字符集和比較規則
將字符映射成二進制的程序叫做編碼,將二進制映射成字符的程序叫做解碼,
我們看一下常用字符集的情況:
ASCII字符集:共收錄128個字符,包括空格、標點符號、數字、大小寫字母和一些不可見字符,
ISO 8859-1字符集:共收錄256個字符,它在ASCII字符集的基礎上有擴充了128個西歐常用字符,
GB2312字符集:收錄了漢字以及拉丁字母、希臘字母、日文平假名以及片假名字母、俄語西里爾字母,收錄漢字6763個,
GBK字符集:GBK字符集在GB2312字符集進行了擴充,
UTF-8字符集:幾乎收錄了當今世界各個國家/地區使用的字符,而且還在不斷擴充,
umf8mb3:"閹割"過的UTF-8字符集,使用1~3位元組表示字符, umf8mb4:正宗的UTF-8字符集,使用1~4位元組表示字符,
utf8是使用umf8mb3的別名,
比較規則是對某個字符集中字符比較大小的一種規則,一種字符集對應若干種比較規則,其中有一個默認比較規則,一個比較規則必須對應一個字符集,
MySQL有4個字符集和比較規則,分別是服務器級別、資料庫級別、表級別、列級別,
服務器級別
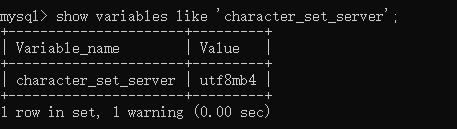
(1)查看服務器級別的字符集
mysql> show variables like 'character_set_server';
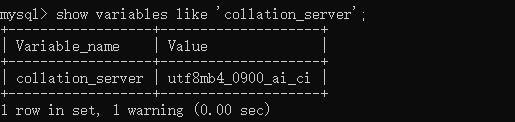
(2)查看服務器級別的比較規則
mysql> show variables like 'collation_server';
資料庫級別
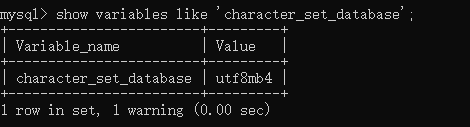
(1)查看資料庫級別的字符集
mysql> show variables like 'character_set_database';
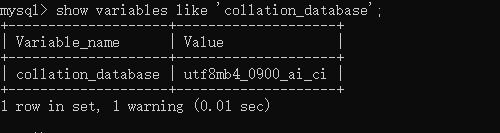
(2)查看資料庫級別的比較規則
mysql> show variables like 'collation_database';
表級別
我們可以在創建表和修改表的時候指定表的字符集和比較規則,如果表中沒有指定,則使用表所在的資料庫和字符集的比較規則作為該表的字符集和比較規則,
列級別
我們可以在創建列和修改列的時候指定列的字符集和比較規則,如果在創建列的沒有顯式指定字符集和比較規則,則該列默認使用表的字符集和比較規則,
客戶端與服務器通信程序的使用的字符集
從本質上說,服務器接收到的請求就是一個位元組序列,服務器將這個位元組序列看作是使用系統變數character_set_client代表的字符集進行編碼的位元組序列,(每個客戶端與服務器建立連接之后,服務器都會為該客戶端維護一個單獨的character_set_client變數,是SESSION級別的)
服務器會將請求的位元組序列當做采用character_set_client對應的字符集進行編碼的位元組序列,在真正處理請求時轉換為使用SESSION級別的系統變數character_set_connection對應的字符集進行編碼的位元組序列,
在客戶端接收的值與表中的某列值比較時,列的字符集和排序規則的優先級更高,例如,
select * from t where c='我';
“我”采用的gbk編碼,列c采用的utf8字符集編碼,這里需要將請求中的“我”先從gbk字符集轉換為utf8,
以上面為例,在服務器生成回應的時候,服務器會將字串“我”從utf8字符集編碼轉換character_set_result系統變數對應的字符集編碼后的位元組序列,之后再發送給客戶端,
| 系統變數 | 描述 |
|---|---|
| character_set_client | 服務器認為請求是按照該系統變數指定的字符集進行編碼 |
| character_set_connection | 服務器在處理請求時,會把請求位元組序列從 character_set_client轉換為character_set_connection |
| character_set_result | 服務器采用該系統變數指定的字符集對回傳客戶端的字串進行編碼 |
在連接到服務器時,客戶端將默認的字符集與用戶名、密碼等資訊一起發送給服務器,服務器在接收后將character_set_client、character_set_connection和character_set_result這三個系統變數的值初始化為客戶端的默認字符集,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234891.html
標籤:其他