第一章 Hadoop 分布式檔案系統HDFS
第一代大資料框架Hadoop由:HDFS分布式檔案系統、MapReduce計算框架和YARN資源調度框架組成,本文為學習HDFS分布式檔案系統時記錄的學習筆記,
文章目錄
- 第一章 Hadoop 分布式檔案系統HDFS
- 前言
- 一、什么是Hadoop?
- 1.hadoop的發展歷史起源介紹
- 2.hadoop的發展歷史起源構
- 二、HDFS分布式檔案系統
- 1.分布式檔案系統的理解
- 2.hdfs的架構詳細剖析
- 1. 檔案分塊存盤&3副本
- 2. 抽象成資料塊的好處
- 3.HDFS架構
- 3.hdfs的shell命令
- 4.NameNode和SecondaryNameNode功能剖析
- 總結
前言
Hadoop作為第一代大資料框架,在大資料行業一直非常熱門,直到現在還是有許多企業在使用該框架,尤其對與熟悉Java的同學,Hadoop框架是入門大資料的首選,
一、什么是Hadoop?
1.hadoop的發展歷史起源介紹
-
Hadoop最早起源于Nutch,Nutch的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存盤和索引問題,
-
2003年、2004年谷歌發表的兩篇論文為該問題提供了可行的解決方案,
——分布式檔案系統(GFS),可用于處理海量網頁的存盤
——分布式計算框架MAPREDUCE,可用于處理海量網頁的索引計算問題,
-
Nutch的開發人員完成了相應的開源實作HDFS和MAPREDUCE,并從Nutch中剝離成為獨立專案HADOOP,到2008年1月,HADOOP成為Apache頂級專案(同年,cloudera公司成立),迎來了它的快速發展期,
-
Hadoop作者Doug Cutting
-
Apache Lucene是一個文本搜索系統庫
-
Apache Nutch作為前者的一部分,主要包括web爬蟲、全文檢索;2003年“谷歌分布式檔案系統GFS”論文,2004年開源版本HDFS
-
2004年“谷歌MapReduce”論文,2005年Nutch開源版MapReduce,
2.hadoop的發展歷史起源構

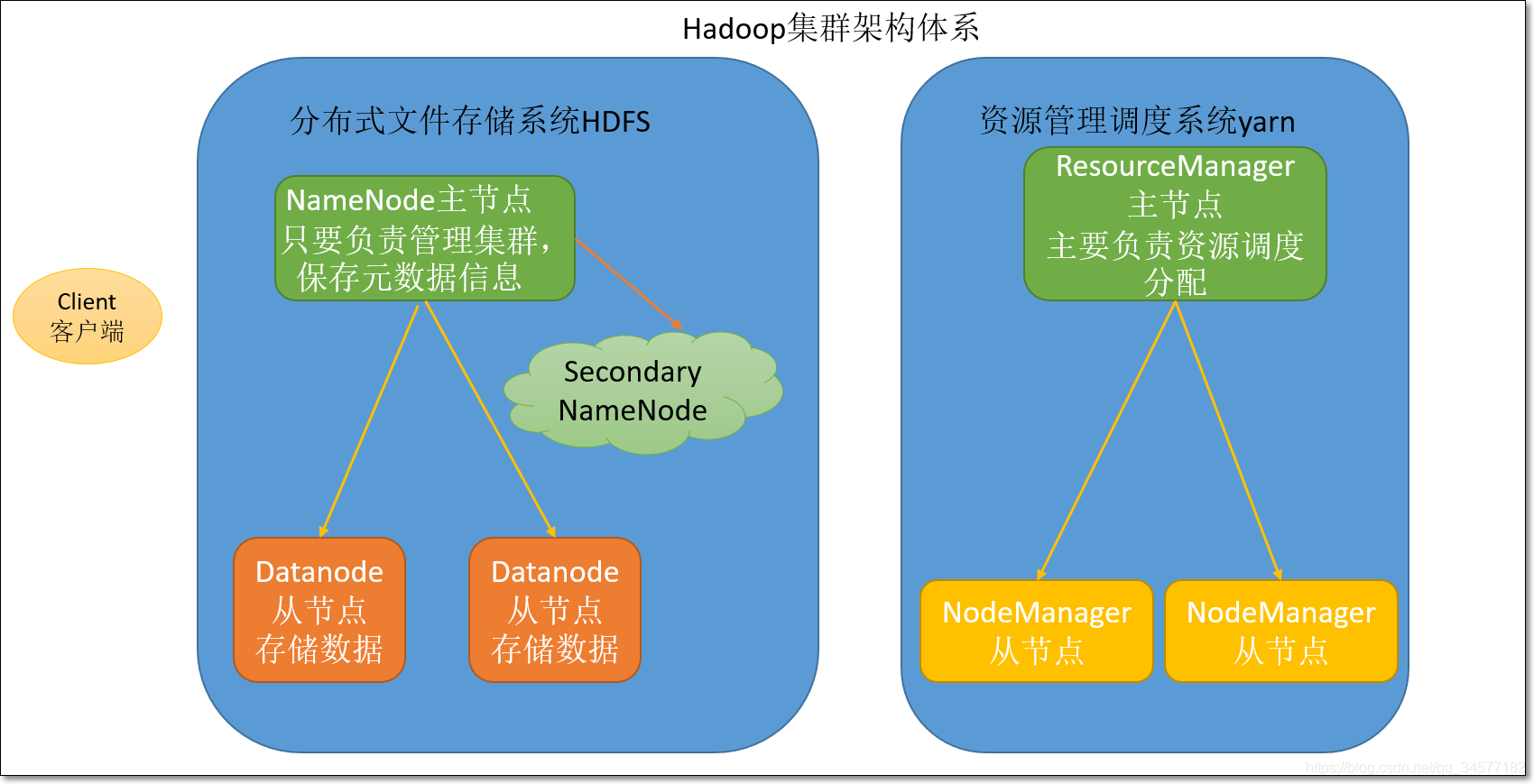
- HDFS模塊:
- namenode:主節點,主要負責集群的管理以及元資料資訊管理
- datanode:從節點,主要負責存盤用戶資料
- secondaryNameNode:輔助namenode管理元資料資訊,以及元資料資訊的冷備份
- Yarn模塊:
- ResourceManager:主節點,主要負責資源分配
- NodeManager:從節點,主要負責執行任務
二、HDFS分布式檔案系統
1.分布式檔案系統的理解
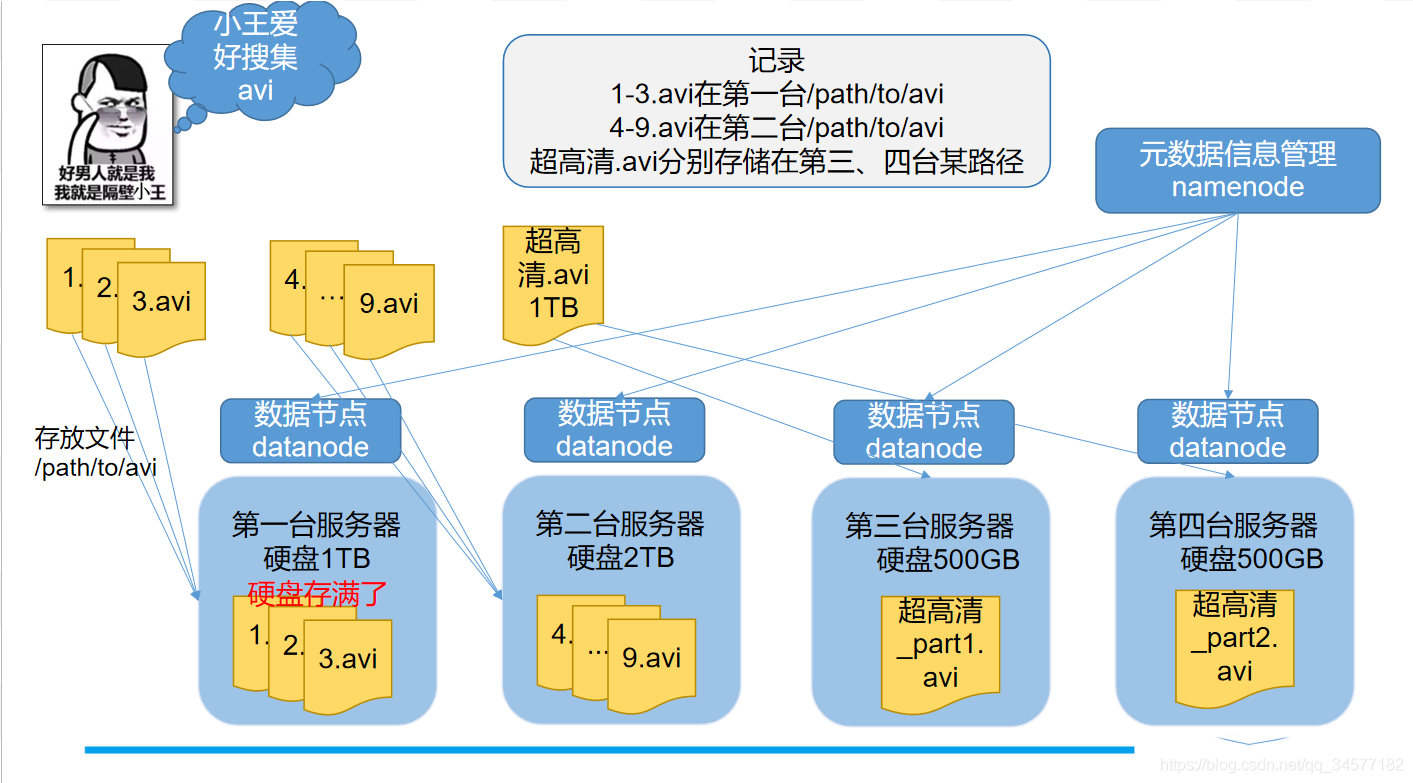

- 圖中小王收藏的avi存盤于哪臺機器上的記錄我們稱之為元資料,元資料保存在記憶體中,
- 最直觀的理解便是三個臭皮匠,頂個諸葛亮,
- 很多的磁盤加一起就可以裝下天下所有的avi
- 類似于你出五毛,我出五毛,我們一起湊一塊的效果
2.hdfs的架構詳細剖析
1. 檔案分塊存盤&3副本

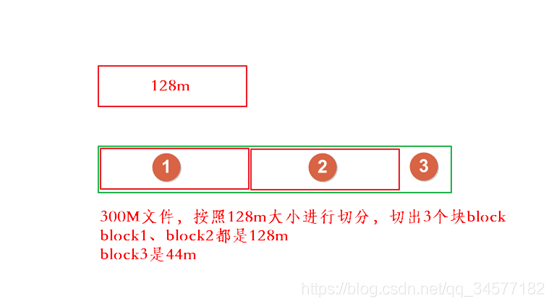
- 保存檔案到HDFS時,會先默認按128M的大小對檔案進行切分;效果如上圖
- 資料以block塊的形式進統一存盤管理,每個block塊默認最多可以存盤128M的檔案,
- 每個block塊的元資料大小大概為150位元組
- 所有的檔案都是以block塊的方式存放在HDFS檔案系統當中,在hadoop1當中,檔案的block塊默認大小是64M,hadoop2當中,檔案的block塊大小默認是128M,block塊的大小可以通過hdfs-site.xml當中的組態檔進行指定
<property>
<name>dfs.block.size</name>
<value>塊大小 以位元組為單位</value><!-- 只寫數值就可以 -->
</property>
- 為了保證block塊的安全性,也就是資料的安全性,在hadoop2當中,檔案默認保存三個副本,我們可以更改副本數以提高資料的安全性,如動圖中block2副本所在的機器宕機,namenode在發現后,會通知其他某個block2副本所在機器重新創建一個副本,發送到其他機器,保證每個block都會有3個副本的存在,
- 在hdfs-site.xml當中修改以下配置屬性,即可更改檔案的副本數
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
2. 抽象成資料塊的好處
1.一個檔案可能大于集群中的任何一個磁盤,分成多個塊,就可以完整的將檔案存在不同磁盤里;
2.檔案只考慮塊的概念,從而簡化了檔案系統的設計;
3.抽象成塊后便于備份,有利于資料的容錯和可用性,
3.HDFS架構
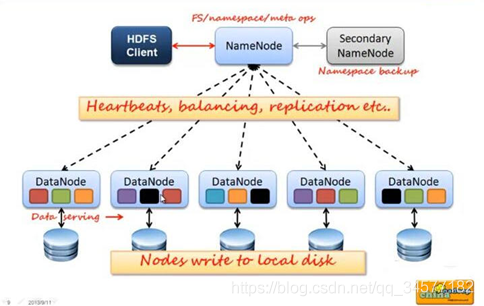
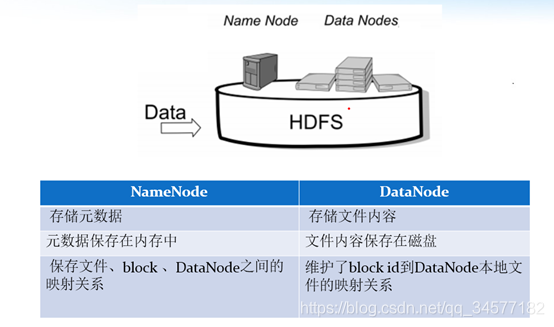
HDFS集群包括,NameNode和DataNode以及Secondary Namenode,
- NameNode負責管理整個檔案系統的元資料,以及每一個路徑(檔案)所對應的資料塊資訊,
- DataNode 負責管理用戶的檔案資料塊,每一個資料塊都可以在多個datanode上存盤多個副本,
- Secondary NameNode用來監控HDFS狀態的輔助后臺程式,每隔一段時間獲取HDFS元資料的快照,最主要作用是輔助namenode管理元資料資訊
3.hdfs的shell命令
HDFS命令有兩種風格:
- hadoop fs開頭的
- hdfs dfs開頭的
- 兩種命令均可使用,效果相同
1.如何查看hdfs或hadoop子命令的幫助資訊,如ls子命令
hdfs dfs -help ls
hadoop fs -help ls #兩個命令等價
2.查看hdfs檔案系統中指定目錄的檔案串列,對比linux命令ls
hdfs dfs -ls /
hadoop fs -ls /
hdfs dfs -ls -R /
3.在hdfs檔案系統中創建檔案
hdfs dfs -touchz /edits.txt
4.向hdfs檔案中追加內容
hadoop fs -appendToFile edit1.xml /edits.txt
#將本地磁盤當前目錄的edit1.xml內容追加到HDFS根目錄 的edits.txt檔案
5.查看HDFS檔案內容
hdfs dfs -cat /edits.txt
6.從本地路徑上傳檔案至HDFS
#用法:hdfs dfs -put /本地路徑 /hdfs路徑
hdfs dfs -put /linux本地磁盤檔案 /hdfs路徑
hdfs dfs -copyFromLocal /linux本地磁盤檔案 /hdfs路徑 #跟put作用一樣
hdfs dfs -moveFromLocal /linux本地磁盤檔案 /hdfs路徑 #跟put作用一樣,只不過,源檔案被拷貝成功后,會被洗掉
7.在hdfs檔案系統中下載檔案
hdfs dfs -get /hdfs路徑 /本地路徑
hdfs dfs -copyToLocal /hdfs路徑 /本地路徑 #根get作用一樣
8.在hdfs檔案系統中創建目錄
hdfs dfs -mkdir /shell
9.在hdfs檔案系統中洗掉檔案
hdfs dfs -rm /edits.txt
10.在hdfs檔案系統中修改檔案名稱(也可以用來移動檔案到目錄)
hdfs dfs -mv /xcall.sh /call.sh
hdfs dfs -mv /call.sh /shell
11.在hdfs中拷貝檔案到目錄
hdfs dfs -cp /*** /***
12.遞回洗掉目錄
hdfs dfs -rm -r /shell
13.列出本地檔案的內容(默認是hdfs檔案系統)
hdfs dfs -ls file:///home/hadoop/
14.查找檔案
# linux find命令
find . -name 'edit*'
# HDFS find命令
hadoop fs -find / -name part-r-00000 # 在HDFS根目錄中,查找part-r-00000檔案
4.NameNode和SecondaryNameNode功能剖析
- namenode與secondaryName決議
- NameNode主要負責集群當中的元資料資訊管理,而且元資料資訊需要經常隨機訪問,因為元資料資訊必須高效的檢索,那么如何保證namenode快速檢索呢??元資料資訊保存在哪里能夠快速檢索呢??如何保證元資料的持久安全呢??
- 為了保證元資料資訊的快速檢索,那么我們就必須將元資料存放在記憶體當中,因為在記憶體當中元資料資訊能夠最快速的檢索,那么隨著元資料資訊的增多(每個block塊大概占用150位元組的元資料資訊),記憶體的消耗也會越來越多,
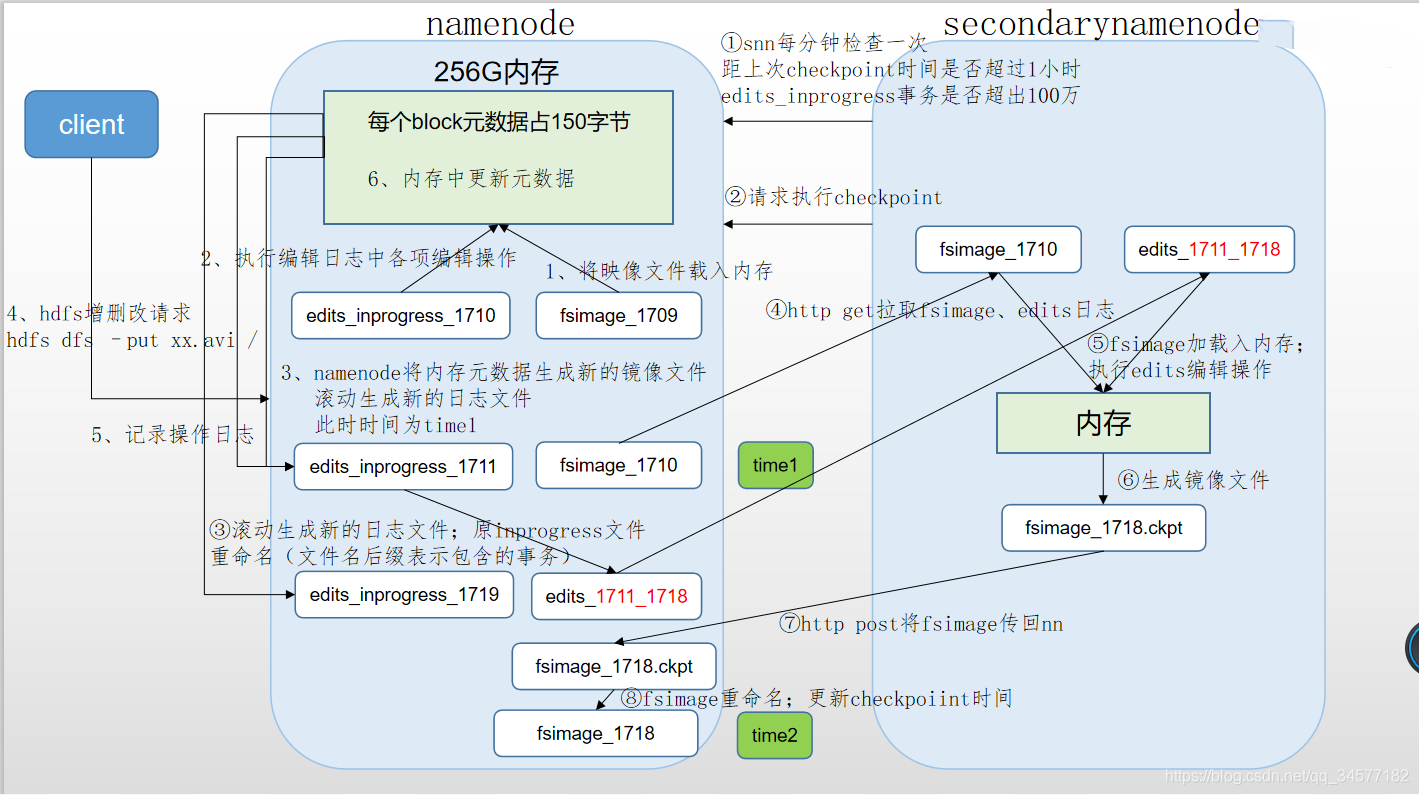
- 如果所有的元資料資訊都存放記憶體,服務器斷電,記憶體當中所有資料都消失,為了保證元資料的安全持久,元資料資訊必須做可靠的持久化,在hadoop當中為了持久化存盤元資料資訊,將所有的元資料資訊保存在了FSImage檔案當中,那么FSImage隨著時間推移,必然越來越膨脹,FSImage的操作變得越來越難,為了解決元資料資訊的增刪改,hadoop當中還引入了元資料操作日志edits檔案,edits檔案記錄了客戶端操作元資料的資訊,隨著時間的推移,edits資訊也會越來越大,為了解決edits檔案膨脹的問題,hadoop當中引入了secondaryNamenode來專門做fsimage與edits檔案的合并
-
namenode作業機制
(1)第一次啟動namenode格式化后,創建fsimage和edits檔案,如果不是第一次啟動,直接加載編輯日志和鏡像檔案到記憶體,
(2)客戶端對元資料進行增刪改的請求
(3)namenode記錄操作日志,更新滾動日志,
(4)namenode在記憶體中對資料進行增刪改查
-
Secondary NameNode作業
(1)Secondary NameNode詢問namenode是否需要checkpoint,直接帶回namenode是否檢查結果,
? (2)Secondary NameNode請求執行checkpoint,
? (3)namenode滾動正在寫的edits日志
? (4)將滾動前的編輯日志和鏡像檔案拷貝到Secondary NameNode
? (5)Secondary NameNode加載編輯日志和鏡像檔案到記憶體,并合并,
? (6)生成新的鏡像檔案fsimage.chkpoint
? (7) 拷貝fsimage.chkpoint到namenode
? (8)namenode將fsimage.chkpoint重新命名成fsimage
總結
以上是關于HDFS的學習筆記,介紹了Hadoop框架,詳細描述了HDFS架構,其中block的劃分以及 NameNode和SecondaryNameNode功能剖析需要重點掌握,下半部分關于HDFS的筆記中會補充HDFS的讀寫流程、datanode作業機制以及資料存盤和hdfs的小檔案治理等一些關于HDFS的進階知識,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234850.html
標籤:其他