近日 K8s 官方稱最早將在 1.23版本棄用 docker 作為容器運行時,并在博客中強調可以使用如 containerd 等 CRI 運行時來代替 docker,本文會做詳細解讀,并介紹 docker 與 containerd 的關系,以及為什么 containerd 是更好的選擇,這里先回答下TKE用戶關心的問題:我們的集群該怎么辦?
TKE集群該怎么辦
- TKE早在 2019年5月就已經支持選擇 containerd 作為容器運行時,如果新建集群,推薦選擇 containerd 作為容器運行時
- 已有集群在升級到 K8s 1.23(假定 TKE 第一個不支持 dockershim 的 K8s版本,也可能是 1.24)之前,仍然可以繼續使用 docker 作為容器運行時
- 已有集群通過 TKE 集群升級功能升級到 1.23時, TKE會提供切換運行時為 containerd 的選項,當然,這種情況下沒辦法做到 Pod 不受影響,只能采用重裝節點的方式來升級
- 已有集群也可以將運行時切換為 containerd ,新增節點會使用 containerd , 存量節點不受影響仍然使用 docker (注意: 這會造成同一集群中 docker 節點與 containerd 節點共存,如果有使用 Docker in Docker, 或者其他依賴節點上 docker daemon 與 docker.sock 的業務,需要提前采取措施來避免產生問題,例如通過按節點標簽調度,保證這類業務調度到 docker 節點;或者采用如前文所述在 containerd 集群運行 Docker in Docker 的方案)
- 當然,在未來 docker 也有可能在內部實作 CRI 或者添加一個 dockershim 行程,如果 docker 做了相應適配,TKE 這邊在未來也會進行支持,
解讀 K8s 棄用 dockershim
Docker support in the kubelet is now deprecated and will be removed in a future release. The kubelet uses a module called "dockershim" which implements CRI support for Docker and it has seen maintenance issues in the Kubernetes community. We encourage you to evaluate moving to a container runtime that is a full-fledged implementation of CRI (v1alpha1 or v1 compliant) as they become available. (#94624, @dims) [SIG Node]
K8s 在 1.20的 change log 中提到 K8s 將于 1.20版本開始逐步放棄對 Docker 的支持,在 K8s 的官方博客中也提到具體的宣告和一些 FAQ,
- Don't Panic: Kubernetes and Docker
- Dockershim FAQ
在博客中提到 K8s 將在 1.20版本中添加不推薦使用 docker 的資訊,且最早將于 1.23版本中把 dockershim 從 kubelet 中移除,屆時用戶將無法使用 docker 作為 K8s 集群的運行時,不過通過 docker 構建的鏡像在沒有 docker 的 K8s 集群中依然可以使用,
“寄生”在 kubelet 中的 dockershim
本次改動主要內容是準備洗掉 kubelet 中的 dockershim,當然這種做法也是符合預期的,在早期 rkt 和 docker 爭霸時,kubelet 中需要維護兩坨代碼分別來適配 docker 和 rkt ,這使得 kubelet 每次發布新功能都需要考慮對運行時組件的適配問題,嚴重拖慢了新版本發布速度,另外虛擬化已經是一個普遍的需求,如果出現了型別的運行時,SIG-Node 小組可能還需要把和新運行時適配的代碼添加到 kubelet 中,這種做法并不是長久之計,于是在 2016 年,SIG-Node提出了容器操作介面 CRI(Container Runtime Interface), CRI 是對容器操作的一組抽象,只要每種容器運行時都實作這組介面,kubelet 就能通過這組介面來適配所有的運行時,但 Docker 當時并沒有(也不打算)實作這組介面, kubelet 只能在內部維護一個稱之為“dockershim”組件,這個組件充當了 docker 的 CRI 轉接器,kubelet 在創建容器時通過 CRI 介面呼叫 dockershim ,而 dockershim 在通過 http 請求把請求交給 docker ,于是 kubelet 的架構變成下圖這樣:
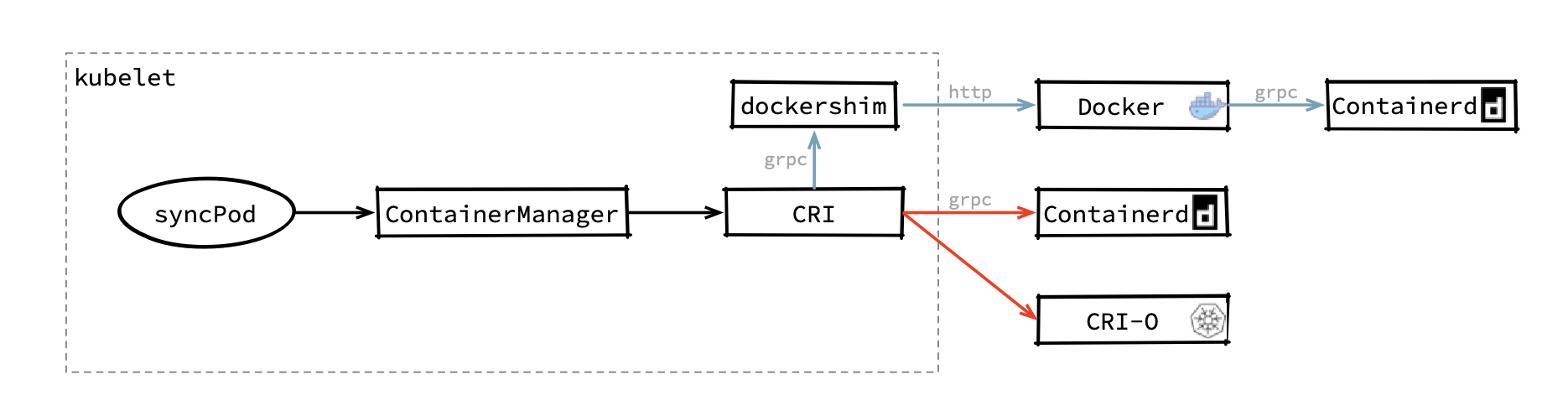
在使用實作了 CRI 介面的組件作為容器運行時的情況下,kubelet 創建容器的呼叫鏈如圖中紅色箭頭所示,kubelet 中的 ContainerManager 可以直接通過 CRI 呼叫到容器運行時,這程序中只需要一次 grpc 請求;而在使用 docker 時,ContainerManager 會走圖中藍色的呼叫鏈, CRI 的請求通過 unix:///var/run/dockershim.sock 流向 dockershim,dockershim 做轉換后把請求轉發給 docker,至于為什么 docker 后面還有個 containerd 稍后會講到,在 kubelet 中實作 docker 的轉接器本來就是一種不優雅的實作,這種做法讓呼叫鏈變長且不穩定性,還給 kubelet 的維護添加了額外作業,把這部分內容從 kubelet 刪掉就是時間問題了,
棄用 Docker 后會有什么不同?
If you’re an end-user of Kubernetes, not a whole lot will be changing for you. This doesn’t mean the death of Docker, and it doesn’t mean you can’t, or shouldn’t, use Docker as a development tool anymore. Docker is still a useful tool for building containers, and the images that result from running
docker buildcan still run in your Kubernetes cluster.
訊息一出,大家最關心的事情應該就是棄用 docker 后到底會產生什么影響?
官方的答復是:Don't Panic!隨后又重點解釋了幾個大家最關心的問題,我們來分析下官方提到的這些方面:
-
正常的 K8s 用戶不會有任何影響
是的,生產環境中高版本的集群只需要把運行時從 docker 切換到其他的 runtime(如 containerd)即可,containerd 是 docker 中的一個底層組件,主要負責維護容器的生命周期,跟隨 docker 經歷了長期考驗,同時 2019年初就從 CNCF 畢業,可以單獨作為容器運行時用在集群中,TKE 也早在 2019 年就已經提供了 containerd 作為運行時選項,因此把 runtime 從 docker 轉換到 containerd 是一個基本無痛的程序,CRI-O 是另一個常被提及的運行時組件,由 redhat 提供,比 containerd 更加輕量級,不過和 docker 的區別較大,可能轉換時會有一些不同之處,
-
開發環境中通過
docker build構建出來的鏡像依然可以在集群中使用鏡像一直是容器生態的一大優勢,雖然人們總是把鏡像稱之為“docker鏡像”,但鏡像早就成為了一種規范了,具體規范可以參考image-spec,在任何地方只要構建出符合 Image Spec 的鏡像,就可以拿到其他符合 Image Spec 的容器運行時上運行,
-
在 Pod 中使用 DinD(Docker in Docker)的用戶會受到影響
有些使用者會把 docker 的 socket (/run/docker.sock)掛載到 Pod 中,并在 Pod 中呼叫 docker 的 api 構建鏡像或創建編譯容器等,官方在這里的建議是使用 Kaniko、Img 或 Buildah,我們可以通過把 docker daemon 作為 DaemonSet 或者給想要使用 docker 的 Pod 添加一個 docker daemon 的 sidecar 的方式在任意運行時中使用 DinD 的方案,TKE 也專門為在 containerd 集群中使用 DinD 提供了方案,詳見 在containerd中使用DinD,
containerd 的今生前世
所以 containerd 到底是個啥?和 docker 又是什么關系?可能有些同學看到博客后會發出這樣的疑問,接下來就給同學們講解下 containerd 和 docker 的淵源,
docker 與 containerd
2016年,docker 把負責容器生命周期的模塊拆分出來,并將其捐贈給了社區,也就是現在的 containerd,docker 拆分后結構如下圖所示(當然 docker 公司還在 docker 中添加了部分編排的代碼),
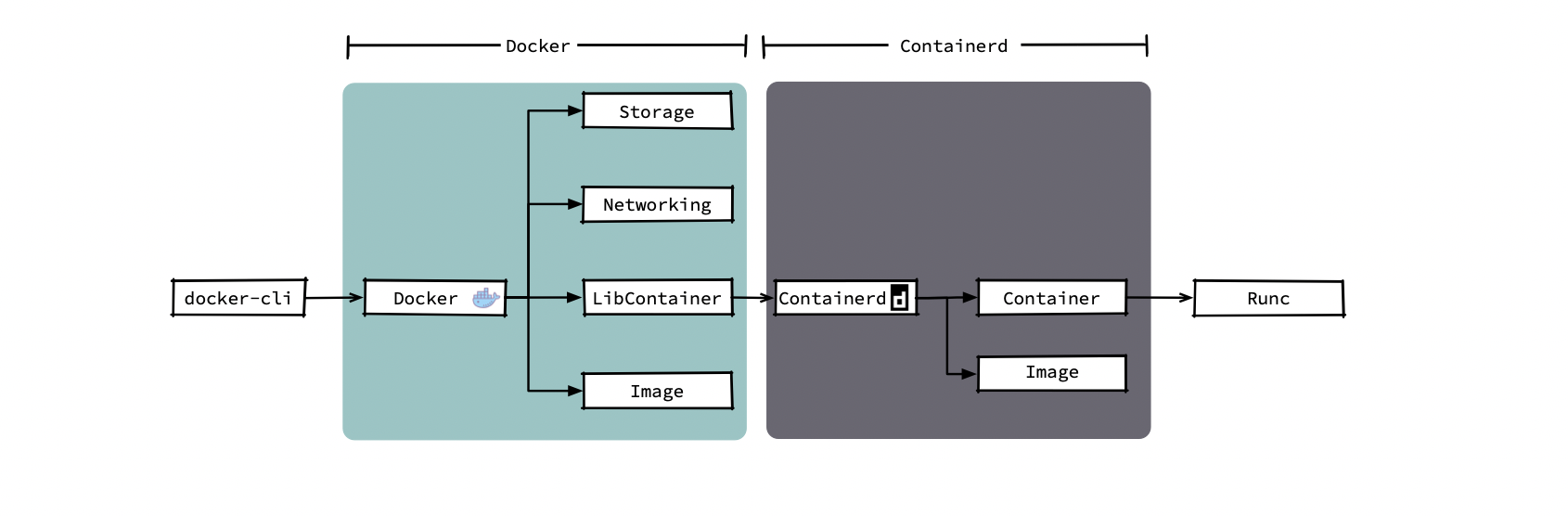
在我們呼叫 docker 命令創建容器后,docker daemon 會通過 Image 模塊下載鏡像并保存到 Graph Driver 模塊中,之后通過 client 呼叫containerd 創建并運行容器,我們在使用 docker 創建容器時可能需要使用--volume給容器添加持久化存盤;還有可能通過--network連接我們用 docker 命令創建的幾個容器,當然,這些功能是 docker 中的 Storage 模塊和 Networking 模塊提供給我們的,但 K8s 提供了更強的卷掛載能力和集群級別的網路能力,在集群中 kubelet 只會使用到 docker 提供的鏡像下載和容器管理功能,而編排、網路、存盤等功能都不會用到,下圖中可以看出當前的模式下各模塊的呼叫鏈,同時圖中被紅框標注出的幾個模塊就是 kubelet 創建 Pod 時所依賴的幾個運行時的模塊,
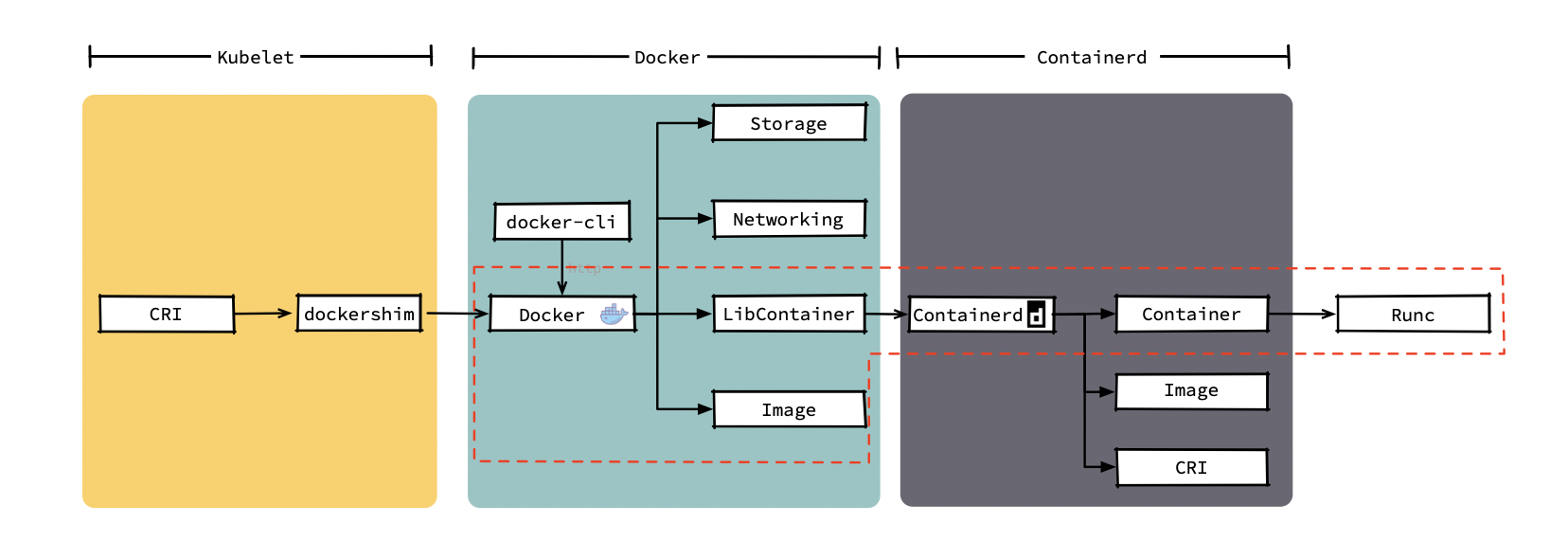
containerd 被捐贈給CNCF社區后,社區給其添加了鏡像管理模塊和 CRI 模塊,這樣 containerd 不只可以管理容器的生命周期,還可以直接作為 K8s 的運行時使用,于是 containerd 在 2019年2月從 CNCF 社區畢業,正式進入生產環境,下圖中能看出以 containerd 作為容器運行時,可以給 kubelet 帶來創建 Pod 所需的全部功能,同時還得到了更純粹的功能模塊以及更短的呼叫鏈,
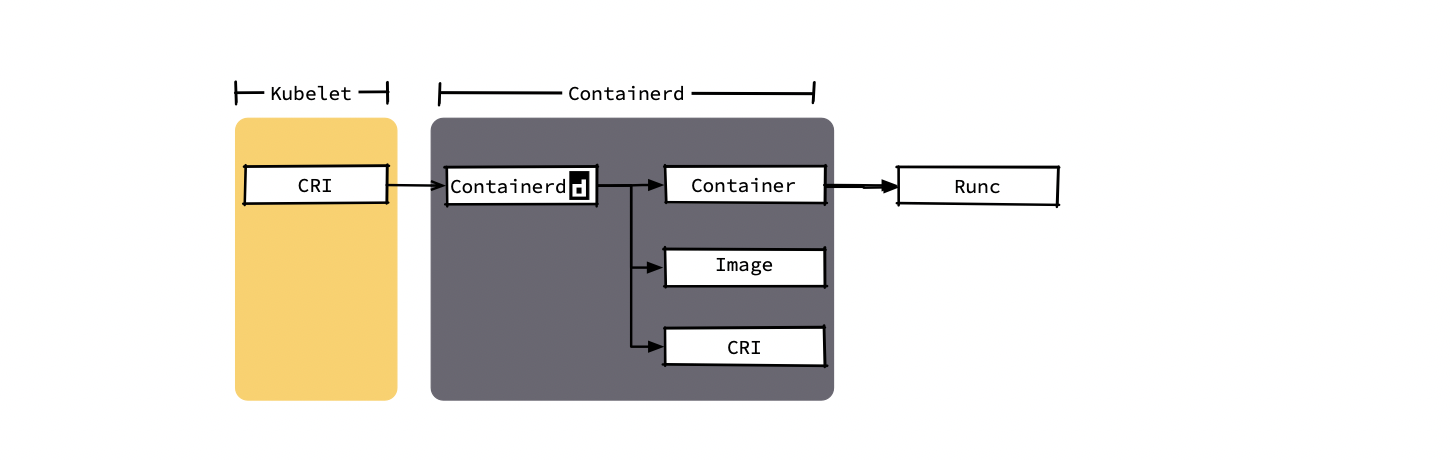
從上面的對比可以看出從 containerd 被捐贈給社區開始,就一直以成為簡單、穩定且可靠的容器運行時為目標;而 docker 則是希望能成為一個完整的產品,官方檔案中也提到了這一點,docker 為了給用戶更好的互動和使用體驗以及更多的功能,提供了很多開發人員所需要的特性,同時為了給 swarm 做基礎,提供了網路和卷的功能,而這些功能其實都是是 K8s 用不上的;containerd 則相反,僅提供了 kubelet 創建 Pod 所需要的基礎功能,當然這換來的就是更高的魯棒性以及更好的性能,在一定程度上講,即使在 kubelet 1.23 版本之后 docker 提供了 CRI 介面,containerd 仍然是更好的選擇,
在 Kubernetes 集群中使用 containerd
當然現在有諸多的 CRI 實作者,比較主要的除了 containerd 還有 CRI-O,CRI-O 是主要由 Red Hat 員工開發的 CRI 運行時,完全和 docker 沒有關系,因此從 docker 遷移過來可能會比較困難,無疑 containerd 才是 docker 被拋棄后的 CRI 運行時的最佳人選,對于開發同學來說整個遷移程序應該是無感知的,不過對于部分運維同學可能會比較在意部署和運行中細節上的差異,接下來我們重點介紹下在 K8s 中使用 containerd 和 docker 的幾處區別,
- 容器日志對比項
| 對比項 | Docker | Containerd |
|---|---|---|
| 存盤路徑 | 如果 docker 作為 K8s 容器運行時,容器日志的落盤將由 docker 來完成,保存在類似/var/lib/docker/containers/$CONTAINERID 目錄下,kubelet 會在 /var/log/pods 和 /var/log/containers 下面建立軟鏈接,指向 /var/lib/docker/containers/$CONTAINERID 該目錄下的容器日志檔案, | 如果 Containerd 作為 K8s 容器運行時, 容器日志的落盤由 kubelet 來完成,保存至 /var/log/pods/$CONTAINER_NAME 目錄下,同時在 /var/log/containers 目錄下創建軟鏈接,指向日志檔案, |
| 配置引數 | 在 docker 組態檔中指定:"log-driver": "json-file","log-opts": {"max-size": "100m","max-file": "5"} | 方法一:在 kubelet 引數中指定:--container-log-max-files=5 --container-log-max-size="100Mi" 方法二:在 KubeletConfiguration 中指定: "containerLogMaxSize": "100Mi", "containerLogMaxFiles": 5, |
| 把容器日志保存到資料盤 | 把資料盤掛載到 “data-root”(預設是 /var/lib/docker)即可, | 創建一個軟鏈接 /var/log/pods 指向資料盤掛載點下的某個目錄,在 TKE 中選擇“將容器和鏡像存盤在資料盤”,會自動創建軟鏈接 /var/log/pods, |
-
cni 配置方式的區別
在使用 docker 時,kubelet 中的 dockershim 負責呼叫 cni 插件,而 containerd 的場景中 containerd 中內置的 containerd-cri 插件負責呼叫 cni,因此關于 cni 的組態檔需要放在 containerd 的組態檔中(/etc/containerd/containerd.toml):[plugins.cri.cni] bin_dir = "/opt/cni/bin" conf_dir = "/etc/cni/net.d" -
stream 服務的區別
說明:
Kubectl exec/logs 等命令需要在 apiserver 跟容器運行時之間建立流轉發通道,
如何在 containerd 中使用并配置 Stream 服務?
Docker API 本身提供 stream 服務,kubelet 內部的 docker-shim 會通過 docker API 做流轉發,而containerd 的 stream 服務需要單獨配置:
[plugins.cri] stream_server_address = "127.0.0.1" stream_server_port = "0" enable_tls_streaming = false [plugins.cri] stream_server_address = "127.0.0.1" stream_server_port = "0" enable_tls_streaming = false
K8s 1.11 前后版本配置區別是什么?
containerd 的 stream 服務在 K8s 不同版本運行時場景下配置不同,
- 在 K8s 1.11 之前:
kubelet 不會做 stream proxy,只會做重定向,即 kubelet 會將 containerd 暴露的 stream server 地址發送給 apiserver,并讓 apiserver 直接訪問 containerd 的 stream 服務,此時,您需要給 stream 服務轉發器認證,用于安全防護, - 在 K8s 1.11 之后:
K8s1.11 引入了 kubelet stream proxy, 使 containerd stream 服務只需要監聽本地地址即可,
在 TKE 集群中使用 containerd
從 2019年5月份開始,TKE就開始支持把 containerd 作為容器運行時選項之一,隨著TKE逐步在 containerd 集群中支持日志收集服務和 GPU 能力,2020年 9月份 containerd 在 TKE 也摘掉了 Beta 版本的標簽,可以正式用于生產環境中了,在長期使用中,我們也發現了一些 containerd 的問題并且及時進行了修復,如:
- 由于錯誤處理問題導致的 Pod Terminating
- 由于內核版本問題導致鏡像檔案丟失
想要在TKE集群中使用 containerd 作為運行時有三種方式:
-
在創建集群時,選擇 1.12.4 及以上版本的 K8s 后,選擇 containerd 為運行時組件即可
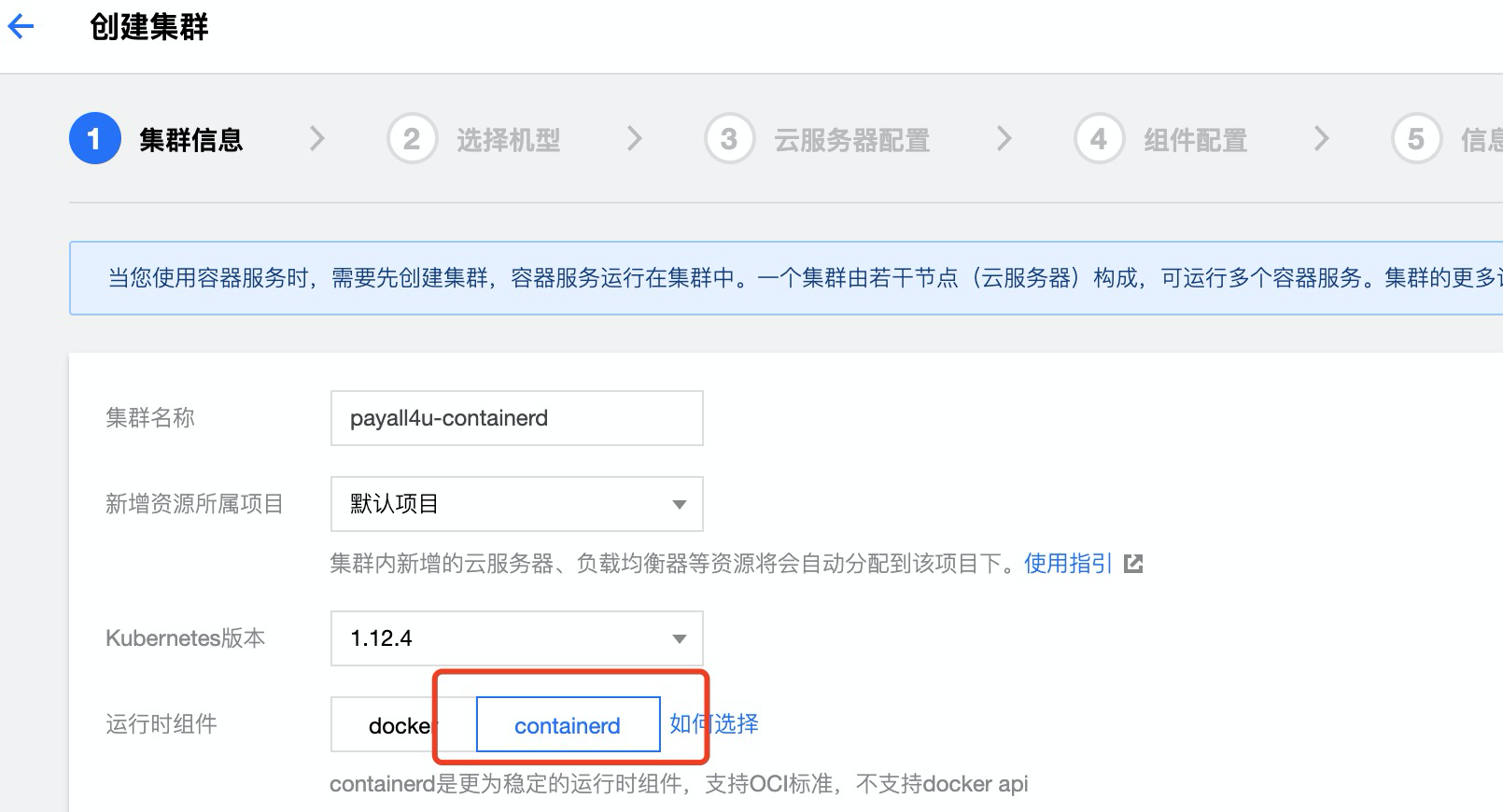
-
在已有 docker 集群中,通過創建運行時為 containerd 的節點池來創建一部分 containerd 節點(新建節點池 > 更多設定 > 運行時組件)
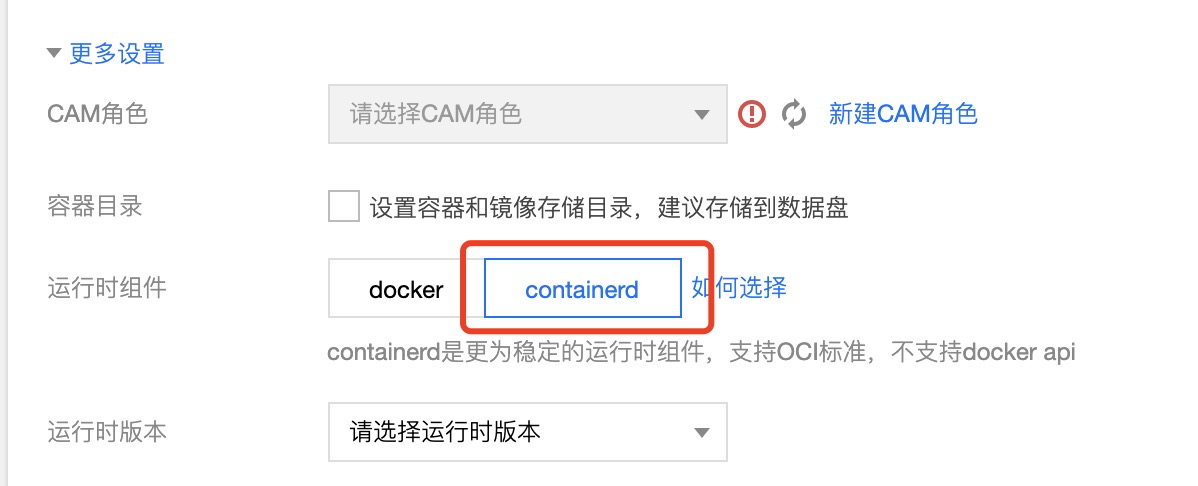
-
在已有 docker 集群中,修改集群或者節點池的"運行時組件"屬性為"containerd"
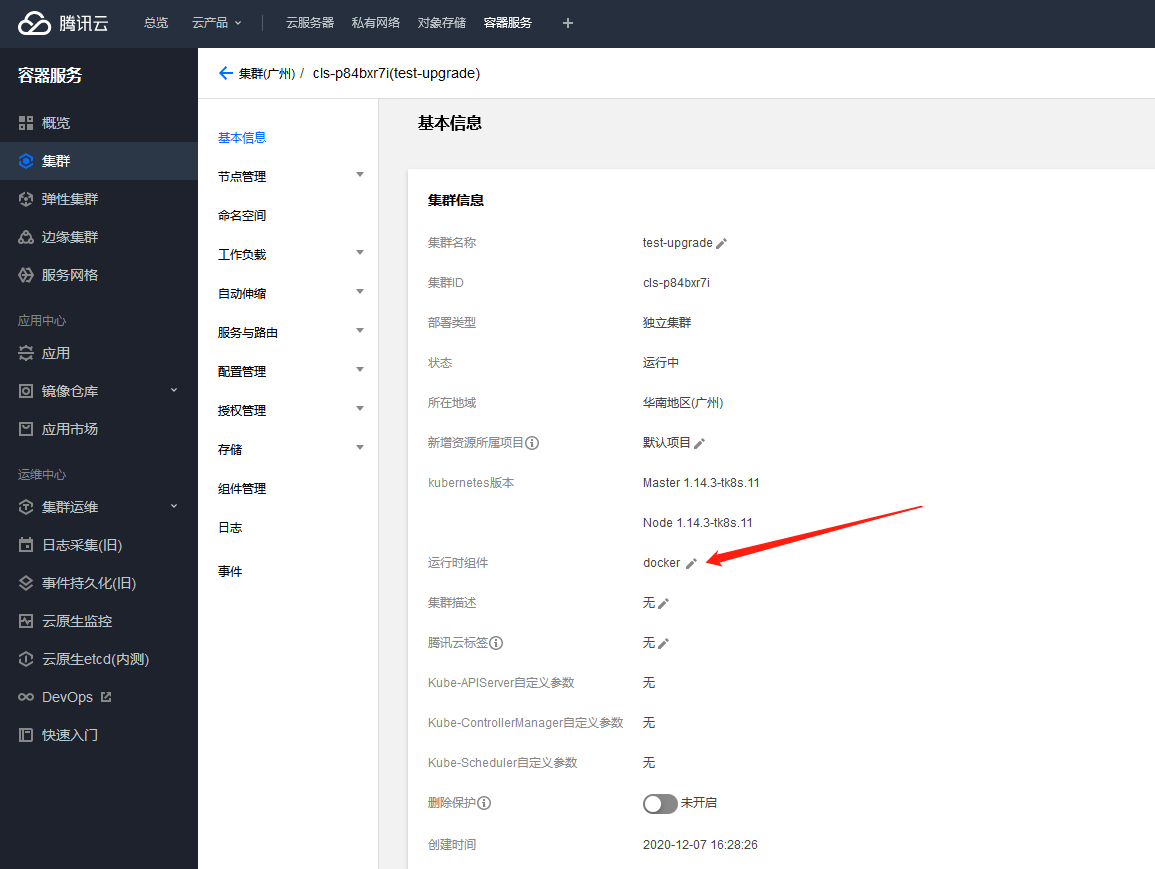
注意: 后兩種方式會造成同一集群中 docker 節點與 containerd 節點共存,如果有使用 Docker in Docker, 或者其他依賴節點上 docker daemon 與 docker.sock 的業務,需要提前采取措施來避免產生問題,例如通過按節點標簽調度,保證這類業務調度到 docker 節點;或者采用如前文所述在 containerd 集群運行 Docker in Docker 的方案,
現階段關于 containerd 和 docker 選擇問題可以查看這里,
參考
[1] Don't Panic: Kubernetes and Docker
[2] Dockershim FAQ
[3] Dockershim Removal Kubernetes Enhancement Proposal
[4] kubernetes CHANGELOG-1.20
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234718.html
標籤:其他