上一節我們了解了PNET的基本原理,本節看看如何生成PNET需要的訓練資料,總體而言我們需要產生兩部分資料,一部分圖片里面包含人臉,另一部分不包含人臉,這里的“包含”或“不包含”并不是指圖片中完全沒有人臉,而是圖片中人臉占據的比率超過一定的閾值時就可以認為給定圖片包含人臉,
演算法會設定三個閾值,當人臉在圖片區域占據比率不超過30%,那么認為圖片不包含人臉,如果超過30%但是不到45%,那么圖片屬于“中性”,當人臉占據區域超過65%則斷定圖片內含有人臉,訓練使用的資料集為WIDERFace,該資料集不但包含了大量含有人臉的圖片,而且還通過文本檔案詳細描述了每張圖片中人臉所在的坐標位置,
下載給定資料集后解壓,可以看到路徑下有多個檔案夾和一個文本檔案,檔案夾中包含不同型別的人臉圖片,文本檔案描述了每張圖片中人臉的坐標位置,例如打開文本可以看到如下一行資訊:
0_Parade_marchingband_1_205 59.60 56.00 78.29 74.94 39.41 1.66 56.60 22.60 90.26 18.61 106.71 41.04 144.10 15.87 161.05 37.30 117.68 30.32 132.38 47.02 201.93 16.36 221.37 36.06 162.79 53.26 176.50 72.45 97.98 53.26 113.19 79.43 9.34 85.48 22.43 106.57 59.35 116.15 76.15 139.59 45.29 161.07 59.74 182.17 18.25 247.82 48.34 278.95 114.79 237.10 139.12 265.09 210.80 239.19 231.73 266.66 308.43 259.50 332.99 285.24 402.90 205.89 433.36 242.02 260.95 141.52 280.40 164.15 283.12 151.71 301.22 170.71 353.49 159.85 370.91 183.38 238.07 37.05 250.12 56.08 251.39 28.39 271.26 47.62 266.40 56.71 280.56 75.95 357.28 80.38 371.45 101.73 489.01 112.72 508.57 135.54 545.43 122.50 561.98 148.07 511.58 73.61 529.88 94.92 543.67 75.11 560.97 100.18 544.68 49.29 561.22 67.59 562.48 67.09 583.04 96.17 464.94 68.59 482.75 94.92 502.80 37.00 520.86 56.81 595.57 53.05 612.62 70.85 574.01 138.29 588.80 159.86 554.71 164.62 567.99 185.18 497.47 256.35 526.72 284.60 580.56 239.07 607.82 267.32 706.86 166.62 747.08 209.82 654.28 140.01 672.72 164.13 533.31 3.35 549.04 20.67 596.23 20.99 613.08 39.74 684.31 47.47 699.18 67.20 665.16 40.90 678.88 58.91 659.73 6.03 673.73 27.46 747.49 10.31 765.78 32.90 795.22 17.75 809.80 37.76 813.52 16.03 830.67 41.19 850.39 39.76 870.40 62.63 806.94 59.48 823.81 84.06 739.20 54.34 756.92 78.35 831.81 117.80 852.40 140.38 866.69 108.36 882.70 132.09 798.11 221.94 830.85 260.00 870.04 236.21 898.59 267.28 911.23 223.52 927.69 245.54 991.32 142.56 1011.70 164.67 940.88 88.66 958.15 109.39 917.04 24.75 939.50 53.08 1000.30 25.44 1017.23 45.83 932.24 58.95 949.51 83.14 759.27 34.53 774.08 57.43 758.94 127.71 775.70 152.78 346.72 22.38 363.76 40.91 25.75 42.00 40.87 63.96 47.01 23.81 62.83 45.78 328.05 219.76 350.44 243.90 "
資料以空格將不同資訊分離,第一個空格前面的字串對應圖片的名稱,上面資料就表明有一張名為0_Parade_marchingband_1_205.jpg的圖片,后面的數字以每四個為一組分別對應一張人臉在圖片中的坐標,因此我們可以通過這些資料將圖片中的人臉“框”出來:
txt_line = "0_Parade_marchingband_1_205 59.60 56.00 78.29 74.94 39.41 1.66 56.60 22.60 90.26 18.61 106.71 41.04 144.10 15.87 161.05 37.30 117.68 30.32 132.38 47.02 201.93 16.36 221.37 36.06 162.79 53.26 176.50 72.45 97.98 53.26 113.19 79.43 9.34 85.48 22.43 106.57 59.35 116.15 76.15 139.59 45.29 161.07 59.74 182.17 18.25 247.82 48.34 278.95 114.79 237.10 139.12 265.09 210.80 239.19 231.73 266.66 308.43 259.50 332.99 285.24 402.90 205.89 433.36 242.02 260.95 141.52 280.40 164.15 283.12 151.71 301.22 170.71 353.49 159.85 370.91 183.38 238.07 37.05 250.12 56.08 251.39 28.39 271.26 47.62 266.40 56.71 280.56 75.95 357.28 80.38 371.45 101.73 489.01 112.72 508.57 135.54 545.43 122.50 561.98 148.07 511.58 73.61 529.88 94.92 543.67 75.11 560.97 100.18 544.68 49.29 561.22 67.59 562.48 67.09 583.04 96.17 464.94 68.59 482.75 94.92 502.80 37.00 520.86 56.81 595.57 53.05 612.62 70.85 574.01 138.29 588.80 159.86 554.71 164.62 567.99 185.18 497.47 256.35 526.72 284.60 580.56 239.07 607.82 267.32 706.86 166.62 747.08 209.82 654.28 140.01 672.72 164.13 533.31 3.35 549.04 20.67 596.23 20.99 613.08 39.74 684.31 47.47 699.18 67.20 665.16 40.90 678.88 58.91 659.73 6.03 673.73 27.46 747.49 10.31 765.78 32.90 795.22 17.75 809.80 37.76 813.52 16.03 830.67 41.19 850.39 39.76 870.40 62.63 806.94 59.48 823.81 84.06 739.20 54.34 756.92 78.35 831.81 117.80 852.40 140.38 866.69 108.36 882.70 132.09 798.11 221.94 830.85 260.00 870.04 236.21 898.59 267.28 911.23 223.52 927.69 245.54 991.32 142.56 1011.70 164.67 940.88 88.66 958.15 109.39 917.04 24.75 939.50 53.08 1000.30 25.44 1017.23 45.83 932.24 58.95 949.51 83.14 759.27 34.53 774.08 57.43 758.94 127.71 775.70 152.78 346.72 22.38 363.76 40.91 25.75 42.00 40.87 63.96 47.01 23.81 62.83 45.78 328.05 219.76 350.44 243.90 "
annotation = txt_line.strip().split(' ')
img_path = annotation[0]
box = list(map(float, annotation[1:]))
boxes = np.array(box, dtype=np.float32).reshape(-1, 4)
print("image contains {} faces".format(len(boxes)))
img = cv2.imread(img_path + ".jpg")
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
img = cv2.rectangle(img, top_left, bottom_right, (255,0,0), 1)
cv2_imshow(img)
上面代碼運行后結果如下:
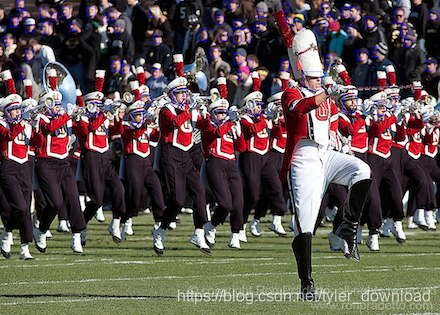
可以看到圖片中很多人臉都被藍色方框選中,由此根據資料集給定資訊我們可以構造不同型別的訓練資料,第一種稱為"neg"的圖片,圖片中人臉占總區域的比率不到0.3,第二種稱為"part",這種人臉在這種圖片中占據的區域在0.3到0.4之間,第三種稱為"pos",人臉占據圖片區域在0,65以上,為了更形象的展示這三種圖片的特性,我們選擇一張只有一個人臉的圖片進行實體講解,首先我們把讀取人臉坐標的邏輯用一個函式封裝起來,然后加載實體需要的人臉圖片:
def get_img_boxes(txt_line):
cur_path = os.getcwd()
annotation = txt_line.strip().split(' ')
img_path = os.path.join(cur_path, annotation[0] + ".jpg")
box = list(map(float, annotation[1:]))
boxes = np.array(box, dtype=np.float32).reshape(-1, 4)
return img_path, boxes
txt_line = "0_Parade_marchingband_1_849 448.51 329.63 570.09 478.23 "
img_path, boxes = get_img_boxes(txt_line)
print("image contains {} faces".format(len(boxes)))
face_img = cv2.imread(img_path)
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
face_img = cv2.rectangle(face_img, top_left, bottom_right, (255,0,0), 1)
cv2_imshow(face_img)
上面代碼運行后結果如下:

接下來我們要生成"neg"屬性的訓練圖片,演算法的基本思路是,在圖片上隨機選擇一系列區域,然后計算所選擇區域與人臉區域的“并”,所謂”并“就是將選擇區域與人臉區域兩部分面積求和,然后減去重疊部分的面積,然后計算重疊部分面積占“并”后面積的比率,根據比率的大小來決定圖片的屬性,由此我們給出計算人臉所占區域比率的代碼:
def IOU(box, boxes):
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
boxes_area = (boxes[:,2] - boxes[:,0] + 1) * (boxes[:,3] - boxes[:,1] + 1)
#計算矩形重疊部分面積
xx1 = np.maximum(box[0], boxes[: ,0])
yy1 = np.maximum(box[1], boxes[:,1])
xx2 = np.minimum(box[2], boxes[:,2])
yy2 = np.minimum(box[3], boxes[:,3])
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
over_lap = w * h
area_combine = (box_area + boxes_area - over_lap + 1e-10) #1e-10避免數值為0
overlap_percentage = over_lap / area_combine
return overlap_percentage
代碼將兩個區域的面積加總然后減去兩個區域的重疊部分由此得到兩個區域的“并后我們隨機在圖片上扣出一系列區域,然后選擇那些與人臉區域交集所占比率小于0.3的區域作為訓練資料:
npr=np.random
def create_neg_parts(img, face_boxes):
neg_num = 0
height, width, channel = img.shape
neg_boxes = []
while neg_num < 50:
#隨機截取一個區域,不小于12*12,因為pnet要訓練得識別12*12的圖片內部是否有人臉
size = npr.randint(12, min(width, height) / 2)
#選取左上角坐標
nx = npr.randint(0, width - size)
ny = npr.randint(0, height - size)
crop_box = np.array([nx, ny, nx+size, ny + size])
iou = IOU(crop_box, face_boxes)
if np.max(iou) < 0.3: #如果截取的面積與所有人臉面積重疊部分小于兩者合并面積的0.3表明截取面積中不含有人臉
neg_boxes.append(crop_box)
neg_num += 1
return neg_boxes
def draw_boxes(img, boxes, color):
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
img = cv2.rectangle(img, top_left, bottom_right, color, 1)
cv2_imshow(img)
接著我們呼叫上面代碼并將所選擇的區域繪制出來,這樣讀者就能對演算法和代碼有更感性的理解:
print(len(boxes))
color = (0, 255, 0)
neg_boxes = create_neg_parts(face_img, boxes)
draw_boxes(face_img.copy(), neg_boxes, color)
代碼運行后所得結果如下:

注意到綠色方框所對應的區域要不完全不包含人臉,要不與人臉區域的交集所占比率少于0.3.為了讓網路對人臉的識別能力更強,我們還需要構造一部分人臉區域所占比率接近0.3的圖片,也就是圖片中含有一小部分人臉,這種只包含部分人臉的圖片對網路的訓練效果最好,選取包含部分人臉圖片的代碼如下:
def create_neg_overlapped_parts(img, face_boxes): #產生只含有部分臉部的區域
height, width, channel = img.shape
neg_overlapped_boxes = []
for box in face_boxes:
left, top, right, bottom = box
w = right - left
h = bottom - top
if max(w, h) < 20 or left < 0 or top < 0: #忽略掉小于20像素的人臉區域
continue
for i in range(5): #每個人臉區域最多生成5個重疊不超過0.3的區域
size = npr.randint(12, min(width, height))
delta_x = npr.randint(max(-size, -left), w)
delta_y = npr.randint(max(-size, -top), h) #沿著左上角隨機上下和左右偏移形成重疊區域的左上角
nx1 = int(max(0, left + delta_x))
ny1 = int(max(0, top + delta_y))
if nx1 + size > width or ny1 + size > height: #確保創建的區域不超過整個圖片范圍
continue
crop_box = np.array([nx1, ny1, nx1+size, ny1+size])
iou = IOU(crop_box, face_boxes)
if np.max(iou) < 0.3:
neg_overlapped_boxes.append(crop_box)
return neg_overlapped_boxes
neg_overlapped_boxes = create_neg_overlapped_parts(face_img, boxes)
print(len(neg_overlapped_boxes))
color = (0, 0, 255)
draw_boxes(face_img.copy(), neg_overlapped_boxes, color)
上面代碼運行后結果如下:

從上圖看到紅色方框就是代碼選擇的區域,這些區域與藍色人臉區域都有重疊,同時重疊部分占兩個區域面積的比率都少于03.接下來使用同樣的方法產生性質為“part"和"post"的圖片,這類圖片包含一部分人臉,其中人臉所占圖片比率在0.3和0.45之間,要不就占據比率超過0.65,而后者是被認為包含了人臉的圖片,代碼如下:
def create_pos_part_box(img, boxes): #產生與臉部重疊部分超過0.65和0.45的交集區域
height, width, channel = img.shape
pos_boxes = []
pos_offset = []
part_boxes = []
part_offset = []
for box in boxes:
left, top, right, bottom = box
w = right - left
h = bottom - top
if max(w, h) < 20 or left < 0 or top < 0:
continue
for i in range(20): #每個人臉生成20個與人臉部分重疊超過0.65或0.4的區域
size = npr.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
if w < 5:
continue
delta_x = npr.randint(-w * 0.2, w * 0.2)
delta_y = npr.randint(-h * 0.2, h * 0.2)
nx1 = int(max(left + w /2 + delta_x - size / 2, 0))
ny1 = int(max(top + h / 2 + delta_y - size / 2, 0))
nx2 = nx1 + size
ny2 = ny1 + size
if nx2 > width or ny2 > height: # 生成區域不能超出圖片大小
continue
crop_box = np.array([nx1, ny1, nx2, ny2])
#計算生成區域左上角和右下角相對于人臉框的偏移比率后期計算需要
offset_x1 = (left - nx1)/float(size)
offset_y1 = (top - ny1) / float(size)
offset_x2 = (right - nx2) / float(size)
offset_y2 = (bottom - ny2) / float(size)
box_ = box.reshape(1, -1)
iou = IOU(crop_box, box_)
if np.max(iou) >= 0.65:
pos_boxes.append(crop_box)
pos_offset.append((offset_x1, offset_y1, offset_x2, offset_y2))
elif np.max(iou) >= 0.4:
part_boxes.append(crop_box)
part_offset.append((offset_x1, offset_y1, offset_x2, offset_y2))
return pos_boxes, pos_offset, part_boxes, part_offset
pos_boxes, pos_offset, part_boxes, part_offset = create_pos_part_box(face_img, boxes)
print("pos boxes len: ", len(pos_boxes))
print("part boxes len: ", len(part_boxes))
color = (125, 125, 0)
draw_boxes(face_img.copy(), pos_boxes, color) #顯示與臉部重疊面積超過0.65的區域
上面代碼運行后結果如下:

圖片中綠色方框就是代碼選擇比率超過0.65的區域,注意到這些區域與藍色方框對應的人臉區域有很大的重疊部分,我們再看看比率在0.3到0.45直接的區域:
color = (0, 125, 125)
draw_boxes(face_img.copy(), part_boxes, color) #顯示與臉部重疊面積超過0.4的區域
代碼運行后所得結果如下:

我們將三部分資料分別存盤在不同檔案夾下,第一種存在"neg"檔案夾,第二種存在"part"檔案夾,第三種存在"pos"檔案夾,然后就可以把他們當做訓練資料輸入網路,這些實踐對理論的理解至關重要,如若不然你看論文描述的演算法就會落入到云里霧里,這也是我認為很多知乎上的文章是裝逼假把式的主要原因,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/235411.html
標籤:AI