第三次周賽題解:
首先題目思維容易程度排個序
- 2020新生典禮
- LSP
- 減數游戲
- 合并石子
- 生成后臺資料
1. 2020新生典禮
根據題意直接寫就可以了,
code:
#include<bits/stdc++.h>
using namespace std;
int main(){
int sum=0;
for(int i=1;i<=5;i++){
int x;
cin>>x;
sum+=x;
}
for(int i=1;i<=5;i++){
int x;
cin>>x;
sum-=x;
}
cout<<sum<<endl;
}
2. LSP
老色批?
預處理一下字串的L和P的的個數
具體來說就是
順著處理一下到第1個字符到當前字串有多少個L
逆著序處理一下第n個字符到當前字串有多少個P
根據乘法原理S的左邊的L和右邊的P的個數相乘就可以了
注意int存不下,要用long long
#include<bits/stdc++.h>
using namespace std;
const int N=1e4+100;
char ss[N];
int suf[N];//處理L
int sub[N];//處理P
int main(){
cin>>ss+1;
int n=strlen(ss+1);
sub[0]=0;
suf[n+1]=0;
for(int i=1;i<=n;i++)
if(ss[i]=='L')sub[i]=sub[i-1]+1;
else sub[i]=sub[i-1];
for(int i=n;i;i--)
if(ss[i]=='P') suf[i]=suf[i+1]+1;
else suf[i]=suf[i+1];
long long ans=0;
for(int i=1;i<=n;i++){
if(ss[i]=='S'){
ans+=suf[i+1]*sub[i-1];
}
}
cout<<ans<<endl;
}
3. 減數游戲
首先Monody的數x如果大于等于n的話一定贏
如果x<n則需要討論一下
x==y的情況
對于LXHing能贏當且僅當
n
%
(
x
+
1
)
=
=
0
n\%(x+1)==0
n%(x+1)==0也就是n是x+1的倍數,為什么呢?
因為Monody只能取1到x,然而LXHing無恥的使得每次減完數結果都是
n
?
p
×
(
x
+
1
)
n-p\times(x+1)
n?p×(x+1),其中p是倍數,
舉個栗子:
n
=
10
,
x
=
4
,
y
=
4
n=10,x=4,y=4
n=10,x=4,y=4
10 % ( 4 + 1 ) = = 0 10\%(4+1)==0 10%(4+1)==0
Monody先出1到4,然后LXHing無恥的再減去
(
5
?
M
o
n
o
d
y
減
去
的
數
)
(5-Monody減去的數)
(5?Monody減去的數)
LXHing減去后的結果剩下是5,這個局面,Monody怎么出都是輸了,LXHing贏了,
那這么說
n
n%(x+1)==0
n 先手必輸,后手必贏
當
x
!
=
y
x!=y
x!=y的時候
這個時候誰減去的數比較大的話誰就能控制對方的局面,最終贏,自己思考一下?
code:
#include<bits/stdc++.h>
using namespace std;
int main(){
int n,x,y;
cin>>n>>x>>y;
if(n<=x) puts("Monody wins!");
else if(x==y){
if(n%(x+1)==0){
puts("LXHing wins!");
}
else puts("Monody wins!");
}
else{
if(x>y) puts("Monody wins!");
else puts("LXHing wins!");
}
return 0;
}
4. 合并石子
設
s
u
m
[
i
]
sum[i]
sum[i]代表前綴和,
L
[
i
]
L[i]
L[i]代表到i的石子數量(合并之后),
f
[
i
]
f[i]
f[i]表示到
i
i
i都符合要求的最小合并次數
狀態轉移方程 :
f
[
i
]
=
f
[
j
]
+
(
i
?
j
?
1
)
f[i] = f[j] + (i - j - 1)
f[i]=f[j]+(i?j?1) 也就是說再加上
i
+
1
i+1
i+1到
j
j
j需要合并的次數
那么就有轉移方程
for(int i=1;i<=n;i++)
for(int j=0;j<=i;j++)
if(sum[i]-sum[j]>=L[j]&&f[i]>=f[j]+i-j-1){
f[i]=f[j]+i-j-1;
L[i]=min(L[i],sum[i]-sum[j]);
}
code:
#include<bits/stdc++.h>
using namespace std;
const int N=5010;
int f[N];
int sum[N];
int L[N];
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
int x;
cin>>x;
sum[i]=sum[i-1]+x;
}
memset(f,0x3f,sizeof(f));
memset(L,0x3f,sizeof(L));
f[0]=L[0]=0;
for(int i=1;i<=n;i++){
for(int j=0;j<=i;j++){
if(sum[i]-sum[j]>=L[j]&&f[i]>=f[j]+i-j-1){
L[i]=min(sum[i]-sum[j],L[i]);
f[i]=f[j]+i-j-1;
}
}
}
cout<<f[n]<<endl;
}
5. 生成后臺資料
設計很久的防止AK題,所以做不出來那么很正常,甚至看不懂題解也正常,因為這個需要扎實資料結構的演算法思維
首先我們看一下這個50000規模的直接暴力的解法時間是多少
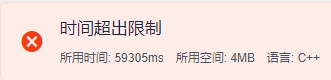
正確解法時間:
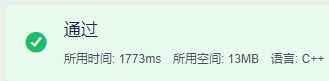
知道為什么直接排序會時間超出限制嗎?
分析一下,如果你用普通排序(比較,冒泡,插入排序),排序一次時間復雜度為
O
(
N
2
)
O(N^2)
O(N2),有M個待排序的區間,那么總的時間復雜度為
O
(
M
N
2
)
O(MN^2)
O(MN2),別說50000的規模了,1000都會時間超限,假如用快速排序那么總的時間復雜度為
O
(
M
N
l
o
g
N
)
O(MNlogN)
O(MNlogN)大概只能承受5000的規模,
正確解法
主體思想就是二分答案,大概就是不斷檢查二分出的答案是大了還是小了,這個可以通過將原陣列中大于二分出來的答案的數變成1,小于等于二分出來的答案的數變成0,來把原陣列變成一個01序列,之后再對01序列進行題目中的操作,
這個只需知道這段區間中有多少個1,然后把前面(降序,升序的話是后面)區間修改成1,其他的修改成0,就可以地實作排序,最后判斷要求的位置上是0/1就好了,若為0,則說明要找的數小于等于當前的答案,若為1,則說明要找的數大于當前答案, 二分的時間為
O
(
l
o
g
n
)
O(log n)
O(logn)
當然頻繁地修改區間,單次將區間修改為0/1區間的時間復雜度為
O
(
n
)
O(n)
O(n),有m次,那么總的時間復雜度為
O
(
M
N
l
o
g
N
)
O(MNlogN)
O(MNlogN),
那這樣有什么優秀的地方嘛,時間還是和快速排序版本一樣啊!這里還沒用上資料結構,別急我們提到了資料結構,
我們可以用資料結構來維護區間的資訊,這里用線段樹,分塊資料結構都行(ps:本題解不提供線段樹,分塊的教程,自行搜索資料學習或者努力打周賽獲得競賽編程書籍QAQ),線段樹在行本領的修改查詢區間時間復雜度
O
(
l
o
g
N
)
O(logN)
O(logN),修改查詢單點的值時間復雜度為
O
(
l
o
g
N
)
O(logN)
O(logN),
二分時間復雜度為
O
(
l
o
g
N
)
O(logN)
O(logN),區間修改的時間復雜度為
O
(
l
o
g
N
)
O(logN)
O(logN),有M次修改操作,那么總的時間復雜度為
O
(
M
l
o
g
2
N
)
O(Mlog^2N)
O(Mlog2N),快到起飛,
code:
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+100;
#define lc (p<<1)
#define rc (p<<1|1)
#define mid ((t[p].l+t[p].r)>>1)
int a[N];
struct Segment{
int l,r;
int lz;
int dat;
}t[N<<2];
void pushup(int p){
t[p].dat=(t[lc].dat+t[rc].dat);
}
void build(int p,int l,int r){
t[p].l=l,t[p].r=r;
t[p].lz=-1;
if(l==r){
t[p].dat=a[l];
return;
}
build(lc,l,mid);
build(rc,mid+1,r);
pushup(p);
}
void spread(int p){
if(t[p].lz!=-1){
t[lc].dat=(t[lc].r-t[lc].l+1)*t[p].lz;
t[rc].dat=(t[rc].r-t[rc].l+1)*t[p].lz;
t[lc].lz=t[p].lz;
t[rc].lz=t[p].lz;
t[p].lz=-1;
}
}
void update(int p,int l,int r,int v){
if(t[p].l>r||t[p].r<l) return;
if(l<=t[p].l&&t[p].r<=r){
t[p].dat=(t[p].r-t[p].l+1)*v;
t[p].lz=v;
return;
}
spread(p);
update(lc,l,r,v);
update(rc,l,r,v);
pushup(p);
}
int querysum(int p,int l,int r){
if(l<=t[p].l&&t[p].r<=r){
return t[p].dat;
}
spread(p);
int val=0;
if(l<=mid) val+=querysum(lc,l,r);
if(r>mid) val+=querysum(rc,l,r);
return val;
}
int query(int p,int x){
if(t[p].l==t[p].r) return t[p].dat;
spread(p);
if(x<=mid) return query(lc,x);
else return query(rc,x);
}
#undef mid
int n,m,k;
int val[N];
struct node{
string op;
int l,r;
}q[N];
inline int check(int mid){
for(int i=1;i<=n;i++){
if(val[i]>=mid) a[i]=1;
else a[i]=0;
}
build(1,1,n);
for(int i=1;i<=m;i++){
int l=q[i].l,r=q[i].r;
int cnt=querysum(1,l,r);
if(q[i].op=="up"){
update(1,r-cnt+1,r,1);
update(1,l,r-cnt,0);
}
else{
update(1,l,l+cnt-1,1);
update(1,l+cnt,r,0);
}
}
return query(1,k);
}
int main(){
cin>>n>>m>>k;
for(int i=1;i<=n;i++){
cin>>val[i];
}
for(int i=1;i<=m;i++){
int l,r;
string op;
cin>>l>>r>>op;
q[i]={op,l,r};
}
int l=1,r=n;
int ans;
while(l<=r){
int mid=(l+r)>>1;
if(check(mid)) l=mid+1,ans=mid;
else r=mid-1;
}
printf("%d\n",ans);
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234959.html
標籤:其他