一、JDK1.7ConcurrentHashMap介紹
JDK1.7中ConcurrentHashMap底層是Segment陣列,每一個Segment物件中包含一個HashEntry陣列,保存的元素會封裝成HashEntry物件,當遇到Hash沖突時,會形成鏈表
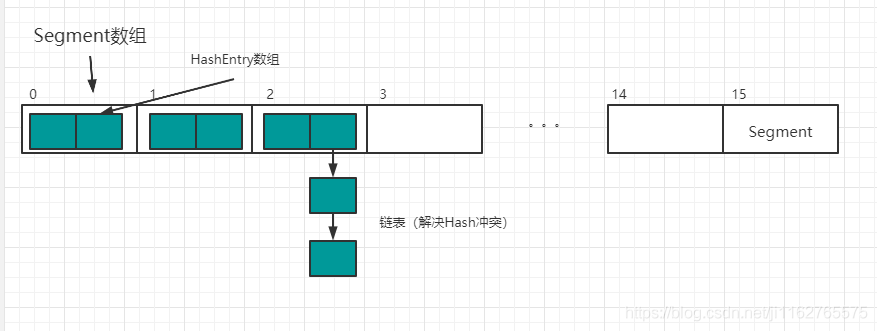
Segment繼承ReentrantLock,當需要控制執行緒安全時,對單獨的Segment進行加鎖,即分段鎖,
幾個默認值
- DEFAULT_INITIAL_CAPACITY 默認初始化容量 16
- MAXIMUM_CAPACITY 最大容量 2的30次冪
- DEFAULT_LOAD_FACTOR 默認的負載因子 0.75
- DEFAULT_CONCURRENCY_LEVEL 并發等級 16
二:構造器
// 空參構造,呼叫多載的構造方法
public ConcurrentHashMap() {
//呼叫本類的帶參構造
//DEFAULT_INITIAL_CAPACITY = 16
//DEFAULT_LOAD_FACTOR = 0.75f
//int DEFAULT_CONCURRENCY_LEVEL = 16
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
// 指定陣列初始化長度
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
// 指定陣列初始化長度與默認負載因子
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
// 所有引數全部指定
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
// 做一些資料判斷
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0; // 移動的位數,用于后續計算高4位的值
int ssize = 1; // Segment陣列的大小
while (ssize < concurrencyLevel) {
++sshift;
// 保證Segment大小為2的次冪,如指定concurrencyLevel 為15則 ssize為16,指定concurrencyLevel為17 則ssize為32
ssize <<= 1;
}
// 這兩個值用于后面計算Segment[]的角標
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
// 計算每個Segment中存盤的元素個數
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 每個Segment最少存盤2個HashEntry物件
int cap = MIN_SEGMENT_TABLE_CAPACITY;
// 保證Segment中存盤的HashEntry個數是2的次冪
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 創建一個Segment物件,作為模板,后續創建Segment物件時,屬性值直接復用,不再重新計算
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
// 創建出底層的Segment陣列
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 使用Unsafe類,將創建的Segment物件放入陣列下標為0的位置
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
// 根據已有的Map去構造
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
默認情況:在new一個ConcurrentHashMap時,底層創建了一個長度為16的Segment陣列,每個Segment中保存了一個長度為2的HshEntry陣列,之后保存的資料都是在HashEntry中,ConcurrentHashMap中默認元素長度為32,而不是16,
三:put方法
/**
* 保存/修改方法,可能會涉及到擴容
* 不允許存盤Null鍵和Null值
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
// 值不可以為Null
throw new NullPointerException();
// 基于key,計算hash值,計算hash值時,key若為Null會報空指標例外
int hash = hash(key);
// 取高位計算要保存的Segment陣列的下標(HashEntry陣列用的低位計算下標)
int j = (hash >>> segmentShift) & segmentMask;
// 如果該位置沒有Segment物件,則創建一個Segment物件
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 呼叫Segmetn的put方法實作元素添加
return s.put(key, hash, value, false);
}
/**
* 回傳對應索引k位置的Segment物件,沒有則使用索引位置0的Segment物件創建一個
* 這里沒有使用鎖機制,僅依靠Unsafe類進行操作
*/
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
// k索引位置對應的偏移量
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 如果陣列ss索引k的位置對應的Segment物件為null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 使用構造器初始化時生成的Segment物件作為原型
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
// 再次確認在此程序中其他執行緒沒有將該Segment物件創建出來
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS將新建的Segment物件放置在陣列的該位置中,如果放置成功,則break回傳,如果失敗再判斷其余執行緒有沒有放置成功,回圈此操作
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
/**
* Segment物件的put方法,加鎖,然后保存值
*/
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 嘗試加鎖,獲取到鎖則繼續,獲取不到則呼叫scanAndLockForPut方法獲取鎖
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 獲取HashEntry陣列的下標,這里用低位
int index = (tab.length - 1) & hash;
// 獲取陣列tab對應下標index的值,有可能為0
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
// 獲取的元素不為空
if (e != null) {
K k;
// 如果重復,覆寫
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
// 不重復,獲取鏈表的下一個元素
e = e.next;
}
else {
if (node != null)
// 如果node在等待鎖的時候已經創建出來,則采用頭插法直接插入即可
node.setNext(first);
else
// 創建一個新的HashEntry,next屬性指向first(頭插法)
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
// 如果超過擴容閾值,進行擴容,再將node插入
rehash(node);
else
// 不擴容,直接放到Entry陣列中
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 釋放鎖
unlock();
}
return oldValue;
}
/**
* 使用Unsafe將元素e放到陣列tab的下標i位置處
*/
static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i,
HashEntry<K,V> e) {
UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e);
}
總結一下put流程:
- 首先判斷不允許null值和null鍵
- 計算hash值,通過hash值的高位計算出要保存的Segment陣列下標
- 判斷Segment陣列該下標位置是否有值,如果沒有值,使用Unsafe類并自旋且使用Segment陣列下標0位置的原型去創建一個Segment物件,創建物件時要判斷其他執行緒有沒有將此物件創建出來,如果獲取到了其他執行緒創建的Segment物件,則將該物件回傳
- 呼叫Segment物件的put方法去保存值
- 保存值時,首先嘗試獲得該Segment物件的鎖,獲取不到則自旋不停嘗試獲取鎖,在此程序中會將要保存的值封裝成一個HashEntry物件,節省之后的時間,如果自旋重試一定次數(64/1)后,不再自旋,強制加鎖,阻塞等待鎖
- 獲取鎖以后,先計算該值應該保存在Segment的HashEntry陣列的哪一個位置,采用低位進行計算
- 獲取HashEntry陣列對應下標的值,記為first
- 遍歷該位置的鏈表,如果first為null或者遍歷完都不重復,則插入(頭插法),插入時,如果在自旋獲取鎖時已經創建好HashEntry物件,直接使用,未創建好則去創建,如果在遍歷鏈表程序中,找到重復的元素,進行替換,
- 在插入程序中,先判斷是否需要擴容,需要擴容則進行擴容,擴容完將該元素插入到新陣列中,不需要擴容則將此元素放到頭結點,
- 最終釋放鎖
四:resize()擴容
擴容只針對加鎖的單個Segment的HashEntry陣列進行擴容,HashEntry陣列大小變成2倍,但僅局限于當前的Segment,其余Segment中的HashEntry陣列大小不會變化,另外,Segment陣列大小在初始化以后也不會發生變化,
/**
* 擴容方法,擴容2倍,將
*/
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 擴容2倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// 創建一個新的HashEntry陣列
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
// 進行資料遷移,將舊陣列上面的
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 計算新陣列的下標
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// 該位置只有一個元素,直接放過去
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
// lastRun機制,對資料轉移進行了一點優化,獲取該位置最后計算出在新陣列位置連續的元素,整體轉移到新陣列中去
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
// 轉移剩余的元素,從原陣列的頭結點開始,到原陣列的lastRun結點
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 將新的元素采用頭插法插入到新陣列中
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// 將新陣列賦值給Segment物件的HashEntry陣列屬性
table = newTable;
}
resize()方法總結:
- 因為是在put方法中,已經獲取到lock,所以可以確保執行緒安全
- 擴容時首先生成一個新的陣列,大小為原陣列的2倍
- 將原陣列的元素遷移到新陣列中,遍歷原HashEntry陣列,獲取到每一個位置的HashEntry鏈表
- 計算原資料應該轉移到新陣列的下標,如果原HashEntry鏈表只有一個元素,直接轉移到新鏈表
- 如果有多個,采用lastRun機制,先獲取最后幾個在新陣列連續的元素,先轉移過去
- 之后遍歷剩余的鏈表,根據原HashEntry元素生成新的HashEntry物件,并采用頭插法放到新陣列中
- 資料轉移完之后,將新的元素再計算下標之后,頭插法放到新陣列中
- 將新陣列更新到Segment物件中
六:get方法
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
// 如果key為null,在這一步會拋例外
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 獲取Segment陣列對應下標的Segment物件以及該Segment物件的HashEntry陣列,并且兩者都不為空
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 獲取HashEntry陣列對應下標的鏈表,遍歷獲取值
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
get方法總結:
- 先計算獲取該key對應哪一個Segment物件(key若為null,則空指標)
- 再計算該key對應Segment物件的哪一個HashEntry鏈表
- 遍歷鏈表獲取值
- 這幾步有任一步驟獲取不到值,回傳null,
七:size方法
/**
* 獲取ConcurrentHashMap的大小
* 先計算兩遍,看一下兩遍計算的值是否相等,若相等則回傳
* 若兩次計算結果不一致,則再計算一遍并比較
* 若再次計算以后結果與上一次計算結果還不一致,則加鎖計算
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
// 先比較再自加,RETRIES_BEFORE_LOCK為2
// -1 0 1 共回圈三次
if (retries++ == RETRIES_BEFORE_LOCK) {
// 對每一個Segment進行加鎖
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
// 計算每一個segment的count之和
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果連續兩次計算值一致,則回傳
if (sum == last)
break;
// 修改次數之和不一致,將此次計算結果記為last,再計算一遍
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
// 如果已經加鎖,則釋放鎖
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
size方法總結:
- 因為在計算ConcurrentHashMap的size時,有可能會并發插入/洗掉資料
- 首先不加鎖,計算兩次所有Segment物件的modCount之和,判斷是否一致,如果不一致再回圈計算一次
- 如果再回圈一次計算的和與之前計算還不一致,就加鎖進行計算,這里加鎖前最多計算三次,
結語:還在學習程序中,做一個學習記錄,如有不對的地方,歡迎批評指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236030.html
標籤:其他