前言
字典, 又稱符號表(symbol table)、關聯陣列(associative array)或者映射(map), 是一種用于保存鍵值對(key-value pair)的抽象資料結構,
在字典中, 一個鍵(key)可以和一個值(value)進行關聯(或者說將鍵映射為值), 這些關聯的鍵和值就被稱為鍵值對,
字典中的每個鍵都是獨一無二的, 程式可以在字典中根據鍵查找與之關聯的值, 或者通過鍵來更新值, 又或者根據鍵來洗掉整個鍵值對, 等等,
字典經常作為一種資料結構內置在很多高級編程語言里面, 但 Redis 所使用的 C 語言并沒有內置這種資料結構, 因此 Redis 構建了自己的字典實作,
字典在 Redis 中的應用相當廣泛, 比如 Redis 的資料庫就是使用字典來作為底層實作的, 對資料庫的增、刪、查、改操作也是構建在對字典的操作之上的,
因此,了解字典對我們了解Redis資料庫有很大的幫助,同時可以跟Java的HashMap進行對比,看看孰好孰壞,
字典的定義
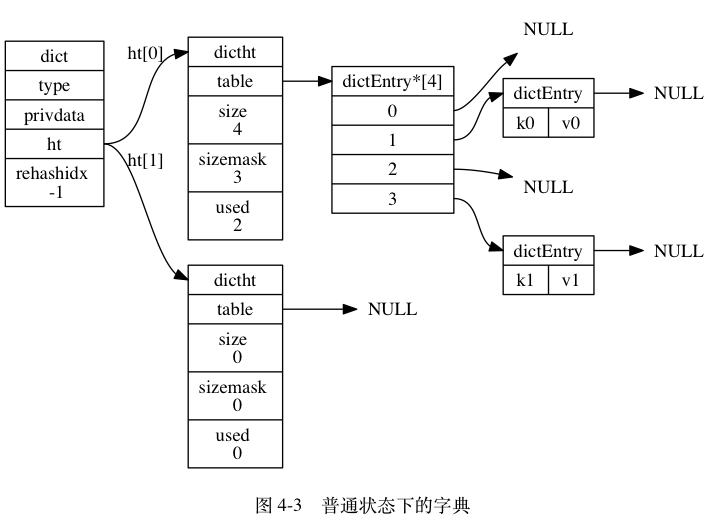
1 typedef struct dict { 2 3 // 型別特定函式 4 dictType *type; 5 6 // 私有資料 7 void *privdata; 8 9 // 哈希表 10 dictht ht[2]; 11 12 // rehash 索引 13 // 當 rehash 不在進行時,值為 -1 14 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ 15 16 } dict;
主要看ht,和rehashidx兩個引數,
ht 屬性是一個包含兩個項的陣列, 陣列中的每個項都是一個 dictht 哈希表, 一般情況下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只會在對 ht[0] 哈希表進行 rehash 時使用,
除了 ht[1] 之外, 另一個和 rehash 有關的屬性就是 rehashidx : 它記錄了 rehash 目前的進度, 如果目前沒有在進行 rehash , 那么它的值為 -1 ,
1 typedef struct dictht { 2 3 // 哈希表陣列 4 dictEntry **table; 5 6 // 哈希表大小 7 unsigned long size; 8 9 // 哈希表大小掩碼,用于計算索引值 10 // 總是等于 size - 1 11 unsigned long sizemask; 12 13 // 該哈希表已有節點的數量 14 unsigned long used; 15 16 } dictht;
table 屬性是一個陣列, 陣列中的每個元素都是一個指向 dict.h/dictEntry 結構的指標, 每個 dictEntry 結構保存著一個鍵值對,
size 屬性記錄了哈希表的大小, 也即是 table 陣列的大小
sizemask 屬性的值總是等于 size-1 , 這個屬性和哈希值一起決定一個鍵應該被放到 table 陣列的哪個索引上面,(不是很清楚,為什么要單獨定義一個mask,而不直接size-1);
而 used 屬性則記錄了哈希表目前已有節點(鍵值對)的數量,
1 typedef struct dictEntry { 2 3 // 鍵 4 void *key; 5 6 // 值 7 union { 8 void *val; 9 uint64_t u64; 10 int64_t s64; 11 } v; 12 13 // 指向下個哈希表節點,形成鏈表 14 struct dictEntry *next; 15 16 } dictEntry;
key 屬性保存著鍵值對中的鍵, 而 v 屬性則保存著鍵值對中的值, 其中鍵值對的值可以是一個指標, 或者是一個 uint64_t 整數, 又或者是一個 int64_t 整數,
next 屬性是指向另一個哈希表節點的指標, 這個指標可以將多個哈希值相同的鍵值對連接在一次, 以此來解決鍵沖突(collision)的問題,
可以明顯的看出來,redis是通過鏈表來解決hash沖突的,
因此,redis的字典大概如下:
Rehash
隨著操作的不斷執行, 哈希表保存的鍵值對會逐漸地增多或者減少, 為了讓哈希表的負載因子(load factor)維持在一個合理的范圍之內, 當哈希表保存的鍵值對數量太多或者太少時, 程式需要對哈希表的大小進行相應的擴展或者收縮,
也就是我們常說的,擴容,再次hash,
Redis rehash程序:
- 為字典的
ht[1]哈希表分配空間,一般為原字典的兩倍,即 ht[0] * 2; - 將保存在
ht[0]中的所有鍵值對 rehash 到ht[1]上面 - 當
ht[0]包含的所有鍵值對都遷移到了ht[1]之后 (ht[0]變為空表), 釋放ht[0], 將ht[1]設定為ht[0], 并在ht[1]新創建一個空白哈希表, 為下一次 rehash 做準備,
但其實rehash是非常的耗時間的,假設ht[0]非常的大呢? 40W,400W,甚至4000W呢?
一次rehash甚至可能導致redis宕機,所以出現了漸進式hash,
漸進式Rehash
這個 rehash 動作并不是一次性、集中式地完成的, 而是分多次、漸進式地完成的,為了避免 rehash 對服務器性能造成影響, 服務器不是一次性將 ht[0] 里面的所有鍵值對全部 rehash 到 ht[1] , 而是分多次、漸進式地將 ht[0] 里面的鍵值對慢慢地 rehash 到 ht[1] ,
- 為
ht[1]分配空間, 讓字典同時持有ht[0]和ht[1]兩個哈希表, - 在字典中維持一個索引計數器變數
rehashidx, 并將它的值設定為0, 表示 rehash 作業正式開始, - 在 rehash 進行期間, 每次對字典執行添加、洗掉、查找或者更新操作時, 程式除了執行指定的操作以外, 還會順帶將
ht[0]哈希表在rehashidx索引上的所有鍵值對 rehash 到ht[1], 當 rehash 作業完成之后, 程式將rehashidx屬性的值增一, - 隨著字典操作的不斷執行, 最終在某個時間點上,
ht[0]的所有鍵值對都會被 rehash 至ht[1], 這時程式將rehashidx屬性的值設為-1, 表示 rehash 操作已完成,
擴容代碼大致如下:
1 int dictRehash(dict *d, int n) { 2 int empty_visits = n*10; /* Max number of empty buckets to visit. */ 3 4 // 判斷是否正在擴容 5 if (!dictIsRehashing(d)) return 0; 6 7 while(n-- && d->ht[0].used != 0) { 8 dictEntry *de, *nextde; 9 10 /* Note that rehashidx can't overflow as we are sure there are more 11 * elements because ht[0].used != 0 */ 12 assert(d->ht[0].size > (unsigned long)d->rehashidx); 13 14 // 找到一個不為空的桶,進行遷移 15 while(d->ht[0].table[d->rehashidx] == NULL) { 16 d->rehashidx++; 17 if (--empty_visits == 0) return 1; 18 } 19 // 找到這個桶第一個指標節點 20 de = d->ht[0].table[d->rehashidx]; 21 // 將這個桶中的所有的key節點轉移到新的陣列中,while回圈鏈表 22 while(de) { 23 uint64_t h; 24 25 nextde = de->next; 26 /* Get the index in the new hash table */ 27 h = dictHashKey(d, de->key) & d->ht[1].sizemask; 28 de->next = d->ht[1].table[h]; 29 d->ht[1].table[h] = de; 30 d->ht[0].used--; 31 d->ht[1].used++; 32 de = nextde; 33 } 34 // 舊的桶節點置為null,并且rehashidx+1 35 d->ht[0].table[d->rehashidx] = NULL; 36 d->rehashidx++; 37 } 38 39 /* Check if we already rehashed the whole table... */ 40 if (d->ht[0].used == 0) { 41 zfree(d->ht[0].table); 42 d->ht[0] = d->ht[1]; 43 _dictReset(&d->ht[1]); 44 d->rehashidx = -1; 45 return 0; 46 } 47 48 /* More to rehash... */ 49 return 1; 50 }
在進行漸進式 rehash 的程序中, 字典會同時使用 ht[0] 和 ht[1] 兩個哈希表, 所以在漸進式 rehash 進行期間, 字典的洗掉(delete)、查找(find)、更新(update)等操作會在兩個哈希表上進行: 比如說, 要在字典里面查找一個鍵的話, 程式會先在 ht[0]里面進行查找, 如果沒找到的話, 就會繼續到 ht[1] 里面進行查找, 諸如此類,
另外, 在漸進式 rehash 執行期間, 新添加到字典的鍵值對一律會被保存到 ht[1] 里面, 而 ht[0] 則不再進行任何添加操作: 這一措施保證了 ht[0] 包含的鍵值對數量會只減不增, 并隨著 rehash 操作的執行而最終變成空表,
所遇到問提
問題一:
要在字典里面查找一個鍵的話, 程式會先在 ht[0]里面進行查找, 如果沒找到的話, 就會繼續到 ht[1] 里面進行查找, 諸如此類,
這一點其實我比較有疑惑?為何要先去ht[0]中查找,找不到再去ht[1]中查找,這樣豈不是效率低下,查找了兩張表,不能根據hash值和rehashidx進行比較判斷么?只查一張表不行么?
為此我翻閱了不少資料:
這是redis官方其他人的pull request:https://github.com/antirez/redis/pull/5692 暫時還沒有merge
同時這是我和一位大佬的討論:https://github.com/Junnplus/blog/issues/35 最終得出結論
還是看原始碼:(原始碼真是一個好東西)
1 for (table = 0; table <= 1; table++) { 2 // 找到key的index 3 idx = h & d->ht[table].sizemask; 4 // 拿到key值對應的value 5 he = d->ht[table].table[idx]; 6 while(he) { 7 if (key==he->key || dictCompareKeys(d, key, he->key)) 8 return he; 9 he = he->next; 10 } 11 if (!dictIsRehashing(d)) return NULL; 12 }
其實只有兩種情況
- key在ht[0],還沒有遷移
- key在ht[1],已經遷移了,
針對第一種情況,他在第一層的回圈已經找到了key值,并且回傳(第八行),不再繼續后面操作,因此不存在效率問題,
第二種情況,看第五行,he此時為null,根本不會回圈鏈表,然后第二次回圈才能找到key,而第一次是做了一次hash,復雜度為O(1),效率幾乎是沒有損失,因此也不存在效率問題,
綜上:我得出的結論是,可以拿idx和rehashidx進行對比,同時也可以像redis這樣寫,不會損失效率,redis可能為了代碼的簡潔以及統一,不想寫那么多的判斷條件,因此沒有比較idx和rehashidx,
當我認為提前結束會更好,畢竟不用后續判斷了,也比較清楚,類似這個request:https://github.com/antirez/redis/pull/5692/files
問題二:
假如在redis準備進行rehash的時候,他需要為ht[1]申請一塊記憶體,這塊記憶體可是ht[0]的兩倍哦,那次是計算機記憶體不存會如何?
梳理一下哈希表大小和記憶體申請大小的對應關系:
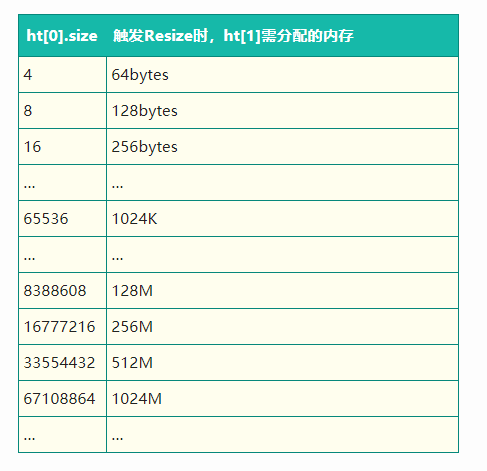
正常狀態下,redis為ht[1]分配完記憶體后,會持續一段時間進行rehash,rehash完畢后,就會釋放ht[0]記憶體了,類似如下圖:
記憶體先上升,后下降,
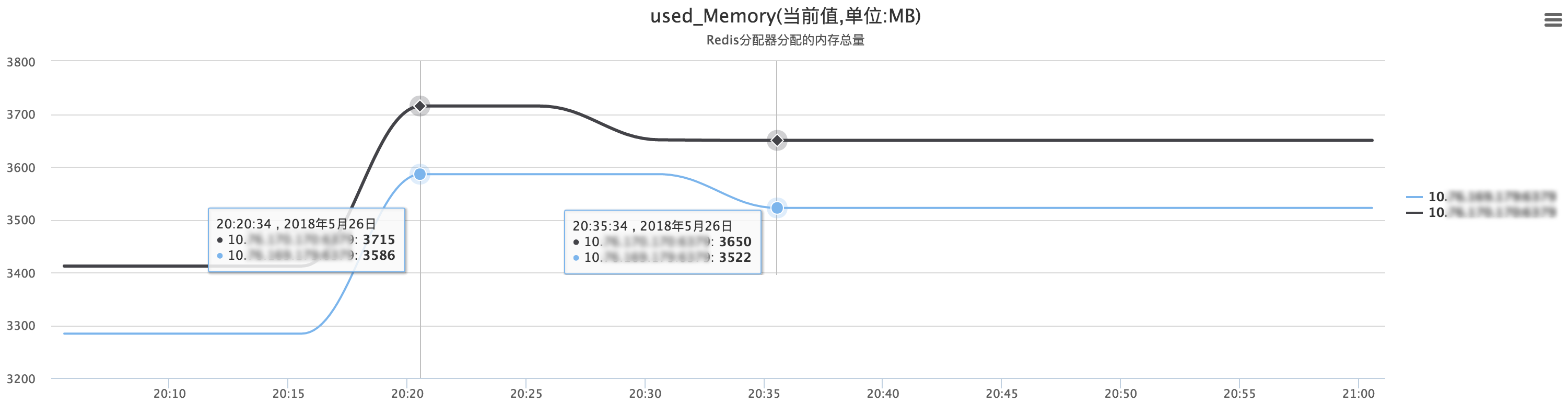
但此時記憶體不存的話,Redis會進行大量的Key驅逐,也就是會淘汰掉很久未使用的key,跟LRU有點類似,
那么此時可能就會影響到了業務,這是非常大的問題呢,
那么針對在Redis滿容驅逐狀態下,如何避免因Rehash而導致Redis抖動的這種問題,
- 我們在Redis Rehash原始碼實作的邏輯上,加上了一個判斷條件,如果現有的剩余記憶體不夠觸發Rehash操作所需申請的記憶體大小,即不進行Resize操作;
- 通過提前運營進行規避,比如容量預估時將Rehash占用的記憶體考慮在內,或者通過監控定時擴容,
參考文獻:
《redis設計與實作》 http://redisbook.com/preview/dict/incremental_rehashing.html
《美團針對Redis Rehash機制的探索和實踐》 https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
《Redis原始碼分析》 https://github.com/Junnplus/blog/issues/35
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/235313.html
標籤:其他