在Ubuntu Kylin系統中使用 Eclipse 開發 MapReduce 程式對單詞計數
目錄
- 一、 首先利用Windows中使用VirtualBox安裝Ubuntu
- 二、 前期準備作業
- 1. 創建帳戶Hadoop
- 2. 設定hadoop密碼
- 3. 給hadoop用戶增加管理員權限
- 4. 更新 apt
- 5. 安裝vim
- 6. 配置SSH
- 三、 安裝Java環境
- 1.安裝JDK
- 2.此時驗證一下jdk安裝情況
- 3.這時需要設定java壞境變數
- 4.驗證java的安裝情況
- 四、 安裝Hadoop
- 五、 Hadoop偽分布式配置
- 六、 呼叫MapReduce執行WordCount對單詞進行計數
- 七、 個人總結
- 八、 參考資料
一、 首先利用Windows中使用VirtualBox安裝Ubuntu
本實驗采用Ubuntu Kylin版本,Ubuntu Kylin系統檔案可以從參考資料[1]中獲取,
二、 前期準備作業
1. 創建帳戶Hadoop
sudo useradd -m hadoop -s /bin/bash
2. 設定hadoop密碼
sudo passwd hadoop
3. 給hadoop用戶增加管理員權限
sudo adduser hadoop sudo
在完成注銷當前用戶,回傳登陸界面,在登陸界面中選擇hadoop 用戶進行登錄,
4. 更新 apt
登錄成功后,先更新一下apt,后面將會使用apt安裝軟體,如果沒有更新可能無法完成后續安裝(如所示下圖),在終端執行以下命令:
sudo apt-get update
5. 安裝vim
在后續的組態檔時,將會使用vim進行編輯,所以可以安裝vim,命令如下:
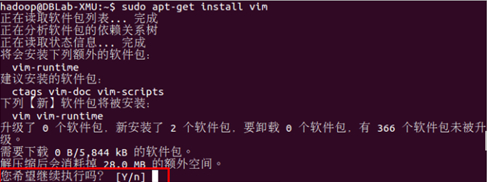
sudo apt-get install vim
也可以使用gedit進行編輯,gedit相對與vim更加直觀,
如果在安裝程序中出現(如所示下圖)的錯誤,可在提示處輸入y,
6. 配置SSH
(1)集群、單節點模式都需要用到 SSH 登陸,在ubuntu 默認已安裝了 SSH client,此外還需要安裝 SSH server:
sudo apt-get install openssh-server
(2)安裝后,可以使用如下命令登陸本機:
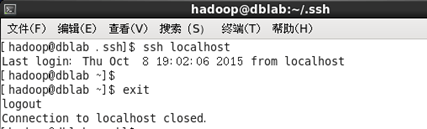
ssh localhost
在此時會有提示(SSH首次登陸提示),輸入 yes ,然后按提示輸入密碼 hadoop,這樣就登陸到本機了, 但這樣登陸是需要每次輸入密碼的,因此需要配置成SSH無密碼登陸較為方便,
(3)首先退出剛才的 ssh,就回到了我們原先的終端視窗,然后利用 ssh-keygen 生成密鑰,并將密鑰加入到授權中:
exit # 退出剛才的 ssh localhost
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授權
此時再使用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示,
三、 安裝Java環境
1.安裝JDK
Hadoop3.1.3需要使用JDK版本在1.8及以上, 我已經把JDK1.8的安裝包jdk-8u162-linux-x64.tar.gz匯入ubuntu中,有需要的可以[點擊這里到百度云盤下載](https://pan.baidu.com/share/init?surl=gbmPBXrJDCxwqPGkfvX5Xg)(提取碼:lnwl), 接下來在Linux命令列界面中,執行如下的命令(注意:當前登錄用戶名是hadoop):
cd /usr/lib
sudo mkdir jvm #創建/usr/lib/jvm目錄用存放jdk檔案
cd ~ #進入hadoop用戶的主目錄下
cd Downloads
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK檔案解壓到/usr/lib/jvm目錄下
2.此時驗證一下jdk安裝情況
cd /usr/lib/jvm
ls
3.這時需要設定java壞境變數
cd ~
vim ~/.bashrc
通過vim編輯器,打開環境變數配置.bashrc檔案,在檔案開頭添加如下幾行內容: (關于vim使用方法,可參考以下的網址:https://blog.csdn.net/lsg_down/article/details/87073295)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc檔案并退出vim編輯器,然后,繼續執行如下命令讓.bashrc檔案的配置立即生效:
source ~/.bashrc
4.驗證java的安裝情況
java -version
若回傳如下資訊,則說明JAVA環境配置成功
四、 安裝Hadoop
1.首先下載hadoop,這里選擇使用Hadoop2.10.0版本,
Hadoop官網下載hadoop-3.1.3.tar.gz
2.將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxf ~/下載/hadoop-3.1.3.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 將檔案夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改檔案權限
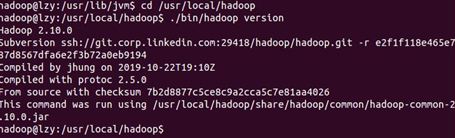
3.驗證Hadoop是否可用,成功則會顯示 Hadoop 版本資訊,如下圖所示,
cd /usr/local/hadoop
./bin/hadoop version
五、 Hadoop偽分布式配置
1. Hadoop 的組態檔位于 /usr/local/hadoop/etc/hadoop/ 中,偽分布式需要修改2個組態檔 core-site.xml 和 hdfs-site.xml ,Hadoop的組態檔是 xml 的格式,每個配置以宣告 property的 name 和 value 的方式來實作, 在修改組態檔前,需要自行創建相應的檔案夾進行存放,以防后續操作無法啟動Hadoop,
sudo mkdir /usr/local/hadoop/tmp
sudo mkdir /usr/local/hadoop/tmp/dfs/name
sudo mkdir /usr/local/hadoop/tmp/dfs/data
2. 對2個組態檔 core-site.xml 和 hdfs-site.xml進行修改,
(1)打開組態檔 core-site.xml,在這里使用gedit,也可以使用vim編輯,
gedit core-site.xml
在配置core-site.xml 的檔案中找到下面的標簽對:
<configuration>
</configuration>
(2)修改為下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.
</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(3)打開組態檔hdfs-site.xml ,
gedit hdfs-site.xml
在配置 hdfs-site.xml的檔案中找到下面的標簽對:
<configuration>
</configuration>
(4)修改為下面配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value> </property>
</configuration>
3. 格式化 NameNode
當我們配置完core-site.xml 和 hdfs-site.xml,需要對NameNode進行格式化: cd /usr/local/hadoop ./bin/hdfs namenode -format 成功的話,會看到 “successfully formatted” 的提示,具體回傳資訊,如下圖所示,
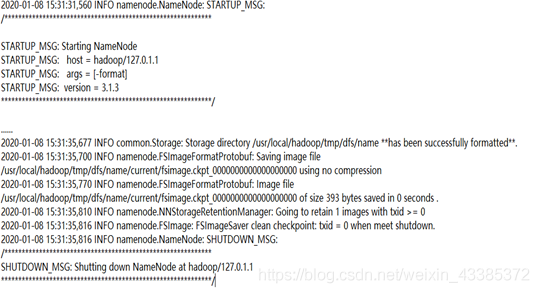
4. 開啟NameNode和DataNode守護行程
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是個完整的可執行檔案,中間沒有空格
若出現如下SSH提示,輸入yes即可,
5. 啟動Hadoop,并確定是否安裝成功,
當程式啟動完成后,可以通過命令 jps 來判斷是否成功啟動,若成功啟動則會列出如下行程: “NameNode”、”DataNode” 和 “SecondaryNameNode”, 成功啟動后,不僅可以訪問 Web 界面 http://localhost:50070查看 NameNode 和 Datanode 資訊,還可以查看 HDFS 中的檔案,
六、 呼叫MapReduce執行WordCount對單詞進行計數
1. 準備一個單詞檔案(在這里使用的是不少于10000萬單詞的文本檔案),我將這個檔案置于/usr/local/hadoop的路徑檔案夾中,以便實驗,如下圖所示,
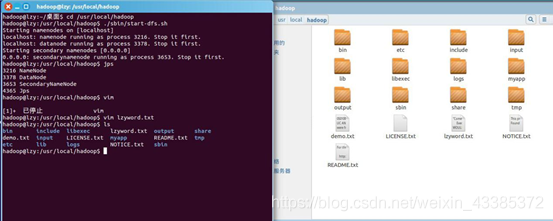
2. 將lzyword.txt上傳到HDFS中(在此步操作時注意請確保Hadoop為開啟狀態)
./bin/hdfs dfs -put /usr/local/hadoop/lzyword.txt input
3. 驗證是否上傳成功,成功可看到實驗檔案,如下圖所示,
./bin/hdfs dfs -ls input

4. 在軟體中心中,在搜索框輸入Eclipse找到對應檔案下載即可,(此步已完成安裝)
5. 安裝Hadoop-Eclipse-Plugin用于在 Eclipse 上編譯和運行 MapReduce 程式,可下載 Github 上的[hadoop2x-eclipse-plugin](https://github.com/winghc/hadoop2x-eclipse-plugin) (下載后,將release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar 復制到 Eclipse 安裝目錄的 plugins 檔案夾中,運行 eclipse -clean 重啟 Eclipse 即可,添加插件后只需要運行一次該命令,以后可以正常方式啟動),
unzip -qo ~/下載/hadoop2x-eclipse-plugin-master.zip -d ~/下載 # 解壓到 ~/下載 中
sudo cp ~/下載/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/ # 復制到 eclipse 安裝目錄的 plugins 目錄下
/usr/lib/eclipse/eclipse -clean # 添加插件后需要用這種方式使插件生效
6. 這時配置 Hadoop-Eclipse-Plugin,當執行完/usr/lib/eclipse/eclipse -clean 后,系統會自動打開Eclipse,打開后我們看到左邊的Project Explorer里出現了DFS Locations,如下圖所示,
7. 進一步配置插件
(1)Eclipse的上方找到Window->Preference,如下圖所示,
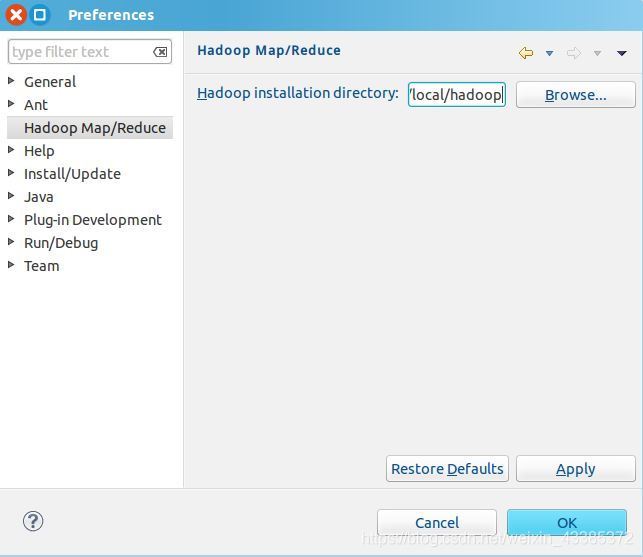
(2)這時找到Hadoop Map/Reduce,在那里填入hadoop的安裝地址/usr/local/hadoop,如下圖所示,
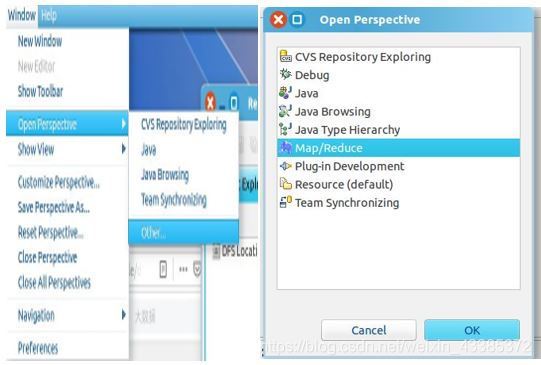
(3)我們切換 Map/Reduce 開發視圖,選擇 Window 選單下選擇 Open Perspective->Other,在里面找到Map/Reduce,如下圖所示,
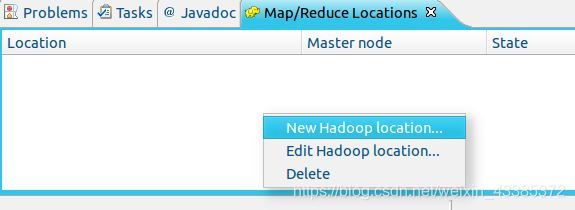
(4)這時需要連接 Hadoop 集群,點擊 Eclipse右下角的 Map/Reduce Locations 面板,在面板中單擊右鍵,選擇 New Hadoop Location,如下圖所示,
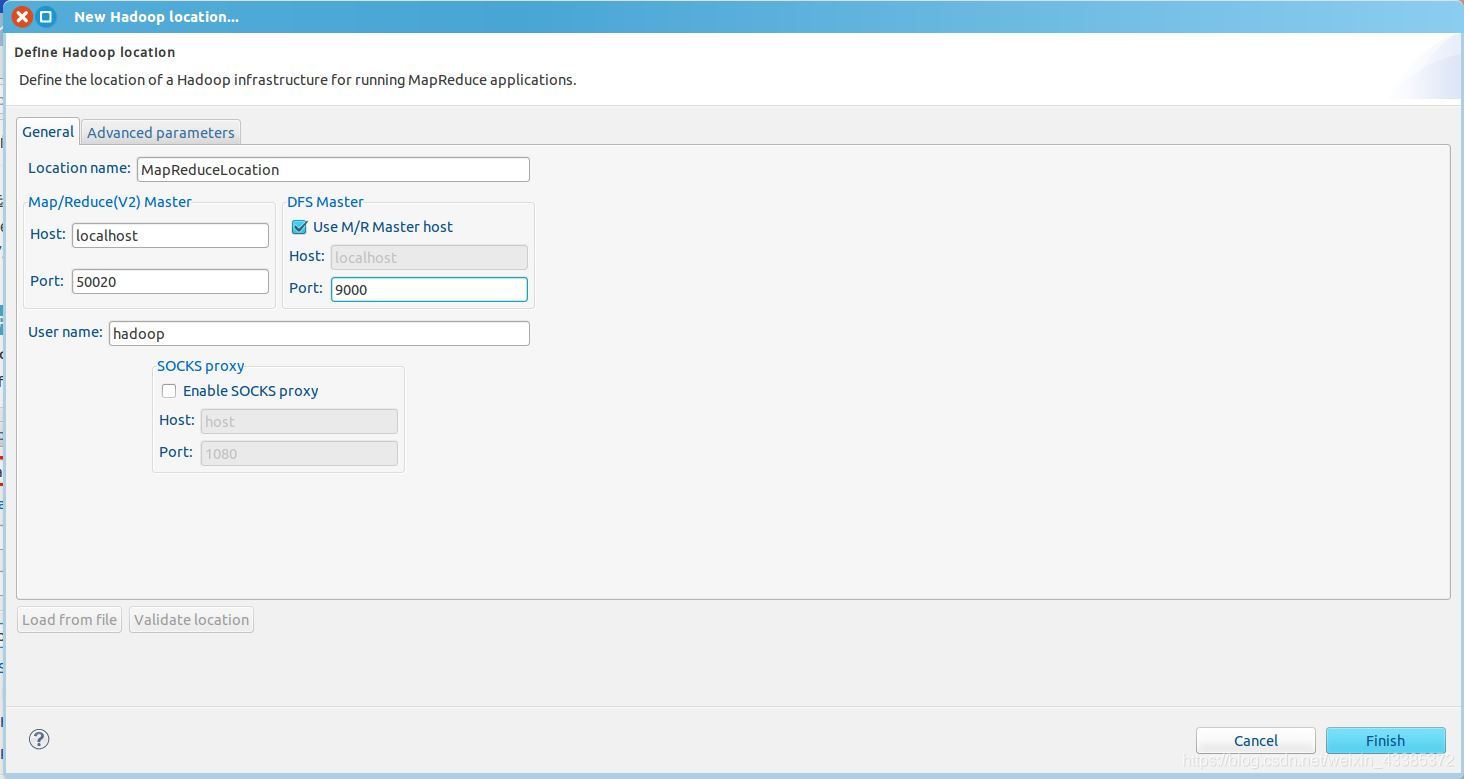
(5)會彈出來的 General 選項面板中,General 的設定要與 Hadoop 的配置一致,Host中填localhost,DFS Master 的 Port 需要改為 9000,Location name填MapReduceLocation,如下圖所示,
(6)在上述步驟配置好后,需要點擊左側 Project Explorer 中的 MapReduce Location (點擊三角形展開)就能直接查看 HDFS 中的檔案串列,如下圖所示,

(7)在 Eclipse 中創建 MapReduce 專案,點擊 File 選單,選擇 New->Project,如下圖所示,
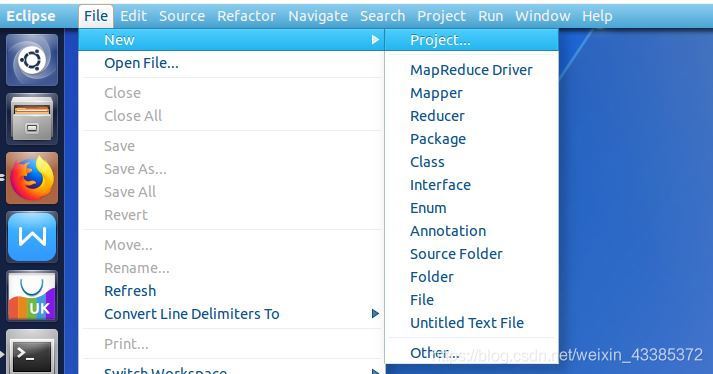
(8)選擇 Map/Reduce Project,點擊 Next,如下圖所示,
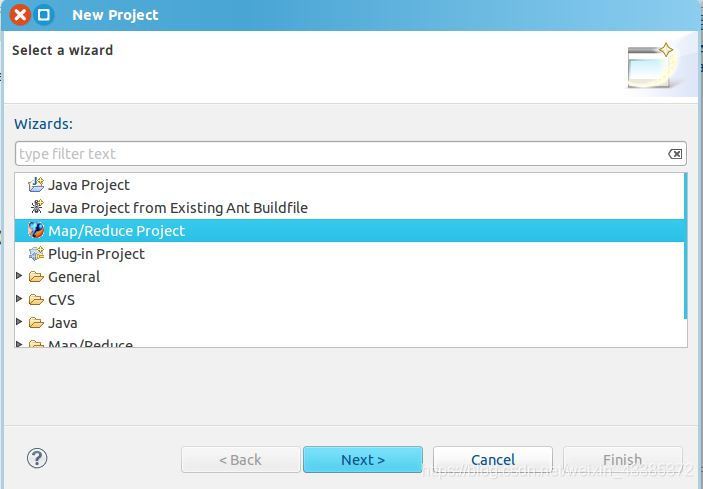
(9)寫 Project name 為 WordCount(這里命名為lzy0048WordCount) 即可,點擊 Finish 就創建好了專案,如下圖所示,
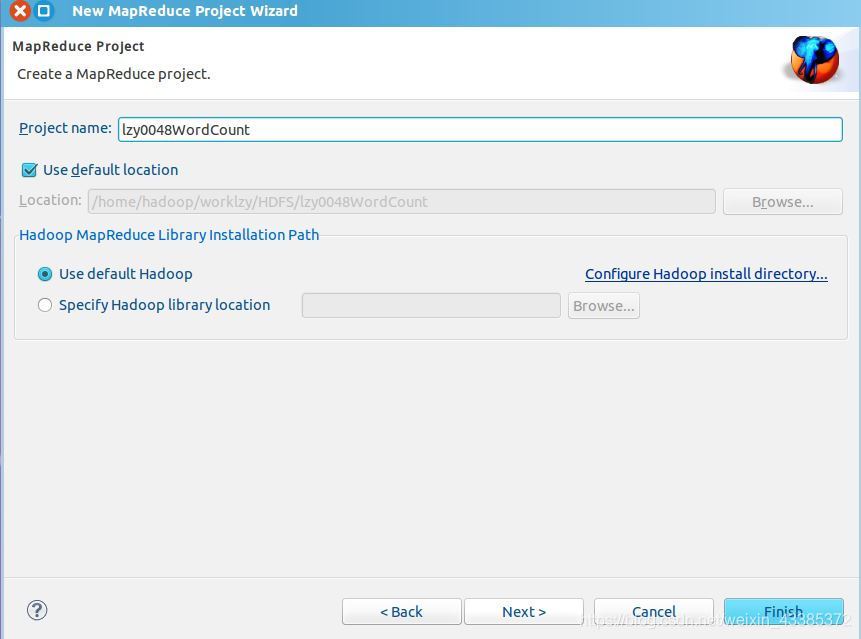
(10)下一步右鍵點擊剛創建的 lzy0048WordCount 專案,選擇 New->Class,如下圖所示,
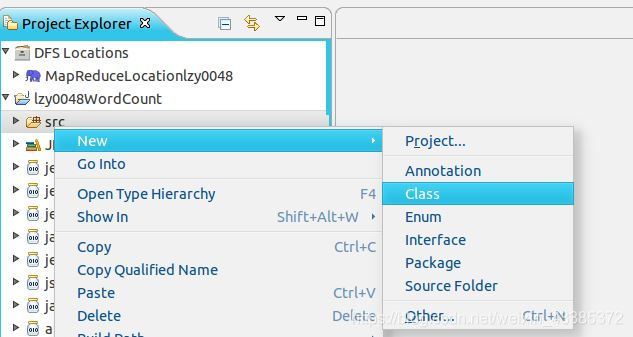
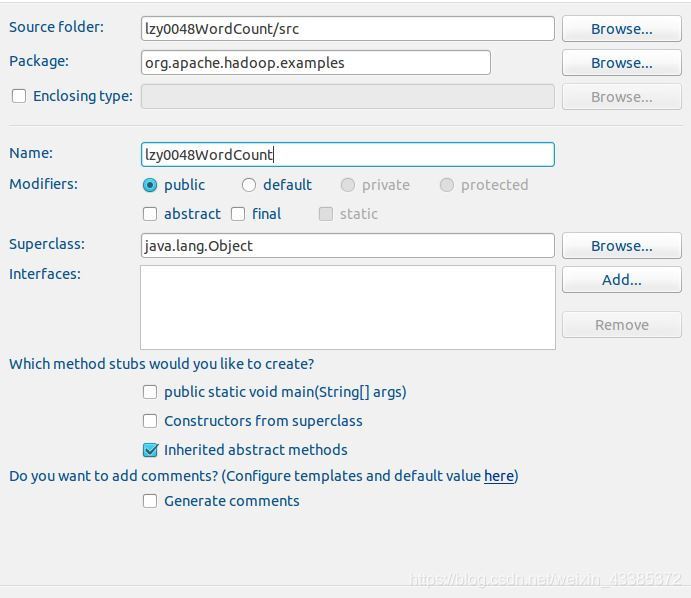
(11)在 Package 處填寫 org.apache.hadoop.examples;在 Name 處填寫 lzy0048WordCount,如下圖所示,
(12)需要將 /usr/local/hadoop/etc/hadoop 中將有修改過的組態檔(如偽分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 復制到 lzy0048WordCount專案下的 src 檔案夾(~/worklzy/HDFS/lzy0048WordCount/src)中,在終端中輸入下列幾行內容:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/worklzy/HDFS/lzy0048WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/worklzy/HDFS/lzy0048WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/worklzy/HDFS/lzy0048WordCount/src
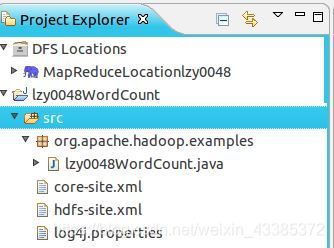
當復制完成后,右鍵點擊 lzy0048WordCount選擇 refresh 進行重繪一下,可看到src中多出了幾個檔案,就如下圖所示,
(13)將如下 lzy0048WordCount的代碼復制到該lzy0048WordCount.java檔案中,
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class lzy0048WordCount{
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"};
if(otherArgs.length < 2) {
System.err.println("Usage: lzy0048WordCount<in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
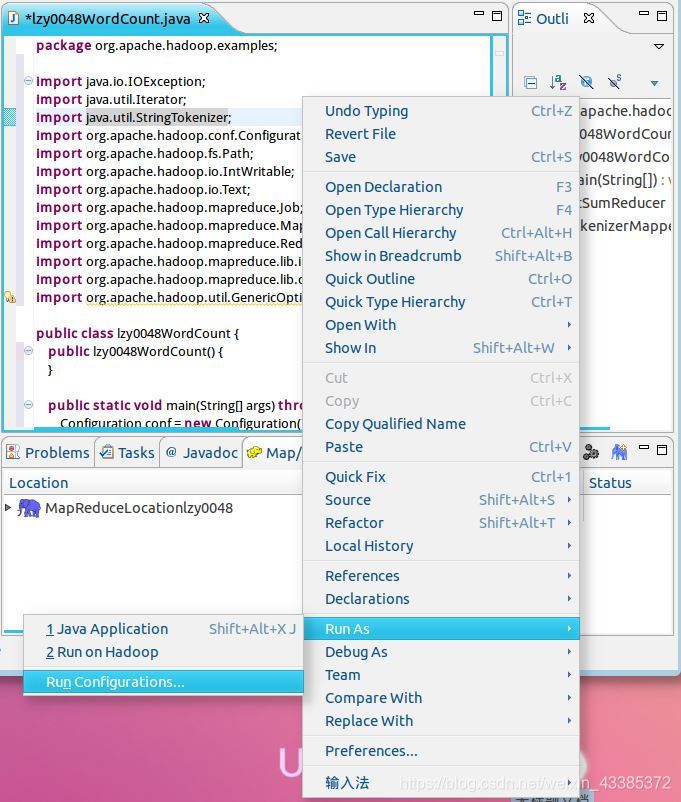
(13)在lzy0048WordCount.java的代碼檔案中,右鍵選擇Run As——Run Configurations...,就可以運行 MapReduce 程式了(運行檔案前,務必把Hadoop啟動),如下圖所示,
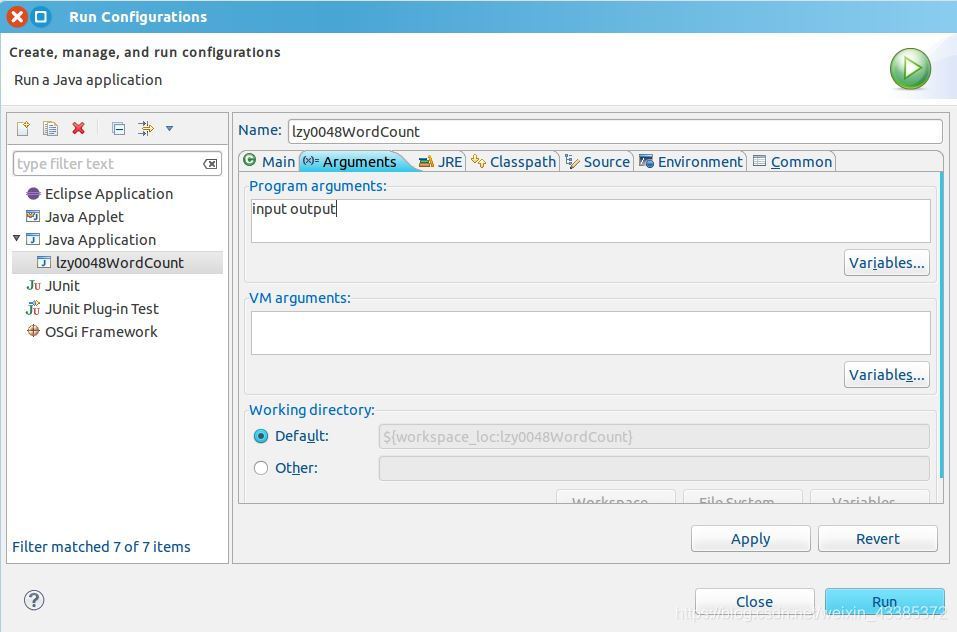
(14)在此處可以設定運行時的相關引數(如果 Java Application 下面沒有 lzy0048WordCount,那么需要先雙擊 Java Application),切換到 “Arguments” 欄,在 Program arguments 處填寫 “input output” 就可以了,如下圖所示,
(15)程式執行完畢后,我們就可以在output--part-r-00000這個檔案中就可以看到輸出結果了,
除了以上的方法,也可以使用輸入下面命令進行查看,如下圖所示,
cd /usr/local/hadoop
./bin/hdfs dfs -cat output/part-r-00000
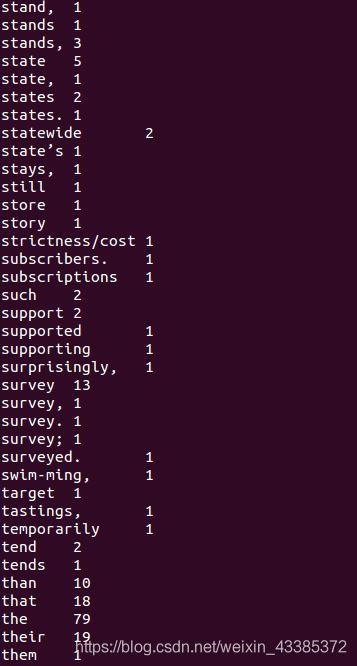
輸入下面命令,可以把HDFS中檔案下載到本地檔案系統中的“/home/hadoop/下載/”這個目錄下,如下圖所示,
./bin/hdfs dfs -get output/part-r-00000 /home/hadoop/下載
七、 個人總結
此次實驗,我在Ubuntu Kylin系統中使用 Eclipse 開發 MapReduce 程式對單詞計數的實驗操作,從Ubuntu的安裝到WordCount的案例操作,讓我對每個部分進行理解和實踐,包括如何配置jdk,java,Hadoop、MapReduce,Eclipse,插件等,同時在CSDN上分享了自己的步驟,有利于課程結束后回顧溫習, 以上就是我要分享的內容,如有錯誤,請多指教,
八、 參考資料
[1] http://dblab.xmu.edu.cn/blog/285/
[2]http://dblab.xmu.edu.cn/blog/290-2/
[3]http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233991.html
標籤:其他