轉載請表明出處
背景
對 布隆過濾器 畫個重點,它應該在 “過濾” 二字上,這個演算法的重點在于把曾經來過跟從未來過的事物區分開,具體過濾那種事物(曾經來過or從未來過),由具體場景決定,它一般用于資料庫存盤中過濾不存在的行(減少訪問磁盤),推薦系統去重等等場景,
SET
說到去重,很容易想到STL中的SET容器,它本身自帶去重功能,而且還能查詢,
那么最簡單的方式,直接用SET,每次操作的時候,先查詢該事物是否存在?
- 如果存在直接回傳“存在”結果,
- 如果不存在就插入其中,然后再回傳“不存在”結果,
具體如下圖所示:
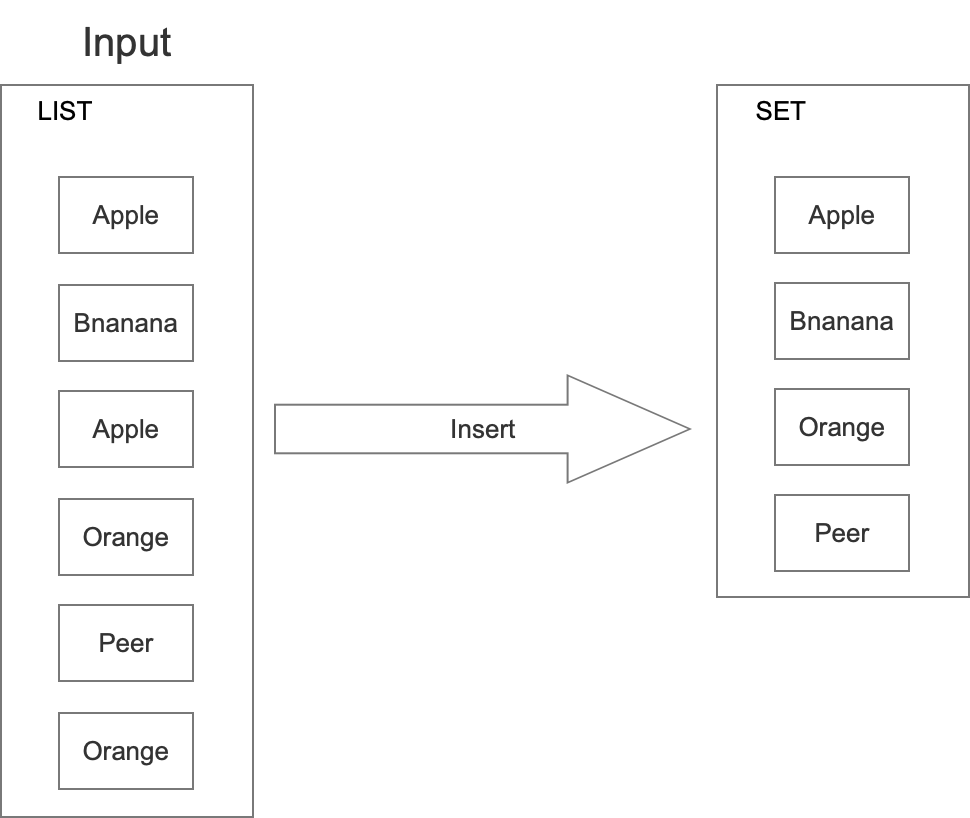
這種方式準確率是絕對準確的,但是這種方式耗費的記憶體也是巨大的,
假設每個事物需要 K 位元組,那么如果有 M 個事物,一共需要 K * M 位元組,那么我們能不能縮小這里的記憶體呢?
稍微損失一點準確率換取記憶體?具體見下面HashMap的方式
HashMap
在上一種方式中,它存盤了具體的事物資訊,其實在我們這個場景中是不需要的,我們需要的只是這個事物是否存在就行了,所以HashMap的方式誕生了,
這種演算法在每次操作的時候,先查詢該事物是否存在,
- 如果存在回傳“存在”結果,
- 如果不存在就在特定位置置1,然后再回傳“不存在”結果,
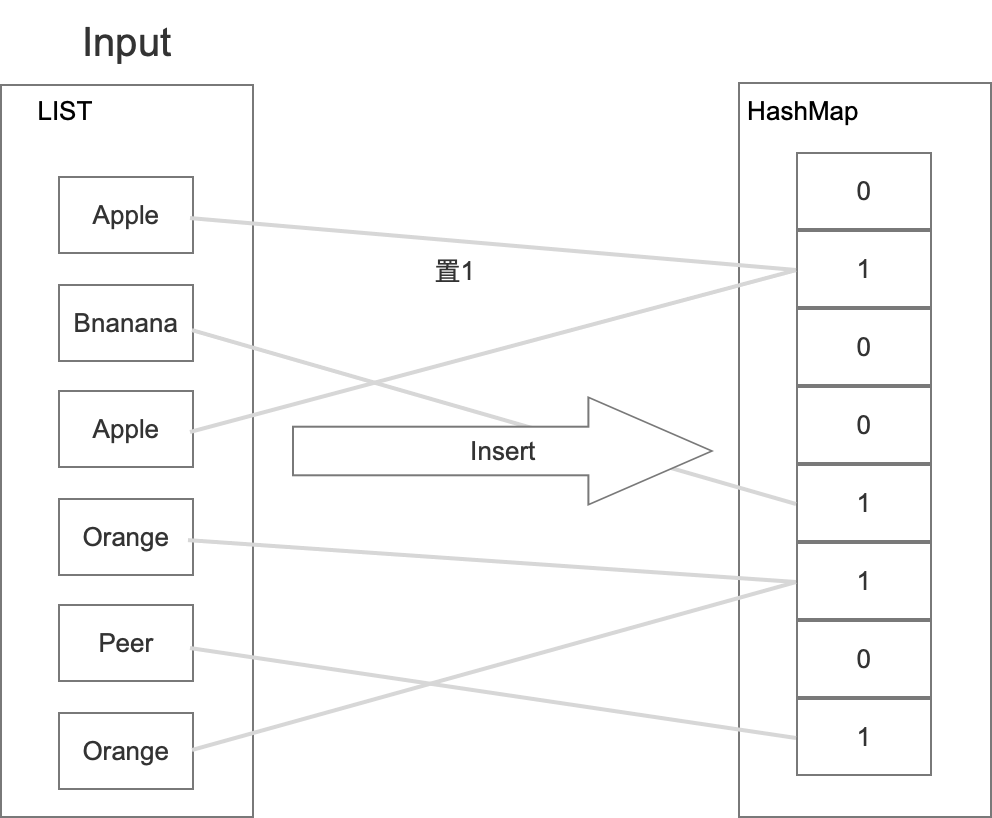
眾所周知,hash都是有一定概率沖突的,而且當哈希桶快滿的時候,沖突率更高,
接下來我們來看看這里的沖突率有多少?假設哈希桶長度為M,那么每次插入到特定一個桶的概率是:$$(1-\frac{1}{M})$$
而沒有插入特定桶的概率是:$$1-(1-\frac{1}{M})$$
然后假設目前已經插入N個事物,那么特定桶中為0的概率是:$$(1-\frac{1}{M})^N$$
特定桶中為1的概率是:$$1-(1-\frac{1}{M})^N$$
假設現在要新插入一個事物,這次插入的沖突率就是:
\[1-(1-\frac{1}{M})^N = 1- ((1+\frac{1}{-M})^{-M})^{-\frac{N}{M}} \approx 1 - e^{-\frac{N}{M}} \]所以這里在N接近M的時候,沖突率是很高的,這種演算法就完全失效了,
有沒有辦法解決這種情況呢?布隆過濾器能降低這里沖突率,
布隆過濾器
布隆過濾器是用了多hash的方式降低了沖突率的,
這種演算法在每次操作的時候,先查詢該事物在K個hash桶中是否都存在,
- 如果存在回傳“存在”結果,
- 如果有一個桶不存在,就在K個hash桶中全部置1,然后再回傳“不存在”結果,
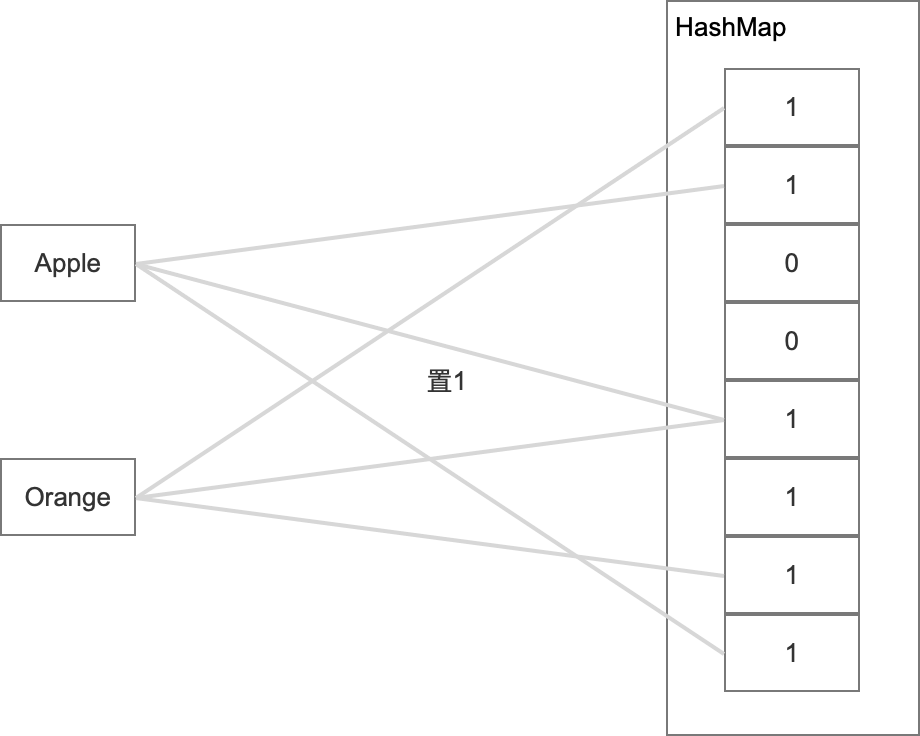
接下來我們來看看這種有K個Hash加持的演算法,沖突率有多少?假設哈希桶長度為M,那么每次插入到特定一個桶的概率是:$$K (1-\frac{1}{M})$$
而沒有插入特定桶的概率是:$$(1-(1-\frac{1}{M}))^K$$
然后假設目前已經插入N個事物,那么特定桶中為0的概率是:$$(1-\frac{1}{M})^{NK}$$
特定桶中為1的概率是:$$1-(1-\frac{1}{M})^{NK}$$
假設現在要新插入一個事物,這次插入的沖突率就是:
由于這里有K次方的加持,它的沖突率小很多的,
一般來說,在使用布隆過濾器的時候,N是由場景已經決定了的,怎么選擇M跟K呢?
P為沖突率
由于布隆過濾器都是直接置1,所以它根本無法洗掉一個事物的,有沒有辦法支持它洗掉+統計個數呢?
布隆過濾器升級版
想要洗掉特定事物,那其實也很簡單,
直接把布隆過濾器的位存盤改成數字存盤就行了,
那么在每次操作的時候,跟布隆過濾器差別的點在于:
- 無論是否存在都在K個hash桶中加1,
- 然后在需要洗掉的時候,就在K個hash桶中減1,
具體如下圖所示:
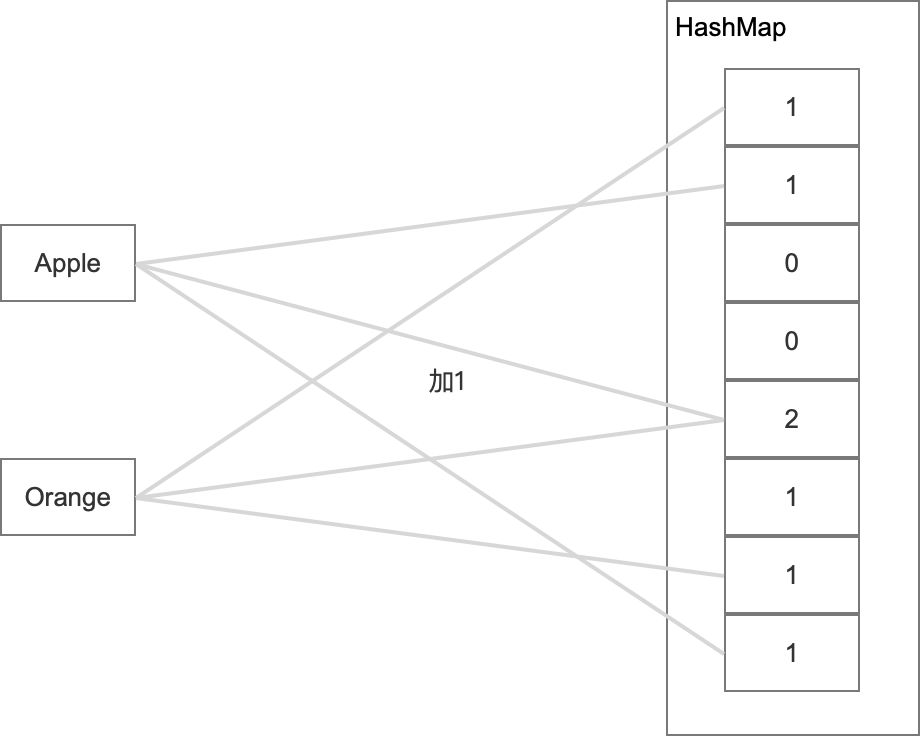
這種演算法是已經支持洗掉+統計了,相應的它的記憶體占用可不是翻倍這么簡單的,
不同的場景用不同的演算法吧,最合適的才是效果最好滴,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234706.html
標籤:其他
下一篇:不復雜的時間復雜度