
在前一講(不復雜的時間復雜度)中,我們介紹了「時間復雜度」,
和(漸進)時間復雜度一樣,「空間復雜度」(space complexity)也不是去計算程式具體占用了多少的空間,而是反映演算法運行程序中大約會臨時占用多少存盤空間的一個趨勢,我們同樣更關心的是所需空間是如何隨著輸入資料的增長而增長的,
大O表示法 \(O(f(n))\) 在數學上的定義是上限趨近于 \(f(n)\) 函式的合集,它可以被用于表示時間復雜度,同樣也可以被用于表示空間復雜度,
我們將空間復雜度定義為 \(S(n)\),通過大O表示法 \(O(f(n))\) 來表示,記為\(S(n) = O(f(n))\),
空間復雜度\(O(1)\)
int sum(int x, int y, int z) {
int r = x + y + z;
return r;
}
該演算法無論怎樣都是分配3個存盤單元給引數,1個存盤單元給本地變數,所以該演算法的空間復雜度為\(O(1)\),標記為\(S(n) = O(1)\),
空間復雜度\(O(n)\)
int sum(int a[], int n) {
int r = 0;
for (int i = 0; i < n; ++i) {
r += a[i];
}
return r;
}
該演算法需要分配n個存盤單元給陣列\(a\),還有3個存盤單元給變數\(n\),\(r\),\(i\),但它們不隨資料規模的增長而改變,n才是主導性因素,所以該演算法的空間復雜度為\(O(n)\),
其他情況
如果一個函式\(A\)需要M個存盤單元(包括本地變數和引數),并且它呼叫了一次函式B,函式B需要N個存盤單元,那么函式A就總共需要M+N個存盤空間,如果它呼叫了三次函式B,也仍然只需要M+N的存盤空間,原因是因為B在呼叫時會將其壓入堆疊中(push),在一次呼叫結束時會將其推出堆疊(pop),等到新一次的呼叫時再將其重新壓入堆疊,所以這份空間一直在被重復利用,所以不會需要更多存盤空間,
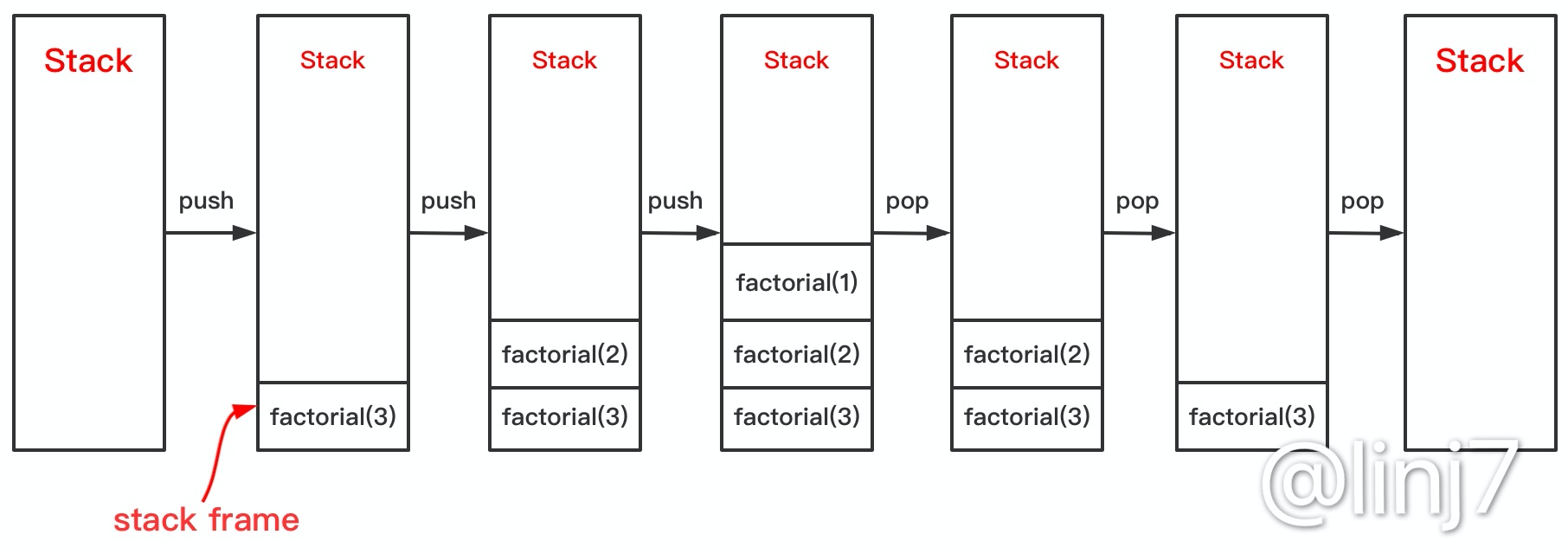
那如果函式\(A\)是個遞回函式,它反復呼叫自身n次呢?那它就需要\(M \times N\)個存盤空間,即空間復雜度為\(O(n^2)\),這是因為只有當函式呼叫到最后一層時才會結束一層呼叫,而之前的呼叫由于沒有結束,所以會被一直壓入堆疊中,如下圖所示,空間無法得以重復利用,所以空間復雜度為\(O(n^2)\),
此外,如果傳遞的是指標或參考,由于它們都會指向原本的記憶體空間,因此不需要分配新的存盤單元,
后記(摘選自此文)
如今硬體的存盤量級都比較大,一般不會為了稍微減少一點兒空間復雜度而大動干戈,更多的是去想怎么優化演算法的時間復雜度,因此衍生出了用「空間換時間」的做法,并且成為常態,
比如我們在求解斐波那契數列的時候我們可以直接用公式去遞回求,用哪個求哪個,同樣也可以先把很多結果都算出來保存起來,然后用到哪個直接呼叫,這就是典型的用空間換時間的做法,但是你說這兩種具體哪個好,偉大的馬克思告訴我們「具體問題具體分析」,
總結
本講介紹了衡量演算法在空間維度上的指標——空間復雜度,常見的空間復雜度量級有\(O(1)\)和\(O(n)\),本講還介紹了當函式呼叫其他函式和呼叫自身函式這兩種情形下的空間占用情況,由于如今硬體的存盤量級都較大,空間換時間的做法成為常態,
參考
- https://courses.cs.northwestern.edu/311/html/space-complexity.html
- https://www.sohu.com/a/271774788_115128
創作不易,點個贊再走叭~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/235326.html
標籤:其他
上一篇:樹狀陣列詳解