轉載請注明出處
背景
在互聯網公司中,每個專案都需要資料統計、分析,便于專案組利用詳細資料研究專案的整體情況,進行下一步的調整,在資料統計中,UV統計是最常見的,也是最普遍的,有的場景要求實時性很高,有點場景要求準確性很高,有的場景比較在意計算程序中的記憶體,不同的場景使用不同的演算法,下面我們從0到1簡單介紹下UV統計領域,
什么是UV統計
假設我們的場景是商家這邊上架一系列水果,然后需要統計出一共上架幾種水果,具體如下所示:
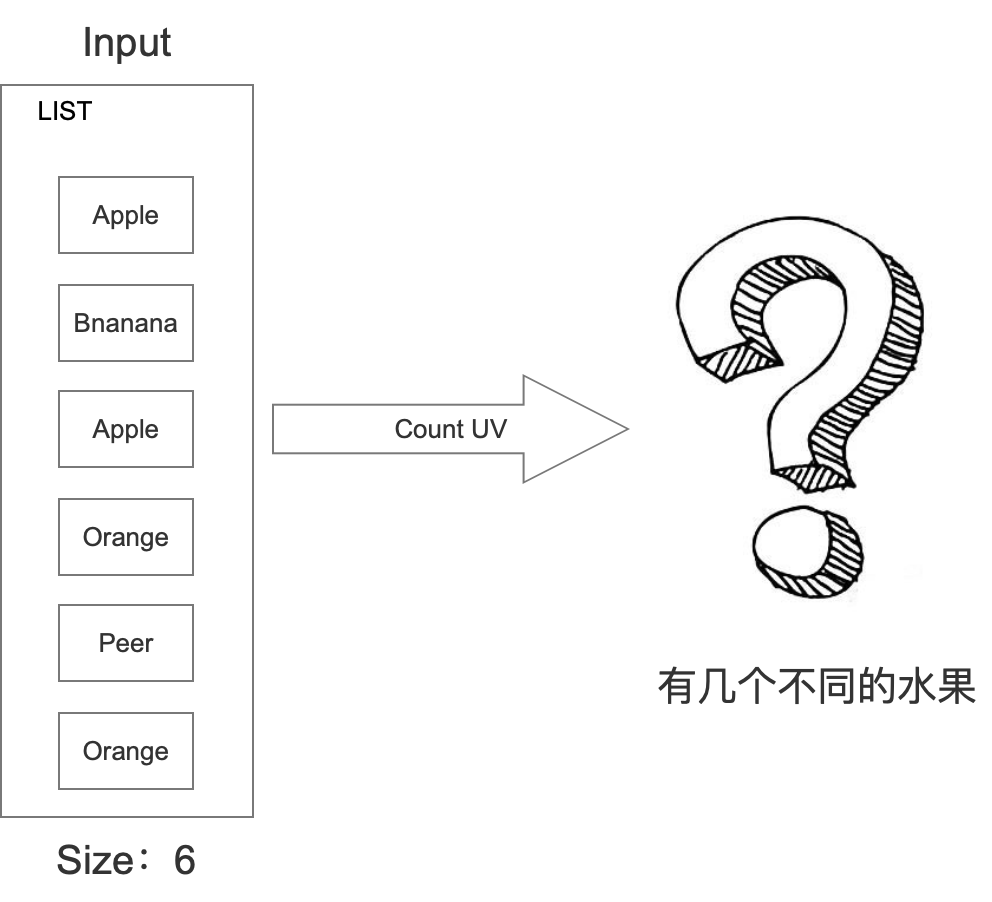
針對這個問題,我們想到的最簡單的方式就是利用STL中的set處理,
SET
上架一個水果的時候,也同時在set中插入,最后需要統計的時候,直接計算set中一共有幾個水果即可,具體如下所示:
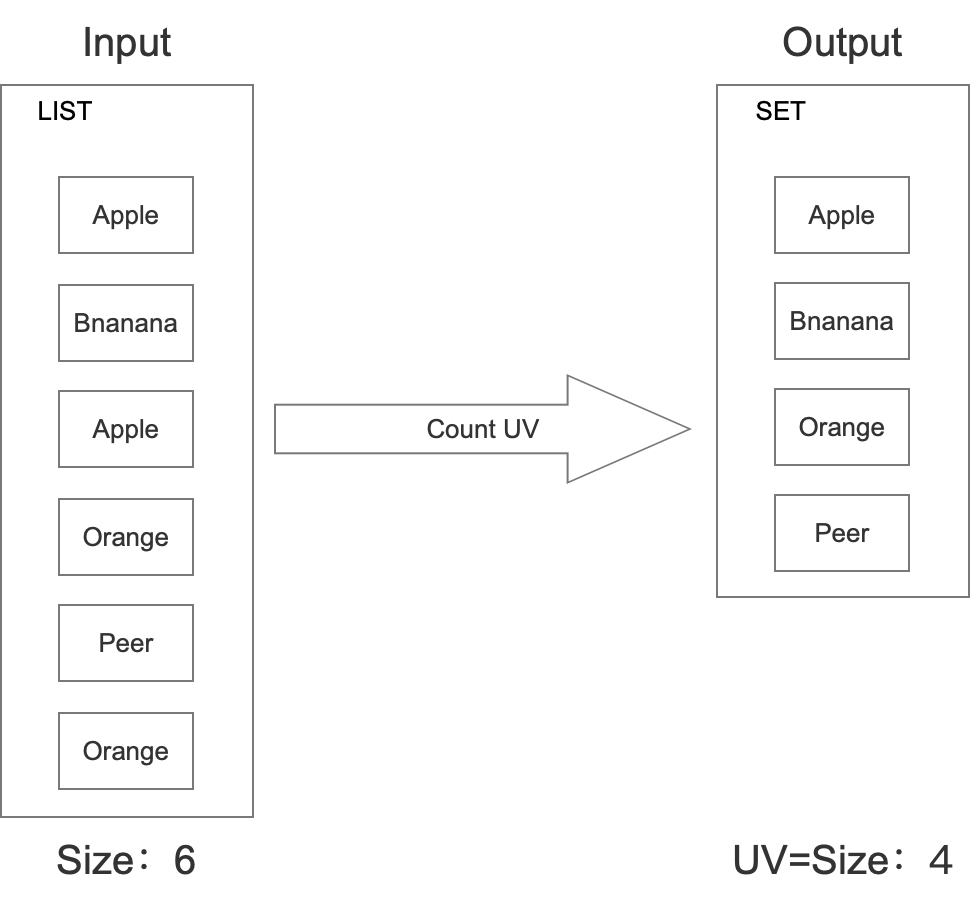
這種方式準確率是絕對準確的,但是這種方式耗費的記憶體是很大的,
假設每個水果需要 K 位元組,那么如果有 M 個水果,一共需要 K * M 位元組,那么我們能不能縮小這里的記憶體呢?
稍微損失一點準確率換取記憶體?具體見下面HashMap的方式
HASHMAP
這種演算法在上架一個水果的時候,只需要在特定的位置置1即可,而不需要存盤這個位置上究竟是何種水果,然后在統計的時候,只需要統計hashmap里面有多少個1即可,具體如下所示:
具體如下所示:
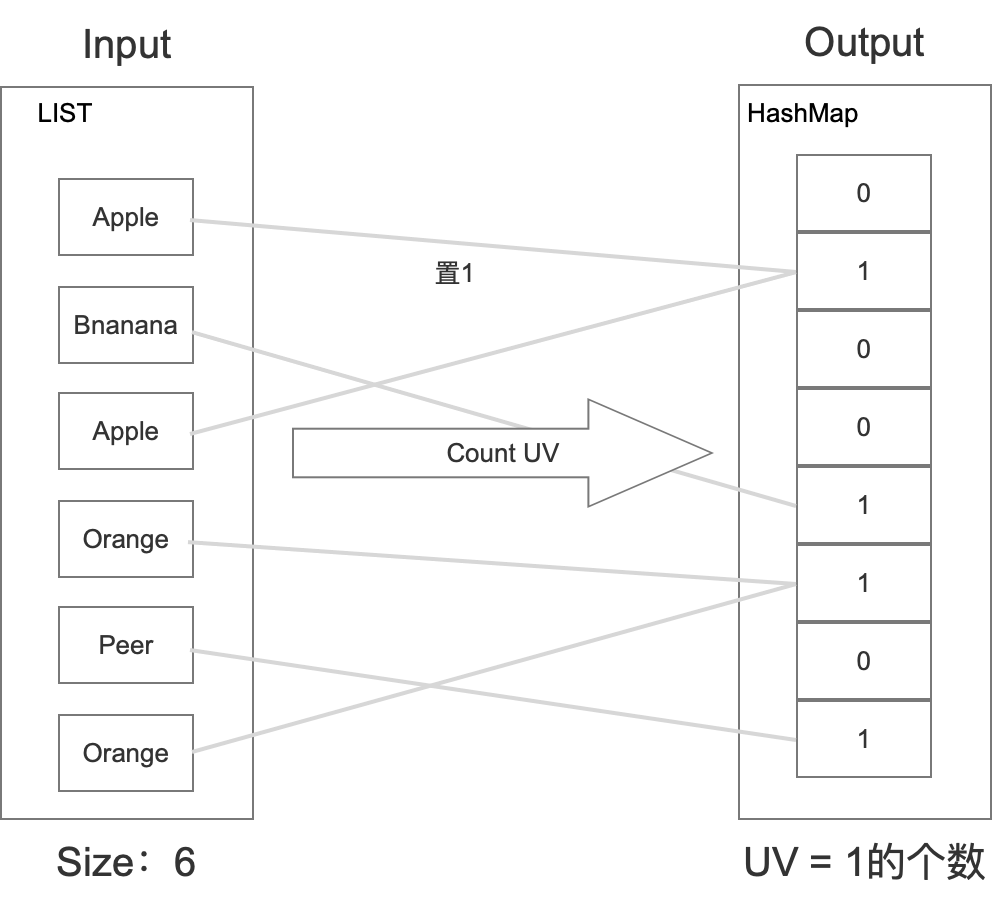
那么如果有M個水果,這里其實只需要 M / 8 位元組,相比set的方式記憶體直接縮小到1/8,當然Hash肯定會有沖突的,所以這里肯定有一定準確率的損失,
但是如果涉及到海量資料的UV統計,這里的記憶體還是很大的,
能否用上統計學進一步縮小記憶體呢?具體見下面的Linear Count的方式,
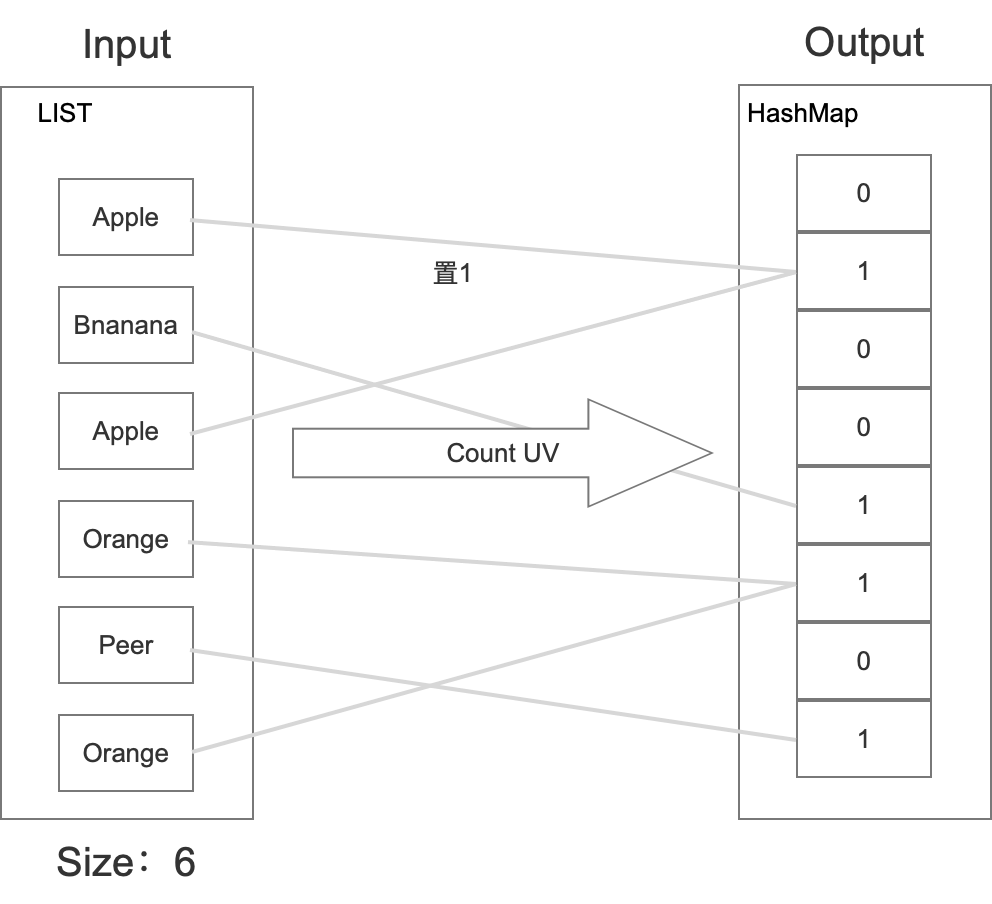
Linear Count
這種演算法在上架一個水果的時候,完全跟hashmap一致,在相應位置置1,
然后在統計的時候,利用統計學的方式,根據hashmap中零的個數給出一個估算值,具體如下所示:
假設M為哈希桶長度,那么每次上架水果,每個桶被選中的概率為:
$$\frac{1}{M}$$
然后在上架N個元素后,某個桶為0的概率為:
$$(1-\frac{1}{M}) ^N$$
所以在上架n個元素后,哈希桶中零的個數期望為:
$$ZeroNum=\sum_{i=1}^M (1-\frac{1}{M}) ^N = M (1-\frac{1}{M}) ^N= M ((1+\frac{1}{-M}){-M}){-\frac{N}{M}}) \approx Me^{- \frac{N}{M}}$$
所以最終:
$$
N = UV = -M ln(\frac{ZeroNum}{M})
$$
所以Linear Count演算法中,只需統計下hashmap中零的個數,然后代入上式即可,
這種演算法在N很小的時候,準確率是很高的,但是N很大的時候,它的準確率急劇下降,
針對海量資料的情況,LogLog Count的演算法更加魯棒
LogLog Count
這種演算法跟上面幾種都不同,上架水果的時候,在相應桶里面記錄的是二進制數后面最長的連續零個數,然后統計的時候,利用統計學的方式,根據存盤中最長連續后綴零個數,得出一個估計值,具體如下所示:
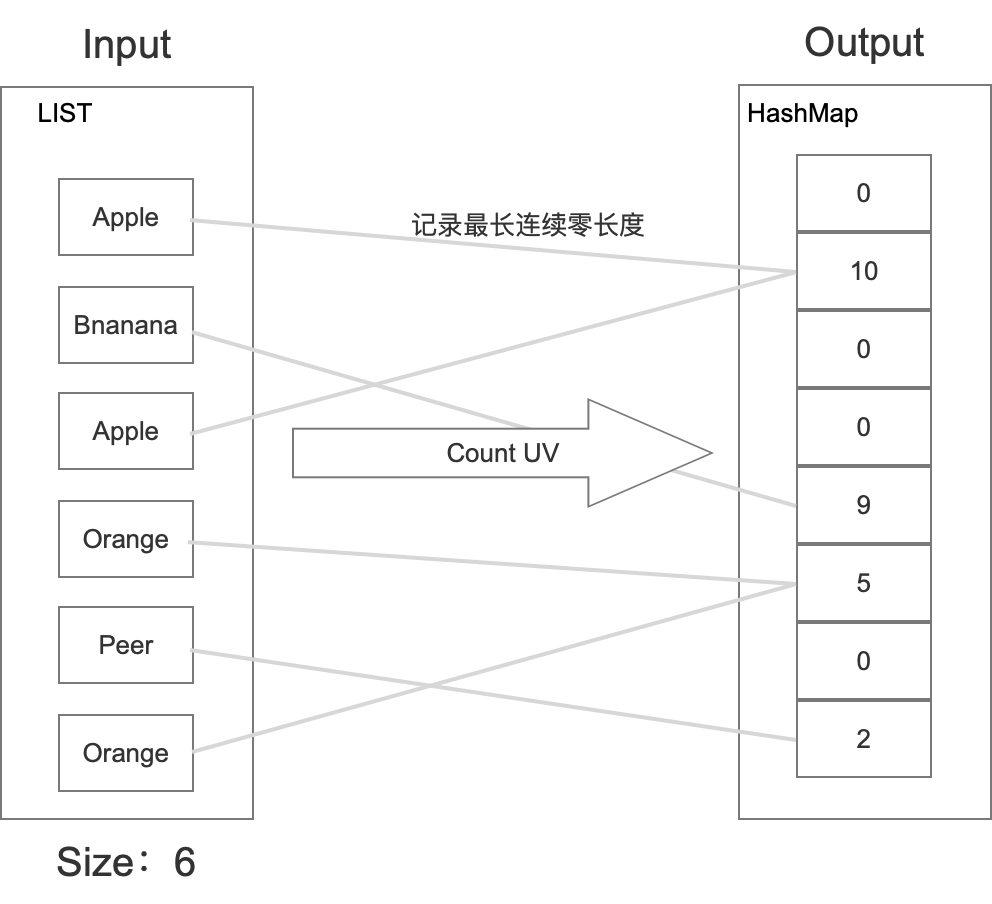
它的原理如下:


這里如果只使用一個桶來估計的話,它的誤差是很大,需要用分桶平均的方式來減少它的誤差,
分桶平均
既然這里利用了分桶來減少誤差,那么這里統計的時候就必須合起來,這里有4種方式:
- 算術平均:$$UV=\frac{\sum_{j=1}^mUV_j} { m}$$
- 幾何平均:$$UV=\sqrt[m]{UV_1...UVm}$$
- 調和平均:$$UV=\frac{m}{\sum_{j=1}mUV_j{-1}}$$
- 中位數:$$UV=mediam {UV_1,...,UV_m}$$
LogLog Count利用的是算術平均的方式,所以最終估計值為:
$$UV=2{\frac{\sum_{j=1}m{UV_j}}{m}}$$
這種演算法對于基數大的情況下準確率挺高的,但是基數小的情況下準確率很低,
HyperLogLog Count
這種演算法跟LogLog Count 類似,有個區別點就是它在求均值的時候利用了調和平均數,而不是算術平均數,這里最終估計值為:
$$UV=mm(\sum_{j=1}m{2{-M_j}})^{-1}$$
然后它還引入了分段誤差修正,
誤差修正

具體可以看我github上的代碼:HyperLogLog
總結
| 準確率 | 記憶體 | 耗時 | |
|---|---|---|---|
| Set | 絕對準確 | K * M | O(Mlog(M)) |
| HashMap | 很高 | M/8 | O(M) |
| Linear Count | 基數小高,基數大低 | M/8 | O(M/8) |
| LogLog Count | 基數小低,基數大高 | ||
| HyperLogLog Count | 高 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234178.html
標籤:其他
下一篇:大資料開發-數倉ads層指標計算