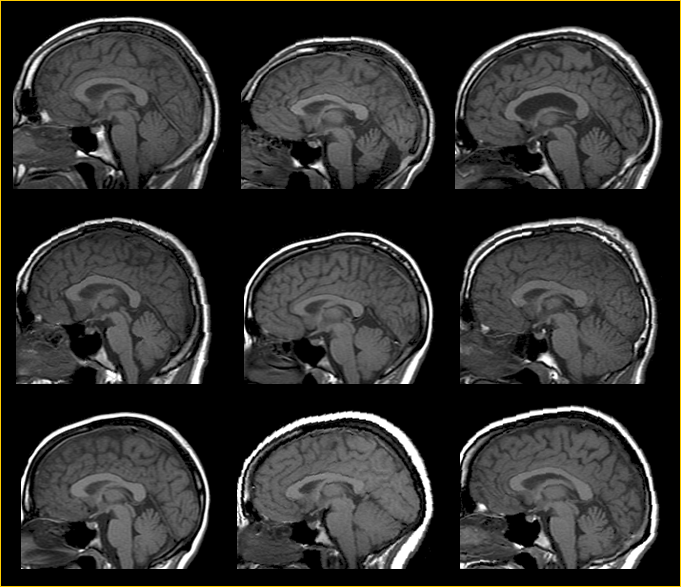
??2、不同的人,腦袋大小形狀都不一樣,不同次的掃描,腦袋的擺放位置也不一樣,如圖1所示,圖源1,而多樣本統計分析尋找區域解剖結構變化的顯著性,往往只是通過對應位置值相減,再通過假設檢驗來得到的,
??也就是說,如果所有被試的影像相同空間坐標對應的解剖位置不基本一致,即沒有一致性,那相減得到的差異是沒有意義的,無法進行進一步統計分析,所以需要讓所有被試的腦袋在不失皮質特征差異的前提下,都對齊到標準模板上,以校正大腦整體形狀和解剖位置的差異,讓不同的被試,不同的掃描之間具有可比性或者一致性,
-
歸一化到哪——標準模板(template)——技術
??MNI是最常用的標準模板之一,在NeuroImaging and Surgical Technologies Lab的網站上,我們可以下載最新的一些模板來看看,有人腦也有猴子腦的,
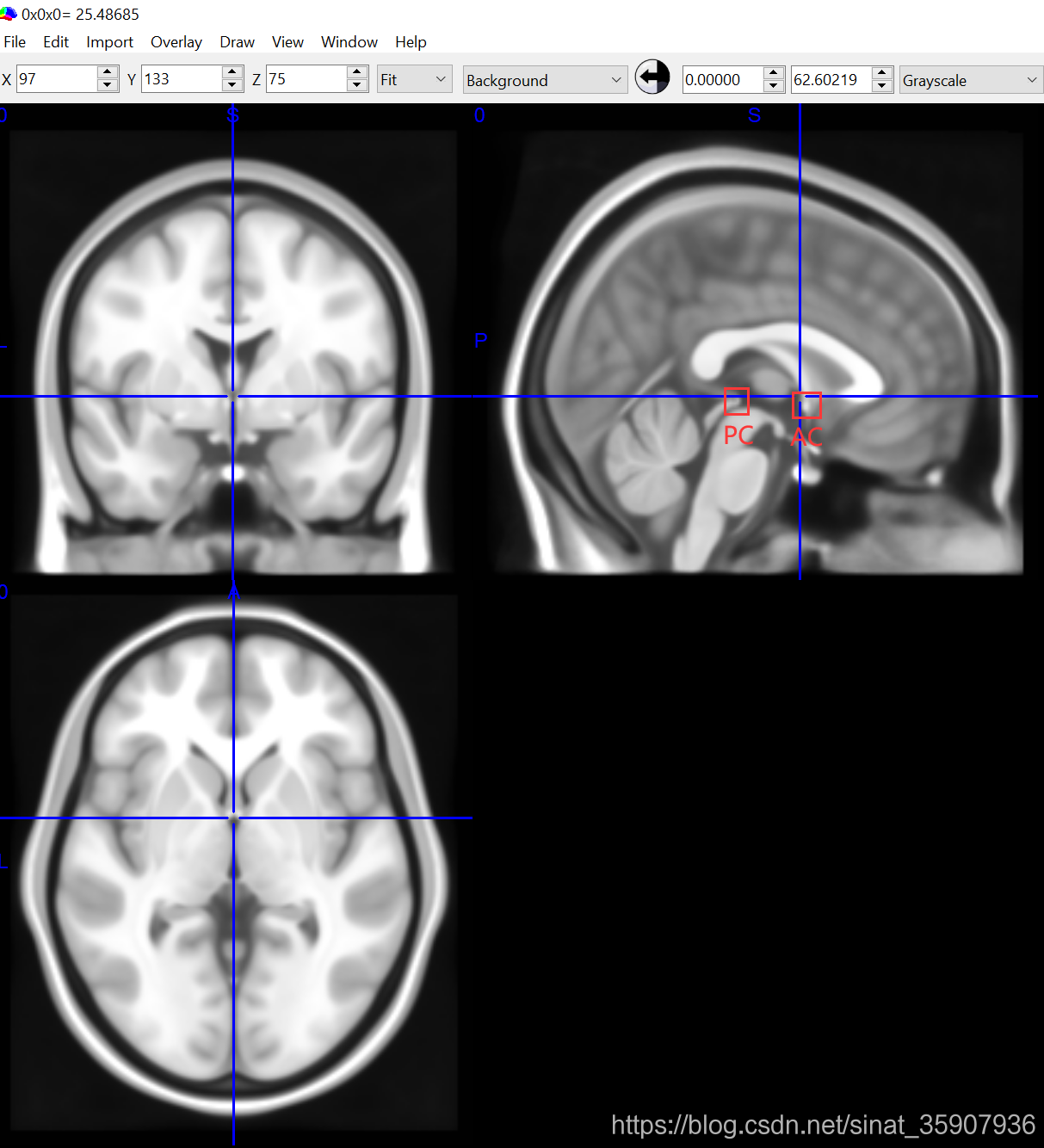
??ICBM 152是MNI的標準版,筆者下載了其第六代非線性對稱平均腦立體定向配準模型的Nifti格式檔案2 ,然后用MRIcron查看,結果如圖2,由于它是152個人腦T1掃描影像的平均,所以看起來有點糊,不過我們還是很容易的就可以找到前聯合AC和后連合PC點,CAT,FSL,SPM都有用MNI空間作為標準模板,
??為了描述大腦volume中的某個位置,顯然我們需要定義一個三維笛卡爾坐標系(空間),一個笛卡爾坐標系可以通過坐標原點,單位長度唯一確定,MNI標準模板坐標空間X軸線如下圖紅線所示,圖源3,Y軸基本上和中央溝重合,AC點在其下方約4mm,并且AC和PC沒有水平對齊,AC點靠近坐標原點,
??有的空間坐標原點直接是AC,而且AC-PC line直接是X軸,如Talairach空間,被試影像在和標準模板配準(歸一化)的同時,也將其原始坐標空間轉換到了標準模板對應的坐標空間,不同的標準模板對應的坐標空間可能會有差異,但是可以相互轉換,

copyright?意疏:
-
如何歸一化——配準——技術
??配準程序中要進行線性和非線性配準,
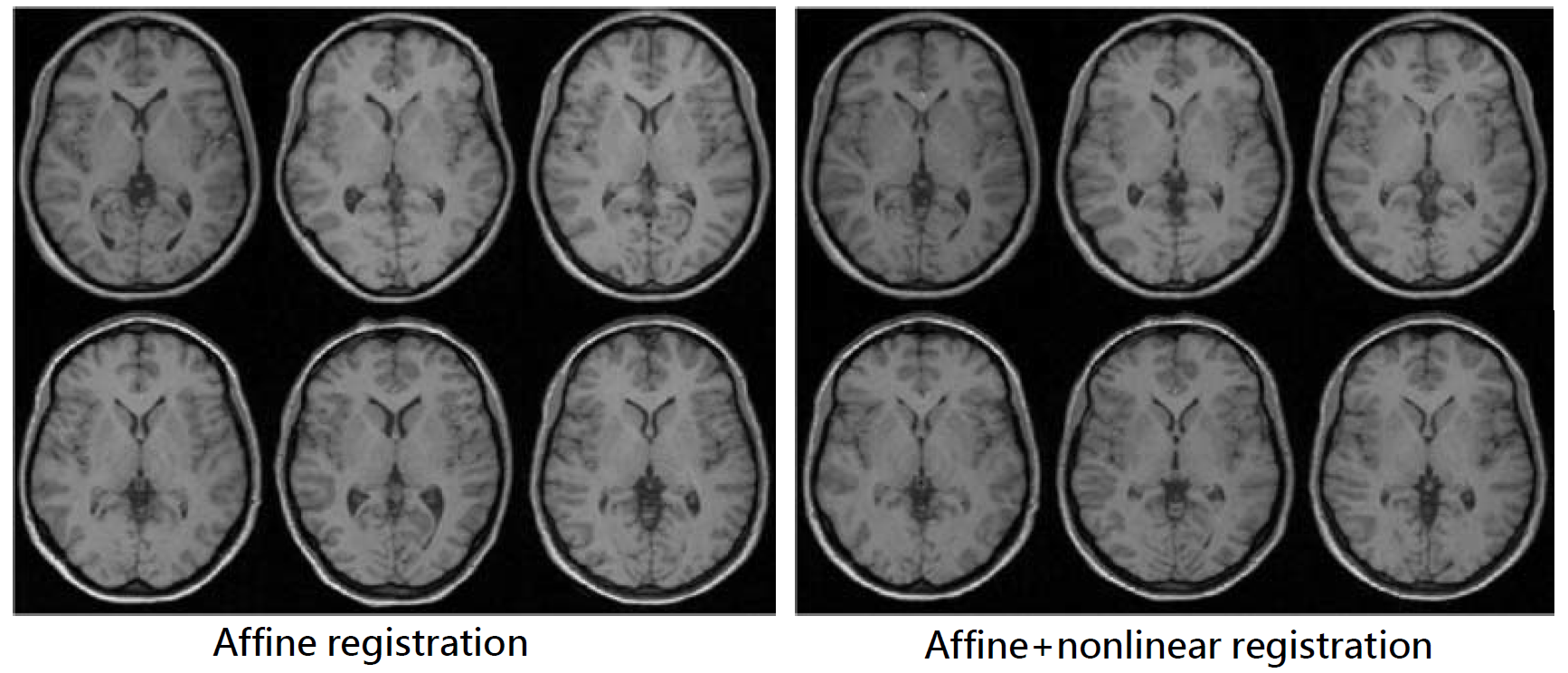
??線性配準就是在做仿射變換,通過乘以一個由貝葉斯后驗估計出的變換矩陣來實作,是線性操作,仿射變換包括旋轉,平移,縮放和錯切1等,前兩者是剛體變換,仿射變換是對影像整體進行操作,所以只能匹配整體的位置和大小,所以配準后的腦袋在形狀和組織位置上還有較大差異,如圖3左圖,圖源4 ,
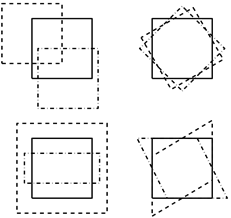
??非線性配準是在對線性配準后的影像進行扭曲和變形(warping , deforming)操作,意在使其與模板盡可能的像,操作程序由最優化理論和一些平滑度量控制,目標是最小化平方誤差函式1,非線性配準后不同被試的腦袋形狀和組織解剖位置已經變得非常相似——相同空間坐標對應的解剖位置基本一致,如圖4右圖,圖源4,
??最后,如果我們用MNI模板,前面提到MNI標準模板對應的坐標空間原點在AC附近,而AC-PC line靠近Y軸,所以如果我們在采集影像的時候,或者配準前手動校正坐標原點(reorientation)的時候,定義原始坐標空間的原點和軸都應該盡量靠近該標準,這樣不僅配準的精度,還有配準的速度都會有所增加,
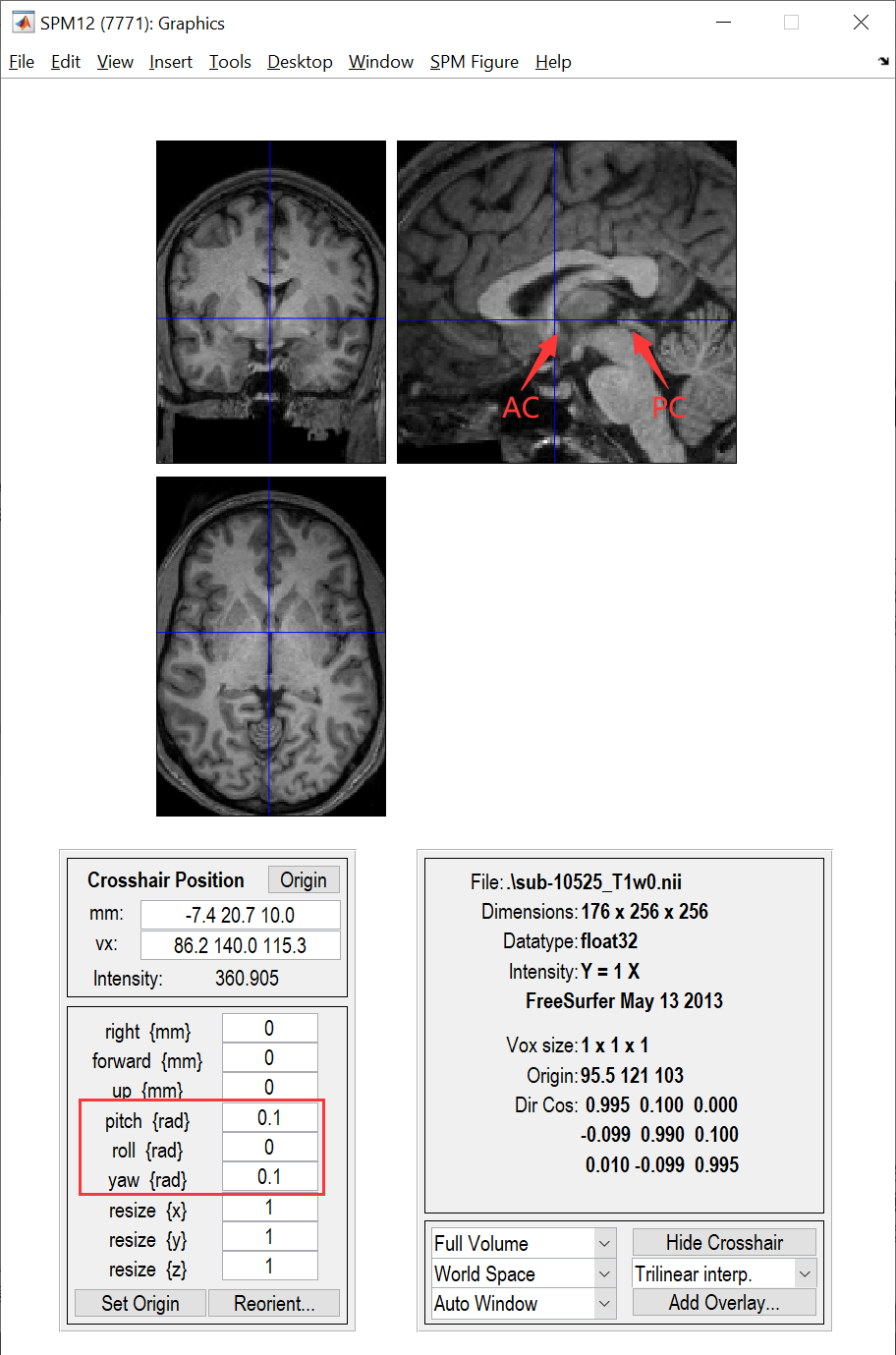
??如果配準結果壞掉了,多半是坐標原點離AC太遠或者Y軸嚴重偏離AC-PC line,此時可以用SPM的Display工具,修改位移量,旋轉量來重新定義原始空間的坐標原點,當然,如果對配準精度要求比較高,在配準之前也可以用SPM的Display工具處理一下,以減少在非線性配準的優化程序中落入區域最優解的可能,如圖5所示,另外,三個位移量分別對應mm:后面的三個值的相反數,最后填完需要點Reorient保存修改,
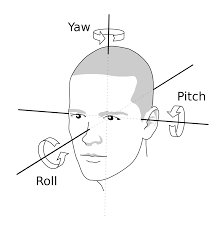
??Pitch: 表示低頭仰頭或者點頭動作;Yaw: 表示左右轉頭或者搖頭動作;Roll: 表示左右偏頭動作;注意到,pitch本意是拋,想想這個動作,就可以記住它表示的方向了,另外,yaw表示的意思是偏航,如果我們走路換方向了,我們的頭會不由自主的轉動,
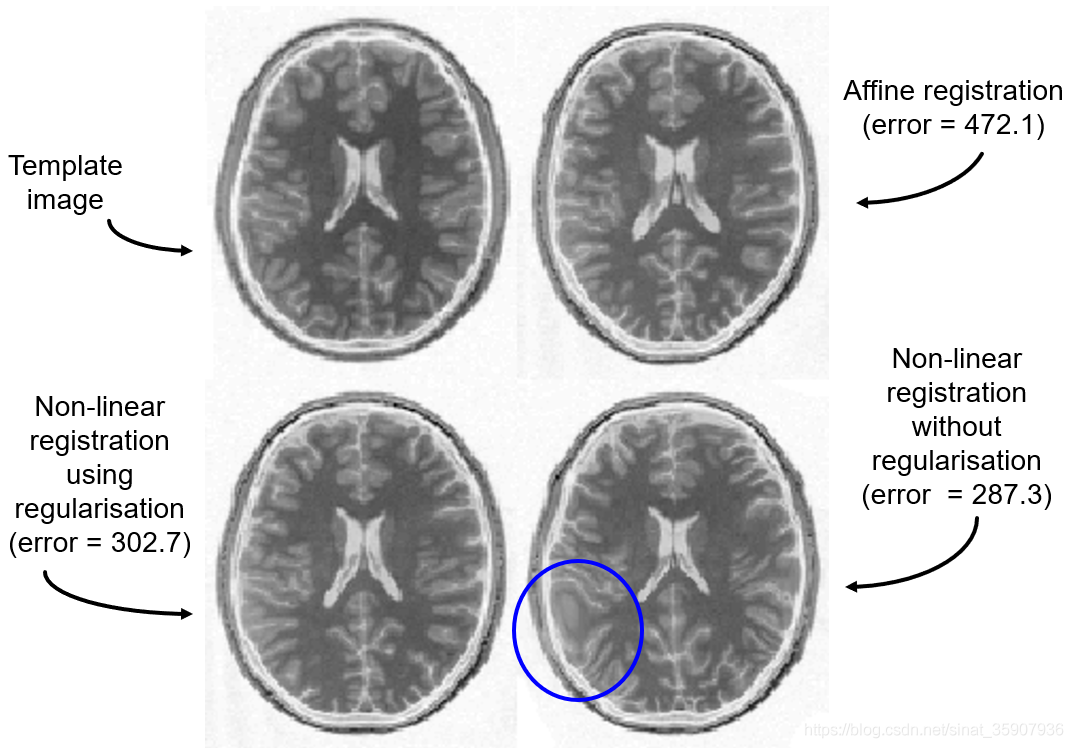
??另外還有種原因可能導致配準結果壞掉,那就是非線性配準優化程序中過擬合——太追求誤差小了,而把某些組織結構給抹掉的,如圖5藍色圈出部分,圖源5,可以通過加正則項或者懲罰項來減少過擬合,熟悉最優化理論或者機器學習的朋友應該會對這個概念比較熟悉,不過一般的工具包都考慮了這個,只需點點點就可以了,
copyright?意疏:
偏置場校正(bias field correction)
-
什么是偏置場——哲學
??掃描設備中磁場不均勻,被試在掃描儀中的位置不同(靠近線圈部分可能更亮),噪聲以及許多未知因素,可導致MR影像上同一組織的像素灰度值平滑的發生變化,導致這些變化的所有因素統稱為偏置場,關于偏置場的定義和解釋有很多,這個解釋是筆者比較贊同的一個,
-
為什么要偏置場校正——哲學
??一般而言,我們是希望相同的組織灰度值是比較均勻的,逐體素的組織分割,是基于每個體素的灰度值和該體素位置屬于某個組織的先驗概率的,先驗概率由TPM固定,現在假設在白質區域取兩個體素,在TPM上它們屬于白質的先驗概率都是1,而其中一個的灰度值是0.9,另一個的灰度值卻只有0.4,這樣前者貝葉斯最大后驗分子為0.9,而后者只是0.4,VBM幾憾訓把兩個體素判定為兩種組織的,但是它們本屬于同一組織,這就會導致嚴重的分割錯誤,
??如圖6中,圖源,有些地方白質的亮度已經和灰質很接近了,有些地方的灰質比白質還亮,如果直接對該圖進行分割,結果肯定是不理想的,當然實際情況不會像圖中那么明顯,但處于廣泛化的考量,還是會進行偏置場校正,
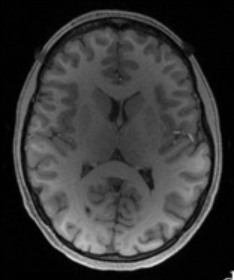
-
如何進行偏置場校正——技術
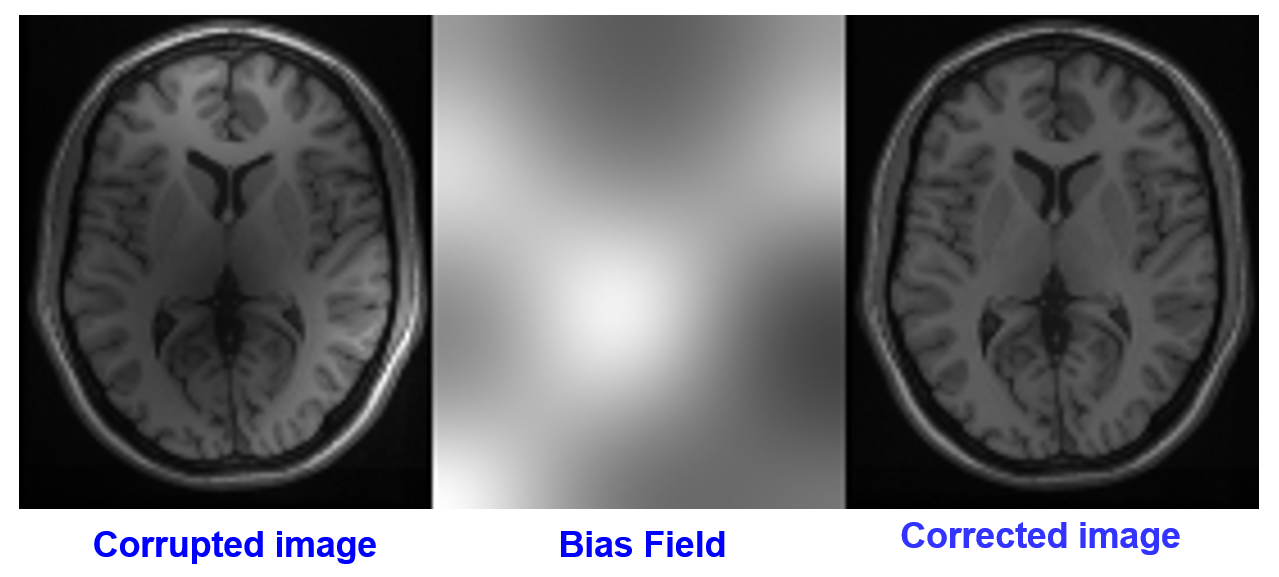
??將偏置場疊加到原影像上,就可以實作偏置場校正,如圖7所示,圖源5,偏置場可以通過演算法估計得到,如N4BiasFieldCorrection方法,
分割(segmentation)
-
為什么要進行組織分割——哲學
??結構決定功能,不同組織的形態學變化可能與大腦某些功能的變化有聯系,我們先要獲取到不同組織的形態學指標,才能對其進行分析,而它們都需要分割來得到,
-
如何進行組織分割——技術
??最容易理解也是最常用的分割方法之一,是基于高斯混合模型和樸素貝葉斯的,
??由中央極限定理,我們可以知道在大樣本的條件下,采樣值出現的概率是服從高斯分布的,腦影像不同組織可能也包含上萬體素,所以它們的值也可以近似認為服從某個高斯分布,如圖8所示,圖源5,當知道每一種組織體素值的均值和方差時,我們可以很容易得到它們的分布,進而很容易用樸素貝葉斯進行分類,
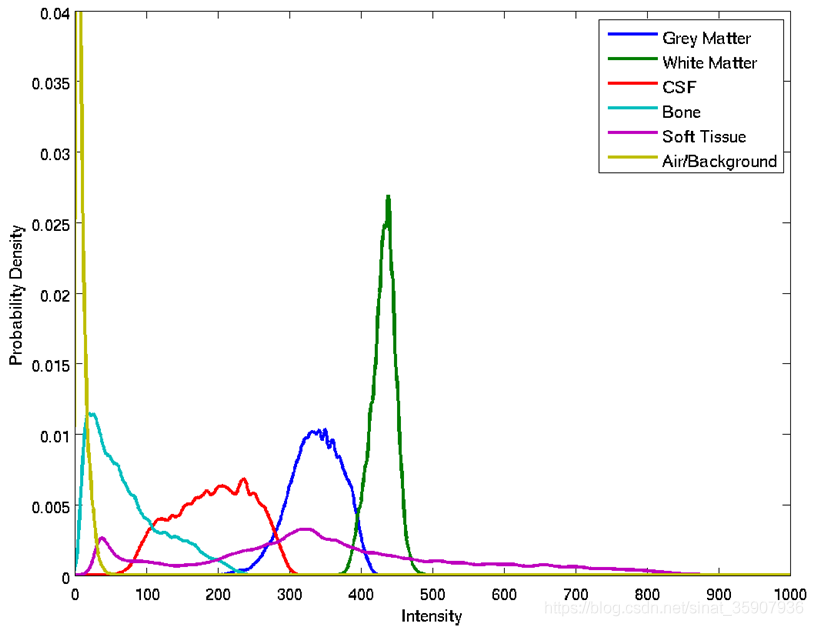
??但顯然,在腦影像中,我們并不知道某個體素究竟素屬于哪個組織,沒有辦法直接求出其均值和方差,所有體素都是混在一起的,此時每個體素都服從一個總分布,它可以看做是每個組織服從的高斯分布的疊加,這就是所謂的高斯混合模型,其中,EM演算法常用于估計混合高斯模型中每一個成分分布的引數,對應腦影像,就是每一個組織的體素值分布的引數,
??現在假定我們已經估計出每個組織的分布引數了,即我們已經知道每一種組織出現某個體素值的概率,接下來就可以利用樸素貝葉斯對腦影像中的每一個體素進行打標簽作業,判斷它們是輸入灰質,白質還是腦脊液,我們知道偉大的貝葉斯公式是下面這樣的:
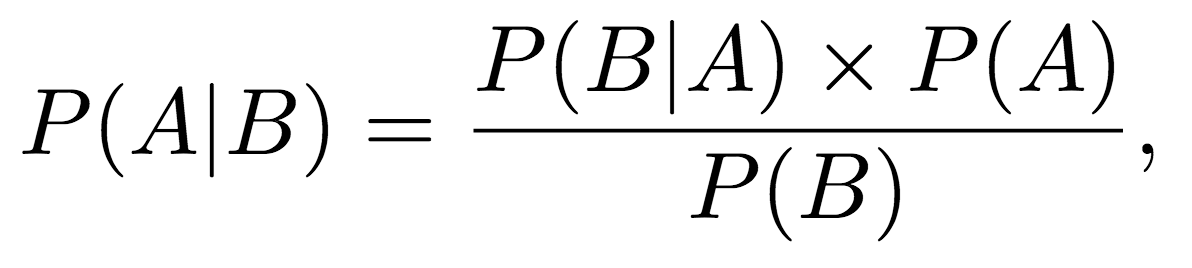
??其中,P(B|A)是類條件概率,即每一個組織出現某個體素值的概率,由估計出來的概率分布得到,P(A)是先驗概率,即某個位置出現某個組織的概率,由TPM得到,P(B)全概率,即某個位置出現某個體素值的全概率,由全概率公式得到,最后結果就是某個位置,出現某個體素值時,貢獻最大的組織標簽,就是該體素屬于的組織型別,
??TMP是標準的先驗模板,它是通過統計得到的,如圖9所示,是灰質,白質,腦脊液和背景的模板,圖源5,越亮表示該組織在此處出現的可能性越大,即先驗概率越大,
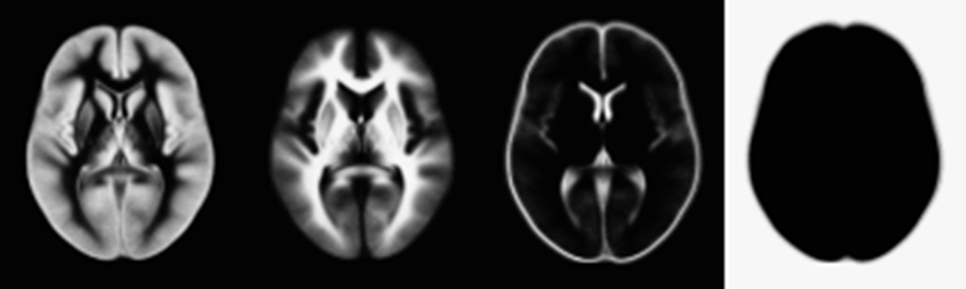
copyright?意疏:
調制(modulation)
-
為什么要調制——哲學
??我們可以知道,空間歸一化之后,的確分割與統計分析都變得容易了,因為在相同坐標空間下,不同被試相同坐標對應的組織結構基本上是一樣的,但是我們會發現一件很詭異的事情,就是如果分割完成后每個體素代表的實際尺寸是相同的話,那么不同被試的對應組織的形狀體積也變的基本一樣了,這樣就不用分析了,反正大家都一樣,但不應該是這樣的,分割后或者說空間歸一化后的每一個體素代表的實際尺寸已經改變了,具體尺寸由形變程序決定,無法直接比較,
??我們知道,旋轉平移肯定不會使得尺寸改變,但線性配準中的尺度變換和錯切,非線性變換中的扭曲(warp)和變形(deform) 都會使作用后每個體素代表的實際尺寸發生變化,而分割后的結果中顯然丟失了這種變化的資訊,所以我們需要在分割結果中加上這種變化資訊,這個程序就叫做調制,
-
如何調制——雅可比矩陣——技術
??分割完成后同一組織的體素值是相同的,只代表邊界,沒有實際含義,但如果我們將配準程序中產生的形變數圖譜乘到體素值中,那么由于同一組織不同位置發生的形變數不同,最后得到的體素值也將不同,而這些值將含有原先的體積資訊,而它也將有一個新的名字,體素濃度,代表分割后或者是標準化后每個體素含有原空間的體素的個數,
??如圖9是標準化后輸出的,每個位置的形變數圖譜,或者叫做雅克比矩陣,它代包含標準化程序中丟失的體積變化資訊,如果分割后的一個體素是原先多個體素壓縮來的,那么它的體素濃度就會較高,代表較大的體積,應該就更亮,如果分割后的一個體素是原先幾分之一個體素壓縮來的,那么它的體素濃度就會較低,代表較小的體積,應該就更暗,所以分割后組織影像的灰度值將不代表信號強度,而代表體素濃度,或者體積值,

平滑(smoothing)
-
為什么要平滑——哲學
??影像中含有的隨機噪聲可能帶來統計結果的假陽性,
??哪怕通過非線性配準配準,影像也不是和模板完全精確對應的,一定程度的平滑,可以使得影像變得模糊,從而彌補配準的不準確,而且世界本來就是馬爾科夫的,
??用高斯核平滑后的結果,更加服從中央極限定理,有助于統計分析,
-
如何進行平滑——技術
??平滑的本質是將某個體素值與周圍的若干體素值加權平均后代替原先的值,使得一個區域內的值更相近,可以用卷積來實作,在用高斯核來進行平滑的時候,模糊程度由其半高全寬(FWHM)決定,一般取8,三個維度上就是[8 8 8],FWHM越大,對應頻域就越窄,高頻就濾的更嚴重,影像就會更模糊,二維高斯核如圖10所示,圖源5,

參考
https://www.slideserve.com/thurman/vbm-voxel-based-morphometry ?? ?? ?? ??
http://packages.bic.mni.mcgill.ca/mni-models/icbm152/mni_icbm152_nl_VI_nifti.zip ??
https://mri-q.com/uploads/3/4/5/7/34572113/talairachversusmni.pdf ??
Karl J. Friston et al., Statistical Parametric Mapping, Academic Press, 2006. ?? ??
https://www.slideserve.com/damita/zurich-spm-course-2011-spatial-preprocessing ?? ?? ?? ?? ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233886.html
標籤:其他
下一篇:編程簡介