前言:近年來,音視頻會議產品提升著作業協同的效率,在線教育產品突破著傳統教育形式的種種限制,娛樂互動直播產品豐富著生活社交的多樣性,背后都離不開音視頻通信技術的優化與創新,其中音頻資訊內容傳遞的流暢性、完整性、可懂度直接決定著用戶之間的溝通質量,自 2011 年 WebRTC 開源以來,無論是其技術架構,還是其中豐富的演算法模塊都是值得我們細細品味,音頻方面熟知的 3A 演算法(AGC: Automatic gain control; ANS: Adaptive noise suppression; AEC: Acoustic echo cancellation)就是其中閃閃發光的明珠,本文章將結合實體全面決議 WebRTC AEC 的基本框架和基本原理,一起探索回聲消除的基本原理,技術難點以及優化方向,
作者:珞神,阿里云高級開發工程師,負責阿里云 RTC 音頻研發
回聲的形成
WebRTC 架構中上下行音頻信號處理流程如圖 1,音頻 3A 主要集中在上行的發送端對發送信號依次進行回聲消除、降噪以及音量均衡(這里只討論 AEC 的處理流程,如果是 AECM 的處理流程 ANS 會前置),AGC 會作為壓限器作用在接收端對即將播放的音頻信號進行限幅,
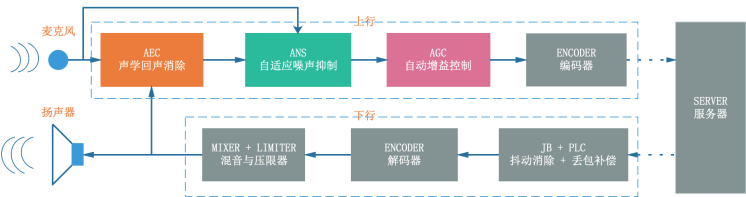
那么回聲是怎么形成的呢?
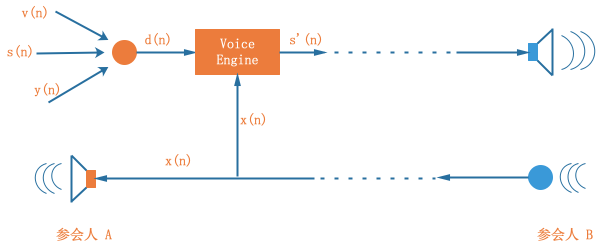
如圖 2 所示,A、B 兩人在通信的程序中,我們有如下定義:
- x(n): 遠端參考信號,即 A 端訂閱的 B 端音頻流,通常作為參考信號;
- y(n): 回聲信號,即揚聲器播放信號 x(n) 后,被麥克風采集到的信號,此時經過房間混響以及麥克風采集的信號 y(n) 已經不能等同于信號 x(n) 了, 我們記線性疊加的部分為 y'(n), 非線性疊加的部分為 y''(n), y(n) = y'(n) + y''(n);
- s(n): 麥克風采集的近端說話人的語音信號,即我們真正想提取并發送到遠端的信號;
- v(n):環境噪音,這部分信號會在 ANS 中被削弱;
- d(n): 近端信號,即麥克風采集之后,3A 之前的原始信號,可以表示為:d(n) = s(n) + y(n) + v(n);
- s'(n): 3A 之后的音頻信號,即準備經過編碼發送到對端的信號,
WebRTC 音頻引擎能夠拿到的已知信號只有近端信號 d(n) 和遠端參考信號 x(n),
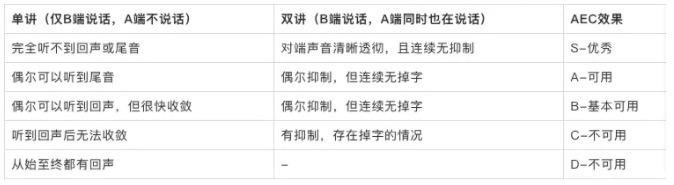
如果信號經過 A 端音頻引擎得到 s'(n) 信號中依然殘留信號 y(n),那么 B 端就能聽到自己回聲或殘留的尾音(回聲抑制不徹底留下的殘留),AEC 效果評估在實際情況中可以粗略分為如下幾種情況(專業人員可根據應用場景、設備以及單雙講進一步細分):
回聲消除的本質
在決議 WebRTC AEC 架構之前,我們需要了解回聲消除的本質是什么,音視頻通話程序中,聲音是傳達資訊的主要途徑,因此從復雜的錄音信號中,通過信號處理的手段使得我們要傳遞的資訊:高保真、低延時、清晰可懂是一直以來追求的目標,在我看來,回聲消除,噪聲抑制和聲源分離同屬于語音增強的范疇,如果把噪聲理解為廣義的噪聲三者之間的關系如下圖:
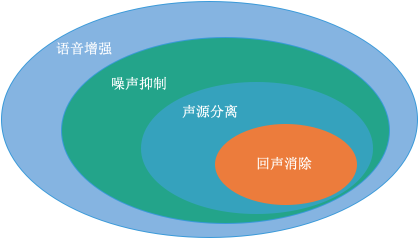
噪聲抑制需要準確估計出噪聲信號,其中平穩噪聲可以通過語音檢測判別有話端與無話端的狀態來動態更新噪聲信號,進而參與降噪,常用的手段是基于譜減法(即在原始信號的基礎上減去估計出來的噪聲所占的成分)的一系列改進方法,其效果依賴于對噪聲信號估計的準確性,對于非平穩噪聲,目前用的較多的就是基于遞回神經網路的深度學習方法,很多 Windows 設備上都內置了基于多麥克風陣列的降噪的演算法,效果上,為了保證音質,噪聲抑制允許噪聲殘留,只要比原始信號信噪比高,噪且聽覺上失真無感知即可,
單聲道的聲源分離技術起源于傳說中的雞尾酒會效應,是指人的一種聽力選擇能力,在這種情況下,注意力集中在某一個人的談話之中而忽略背景中其他的對話或噪音,該效應揭示了人類聽覺系統中令人驚奇的能力,即我們可以在噪聲中談話,科學家們一直在致力于用技術手段從單聲道錄音中分離出各種成分,一直以來的難點,隨著機器學習技術的應用,使得該技術慢慢變成了可能,但是較高的計算復雜度等原因,距離 RTC 這種低延時系統中的商用還是有一些距離,
噪聲抑制與聲源分離都是單源輸入,只需要近端采集信號即可,傲嬌的回聲消除需要同時輸入近端信號與遠端參考信號,有同學會問已知了遠端參考信號,為什么不能用噪聲抑制方法處理呢,直接從頻域減掉遠端信號的頻譜不就可以了嗎?
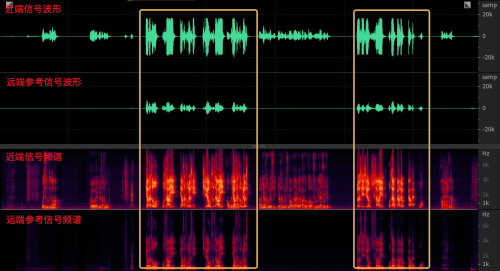
上圖中第一行為近端信號 s(n),已經混合了近端人聲和揚聲器播放出來的遠端信號,黃色框中已經標出對齊之后的遠端信號,其語音表達的內容一致,但是頻譜和幅度(明顯經過揚聲器放大之后聲音能量很高)均不一致,意思就是:參考的遠端信號與揚聲器播放出來的遠端信號已經是“貌合神離”了,與降噪的方法相結合也是不錯的思路,但是直接套用降噪的方法顯然會造成回聲殘留與雙講部分嚴重的抑制,接下來,我們來看看 WebRTC 科學家是怎么做的吧,
信號處理流程
WebRTC AEC 演算法包含了延時調整策略,線性回聲估計,非線性回聲抑制 3 個部分,回聲消除本質上更像是音源分離,我們期望從混合的近端信號中消除不需要的遠端信號,保留近端人聲發送到遠端,但是 WebRTC 工程師們更傾向于將兩個人交流的程序理解為一問一答的交替說話,存在遠近端同時連續說話的情況并不多(即保單講輕雙講),
因此只需要區分遠近端說話區域就可以通過一些手段消除絕大多數遠端回聲,至于雙講恢復能力 WebRTC AEC 演算法提供了 {kAecNlpConservative, kAecNlpModerate, kAecNlpAggressive} 3 個模式,由低到高依次代表不同的抑制程度,遠近端信號處理流程如圖 4:
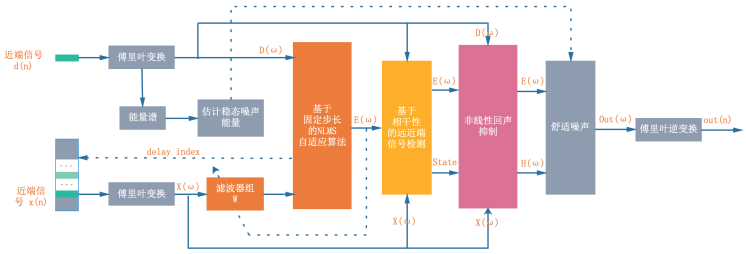
NLMS 自適應演算法(上圖中橙色部分)的運用旨在盡可能地消除信號 d(n) 中的線性部分回聲,而殘留的非線性回聲信號會在非線性濾波(上圖中紫色部分)部分中被消除,這兩個模塊是 Webrtc AEC 的核心模塊,模塊前后依賴,現實場景中遠端信號 x(n) 由揚聲器播放出來在被麥克風采集的程序中,同時包含了回聲 y(n) 與近端信號 x(n) 的線性疊加和非線性疊加:需要消除線性回聲的目的是為了增大近端信號 X(ω) 與濾波結果 E(ω) 之間的差異,計算相干性時差異就越大(近端信號接近 1,而遠端信號部分越接近 0),更容易通過門限直接區分近端幀與遠端幀,非線性濾波部分中只需要根據檢測的幀型別,調節抑制系數,濾波消除回聲即可,下面我們結合實體分析這套架構中的線性部分與非線性分,
線性濾波
線性回聲 y'(n) 可以理解為是遠端參考信號 x(n) 經過房間沖擊回應之后的結果,線性濾波的本質也就是在估計一組濾波器使得 y'(n) 盡可能的等于 x(n),通過統計濾波器組的最大幅值位置 index 找到與之對齊遠端信號幀,該幀資料會參與相干性計算等后續模塊,
需要注意的是,如果 index 在濾波器階數兩端瘋狂試探,只能說明當前給到線性部分的遠近端延時較小或過大,此時濾波器效果是不穩定的,需要借助固定延時調整或大延時調整使 index 處于一個比較理想的位置,線性部分演算法是可以看作是一個固定步長的 NLMS 演算法,具體細節大家可以結合原始碼走讀,本節重點講解線型濾波在整個框架中的作用,
從個人理解來看,線性部分的目的就是最大程度的消除線性回聲,為遠近端幀判別的時候,最大程度地保證了信號之間的相干值( 0~1 之間,值越大相干性越大)的可靠性,
我們記消除線性回聲之后的信號為估計的回聲信號 e(n),e(n) = s(n) + y''(n) + v(n),其中 y''(n) 為非線性回聲信號,記 y'(n) 為線性回聲,y(n) = y'(n) + y''(n),相干性的計算 (Matlab代碼):
% WebRtcAec_UpdateCoherenceSpectra →_→ UpdateCoherenceSpectra
Sd = Sd * ptrGCoh(1) + abs(wined_fft_near) .* abs(wined_fft_near)*ptrGCoh(2);
Se = Se * ptrGCoh(1) + abs(wined_fft_echo) .* abs(wined_fft_echo)*ptrGCoh(2);
Sx = Sx * ptrGCoh(1) + max(abs(wined_fft_far) .* abs(wined_fft_far),ones(N+1,1)*MinFarendPSD)*ptrGCoh(2);
Sde = Sde * ptrGCoh(1) + (wined_fft_near .* conj(wined_fft_echo)) *ptrGCoh(2);
Sxd = Sxd * ptrGCoh(1) + (wined_fft_near .* conj(wined_fft_far)) *ptrGCoh(2);
% WebRtcAec_ComputeCoherence →_→ ComputeCoherence
cohde = (abs(Sde).*abs(Sde))./(Sd.*Se + 1.0e-10);
cohdx = (abs(Sxd).*abs(Sxd))./(Sx.*Sd + 1.0e-10);
兩個實驗
(1)計算近端信號 d(n) 與遠端參考信號 x(n) 的相關性 cohdx,理論上遠端回聲信號的相干性應該更接近 0(為了方便后續對比,WebRTC 做了反向處理: 1 - cohdx),如圖 5(a),第一行為計算近端信號 d(n),第二行為遠端參考信號 x(n),第三行為二者相干性曲線: 1 - cohdx,會發現回聲部分相干值有明顯起伏,最大值有0.7,近端部分整體接近 1.0,但是有持續波動,如果想通過一條固定的門限去區分遠近端幀,會存在不同程度的誤判,反映到聽感上就是回聲(遠端判斷成近端)或丟字(近端判斷為遠端),
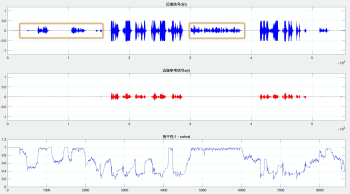
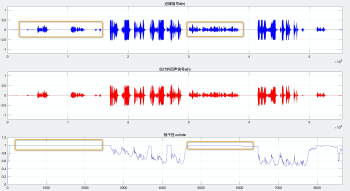
圖 5 信號的相干性
(2)計算近端信號 d(n) 與估計的回聲信號 e(n) 的相干性,如圖 5(b),第二行為估計的回聲信號 e(n),第三行為二者相干性 cohde,很明顯近端的部分幾乎全部逼近 1.0,WebRTC 用比較嚴格的門限(>=0.98)即可將區分絕大部分近端幀,且誤判的概率比較小,WebRTC 工程師設定如此嚴格的門限想必是寧可犧牲一部分雙講效果,也不愿意接受回聲殘留,
從圖 5 可以體會到,線性濾波之后可以進一步凸顯遠端參考信號 x(n) 與估計的回聲信號 e(n) 的差異,從而提高遠近端幀狀態的判決的可靠性,
存在的問題與改進
理想情況下,遠端信號從揚聲器播放出來沒有非線性失真,那么 e(n) = s(n) + v(n),但實際情況下 e(n)與d(n) 很像,只是遠端區域有一些幅度上的變化,說明 WebRTC AEC 線性部分在這個 case 中表現不佳,如圖 6(a) 從頻譜看低頻段明顯削弱,但中高頻部分幾乎沒變,而利用變步長的雙濾波器結構的結果會非常明顯,如圖 6(b) 所示無論是時域波形和頻譜與近端信號 x(n) 都有很大差異,目前 aec3 和 speex 中都采用這種結構,可見 WebRTC AEC 中線性部分還有很大的優化空間,
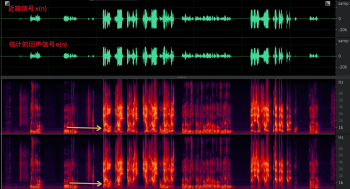
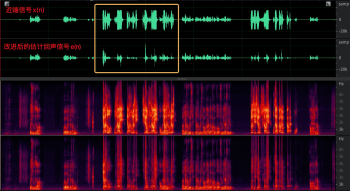
圖 6 近端信號與估計的回聲信號的對比
如何衡量改進的線性部分效果?
這里我們對比了現有的固定步長的 NLMS 和變步長的 NLMS,近端信號 d(n) 為加混響的遠端參考信號 x(n) + 近端語音信號 s(n),理論上 NLMS 在處理這種純線性疊加的信號時,可以不用非線性部分出馬,直接干掉遠端回聲信號,圖 7(a) 第一行為近端信號 d(n),第二列為遠端參考信號 x(n),線性部分輸出結果,黃色框中為遠端信號,WebRTC AEC 中采用固定步長的 NLMS 演算法收斂較慢,有些許回聲殘留,但是變步長的 NLMS 收斂較快,回聲抑制相對好一些,如圖 7(b),
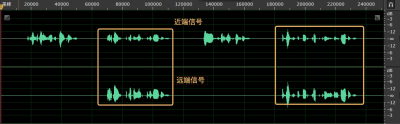

圖 7 兩種 NLMS 演算法的效果對比
線性濾波器引數設定
#define FRAME_LEN 80
#define PART_LEN 64
enum { kExtendedNumPartitions = 32 };
static const int kNormalNumPartitions = 12;
FRAME_LEN 為每次傳給音頻 3A 模塊的資料的長度,默認為 80 個采樣點,由于 WebRTC AEC 采用了 128 點 FFT,內部拼幀邏輯會取出 PART_LEN = 64 個樣本點與前一幀剩余資料連接成128點做 FFT,剩余的 16 點遺留到下一次,因此實際每次處理 PART_LEN 個樣本點(4ms 資料),
默認濾波器階數僅為 kNormalNumPartitions = 12 個,能夠覆寫的資料范圍為 kNormalNumPartitions * 4ms = 48ms,如果打開擴展濾波器模式(設定 extended_filter_enabled為true),覆寫資料范圍為 kNormalNumPartitions * 4ms = 132ms,隨著芯片處理能力的提升,默認會打開這個擴展濾波器模式,甚至擴展為更高的階數,以此來應對市面上絕大多數的移動設備,另外,線性濾波器雖然不具備調整延時的能力,但可以通過估計的 index 衡量當前信號的延時狀態,范圍為 [0, kNormalNumPartitions],如果 index 處于作用域兩端,說明真實延時過小或過大,會影響線性回聲估計的效果,嚴重的會帶來回聲,此時需要結合固定延時與大延時檢測來修正,
非線性濾波
非線性部分一共做了兩件事,就是想盡千方百計干掉遠端信號,
(1) 根據線性部分提供的估計的回聲信號,計算信號間的相干性,判別遠近端幀狀態,
(2) 調整抑制系數,計算非線性濾波引數,
非線性濾波抑制系數為 hNl,大致表征著估計的回聲信號 e(n) 中,期望的近端成分與殘留的非線性回聲信號 y''(n) 在不同頻帶上的能量比,hNl 是與相干值是一致的,范圍是 [0,1.0],通過圖 5(b) 可以看出需要消除的遠端部分幅度值也普遍在 0.5 左右,如果直接使用 hNl 濾波會導致大量的回聲殘留,
因此 WebRTC 工程師對 hNl 做了如下尺度變換,over_drive 與 nlp_mode 相關,代表不同的抑制激行程度,drive_curve 是一條單調遞增的凸曲線,范圍 [1.0, 2.0],由于中高頻的尾音在聽感上比較明顯,所以他們設計了這樣的抑制曲線來抑制高頻尾音,我們記尺度變換的 α = over_drive_scaling * drive_curve,如果設定 nlp_mode = kAecNlpAggressive,α 大約會在 30 左右,
% matlab代碼如下:
over_drive = min_override(nlp_mode+1);
if (over_drive < over_drive_scaling)
over_drive_scaling = 0.99*over_drive_scaling + 0.01*over_drive; % default 0.99 0.01
else
over_drive_scaling = 0.9*over_drive_scaling + 0.1*over_drive; % default 0.9 0.1
end
% WebRtcAec_Overdrive →_→ Overdrive
hNl(index) = weight_curve(index).*hNlFb + (1-weight_curve(index)).* hNl(index);
hNl = hNl.^(over_drive_scaling * drive_curve);
% WebRtcAec_Suppress →_→ Suppress
wined_fft_echo = wined_fft_echo .*hNl;
wined_fft_echo = conj(wined_fft_echo);
如果當前幀為近端幀(即 echo_state = false),假設第 k 個頻帶 hNl(k) = 0.99994 ,hNl(k) = hNl(k)^α = 0.99994 ^ 30 = 0.9982,即使濾波后的損失聽感上幾乎無感知,如圖 8(a),hNl 經過 α 調制之后,幅值依然很接近 1.0,
如果當前幀為遠端幀(即 echo_state = true),假設第 k 個頻帶 hNl(k) = 0.6676 ,hNl(k) = hNl(k)^α = 0.6676 ^ 30 = 5.4386e-06,濾波后遠端能量小到基本聽不到了,如圖 8(b),hNl 經過 α 調制之后,基本接近 0,
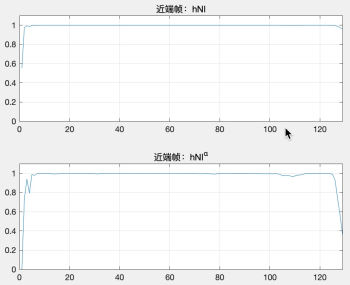
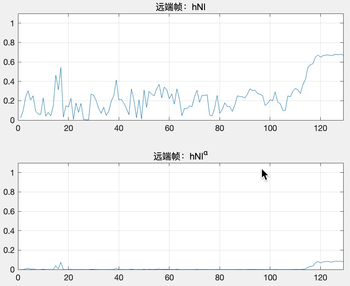
圖 8 遠近端信號抑制系數在調制前后的變化
經過如上對比,為了保證經過調制之后近端期望信號失真最小,遠端回聲可以被抑制到不可聽,WebRTC AEC 才在遠近端幀狀態判斷的的模塊中設定了如此嚴格的門限,
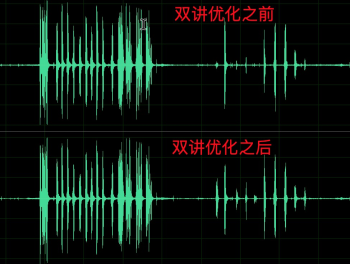
另外,調整系數 α 過于嚴格的情況下會帶來雙講的抑制,如圖 9 第 1 行,近端說話人聲音明顯丟失,通過調整 α 后得以恢復,如第 2 行所示,因此如果在 WebRTC AEC 現有策略上優化 α 估計,可以緩解雙講抑制嚴重的問題,
延時調整策略
回聲消除的效果與遠近端資料延時強相關,調整不當會帶來演算法不可用的風險,在遠近端資料進入線性部分之前,一定要保證延時在設計的濾波器階數范圍內,不然延時過大超出了線性濾波器估計的范圍或調整過當導致遠近端非因果都會造成無法收斂的回聲,先科普兩個問題:
(1)為什么會存在延時?
首先近端信號 d(n) 中的回聲是揚聲器播放遠端參考 x(n),又被麥克風采集到的形成的,也就意味著在近端資料還未采集進來之前,遠端資料緩沖區中已經躺著 N 幀 x(n)了,這個天然的延時可以約等于音頻信號從準備渲染到被麥克風采集到的時間,不同設備這個延時是不等的,蘋果設備延時較小,基本在 120ms 左右,Android 設備普遍在 200ms 左右,低端機型上會有 300ms 左右甚至以上,
(2)遠近端非因果為什么會導致回聲?
從(1)中可以認為,正常情況下當前幀近端信號為了找到與之對齊的遠端信號,必須在遠端緩沖區沿著寫指標向前查找,如果此時設備采集丟資料,遠端資料會迅速消耗,導致新來的近端幀在向前查找時,已經找不到與之對齊的遠端參考幀了,會導致后續各模塊作業例外,如圖 10(a) 表示正常延時情況,(b) 表示非因果,
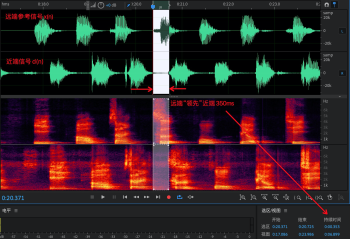
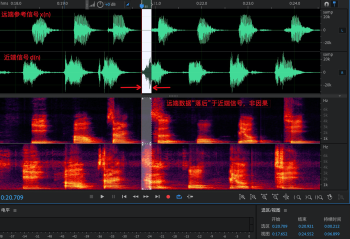
圖10 正常遠近端延時與非因果
WebRTC AEC 中的延時調整策略關鍵而且復雜,涉及到固定延時調整,大延時檢測,以及線性濾波器延時估計,三者的關系如下:
① 固定延時調整只會發生在開始 AEC 演算法開始處理之前,而且僅調整一次,如會議盒子等固定的硬體設備延時基本是固定的,可以通過直接減去固定的延時的方法縮小延時估計范圍,使之快速來到濾波器覆寫的延時范圍之內,
下面結合代碼來看看固定延時的調整程序:
int32_t WebRtcAec_Process(void* aecInst,
const float* const* nearend,
size_t num_bands,
float* const* out,
size_t nrOfSamples,
int16_t reported_delay_ms,
int32_t skew);
WebRtcAec_Process 介面如上,引數 reported_delay_ms 為當前設備需要調整延時的目標值,如某 Android 設備固定延時為 400ms 左右,400ms 已經超出濾波器覆寫的延時范圍,至少需要調整 300ms 延時,才能滿足回聲消除沒有回聲的要求,固定延時調整在 WebRTC AEC 演算法開始之初僅作用一次:
if (self->startup_phase) {
int startup_size_ms = reported_delay_ms < kFixedDelayMs ? kFixedDelayMs : reported_delay_ms;
int target_delay = startup_size_ms * self->rate_factor * 8;
int overhead_elements = (WebRtcAec_system_delay_aliyun(self->aec) - target_delay) / PART_LEN;
printf("[audio] target_delay = %d, startup_size_ms = %d, self->rate_factor = %d, sysdelay = %d, overhead_elements = %d\n", target_delay, startup_size_ms, self->rate_factor, WebRtcAec_system_delay(self->aec), overhead_elements);
WebRtcAec_AdjustFarendBufferSizeAndSystemDelay_aliyun(self->aec, overhead_elements);
self->startup_phase = 0;
}
為什么 target_delay 是這么計算?
int target_delay = startup_size_ms * self->rate_factor * 8;
startup_size_ms 其實就是設定下去的 reported_delay_ms,這一步將計算時間毫秒轉化為樣本點數,16000hz 采樣中,10ms 表示 160 個樣本點,因此 target_delay 實際就是需要調整的目標樣本點數(aecpc->rate_factor = aecpc->splitSampFreq / 8000 = 2),
我們用 330ms 延時的資料測驗:
如果設定默認延時為 240ms,overhead_elements 第一次被調整了 -60 個 block,負值表示向前查找,正好為 60 * 4 = 240ms,之后線性濾波器固定 index = 24,表示 24 * 4 = 96ms 延時,二者之和約等于 330ms,日志列印如下:

② 大延時檢測是基于遠近端資料相似性在遠端大快取中查找最相似的幀的程序,其演算法原理有點類似音頻指紋中特征匹配的思想,大延時調整的能力是對固定延時調整與線型濾波器能力的補充,使用它的時候需要比較慎重,需要控制調整的頻率,以及控制造成非因果的風險,
WebRTC AEC 演算法中開辟了可存盤 250 個 block 大緩沖區,每個 block 的長度 PART_LEN = 64 個樣本點,能夠保存最新的 1s 的資料,這也是理論上的大延時能夠估計的范圍,絕對夠用了,
static const size_t kBufferSizeBlocks = 250;
buffer_ = WebRtc_CreateBuffer(kBufferSizeBlocks, sizeof(float) * PART_LEN);
aec->delay_agnostic_enabled = 1;
我們用 610ms 延時的資料測驗(啟用大延時調整需要設定 delay_agnostic_enabled = 1):
我們還是設定默認延時為 240ms,剛開始還是調整了 -60 個 block,隨后大延時調整接入之后有調整了 -88 個 block,一共調整(60 + 88) * 4 = 592ms,之后線性濾波器固定 index = 4,表示最后剩余延時剩余 16ms,符合預期,


③ 線性濾波器延時估計是固定延時調整和大延時調整之后,濾波器對當前遠近端延時的最直接反饋,前兩者調整不當會造成延時過小甚至非因果,或延時過大超出濾波器覆寫能力,導致無法收斂的回聲,因此前兩者在調整的程序中需要結合濾波器的能力,確保剩余延時在濾波器能夠覆寫的范圍之內,即使延時小范圍抖動,線性部分也能自適應調整,
總結與優化方向
WebRTC AEC 存在的問題:
(1)線性部分收斂時間較慢,固定步長的 NLMS 演算法對線性部分回聲的估計欠佳;
(2)線性部分濾波器階數默認為 32 階,默認覆寫延時 132ms,對移動端延時較大設備支持不是很好,大延時檢測部分介入較慢,且存在誤調導致非因果回聲的風險;
(3)基于相干性的幀狀態依賴嚴格的固定門限,存在一定程度的誤判,如果再去指導非線性部分抑制系數的調節,會帶來比較嚴重的雙講抑制,
優化的方向:
(1)演算法上可以通過學習 speex 和 AEC3 的線性部分,改善當前線性濾波效果;
(2)演算法上可以優化延時調整策略,工程上可以新增引數配置下發等工程手段解決一些設備的延時問題;
(3)另外,有一些新的思路也是值得我們嘗試的,如開頭提到的,既然回聲也可以是視為噪聲,那么能否用降噪的思路做回聲消除呢,答案是可以的,
「視頻云技術」你最值得關注的音視頻技術公眾號,每周推送來自阿里云一線的實踐技術文章,在這里與音視頻領域一流工程師交流切磋,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234711.html
標籤:其他