計算機視覺入門系列(一) 綜述
自大二下學期以來,學習計算機視覺及機器學習方面的各種課程和論文,也親身參與了一些專案,回想起來求學程序中難免走了不少彎路和坎坷,至今方才敢說堪堪入門,因此準備寫一個計算機視覺方面的入門文章,一來是時間長了以后為了鞏固和溫習一下所學,另一方面也希望能給新入門的同學們介紹一些經驗,還有自然是希望各位牛人能夠批評指正不吝賜教,由于臨近大四畢業,更新的時間難以保證,這個系列除了在理論上面會有一些介紹以外,也會提供幾個小專案進行實踐,我會盡可能不斷更新下去,
因諸多學術理論及概念的原始論文都發表在英文期刊上,因此在盡可能將專業術語翻譯成中文的情況下,都會在括號內保留其原始的英文短語以供參考,
目錄
- 簡介
- 方向
- 熱點
簡介
計算機視覺(Computer Vision)又稱為機器視覺(Machine Vision),顧名思義是一門“教”會計算機如何去“看”世界的學科,在機器學習大熱的前景之下,計算機視覺與自然語言處理(Natural Language Process, NLP)及語音識別(Speech Recognition)并列為機器學習方向的三大熱點方向,而計算機視覺也由諸如梯度方向直方圖(Histogram of Gradient, HOG)以及尺度不變特征變換(Scale-Invariant Feature Transform, SIFT)等傳統的手辦特征(Hand-Crafted Feature)與淺層模型的組合逐漸轉向了以卷積神經網路(Convolutional Neural Network, CNN)為代表的深度學習模型,
| 方式 | 特征提取 | 決策模型 |
|---|---|---|
| 傳統方式 | SIFT,HOG, Raw Pixel … | SVM, Random Forest, Linear Regression … |
| 深度學習 | CNN … | CNN … |
svm(Support Vector Machine) : 支持向量機
Random Forest : 隨機森林
Linear Regression : 線性回歸
Raw Pixel : 原始像素
傳統的計算機視覺對待問題的解決方案基本上都是遵循: 影像預處理 → 提取特征 → 建立模型(分類器/回歸器) → 輸出 的流程, 而在深度學習中,大多問題都會采用端到端(End to End)的解決思路,即從輸入到輸出一氣呵成,本次計算機視覺的入門系列,將會從淺層學習入手,由淺入深過渡到深度學習方面,
方向
計算機視覺本身又包括了諸多不同的研究方向,比較基礎和熱門的幾個方向主要包括了:物體識別和檢測(Object Detection),語意分割(Semantic Segmentation),運動和跟蹤(Motion & Tracking),三維重建(3D Reconstruction),視覺問答(Visual Question & Answering),動作識別(Action Recognition)等,
物體識別和檢測
物體檢測一直是計算機視覺中非常基礎且重要的一個研究方向,大多數新的演算法或深度學習網路結構都首先在物體檢測中得以應用如VGG-net, GoogLeNet, ResNet等等,每年在imagenet資料集上面都不斷有新的演算法涌現,一次次突破歷史,創下新的記錄,而這些新的演算法或網路結構很快就會成為這一年的熱點,并被改進應用到計算機視覺中的其它應用中去,可以說很多灌水的文章也應運而生,
物體識別和檢測,顧名思義,即給定一張輸入圖片,演算法能夠自動找出圖片中的常見物體,并將其所屬類別及位置輸出出來,當然也就衍生出了諸如人臉檢測(Face Detection),車輛檢測(Viechle Detection)等細分類的檢測演算法,
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-6CMcHxvM-1608064947984)(https://media.licdn.com/mpr/mpr/AAEAAQAAAAAAAAi-AAAAJDhhMGQwNGY2LTRiNzYtNDcwOC04YTU1LWI4ZmQ1NDVkOTZhZg.jpg)]
####近年代表論文
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Liu, Wei, et al. “SSD: Single shot multibox detector.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
####資料集
- IMAGENET
- PASCAL VOC
- MS COCO
- Caltech
###語意分割
語意分割是近年來非常熱門的方向,簡單來說,它其實可以看做一種特殊的分類——將輸入影像的每一個像素點進行歸類,用一張圖就可以很清晰地描述出來,
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-IvNYx5fD-1608064947986)(https://researchweb.iiit.ac.in/~dineshreddy.n/zerotype/assets/sms.png)]
很清楚地就可以看出,物體檢測和識別通常是將物體在原影像上框出,可以說是“宏觀”上的物體,而語意分割是從每一個像素上進行分類,影像中的每一個像素都有屬于自己的類別,
近年代表論文
- Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062 (2014).
- Noh, Hyeonwoo, Seunghoon Hong, and Bohyung Han. “Learning deconvolution network for semantic segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Zheng, Shuai, et al. “Conditional random fields as recurrent neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
####資料集
- PASCAL VOC
- MS COCO
運動和跟蹤
跟蹤也屬于計算機視覺領域內的基礎問題之一,在近年來也得到了非常充足的發展,方法也由過去的非深度演算法跨越向了深度學習演算法,精度也越來越高,不過實時的深度學習跟蹤演算法精度一直難以提升,而精度非常高的跟蹤演算法的速度又十分之慢,因此在實際應用中也很難派上用場,
那么什么是跟蹤呢?就目前而言,學術界對待跟蹤的評判標準主要是在一段給定的視頻中,在第一幀給出被跟蹤物體的位置及尺度大小,在后續的視頻當中,跟蹤演算法需要從視頻中去尋找到被跟蹤物體的位置,并適應各類光照變換,運動模糊以及表觀的變化等,但實際上跟蹤是一個不適定問題(ill posed problem),比如跟蹤一輛車,如果從車的尾部開始跟蹤,若是車輛在行程序序中表觀發生了非常大的變化,如旋轉了180度變成了側面,那么現有的跟蹤演算法很大的可能性是跟蹤不到的,因為它們的模型大多基于第一幀的學習,雖然在隨后的跟蹤程序中也會更新,但受限于訓練樣本過少,所以難以得到一個良好的跟蹤模型,在被跟蹤物體的表觀發生巨大變化時,就難以適應了,所以,就目前而言,跟蹤算不上是計算機視覺內特別熱門的一個研究方向,很多演算法都改進自檢測或識別演算法,
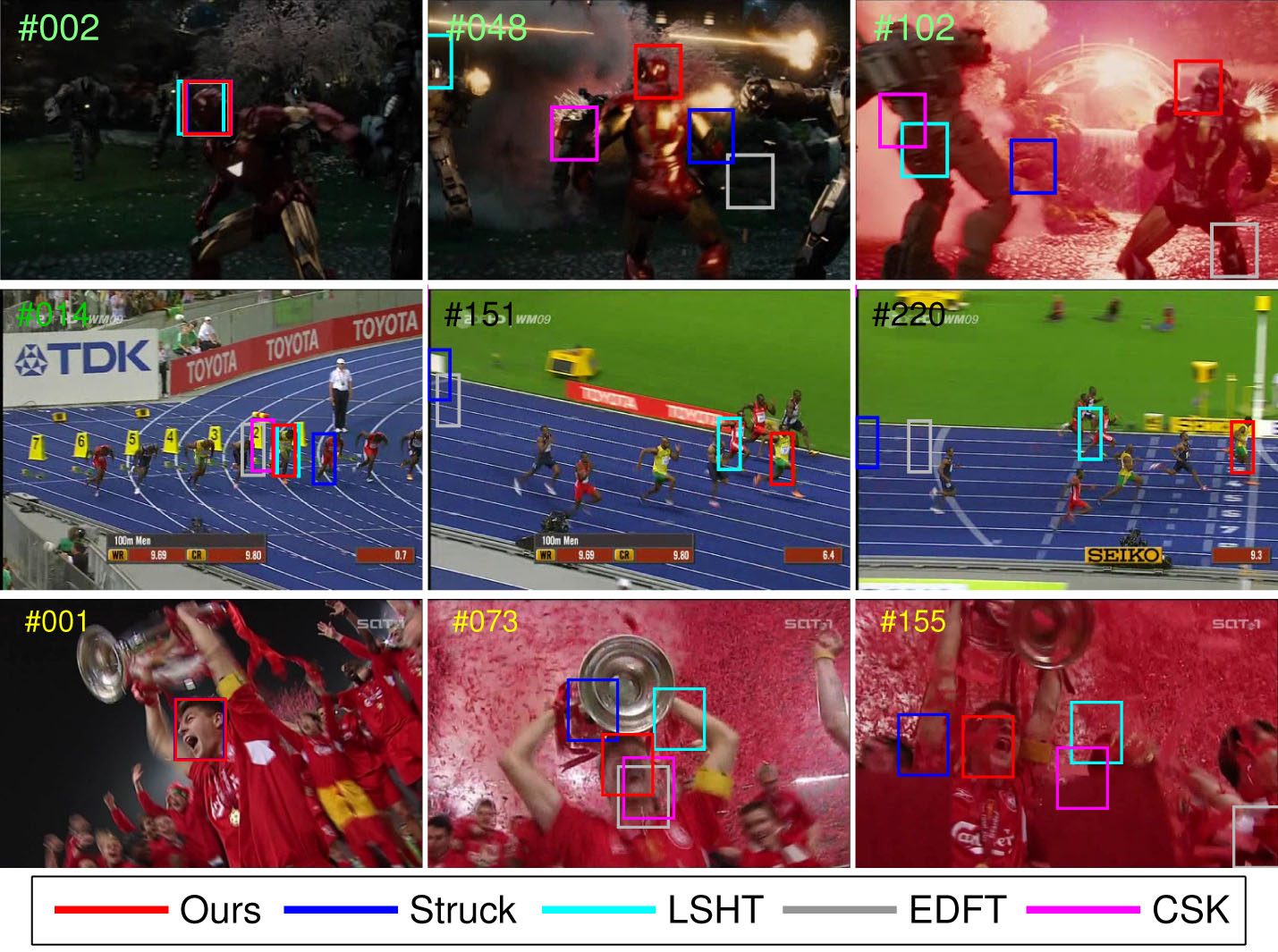
近年代表論文
- Nam, Hyeonseob, and Bohyung Han. “Learning multi-domain convolutional neural networks for visual tracking.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Held, David, Sebastian Thrun, and Silvio Savarese. “Learning to track at 100 fps with deep regression networks.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Henriques, Jo?o F., et al. “High-speed tracking with kernelized correlation filters.” IEEE Transactions on Pattern Analysis and Machine Intelligence 37.3 (2015): 583-596.
- Ma, Chao, et al. “Hierarchical convolutional features for visual tracking.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Bertinetto, Luca, et al. “Fully-convolutional siamese networks for object tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Danelljan, Martin, et al. “Beyond correlation filters: Learning continuous convolution operators for visual tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Li, Hanxi, Yi Li, and Fatih Porikli. “Deeptrack: Learning discriminative feature representations online for robust visual tracking.” IEEE Transactions on Image Processing 25.4 (2016): 1834-1848.
####資料集
- OTB(Object Tracking Benchmark)
- VOT(Visual Object Tracking)
視覺問答
視覺問答也簡稱VQA(Visual Question Answering),是近年來非常熱門的一個方向,其研究目的旨在根據輸入影像,由用戶進行提問,而演算法自動根據提問內容進行回答,除了問答以外,還有一種演算法被稱為標題生成演算法(Caption Generation),即計算機根據影像自動生成一段描述該影像的文本,而不進行問答,對于這類跨越兩種資料形態(如文本和影像)的演算法,有時候也可以稱之為多模態,或跨模態問題,

近年代表論文
- Xiong, Caiming, Stephen Merity, and Richard Socher. “Dynamic memory networks for visual and textual question answering.” arXiv 1603 (2016).
- Wu, Qi, et al. “Ask me anything: Free-form visual question answering based on knowledge from external sources.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Zhu, Yuke, et al. “Visual7w: Grounded question answering in images.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
####資料集
- VQA
熱點
隨著深度學習的大舉侵入,現在幾乎所有人工智能方向的研究論文幾乎都被深度學習占領了,傳統方法已經很難見到了,有時候在深度網路上改進一個非常小的地方,就可以發一篇還不錯的論文,并且,隨著深度學習的發展,很多領域的現有資料集內的記錄都在不斷重繪,已經向人類記錄步步緊逼,有的方面甚至已經超越了人類的識別能力,那么,下一步的研究熱點到底會在什么方向呢?就我個人的一些觀點如下:
- 多模態研究: 目前的許多領域還是僅僅停留在單一的模態上,如單一分物體檢測,物體識別等,而眾所周知的是現實世界就是有多模態資料構成的,語音,影像,文字等等, VQA 在近年來興起的趨勢可見,未來幾年內,多模態的研究方向還是比較有前景的,如語音和影像結合,影像和文字結合,文字和語音結合等等,
- 資料生成: 現在機器學習領域的許多資料還是由現實世界拍攝的視頻及圖片經過人工標注后用作于訓練或測驗資料的,標注人員的職業素養和經驗,以及多人標注下的規則統一難度在一定程度上也直接影響了模型的最終結果,而利用深度模型自動生成資料已經成為了一個新的研究熱點方向,如何使用演算法來自動生成資料相信在未來一段時間內都是不錯的研究熱點,
- 無監督學習:人腦的在學習程序中有許多時間都是無監督(Un-supervised Learning)的,而現有的演算法無論是檢測也好識別也好,在訓練上都是依賴于人工標注的有監督(Supervised Learning),如何將機器學習從有監督學習轉變向無監督學習,應該是一個比較有挑戰性的研究方向,當然這里的無監督學習當然不是指簡單的如聚類演算法(Clustering)這樣的無監督演算法,而LeCun也曾說: 如果將人工智能比喻作一塊蛋糕的話,有監督學習只能算是蛋糕上的糖霜,而增強學習(Reinforce Learning)則是蛋糕上的櫻桃,無監督學習才是真正蛋糕的本體,
最后,想要把握領域內最新的研究成果和動態,還需要多看論文,多寫代碼,
計算機視覺領域內的三大頂級會議有:
Conference on Computer Vision and Pattern Recognition (CVPR)
International Conference on Computer Vision (ICCV)
European Conference on Computer Vision (ECCV)
較好的會議有以下幾個:
The British Machine Vision Conference (BMVC)
International Conference on Image Processing (ICIP)
Winter Conference on Applications of Computer Vision (WACV)
Asian Conference on Computer Vision (ACCV)
當然,畢竟文章的發表需要歷經審稿和出版的階段,因此當會議論文集出版的時候很可能已經過了小半年了,如果想要了解最新的研究,建議每天都上ArXiv的cv板塊看看,ArXiv上都是預出版的文章,并不一定最侄訓被各類會議和期刊接收,所以質量也就良莠不齊,對于沒有分辨能力的入門新手而言,還是建議從頂會和頂級期刊上的經典論文入手,
這是一篇對計算機視覺目前研究領域的幾個熱門方向的一個非常非常簡單的介紹,希望能對想要入坑計算機視覺方向的同學有一定的幫助,由于個人水平十分有限,錯誤在所難免,歡迎大家對文中的錯誤進行批評和指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236072.html
標籤:其他
下一篇:Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation