文章目錄
- 1. 原理
- 2. 公式
- 2.1 二分類
- 2.2 多分類
- 3. 參考
1. 原理
該方法假設特征子集的重要性是由子集中的每個特征所對應的相關統計分量之和所決定的,
所以只需要選擇前 k k k 個大的相關統計量對應的特征,或者大于某個閾值的相關統計量對應的特征即可,
2. 公式
2.1 二分類
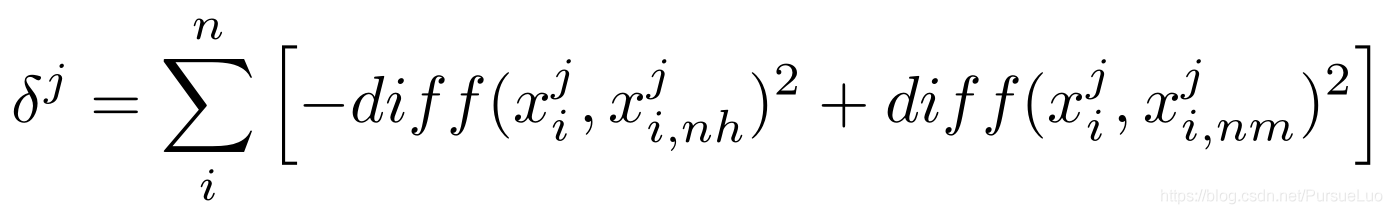
其中:
δ j \delta_j δj? :屬性 j j j 的相關統計量;
x i j x_i^j xij?:樣本 x i x_i xi? 中屬性 j j j 的值;
x i , n h j x_{i,nh}^j xi,nhj?:樣本 x i x_i xi? 的 “猜中近鄰” x i , n h x_{i,nh} xi,nh? 中屬性 j j j 的值;
x i , n m j x_{i,nm}^j xi,nmj?:樣本 x i x_i xi? 的 “猜錯近鄰” x i , n m x_{i,nm} xi,nm? 中屬性 j j j 的值;
d i f f ( x i j , x i , n h j ) diff(x_i^j,x_{i,nh}^j) diff(xij?,xi,nhj?):樣本 x i x_i xi? 和 x i , n h x_{i,nh} xi,nh? 在屬性 j j j 上值的差異;
d i f f ( x i j , x i , n m j ) diff(x_i^j,x_{i,nm}^j) diff(xij?,xi,nmj?):樣本 x i x_i xi? 和 x i , n m x_{i,nm} xi,nm? 在屬性 j j j 上值的差異;
若屬性值為離散型,則 d i f f diff diff 當且僅當屬性值相等時為 0,否則為 1;若屬性值為連續型,則 d i f f diff diff 表示為距離,
2.2 多分類
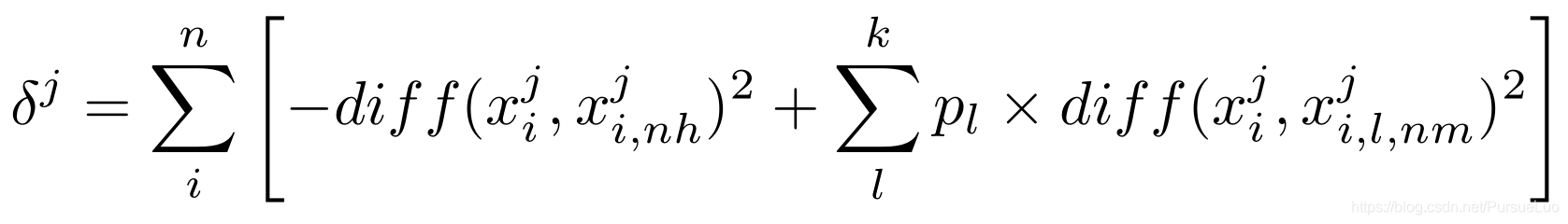
δ
j
\delta_j
δj? :屬性
j
j
j 的相關統計量;
x i j x_i^j xij?:樣本 x i x_i xi? 中屬性 j j j 的值;
x i , n h j x_{i,nh}^j xi,nhj?:樣本 x i x_i xi? 的 “猜中近鄰” x i , n h x_{i,nh} xi,nh? 中屬性 j j j 的值;
p l p_l pl?:第 l l l 類樣本的比例;
x i , l , n m j x_{i,l,nm}^j xi,l,nmj?:樣本 x i x_i xi? 的第 l l l 類的 “猜錯近鄰” x i , l , n m x_{i,l,nm} xi,l,nm? 中屬性 j j j 的值;
d i f f ( x i j , x i , n h j ) diff(x_i^j,x_{i,nh}^j) diff(xij?,xi,nhj?):樣本 x i x_i xi? 和 x i , n h x_{i,nh} xi,nh? 在屬性 j j j 上值的差異;
d i f f ( x i j , x i , l , n m j ) diff(x_i^j,x_{i,l,nm}^j) diff(xij?,xi,l,nmj?):樣本 x i x_i xi? 和 x i , l , n m x_{i,l,nm} xi,l,nm? 在屬性 j j j 上值的差異;
3. 參考
知乎:特征選擇–我要鼓勵娜扎
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234227.html
標籤:其他
上一篇:Java之系統知識體系的構建
下一篇:unexpected EOF, expected 455433 more bytes. The file might be corrupted.解決方案