簡介
prometheus是一個開源的系統監控和警報工具包,最初由SoundCloud開發,自2012年始,許多公司和組織已經采用了prometheus,該專案擁有活躍的開發人員和用戶社區,
它現在是一個獨立的開源專案,獨立于任何公司進行維護,著重于此,prometheus在2016年加入CNCF,是繼kubernetes之后第二個托管的專案,
官網地址: Prometheus
github地址: github
架構圖
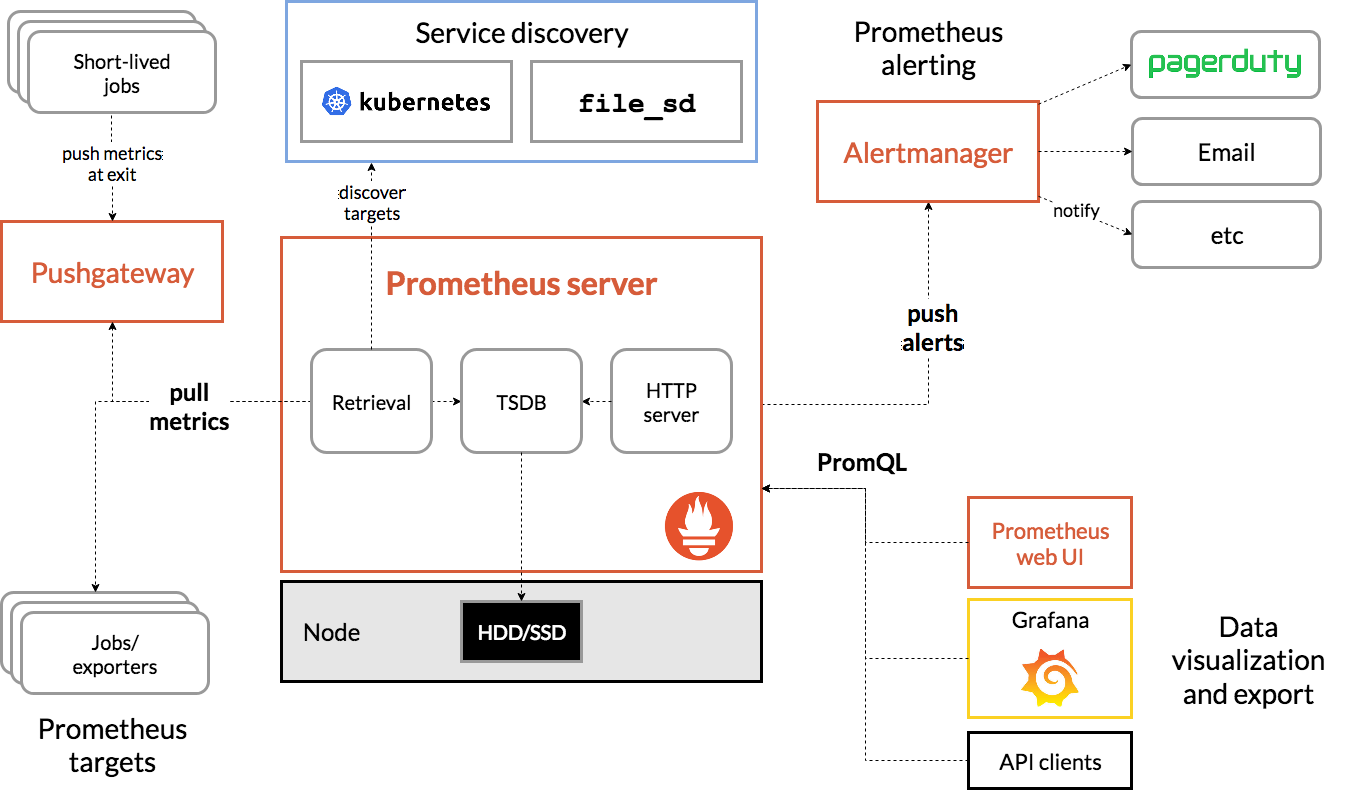
下載與安裝
安裝方式有很多種,如果你是windows用戶,那么只需要在本地起個二進制服務就可以,如果你是linux用戶,可以通過docker等更加靈活方式部署,
二進制
二進制下載地址
tar xvfz prometheus-*.tar.gz
cd prometheus-*
./prometheus --config.file=prometheus.yml
當然你可以下載最新的原始碼進行編譯獲取最新的二進制檔案,
mkdir -p $GOPATH/src/github.com/prometheus
cd $GOPATH/src/github.com/prometheus
git clone https://github.com/prometheus/prometheus.git
cd prometheus
make build
./prometheus -config.file=your_config.yml
docker
# 使用 /opt/prometheus/prometheus.yml 的配置
docker run --name prometheus -d -p 127.0.0.1:9090:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
helm
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add stable https://charts.helm.sh/stable
helm repo update
# Helm 3
$ helm install [RELEASE_NAME] prometheus-community/prometheus
# Helm 2
$ helm install --name [RELEASE_NAME] prometheus-community/prometheus
組態檔
prometheus已經能夠起來了,我們也需要對服務做一些個性化的配置,讓prometheus能夠獲取到資料,
global:
scrape_interval: 15s # 默認抓取間隔,15s向目標抓取一次資料
external_labels:
monitor: 'prometheus-monitor'
# 抓取物件
scrape_configs:
- job_name: 'prometheus' # 名稱,會在每一條metrics添加標簽{job_name:"prometheus"}
scrape_interval: 5s # 抓取時間
static_configs: # 抓取物件
- targets: ['localhost:9090']
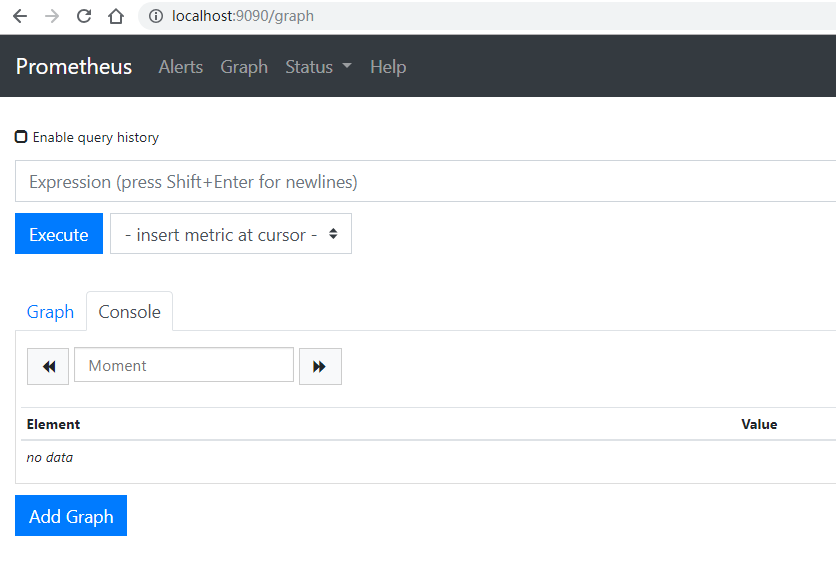

重啟完畢后,我們可以看到這兩個界面,
安裝exporter
如何獲取資料源?從下面的鏈接你可以挑選一些官方或非官方的exporter來監控你的服務,
exporters and integrations
例如:Node Exporter 暴露了如linux等UNIX系統的內核和機器級別的指標(windows用戶應用wmi_exporter),它提供了很多標準的指標如CPU、記憶體、磁盤空間、硬碟I/O和網路帶寬,此外,它還提供了從負載率平均值到主板溫度等很多內核暴露的問題,
下載運行之后,我們需要更新prometheus.yml,然后 重啟 prometheus加載新的配置
global:
scrape_interval: 15s # 默認抓取間隔,15s向目標抓取一次資料
external_labels:
monitor: 'codelab-monitor'
# 抓取物件
scrape_configs:
- job_name: 'prometheus' # 名稱,會在每一條metrics添加標簽{job_name:"prometheus"}
scrape_interval: 5s # 抓取時間
static_configs: # 抓取物件
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
告警通知
如果你需要設定特定的規則,例如cpu/記憶體超過了設定值,需要將告警資料發送到你的郵件、微信、釘釘等,那么你就需要Alertmanager,
告警分為兩個部分,首先需要在prometheus中添加告警規則,定義告警產生的邏輯,其次Altermanager將觸發的警報轉化為通知,例如郵件,呼叫和聊天訊息,
global:
scrape_interval: 15s # 默認抓取間隔,15s向目標抓取一次資料
evaluation_interval: 10s
external_labels:
monitor: 'codelab-monitor'
# 規則檔案
rule_files:
- rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# 抓取物件
scrape_configs:
- job_name: 'prometheus' # 名稱,會在每一條metrics添加標簽{job_name:"prometheus"}
scrape_interval: 5s # 抓取時間
static_configs: # 抓取物件
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
# 規則檔案rules.yml
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
按照 evaluation_interval 的配置,InstanceDown告警每10s將被執行1次,如果持續1m收到資料,那么這個告警就會被觸發,在達到設定的時間長度前,這個告警處于 pending 狀態,在 Alerts 頁面可以單擊警告查看包括它的標簽在內的更多詳細資訊,
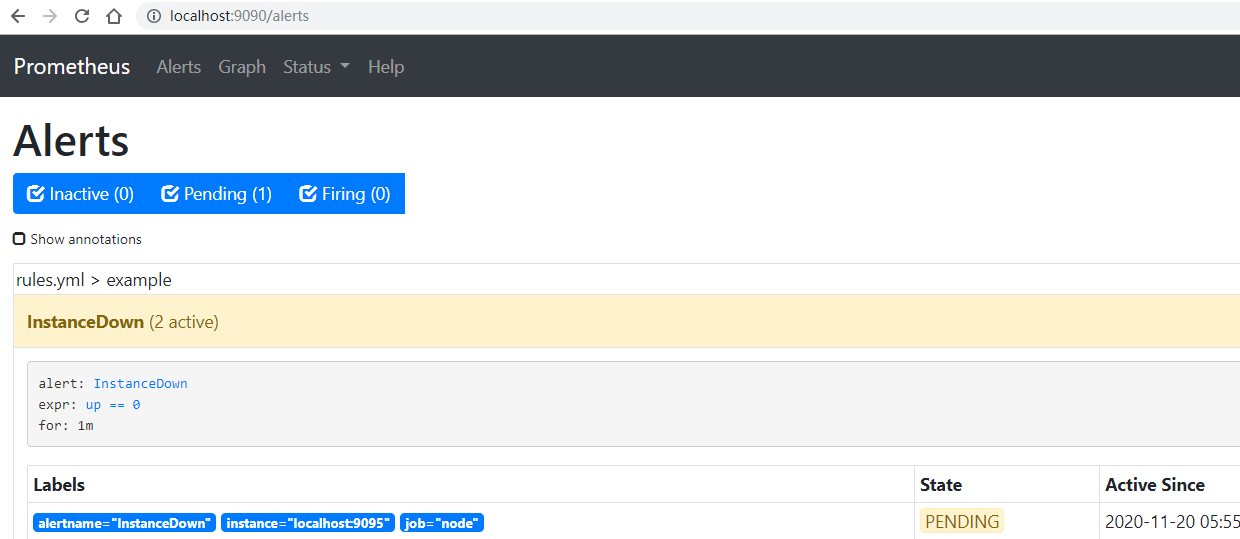
注:通常建議至少5min以減少噪聲從而減輕固有監控的各種情況,
既然有一個被觸發的告警,需要 Alertmanager 針對它做一些事,
Alertmanager
如何管理告警通知?
比如我只想作業時間收到告警,那么可以設定告警事件為09:00-21:00,
比如我某個服務不想收到通知,那么可以暫時關閉通知,
下載地址
現在需要為 Alertmanager 創建一個組態檔,這里有很多中方式讓Alertmanager 通知到你,這里使用SMTP,
global:
smtp_smarthost: 'localhost:25'
smtp_from: '[email protected]'
route:
receiver: example-email
receivers:
- name: 'example-email'
email_configs:
- to: '[email protected]'
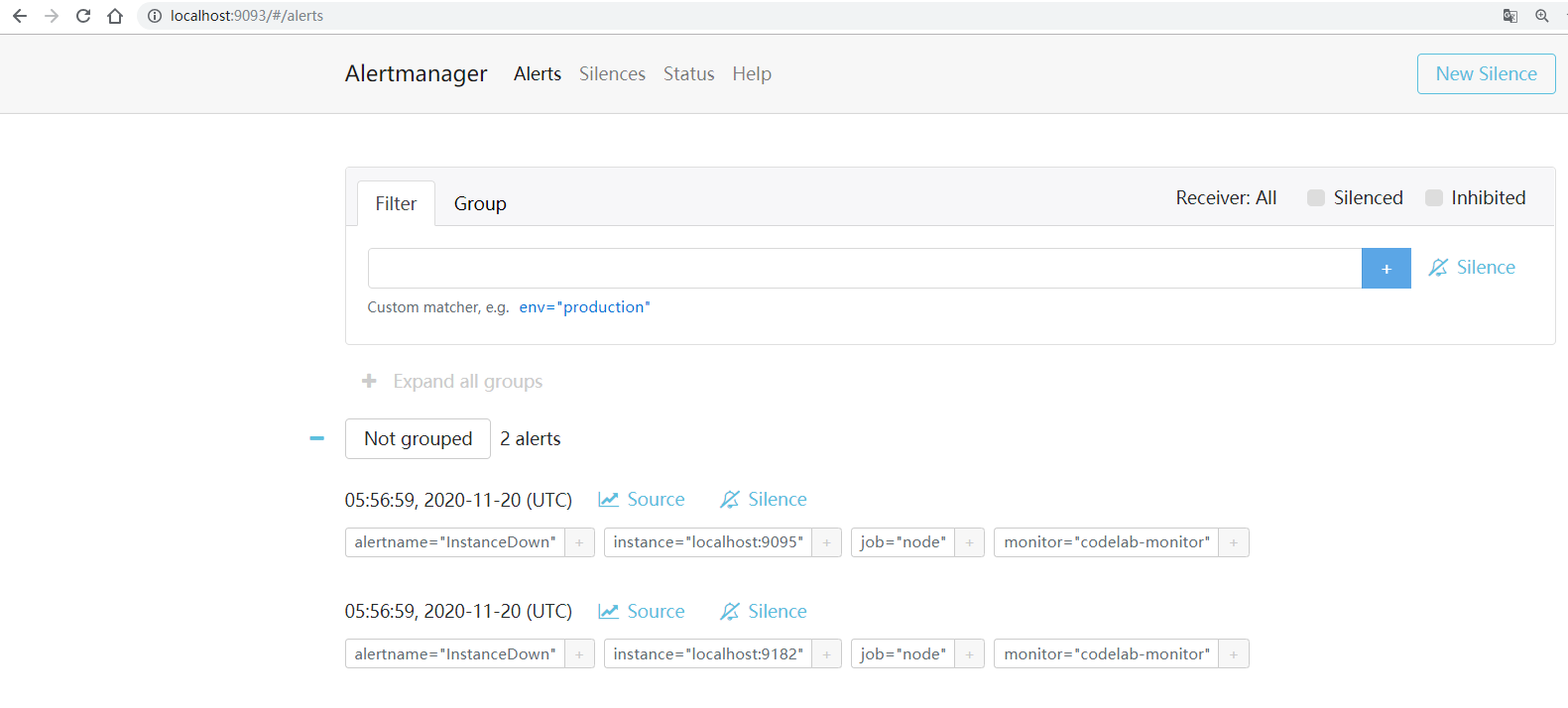
啟動Alertmanager,現在可以在瀏覽器輸入 http://localhost:9093 來訪問 Alertmanager,在這個頁面你將看到觸發的告警,如果所有的配置正確并正常啟動,一兩分鐘后就會收到郵件告警通知,
總結
這個prometheus由exporter、prometheus server、Alertmanager構成,
exporter收集資料,prometheus server 拉取exporter資料,然后根據告警規則,將告警推送到Alertmanager處理,
中間還衍生了許多其他組件,例如pushgateway(客戶端將資料push到pushgateway,由prometheus定期拉取),grafana圖示頁面等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/235675.html
標籤:其他