1.創建資料庫
CREATE DATABASE database_name
2.洗掉資料庫
DROP DATABASE database_name
3.選擇資料庫
USE database_name
4.資料型別
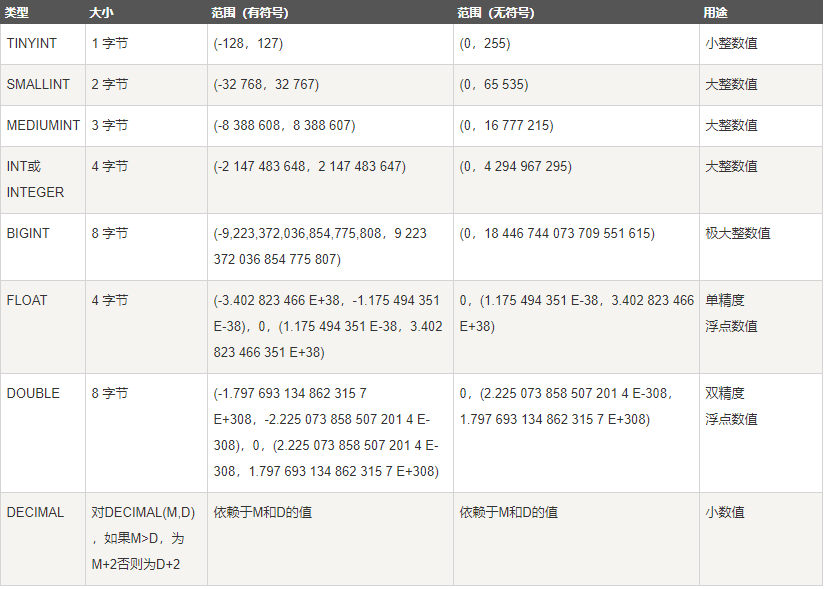
(1)數值型別
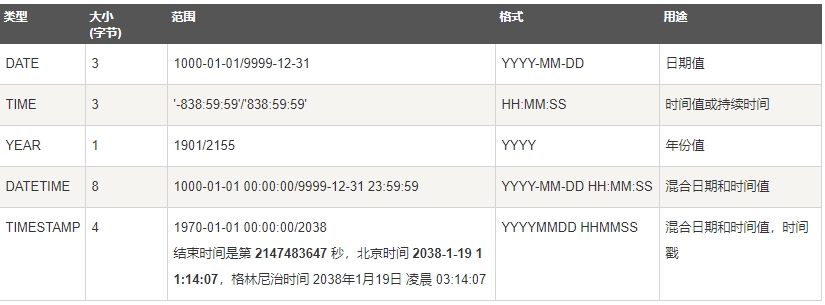
(2)日期和時間型別
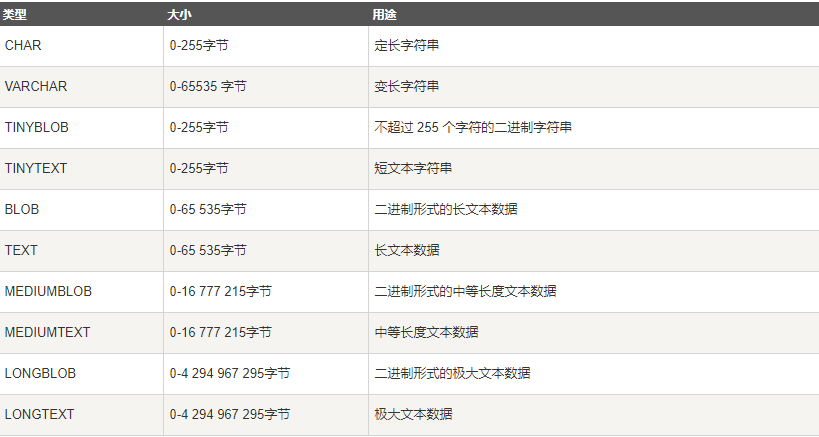
(3)字串型別
5.創建資料表
CREATE TABLE table_name (column_name column_type)
6.洗掉資料表
DROP TABLE table_name
7.更新資料表資訊
(1)添加表欄位
ALTER TABLE table_name ADD new_column DATATYPE
使用FIRST關鍵字可以將新增列的順序調整至資料表的第一列
ALTER TABLE table_name ADD new_column DATATYPE FIRST
使用AFTER關鍵字可以將新增列調整至資料表的指定列之后
ALTER TABLE table_name ADD new_column DATATYPE AFTER old_column
(2)洗掉表欄位
ALTER TABLE table_name DROP old_column
(3)修改表欄位型別
ALTER TABLE table_name MODIFY column_name NEW_DATATYPE
(4)修改欄位名稱
ALTER TABLE table_name CHANGE old_column_name new_column_name DATATYPE
8.插入資料
INSERT INTO table_name (column1, column2,column3...columnN)
VALUES
(value1, value2, value3...valueN);
9.查詢資料
SELECT column1, column2, column3...columnN FROM table_name
(1)使用*可以替代欄位名,SELECT陳述句會回傳表的所有欄位
例:SELECT * FROM table_name
(2)可以使用WHERE陳述句來包含任何條件
例:SELECT * FROM table_name WHERE column=1
(3)可以使用LIMIT屬性設定回傳的記錄數
例:回傳查詢結果的前三條記錄
SELECT * FROM table_name LIMIT 3
例:回傳查詢結果的第三條記錄
SELECT * FROM table_name LIMIT 2,1 (2指的是第幾條資料(從0開始計數),1指的是從2開始回傳幾條資料)
(4)可以使用OFFSET指定開始查詢的偏移量,默認情況下偏移量為0
例:SELECT * FROM table_name LIMIT 2 OFFSET 3 等于 SELECT * FROM table_name LIMIT 2,3
10.更新資料
UPDATE table_name SET column1=value1, column2=value2
WHERE condition
11.洗掉資料
DELECE FROM table_name
WHERE condition
12.LIKE子句
LIKE子句中使用%號來表示任意字符,其的效果類似正則運算式中的*,如果沒有使用%,那么LIKE的效果等價于=
SELECT * FROM table_name
WHERE column1 LIKE %condtion%
13.UNION
SELECT column1, column2, column3...columnN FROM table_a
[WHERE condition]
UNION [ALL | DISTINCT]
SELECT column1, column2, column3...columnN FROM table_b
[WHERE condition]
UNION的作用的連接兩個查詢結果集
DISTINCT的作用是對兩個結果集進行去重處理,默認情況下已經是DISTINCT的結果了
ALL的作用的不對兩個結果集進行去重處理
14.ORDER BY
SELECT * FROM table_name
ORDER BY column1 [ASC | DESC]
ASC:將結果集按column1升序排列,默認情況下使用升序排序
DESC:將結果集按column1降序排列
15.GROUP BY
把資料按照指定列(可以是一列或者多列)進行分組,通常和計算函式COUNT()還有SUM(),AVG()等求值函式一起使用
例:根據column1將資料進行分組,并且統計每種資料的記錄數
SELECT column1, COUNT(*) FROM table_name
GROUP BY column1
WITH ROLLUP可以將GROUP BY的統計結果集基礎上再做相同的統計(SUM,AVG....)
例:假設有下面這樣一張表 name=姓名,website=網站,access_count=訪問記錄
| name | website | access_count |
| 張三 | 百度 | 3 |
| 李四 | 新浪 | 5 |
| 王五 | 淘寶 | 4 |
| 張三 | 新浪 | 2 |
| 李四 | 百度 | 1 |
| 王五 | 搜狐 | 4 |
| 趙六 | 搜狐 | 5 |
執行如下代碼:
SELECT name, SUM(access_count) FROM table_name
GROUP BY name WITH ROLLUP
得到:
| name | SUM(access_count) |
| 張三 | 5 |
| 李四 | 6 |
| 王五 | 8 |
| 趙六 | 5 |
| NULL | 24 |
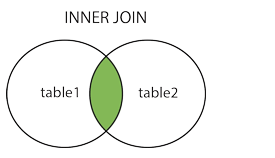
16.INNER JOIN
INNER JOIN被稱為內連接或者等值連接,獲取兩個表中欄位匹配關系的記錄
例:SELECT table1.column1, table1.column1, table2.column3 FROM table1
INNER JOIN table2
ON condition
17.LEFT JOIN
LEFT JOIN被稱為左連接,獲取左邊所有記錄,右表沒有的記錄補為NULL
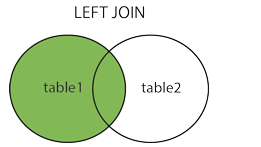
例:SELECT table1.column1, table1.column2, table2.column3 FROM table1
LEFT JOIN table2
ON condition
18.RIGHT JOIN
RIGHT JOIN被稱為右連接,獲取右邊所有資料,左表沒有的記錄補為NULL
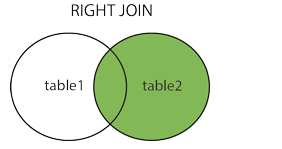
例:SELECT table1.column1, table2.column2, table2.column3 FROM table1
RIGHT JOIN table2
ON condition
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236418.html
標籤:其他