1 HDFS的shell客戶端
[root@linux01 ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
hdfs dfs -ls /
hdfs dfs -put /a.sh /data/
hdfs dfs -get /data/a.sh /doit20/
hdfs dfs -cat /a.sh
hdfs dfs -tail /a.sh
hdfs dfs -head /a.sh
hdfs dfs -chmod -R 777 /data
hdfs dfs -mv
hdfs dfs -cp
hdfs dfs -mkdir -p
hdfs dfs -rm -r
hdfs dfs -rmdir
hdfs dfs -df -h
hdfs dfs -du -h
hdfs dfs -find /data/ -name a.sh
2 HDFS的java客戶端
1 maven專案
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<!--專案需要的jar包 mysql fastjson...-->
<dependencies>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!--添加hdfs的客戶端依賴-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
</project>2 編程
2.1 入門程式
package cn._51doit.day02.hdfs.client;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.net.URISyntaxException;
/**
* FileName: Demo1
* Author: 多易教育-DOIT
* Date: 2020/12/16 0016
* Description:使用java操作HDFS分布式檔案系統
*/
public class Demo1 {
public static void main(String[] args) throws Exception {
// 1 配置資訊物件 用于用戶自定義設定 比如副本個數 物理切塊
Configuration conf = new Configuration();
// 2 獲取HDFS 的客戶端物件
/**
* newInstance獲取檔案系統
* 引數一 URI namenode的位置 HDFS的位置
* URL http://linux01:8080/html/login.html
* jdbc:mysql://localhost:3306/db_dmeo1
* hdfs://linux01:8020
* 引數二 配置物件
* 引數三 用戶名
*/
FileSystem fs = FileSystem.newInstance(new URI("hdfs://linux01:8020"), conf, "root");
// 操作HDFS 系統 ls put get mv rm cat
// 將windows中的檔案上傳到HDFS 中
/**
* 引數一 本地路徑
* 引數二 HDFS 的路徑
*/
fs.copyFromLocalFile(new Path("d://word.txt"),new Path("/"));
fs.close();
}
}
2.2 上傳下載
/**
* 獲取HDFS客戶端
* hdfs://linux01:8020
* @return
* @throws Exception
*/
public static FileSystem getHdfsFs() throws Exception {
Configuration conf = new Configuration();
return FileSystem.newInstance(new URI("hdfs://linux01:8020"),conf , "root");
} /**
* 下載
* @throws Exception
*/
private static void get() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
/**
* 注意:************ 下載API需要windows本地配置HDP環境變數 且生效
* 引數一 是否洗掉待下載的檔案
* 引數二 HDFS的路徑
* 引數三 本地 路徑
* 引數四 是否使用本地原生的檔案系統 *** 默認是false
* 是否使用原生的本地檔案系統 true使用windows的檔案系統來存盤存盤下載的資料 所以在本地沒有生成.word.txt.crc檔案
* 默認使用HDFS系統 ---> windows寫資料 生成校驗檔案 .a.sh.crc
*/
fs.copyToLocalFile(true , new Path("/a.sh") ,new Path("d://"),false);
fs.close();
}
/**
* 上傳
* @throws Exception
*/
private static void put() throws Exception {
//1 上傳
FileSystem fs = HdfsUtils.getHdfsFs();
/**
* 引數一 是否洗掉待上傳的檔案
* 引數二 是否覆寫HDFS中已經存在的檔案
* 引數三 待上傳檔案路徑
* 引數四 HDFS的目標路徑
*/
fs.copyFromLocalFile(true, true, new Path("d://word.txt"), new Path("/"));
fs.close();
}2.3 創建檔案夾
/**
* 創建檔案夾
*
* @throws Exception
*/
private static void mkdirs() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
//創建多級檔案夾
boolean b = fs.mkdirs(new Path("/wbb/wb/b"));
// 如果創建成功回傳true
if (b) {// 成功
// 遍歷/下所有的內容[FileStatus 包括檔案和檔案夾]
FileStatus[] statuses = fs.listStatus(new Path("/"));
for (FileStatus status : statuses) {
// 獲取檔案檔案夾 路徑
Path path = status.getPath();
// 獲取名稱
String name = path.getName();
System.out.println(name);
}
}
fs.close();
}2.4 洗掉內容
/**
* 洗掉內容
*
* @throws Exception
*/
private static void rmr() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
boolean b = fs.delete(new Path("/wbb"), true);
if (b) {
System.out.println("洗掉成功");
} else {
System.out.println("洗掉失敗");
}
fs.close();
}2.5 遍歷路徑下所有的檔案
/**
* 遍歷路徑下所有的檔案
*
* @throws Exception
*/
private static void listFiles() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
// 遞回遍歷一個路徑下所有的檔案
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/"), true);
// 遍歷檔案
while (locatedFileStatusRemoteIterator.hasNext()) {
// 獲取每個檔案
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
// 獲取每個檔案的路徑
Path path = next.getPath();
System.out.println(path);
String name = path.getName(); // 獲取每個檔案的檔案名
}
fs.close();
}
hdfs://linux01:8020/a/b/c/zk.sh hdfs://linux01:8020/a/b/zk.sh hdfs://linux01:8020/wbb.mp4
2.6 API01
/**
* 讀取資料
* @throws Exception
*/
private static void readData() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
// 8 讀取資料
FSDataInputStream ipt = fs.open(new Path("/ab.mp4"));
//wbbhefengjiede qimei aiqing gushi
/* int i = ipt.read();
int j = ipt.read();
System.out.println(j);*/
BufferedReader br = new BufferedReader(new InputStreamReader(ipt));
String line = null ;
while((line = br.readLine())!=null){
System.out.println(line);
}
ipt.close();
br.close();
fs.close();
}
/**
* 移動 重命名
* @param fs
* @throws IOException
*/
private static void mv(FileSystem fs) throws IOException {
fs.rename(new Path("/a.mp4") , new Path("/ab.mp4")) ;
}
/**
* 獲取元資料資訊
* @throws Exception
*/
private static void getFileBlockMeta() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
// 遞回遍歷一個路徑下所有的檔案
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/"), false);
// 遍歷檔案
while (locatedFileStatusRemoteIterator.hasNext()) {
// 獲取每個檔案
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
// 獲取每個檔案的路徑
Path path = next.getPath();
System.out.println(path);
String name = path.getName(); // 獲取每個檔案的檔案名
next.getBlockSize() ;//128M
next.getReplication() ;//3
// 獲取元資料資訊..
BlockLocation[] blockLocations = next.getBlockLocations();// 塊位置 a.txt 300M
for (BlockLocation blockLocation : blockLocations) {//塊 3個副本
long length = blockLocation.getLength(); // 資料塊的大小
String[] names = blockLocation.getNames();
System.out.println(Arrays.asList(names));// names
// 獲取乜咯副本所在的機器
String[] hosts = blockLocation.getHosts(); // 3
List<String> strings = Arrays.asList(hosts); // hosts
System.out.println(strings);
}
}
fs.close();
}
/**
* 遍歷路徑下所有的內容
* @throws Exception
*/
private static void listStatus() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
fileStatus.isDirectory();
if(fileStatus.isFile()){ // 檔案
// 獲取檔案資訊
fileStatus.getAccessTime() ;
fileStatus.getBlockSize();
fileStatus.getLen() ;
fileStatus.getReplication() ;
}
}
fs.close();
}
2,7 追加寫
/**
* 追加寫操作
* @throws Exception
*/
private static void writeData() throws Exception {
FileSystem fs = HdfsUtils.getHdfsFs();
FSDataOutputStream append = fs.append(new Path("/ab.mp4"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(append));
bw.write("wbb 真笨");
bw.newLine();
bw.flush();
bw.close();
fs.close();
}3 原理加強
3.1 資料存盤位置觀察
當datanode啟動以后會向namenode注冊 ,dfs.namenode.rpc-address ! namenode接收注冊 回傳一個唯一的集群ID!
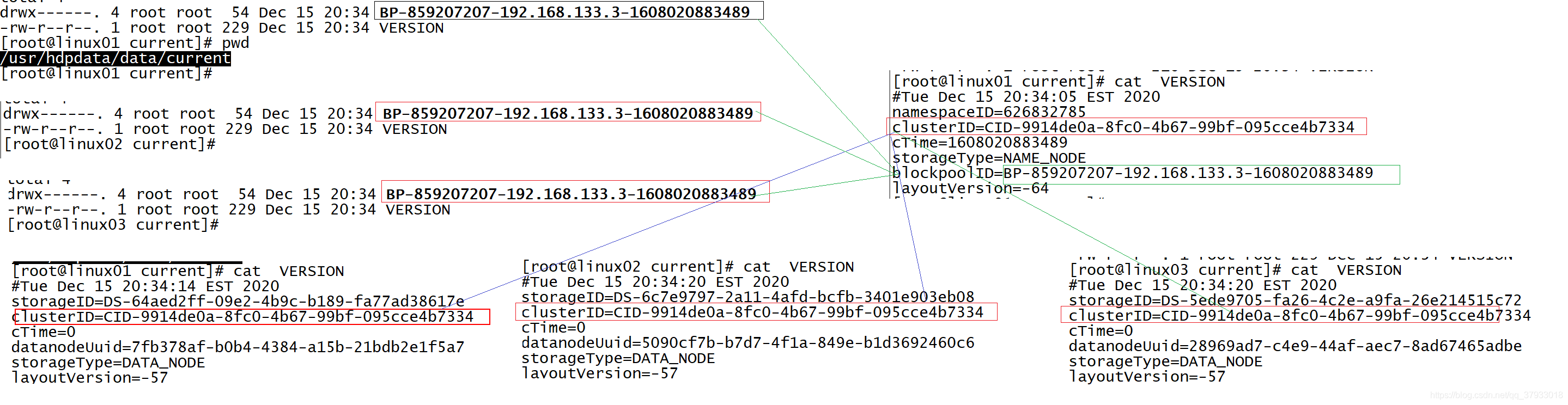
回傳一個blockpoolId, datanode將資料存盤在這個統一的目錄中!
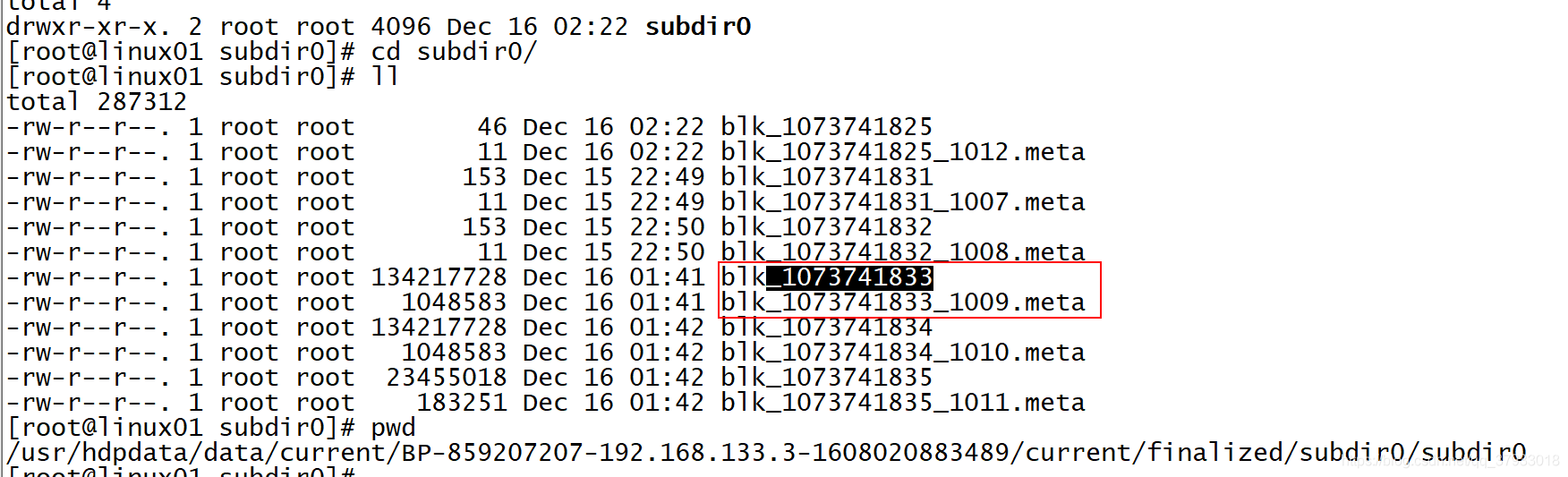
-- 資料在集群中是以128M物理切塊多副本存盤 (集群),資料塊回存盤在
每臺datanode的這個BP-859207207-192.168.133.3-1608020883489目錄下
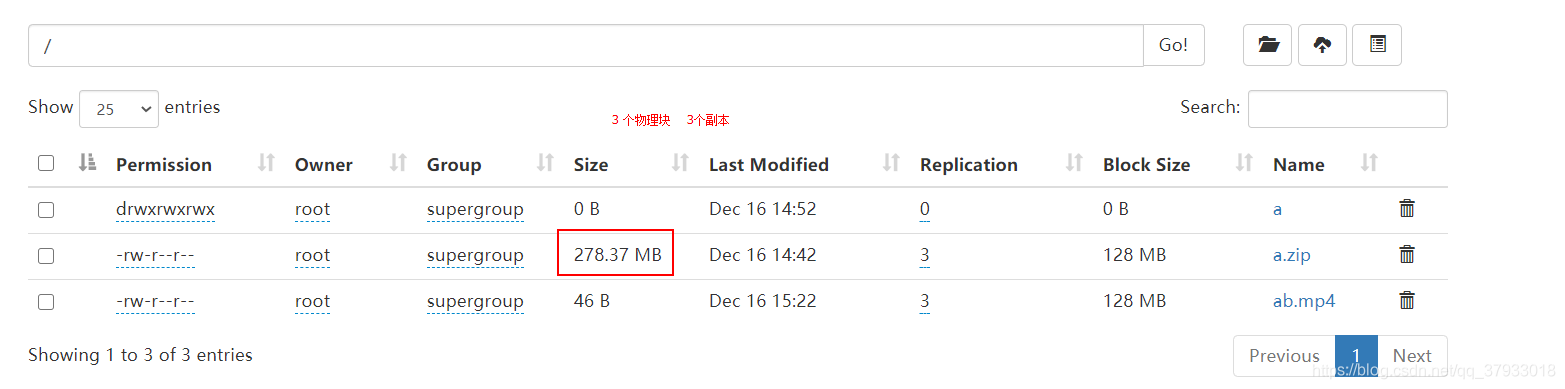
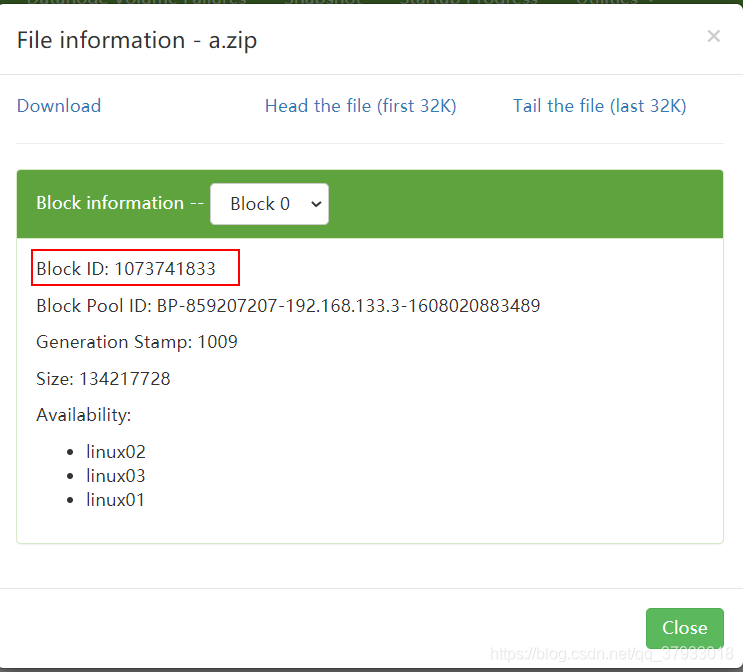
在linux01機器 linux02 linux03的目錄下有資料塊
3.2 寫資料流程(上傳)
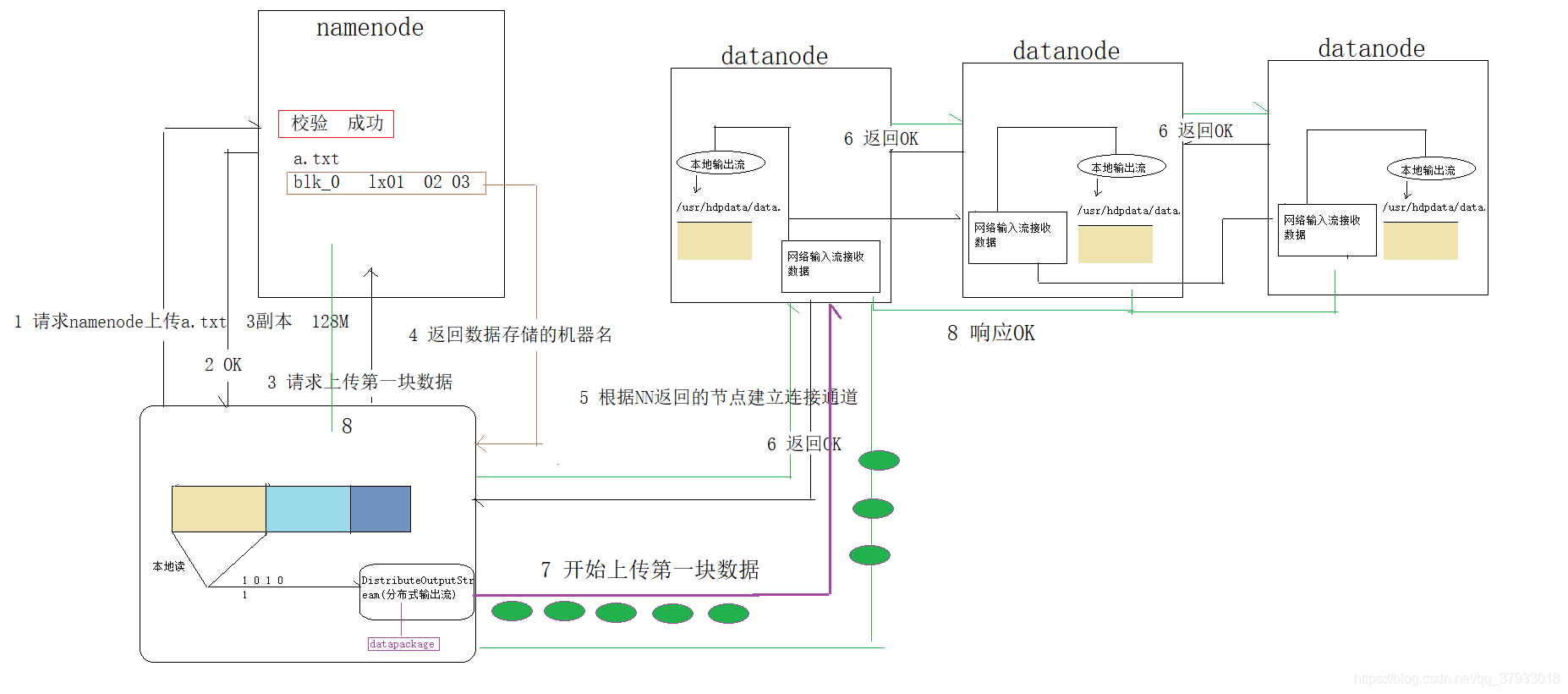
....作業
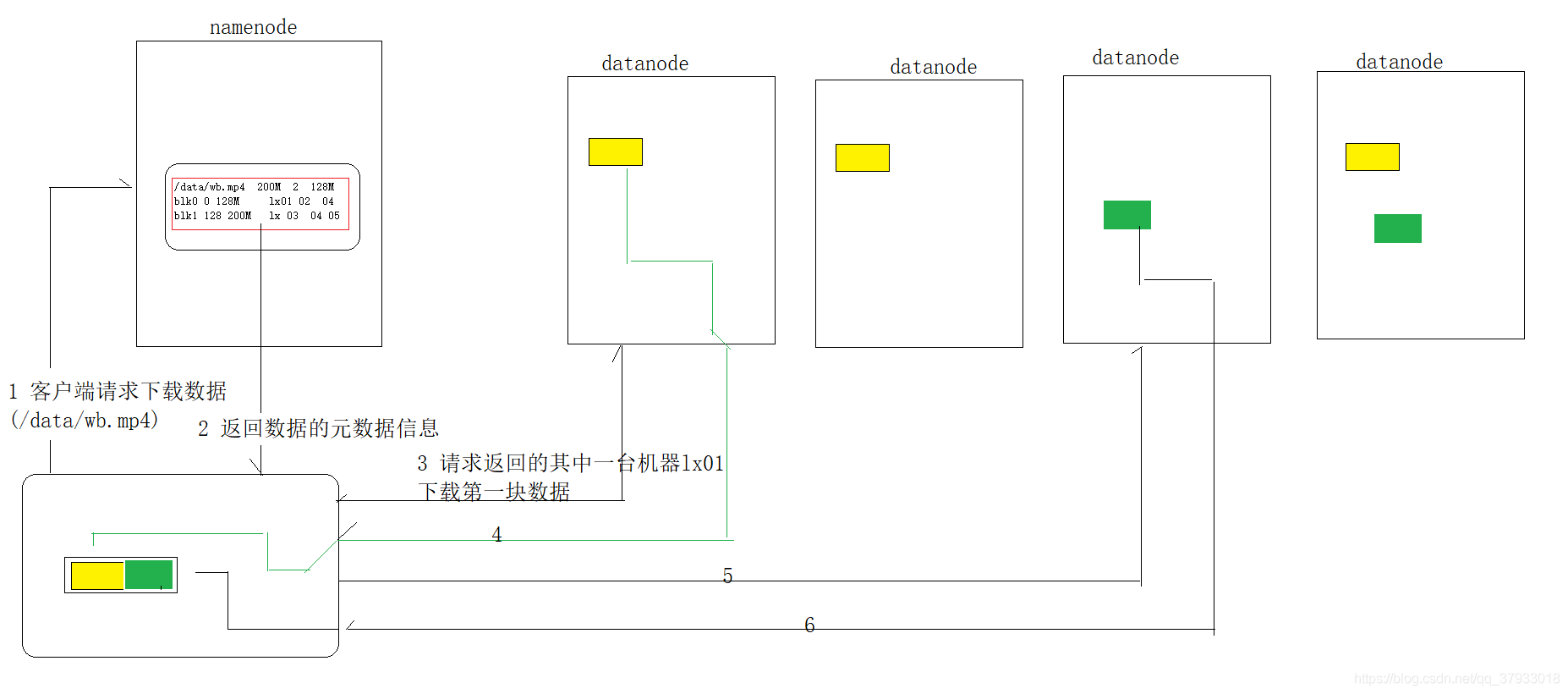
3.3 讀資料流程 (下載)
3.4 namenode和datanode通信
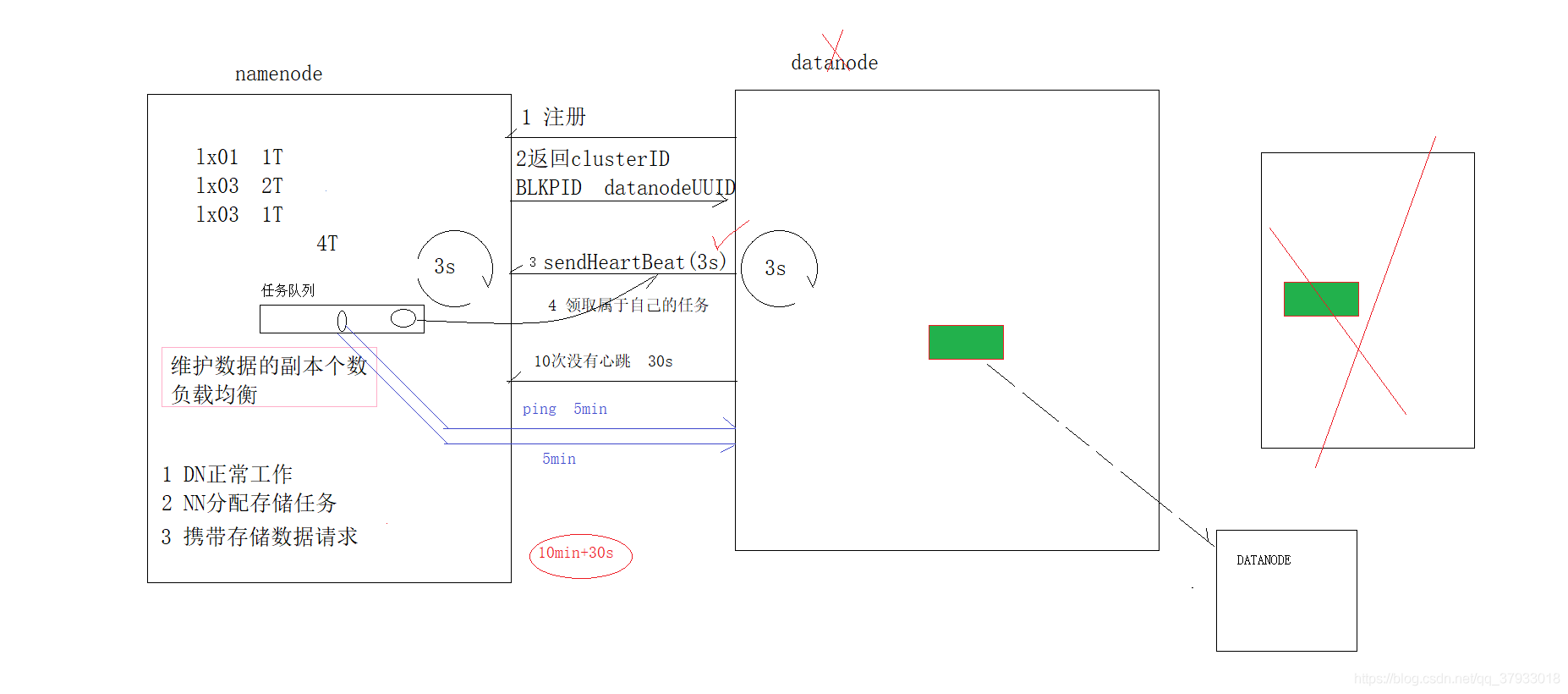
1、namenode 如何判斷datanode節點是否宕機? 先決條件: datanode每隔一段時間像namenode匯報,匯報的資訊有兩點 (1)自身datanode的狀態資訊; (2)自身datanode所持有的所有的資料塊的資訊, 如果namenode連續十次沒有收到datanode的匯報,那么namenode就會認為該datanode存在宕機的可能, datanode啟動以后會專門啟動一個行程負責給namenode發送心跳資料包,如果datanode沒有問題,僅僅只是發送資訊資料包的行程掛了,namenode會發送命令像這個datanode進行確認, 查看這個發送心跳包的行程是否還能正常運行,namenode會向datanode確認兩遍,每五分鐘確認一次,如果兩次都沒有回傳結果,那么namenode就會認為datanode已經宕機了, 最終namenode判斷一個datanode死亡的時間計算公式: timeout = 10 * 心跳間隔時間 + 2 * 檢查一次消耗的時間 心跳間隔時間 配置引數:dfs.heartbeat.interval 默認值:3s,單位s 檢查一次消耗的時間 配置引數:dfs.namenode.heartbeat.recheck-interval 默認值: 300000,單位ms 2、資料塊讀寫操作的一些配置項 (1)配置引數:dfs.blocksize 引數說明:客戶端資料分塊的大小 默認值:134217728(128M);單位:位元組 (2)dfs.client-write-packet-size 引數說明:客戶端寫入資料時packet資料包的大小 默認值:65536(64K),單位位元組 (3)dfs.bytes-per-checksum 引數說明:chunk(寫入資料時最小的一個單位),資料校驗的粒度 默認值:512位元組 注:事實上一個chunk還包含4B的校驗值,因而chunk寫入packet時是516B;資料與檢驗值的比值為128:1,所以對于一個128M的block會有一個1M的校驗檔案與之對應; 3、集群資料損壞以后,自動洗掉時長 配置項:dfs.blockreport.intervalMsec 默認值:21600000(36分鐘),單位:ms 4、元資料checkPount 在分布式或者偽分布集群中,每隔一段時間,會由 secondary namenode 將 namenode 上積累的所有 edits 和一個最新的 fsimage 下載到本地,并加載到記憶體進行 merge(這個程序稱為 checkpoint) dfs.namenode.checkpoint.check.period=60 ##檢查觸發條件是否滿足的頻率,60 秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary ##以上兩個引數做 checkpoint 操作時,secondary namenode 的本地作業目錄 dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 ##最大重試次數 dfs.namenode.checkpoint.period=3600 ##兩次 checkpoint 之間的時間間隔 3600 秒 dfs.namenode.checkpoint.txns=1000000 ##兩次 checkpoint 之間最大的操作記錄 5、jvm重用 配置引數:mapred.job.reuse.jvm.num.tasks 引數解釋:一個jvm內部跑多少個task,默認是1,可以設定為多個,這個引數在2.9.2版本中未找到,
3.5 namenode和datanode角色總結
3.6 元資料管理機制
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236050.html
標籤:其他
上一篇:【MATLAB統計分析與應用100例】案例014:matlab讀取Excel資料,呼叫stepwise函式作互動式逐步回歸分析