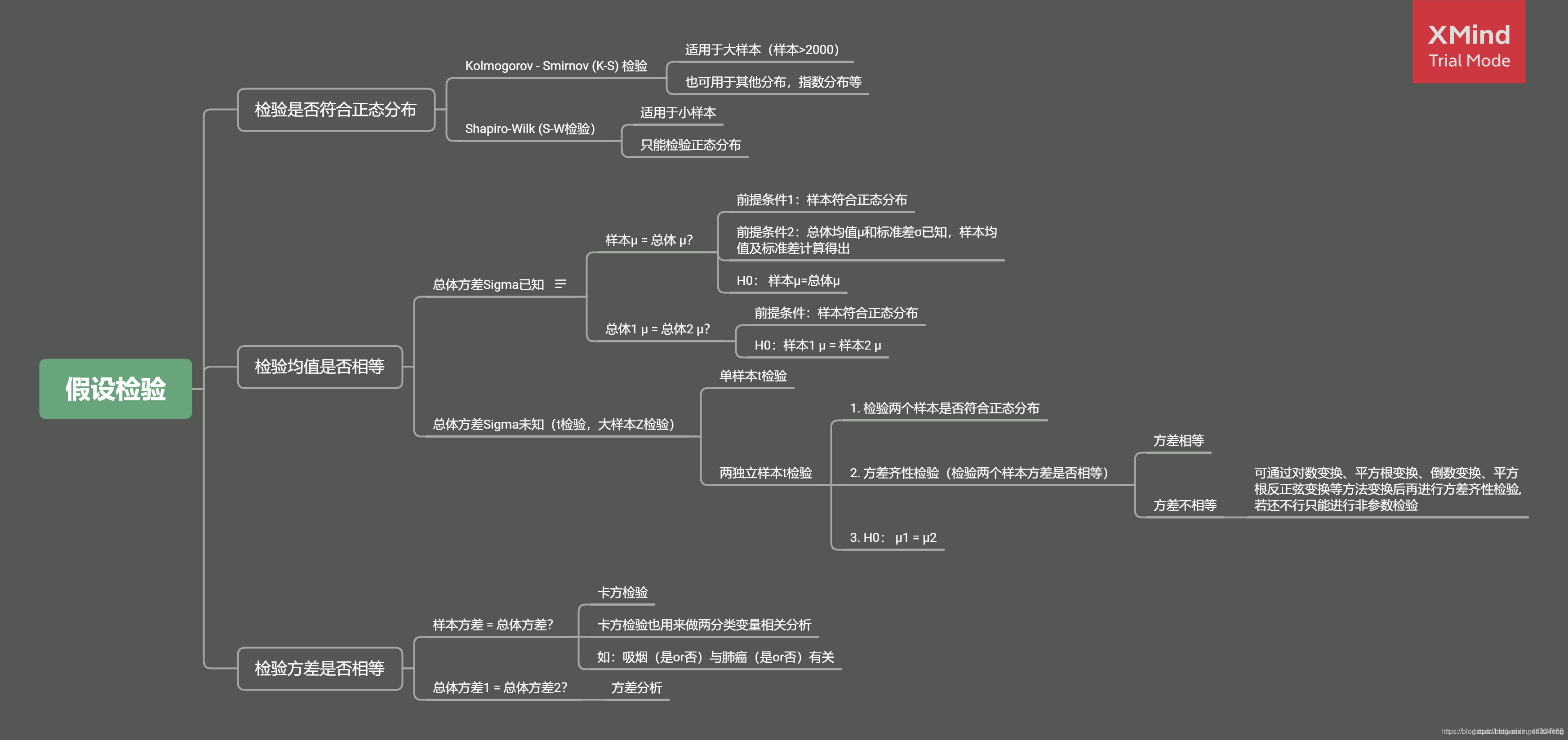
顯著性水平、置信區間、假設檢驗與方差分析相關知識點總結
- 引數說明
- 顯著性水平
- 顯著性水平檢驗
- 置信區間
- 假設檢驗
- 引數檢驗
- F檢驗
- t檢驗
- Z檢驗
- 非引數檢驗
- 卡方檢驗(?2檢驗)
- 秩和檢驗
- 常用的假設檢驗種類及使用的檢驗方法
- 方差分析
- 原理和相關術語
- 單因素方差分析
- 雙因素方差分析
引數說明
- p-value:p值,即某件事情發生的概率
- α:顯著性水平
- β:本文中一般指假設檢驗的第二類錯誤的概率
- Pr(M):置信區間
- σ2:本文中一般指總體方差
- s2:本文中一般指樣本方差
- μ:本文中一般指總體平均值
- X:本文中一般指樣本平均值
- H0:原假設,H0值等
- H1:備擇假設
- t:t檢驗、T分布、t值等
- F:F檢驗、F分布、F值等
- z:z檢驗、z分布、z值等
- ?2:卡方檢驗、卡方分布、卡方值等
- n:樣本長度
顯著性水平
顯著性水平(通常用α表示)是在進行假設檢驗時事先確定一個可允許的概率作為判斷界限的小概率標準,檢驗中,依據顯著性水平大小把概率劃分為二個區間,小于給定標準的概率區間稱為拒絕區間,大于這個標準則為接受區間,事件屬于接受區間,原假設成立而無顯著性差異;事件屬于拒絕區間,拒絕原假設而認為有顯著性差異,
通俗來講,顯著水平表示的是一個標準,即表示判斷界限的小概率標準,往往顯著性水平存在一定的人為因素,通常作為標準的小概率有0.1、0.05、0.01,有時人們也會使用顯著性水平來檢驗假設是否成立,而用到的便是小概率事件,我們一般認為p-value≤0.05就可以認為假設是不成立的,0.05這個標準就是顯著水平,當然選擇多少作為顯著水平也是主觀的,
對顯著水平的理解必須把握以下二點:
- 顯著性水平不是一個固定不變的數值,依據拒絕區間所可能承擔的風險來決定,
- 統計上所講的顯著性與實際生活作業中的顯著性是不一樣的,
顯著性水平檢驗
顯著性水平檢驗屬于假設檢驗的一種,應用的原理便是上面所說的顯著性水平的原理,首先確定一個標準(即判斷界限的小概率標準),一般取0.05(與后續的95%置信區間相對應),當某個事件的發生概率小于這個概率時,事件屬于拒絕區間,該事件具有顯著性差異,拒絕原假設,即假設不成立,
置信區間
- 置信區間是指由樣本統計量所構造的總體引數的估計區間,在統計學中,一個概率樣本的置信區間是對這個樣本的某個總體引數的區間估計,置信區間展現的是這個引數的真實值有一定概率落在測量結果的周圍的程度,其給出的是被測量引數的測量值的可信程度,即前面所要求的“一個概率”,就拿捕魚來說,一網下去,我知道里面有多少比例的魚是我想要的魚,
- 點估計與區間估計:
- 點估計:點估計是用樣本統計量來估計總體引數,因為樣本統計量為數軸上某一點值,估計的結果也以一個點的數值表示,所以稱為點估計,比如買彩票,你買了5號,那么就意味著你猜測5號一定會中獎,
- 區間估計:區間估計是在點估計的基礎上,給出總體引數估計的一個區間范圍,該區間通常由樣本統計量加減估計誤差得到,與點估計不同,進行區間估計時,根據樣本統計量的抽樣分布可以對樣本統計量與總體引數的接近程度給出一個概率度量,仍然是上面的買彩票,你覺得中獎號在5號左右,然后你買了1號到10號10張彩票,那么就意味著你猜測著1號到10張中的某一張會中獎,使用的是點估計加減估計誤差,很顯然區間估計比點估計更準確,
- 計算公式:Pr(c1<=μ<=c2)=1-α,其中α為顯著性水平,
- 95%置信區間:通常使用的較多的是95%置信區間,對應的α為0.05,一個樣本服從X~N(μ,σ2)分布,其中μ為樣本均值,σ2為樣本方差;其95%置信區間可以按照如下方式計算(公式中1.96就是α=0.05時對應的標準值):
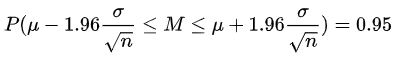
假設檢驗
- 假設檢驗:指事先對總體引數或分布形式作出某種假設,然后利用樣本資訊來判斷原假設是否成立,通常具有①采用邏輯上的反證法,②依據統計上的小概率原理等特點,
- 假設檢驗的分類:
- 引數檢驗:引數檢驗指當總體分布已知的情況下,根據樣本資料對總體分布的統計引數(如均值、方差等)進行推斷,常用的引數檢驗有t檢驗、f檢驗、Z檢驗等;
- 非引數檢驗:非引數檢驗指當總體分布未知的情況下,根據樣本資料對總體的分布形式或特征進行推斷,常用的非引數檢驗有卡方檢驗、秩和檢驗等,
- 兩類錯誤:
- 第Ⅰ類錯誤(棄真錯誤):原假設為真時拒絕原假設,第一類錯誤的概率為α(α即顯著性水平);
- 第Ⅱ類錯誤 (取偽錯誤):原假設為假時接受原假設,第二類錯誤的概率為β,
| H0是真實的 | H0是不真實的 | |
|---|---|---|
| 拒絕H0 | 第Ⅰ類錯誤(α) | 正確 |
| 接受H0 | 正確 | 第Ⅱ類錯誤( β) |
- 兩類錯誤的關系:α越大β越小,α越小β越大,因此無法同時減少兩類錯誤,通常我們都是力求控制α的情況下減小β,
- 假設檢驗的基本步驟:
- 提出原假設和備擇假設
- 確定適當的檢驗統計量
- 規定顯著性水平α
- 計算檢驗統計量的值
- 作出統計決策
- 原假設與備擇假設
- 原假設:待檢驗的假設,又稱“0假設”,表示為H0,通常在假設中包含等號如=,≤,≥等;
- 備擇假設:與原假設的對立的假設,表示為H1,通常在假設中包含不等號如≠,<,>等;
- 雙側檢驗與單側檢驗
- 雙側檢驗(雙尾檢驗):只強調差異不強調方向性(比如大小,多少)的檢驗叫雙尾檢驗,如檢驗樣本和總體均值有無差異, 或樣本數之間有沒有差異,采取雙側檢驗,雙側檢驗的相關資訊表示如下:
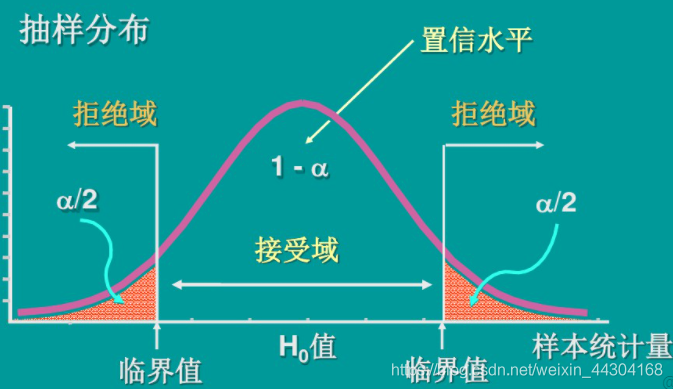
- 單側檢驗(單尾檢驗):強調某一方向的檢驗叫單尾檢驗,如當要檢驗的是樣本所取的總體引數值大于或小于某個特定值時,采用單側檢驗,單側檢驗的相關資訊表示如下:
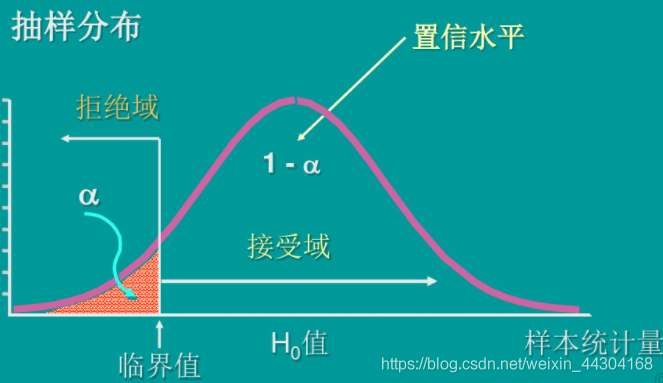
- 區別對比:
①雙側檢驗只關心兩個總體引數之間是否有差異,而不關心誰大誰小;單側檢驗則強調差異的方向性,即關心研究物件是高于還是低于某一總體水平,
②如果不清楚后測資料是否高于前測資料,研究目的是想判斷前后測的均值是否不同,就需要用雙尾檢驗;如果后測資料不可能低于前測資料,研究目的是僅僅想知道后測資料是不是高于前測資料,則可以采用單尾檢驗,
③雙側檢驗的研究假設是檢驗兩引數之間是否有差異,零假設 H0: u1= u0,備擇假設:H1:u1≠ u0;單側檢驗的研究假設中有一引數和另一引數方向性的比較,比如"大于"(或“小于”)等,
-
簡單舉例:
在某次乒乓球賽中,對手提議通過拋硬幣來決定誰先發球,“花”面朝上則對手先發球,反之則我,此時我認為這枚硬幣是不公平的,而對手卻說這枚硬幣是公平的,這時我們可通過假設檢驗來驗證這枚硬幣是否公平,假設 :這枚硬幣是公平的
檢驗 :拋十次硬幣,看是否符合假設,反復拋硬幣符合二項分布X~B(n,μ),其中n代表扔硬幣的次數,μ代表“花”朝上的概率,在硬幣是公平的前提下,扔10次硬幣應該符合以下分布:X~B(10,0.5),
總共扔了兩次,都是“花”朝上,雖然幾率是0.5x0.5 = 0.25,但是也正常,繼續扔;總共扔了四次,也都是“花”朝上,幾率是0.54=0.0625,感覺有點不正常,但是萬一是運氣呢?繼續扔;總共扔了十次,也都是“花”朝上,那我就認為很可能你這枚硬幣不是公平的,
那么當我們拋10次硬幣,當出現多少次“花”面朝上就可以認為該硬幣是不公平的,這是一個客觀的判斷,我們可結合顯著性水平檢驗來判斷,例如,我們可以計算拋10次硬幣出現9次“花”面朝上的概率來檢驗我們的假設是否成立,這一事件的概率為P(9≤X≤10)=0.01≤0.05,表示出來如下圖所示:
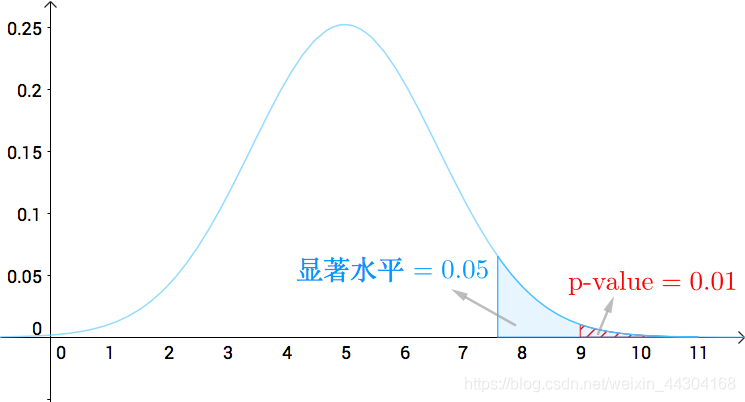
該事件屬于顯著性檢驗的拒絕區間,有顯著性差異,拒絕原假設,即該硬幣不公平,如果扔10次出現出現8次正面:P(8≤X≤10)=0.05,這個和我們的顯著水平是一樣的,我們也可以拒絕假設,只是沒有那么“顯著”了,綜上所述,當需要檢驗一枚硬幣是否公平時,可以連續拋十次,當出現八次以上的“花”面朝上就可以認為該硬幣是不公平的,
引數檢驗
引數檢驗的定義前面已介紹了,這里主要看一下幾種常用的引數檢驗,包括t檢驗、f檢驗和z檢驗,
F檢驗
- F檢驗(也稱方差比率檢驗、方差齊性檢驗)是一種在零假設之下,統計值服從F-分布的檢驗,其通常是用來分析用了超過一個引數的統計模型,以判斷該模型中的全部或一部分引數是否適合用來估計母體,F檢驗可以用于三組或者多組之間的均值比較,但是F檢驗對于資料的正態性非常敏感,如果被檢驗的資料無法滿足均是正態分布的條件時,該資料的穩健型會大打折扣,特別是當顯著性水平比較低時,但是,如果資料符合正態分布,而且α至少為0.05,該檢驗的穩健型還是相當可靠的,
- F檢驗的主要用途有①方差齊性檢驗,②方差分析,③線性回歸方程整體的顯著性檢驗,這里主要說一下第一點,方差齊性是方差分析和一些均數比較t檢驗的重要前提,利用[公式]檢驗進行方差齊性檢驗是最原始的,但對資料要求比較高,它要求樣本來自兩個獨立的、服從正態分布的總體,方差齊性檢驗的 F 值計算方法如下:

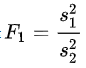
一般約定取較大的方差作為分子,較小的方差作為分母,計算出的F值與理論F值進行比較并得出結論,
t檢驗
- 主要用于樣本含量較小(通常n < 30),總體標準差σ未知的正態分布,那么此時一切可能的樣本平均數與總體平均數的離差統計量呈t分布,t檢驗是用t分布理論來推論差異發生的概率,從而比較兩個平均數的差異是否顯著,
- t檢驗有以下三種方法(選取哪種t檢驗方法是由資料特點和結果要求來決定的):
- 單一樣本T檢驗(One-Sample T Test):用來比較一組資料的平均值和一個數值有無差異,例如,你選取了5個人,測定了他們的身高,要看這五個人的身高平均值是否高于、低于還是等于1.70m,就需要用這個檢驗方法,
- 獨立樣本T檢驗(Independent-Sample T Test):用來看兩組資料的平均值有無差異,比如,你選取了5男5女,想看男女之間身高有無差異,這樣,男的一組,女的一組,這兩個組之間的身高平均值的大小比較可用這種方法,
- 配對樣本T檢驗(Paired-Sample T Test):用來看一組樣本在處理前后的平均值有無差異,比如,你選取了5個人,分別在飯前和飯后測量了他們的體重,想檢測吃飯對他們的體重有無影響,就需要用這個t檢驗,注意,配對樣本t檢驗要求嚴格配對,也就是說,每一個人的飯前體重和飯后體重構成一對,
- t檢驗分為單總體t檢驗和雙總體t檢驗:
- 單總體t檢驗:檢驗一個樣本平均數與一已知的總體平均數的差異是否顯著,當總體分布是正態分布,如總體標準差σ未知且樣本容量n<30,那么樣本平均數與總體平均數的離差統計量呈t分布,檢驗統計量為:
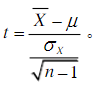
如果樣本屬于大樣本(n>30)也可以寫成:
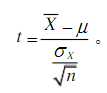
其中,t為樣本平均數與總體平均數的離差統計量;X為樣本平均數;μ為總體平均數;σx為樣本標準差;n為樣本容量, - 雙總體t檢驗 :檢驗兩個樣本平均數與其各自所代表的總體的差異是否顯著,雙總體t檢驗又分為兩種情況,一是相關樣本平均數差異的顯著性檢驗,用于檢驗匹配而成的兩組被試獲得的資料或同組被試在不同條件下所獲得的資料的差異性,這兩種情況組成的樣本即為相關樣本,二是獨立樣本平均數的顯著性檢驗,各實驗處理組之間毫無相關存在,即為獨立樣本,該檢驗用于檢驗兩組非相關樣本被試所獲得的資料的差異性,相關樣本的t檢驗公式為:
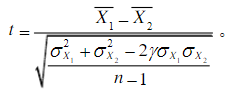
其中,X1,X2分別為兩樣本平均數;σx12,σx22分別為兩樣本方差;y為相關樣本的相關系數,
Z檢驗
- Z檢驗(在國內一般叫U檢驗)就是用服從正態分布N(0,1)的統計量Z來進行顯著性檢驗,使用這種檢驗方法,必須先知道總體的方差σ2;Z檢驗一般用于大樣本(即大于30)平均值差異性檢驗的方法,它是用標準的理論來推斷差異發生的概率,從而比較兩個的差異是否顯著;當已知標準差時,驗證一組數的均值是否與某個值相等時,用Z檢驗,
- 原理:Z檢驗是通過計算兩個平均數之間差的Z分數來與規定的理論Z值相比較,看是否大于規定的理論Z值,從而判定兩平均數的差異是否顯著的一種差異顯著性檢驗方法,
- 一般步驟:
- 建立虛無假設H0:μ1=μ2,即先假定兩個平均數之間沒有顯著差異;
- 計算Z值,對于不同型別的問題選用不同的計算方式:
① 檢驗一個樣本平均數(x)與一個已知的總體平均數(μ0)的差異是否顯著,其Z值計算公式為: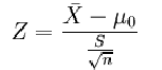

② 檢驗兩組樣本平均數的差異性,從而判斷它們各自代表的總體的差異是否顯著,Z值計算公式為:
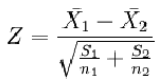

- 比較計算所得Z值與理論Z值,推斷發生的概率,依據Z值與差異顯著性關系表作出判斷,
| Z值 | p值 | 差異程度 |
|---|---|---|
| ≥2.58 | ≤0.01 | 非常顯著 |
| ≥1.96 | ≤0.05 | 顯著 |
| ≤1.96 | ≥0.05 | 不顯著 |
非引數檢驗
卡方檢驗(?2檢驗)
- 卡方檢驗是一種用途很廣的計數資料的假設檢驗方法,主要是比較兩個及兩個以上樣本率(構成比)以及兩個分類變數的關聯性分析,根本思想在于比較理論頻數和實際頻數的吻合程度或者擬合優度問題,應用主要有①兩個率或兩個構成比比較的卡方檢驗;②多個率或多個構成比比較的卡方檢驗以及分類資料的相關分析,
- 卡方檢驗計算原理:
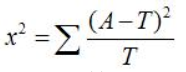
其中:A是實際值,T為理論值,x2表示理論值與實際值的差異程度,
然后查詢卡方分布的臨界值,將計算的值與臨界值比較,如果x2 <臨界值,則假設成立,
查詢臨界值就需要知道自由度:V =(行數-1)*(列數-1),根據算出的V查詢卡方分布表, - 舉例:例如想知道喝牛奶對感冒發病率有沒有影響(下表中括號內的為理論人數),
| 感冒人數 | 未感冒人數 | 合計 | 感冒率 | |
|---|---|---|---|---|
| 喝牛奶組 | 43(39.3231) | 96(99.6769) | 139 | 30.94% |
| 不喝牛奶組 | 28(31.6848) | 84(80.3152) | 112 | 25.00% |
| 合計 | 71 | 180 | 251 | 28.29% |
喝牛奶組和不喝牛奶組的感冒率為30.94%和25.00%,兩者的差別可能是抽樣誤差導致,也可能是 牛奶對感冒率真的有影響,
下面進行假設:假設喝牛奶對感冒發病率沒有影響,即喝牛奶與感冒無關,所以感冒的發病率實際是(43+28)/(43+28+96+84)=28.29%,
根據上面的公式計算出x2=1.077,對于該問題V=1,查詢可得臨界值為3.84,x2=1.077<3.84,假設成立,即喝牛奶與感冒無關,
秩和檢驗
- 秩和檢驗又稱順序和檢驗,它不依賴于總體分布的具體形式,應用時可以不考慮被研究物件為何種分布以及分布是否以知,因而實用性較強,這種方法主要用于比較兩個獨立樣本(兩個樣本可以不等長)的差異,
- 秩和檢驗的優缺點:
- 優點:不受總體分布限制,適用面廣;適用于等級資料及兩端無確定值的資料;易于理解,易于計算,
- 秩和檢驗的缺點:符合引數檢驗的資料,用秩和檢驗,則不能充分利用資訊,檢驗功效低,
- 適用范圍:兩個樣本來自兩個獨立的但非正態獲形態不清的兩總體,要檢驗兩樣本之間的差異是否顯著,不應運用引數檢驗中的t+檢驗,而需采用秩和檢驗,
- 兩樣本的容量長度均小于10的檢驗步驟:
- 將兩個樣本資料混合并由小到大進行等級排列(最小的資料秩次編為1,最大的資料秩次編為n1+n2);
- 把容量較小的樣本中各資料的等級相加,即秩和,用T表示,
- 把T值與秩和檢驗表中 α 顯著性水平下的臨界值相比較,如果 T1 < T < T2,則兩樣本差異不顯著;如果 T ≤ T1或 T ≥ T2,則表明兩樣本差異顯著(T1 、 T2分別為兩個樣本長度對應的秩和檢驗表中 α 顯著性水平下的值),
- 【例】某年級隨機抽取6名男生和8名女生的英語考試成績如下表所示,問該年級男女生的英語成績是否存在顯著差異?
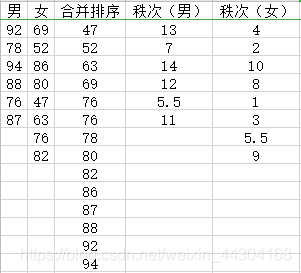
①建立假設:
H0:男女生的英語成績不存在顯著差異;
H1:男女生的英語成績存在顯著差異,
②編排秩序,求秩和T:T= 62.5;
③推斷與結論:根據 n1 = 6, n2 = 8,α = 0.05查秩和表等檢驗的上下限位T1 = 29,T2 = 61;有T>T2,所以拒絕原假設,即男女生的英語成績存在顯著差異, - 兩樣本的容量長度均大于10的檢驗步驟:
當兩個樣本容量都大于10時,秩和 T 的分布接近于正態分布,因此可以用Z檢驗,其基本公式為:
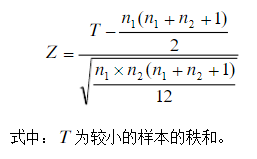
【例】還是前面的例子,不過這一次檢驗的是12個男生和14個女生,成績如下表所示:

①建立假設:
H0:男女生的英語成績不存在顯著差異;
H1:男女生的英語成績存在顯著差異,
②編排秩序,求秩和: n1 = 12, n2 = 14,T= 144.5,將 T 帶入公式算 Z 值得Z = -0.9;
③推斷與結論:α = 0.05,查表得 Zα = 1.96,|Z| < Zα,所以保留原假設,拒絕備擇假設,即男女生的英語成績不存在顯著差異,
常用的假設檢驗種類及使用的檢驗方法
- 單總體均值的假設檢驗
- 總體方差σ2已知:z檢驗,檢驗統計量為:
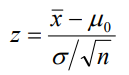
- 總體方差σ2未知:t檢驗,檢驗統計量為:

- 雙總體均值差的假設檢驗
- 兩總體均是正態分布,兩總體方差已知:z檢驗(n可以小于30),檢驗統計量為:
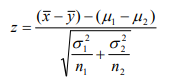
- 兩總體均是正態分布,兩總體方差未知但相等:t檢驗,檢驗統計量為:
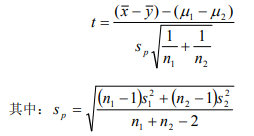
- 兩總體分布未知:z檢驗(兩個樣本容量n都需要大于30),檢驗統計量為:
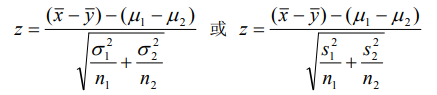
- 單正態總體方差的假設檢驗:?2檢驗,檢驗統計量為:
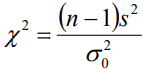
- 雙正態總體方差之比的假設檢驗:F檢驗,檢驗統計量為:
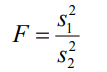
- 匯總:
方差分析
對于一到兩組資料之間的總體均值的假設檢驗,使用T檢驗和Z檢驗就可實作,而對于兩組以上的總體均值的假設檢驗則需要使用方差分析,當然對于三組及以上之間的總體均值的假設檢驗也可通過兩兩組合多次使用T檢驗和Z檢驗來實作,只不過比較麻煩,使用方差分析可以大大減少作業量,并且增強假設檢驗的穩定性,
原理和相關術語
【例】某公司采用四種方式推銷其產品,為檢驗不同方式推銷產品的效果,隨機抽樣得下表,不同的銷售方式對銷售量有影響嗎?
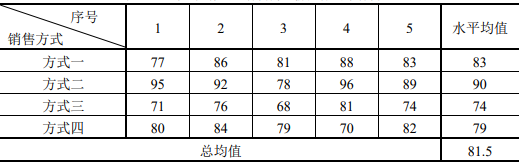
- 方差分析的相關術語:
- 因素(Factor):因素是指所要研究的變數,它可能對因變數產生影響,在【例】中,要分析不同銷售方式對銷售量是否有影響,所以,銷售量是因變數,而銷售方式是可能影響銷售量的因素,如果方差分析只針對一個因素進行,稱為單因素方差分析,如果同時針對多個因素進行,稱為多因素方差分析,本章后面也會介紹單因素方差分析和雙因素方差分析,它們是方差分析中最常用的,
- 水平(Level):水平指因素的具體表現,如銷售的四種方式就是因素的不同取值等級,有時水平是人為劃分的,比如質量被評定為好、中、差,
- 單元(Cell):單元指因素水平之間的組合,【例】中銷售方式一下的五種不同的銷售業績就構成一個單元,方差分析要求的方差齊性就是指的各個單元間的方差齊性,
- 元素(Element):元素指用于測量因變數的最小單位,一個單元里可以只有一個元素,也可以有多個元素,【例】中各單元中有 5 個元素,
- 均衡(Balance):如果一個試驗設計中任一因素各水平在所有單元格中出現的次數相同,且每個單元格內的元素數相同,則稱該試驗是為均衡,否則,就被稱為不均衡,不均衡試驗中獲得的資料在分析時較為復雜,【例】是均衡的,
- 互動作用(Interaction):如果一個因素的效應大小在另一個因素不同水平下明顯不同,則稱為兩因素間存在互動作用,當存在互動作用時,單純研究某個因素的作用是沒有意義的,必須在另一個因素的不同水平下研究該因素的作用大小,如果所有單元格內都至多只有一個元素,則互動作用無法測出,
-
方差分析的基本原理:將資料總的偏差平方和按照產生的原因分解成:(總的偏差平方和)=(由因素水平引起的偏差平方和)+(試驗誤差平方和);上式右邊兩個平方和的相對大小可以說明因素的不同水平是否使得各型號的平均維修時間產生顯著性差異,為此需要進行適當的統計假設檢驗,上例中要看不同推銷方式的效果,其實就歸結為一個檢驗問題,設μi為第 i 種推銷方式 i(i=1,2,3,4)的平均銷售量,即檢驗原假設μ1=μ2=μ3=μ4是否為真,
從上【例】的表可以觀察到,四個均值都不相等,方式二的銷售量明顯較大,然而,我們并不能簡單地根據這種第一印象來否定原假設,而應該分析μ1、μ2、μ3、μ4之間差異的原因,20 個資料各不相同,這種差異可能由兩方面的原因引起的:一是推銷方式的影響,不同的方式會使人們產生不同消費沖動和購買欲望,從而產生不同的購買行動,這種由不同水平造成的差異,我們稱為系統性差異;另一是隨機因素的影響,同一種推銷方式在不同的作業日銷量也會不同,因為來商店的人群數量不一,經濟收入不一,當班服務員態度不一,這種由隨機因素造成的差異,我們稱為隨機性差異,
-
兩個方面產生的差異用兩個方差來計量:
- 組內方差,即水平內部的方差,僅包含隨機性差異;
- 組間方差,即μ1、μ2、μ3、μ4之間的總體差異,它既包含系統性差異,也包含隨機性差異,
- 進行方差分析,樣本通常要符合以下假定:首先是各樣本的獨立性,即各組觀察資料,是從相互獨立的總體中抽取的,只有是獨立的隨機樣本,才能保證方差的可加性;其次要求所有觀察值都是從正態總體中抽取,且方差相等,
單因素方差分析
-
單因素方差分析的資料結構
單因素方差分析的資料結構一般如下圖所示:
在單因素方差分析中,若因素 A 共有 r 個水平,對均衡試驗而言,每個水平的樣本容量為 k,則共有 kr 個觀察值,如上表所示,對不均衡試驗,各水平中的樣本容量可以是不同的,設第i個樣本的容量是ni,則觀測值的總個數為:
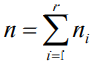
-
單因素方差分析的步驟
- 建立假設
原假設和備擇假設為:
H0:μ1=μ2=μ3=……=μr;
H1:μ1、μ2、μ3、……、μr不全等, - 構造檢驗F統計量
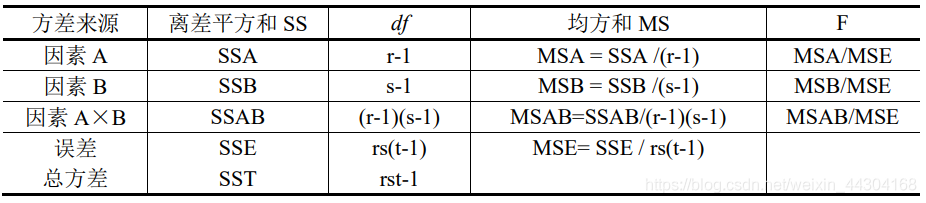
方差分析表:
水平的均值:令xi為第 i 水平的樣本均值,則
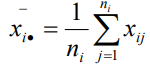
全部觀察值的總均值:令x為全部觀察值的總均值,則
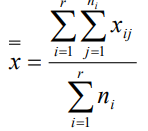
總離差平方和(SST):反映全部觀察值的離散狀況,是全部觀察值與總平均值的離差平方和計算公式為:
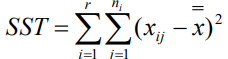
誤差項離差平方和(SSE):又稱為組內離差平方和,它反映了水平內部觀察值的離散情況,即隨機因素產生的影響計,算公式為:
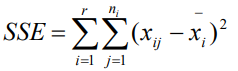
水平項離差平方和(SSA):又稱組間離差平方和,是各組平均值與總平均值的離差平方和,它既包括隨機誤差,也包括系統誤差,計算公式為:
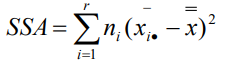
由于各樣本的獨立性,使得變差具有可分解性,即總離差平方和等于誤差項離差平方和加上水平項離差平方和,用公式表達為:SST = SSE + SSA,
根據方差統計表:F=組間方差 / 組內方差= MSA / MSE=[SSA /(r-1)] / [SSE /(n-r)] - 判斷與結論
在假設條件成立時,F統計量服從第一自由度df1為 r-1、第二自由度df2為 n-r 的 F 分布,將統計量 F 與給定的顯著性水平α的臨界值Fα(r-1,n-r) 比較,可以作出決策,決策圖如下:
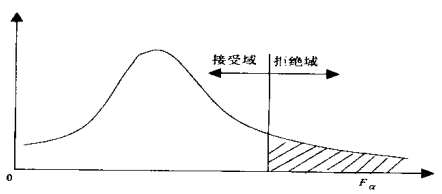
若 F≥Fα,則拒絕原假設H0,表明均值之間的差異顯著,因素 A 對觀察值有顯著影響;
若 F<Fα,則不能拒絕原假設H0,表明均值之間的差異不顯著,因素 A 對觀察值沒有顯著影響,
決策方式:一是用 F 與 F crit 比較,F>F crit,則拒絕原假設;二是用 P-value 與α比較,如果 P-value<α,則拒絕原假設,
- 【例】對以下資料做方差分析,要求判斷四種不同的推銷方式對銷量是否有影響,
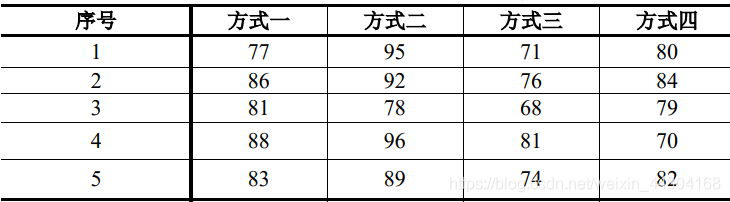
當α=0.05時,分析結果如下(每個數值得含義可參考方差分析表):
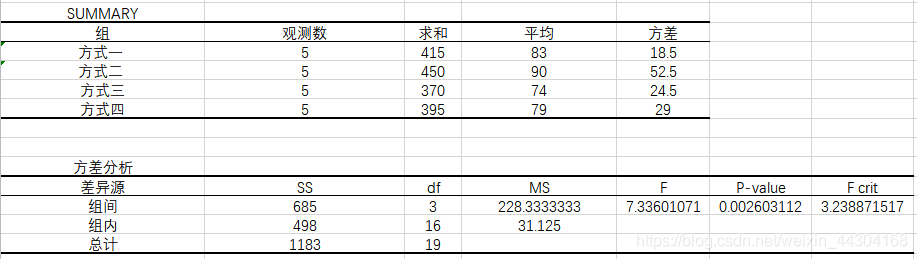
決策:F>F crit,拒絕原假設,即μ1、μ2、μ3、μ4不全等,四種推銷方式對銷售量有顯著影響,
雙因素方差分析
- 雙因素方差分析有兩種型別:
一種是無互動作用的雙因素方差分析,它假定因素 A 和因素 B 的效應之間是相互獨立的,不存在相互關系;另一種是有互動作用的方差分析,它假定 A、B 兩個因素不是獨立的,而是相互起作用的,兩個因素同時起作用的結果不是兩個因素分別作用的簡單相加,兩者的結合會產生一個新的效應, - 無互動作用的雙因素方差分析
方差分析表:
(一)資料結構
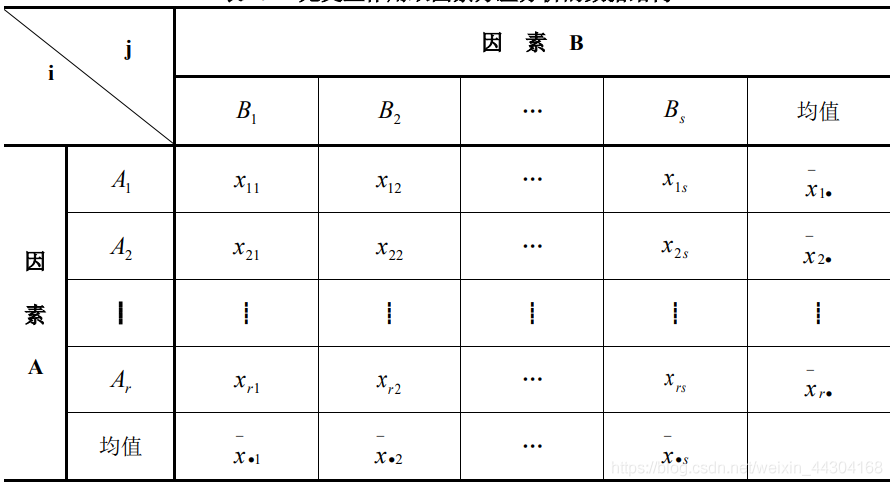
設兩個因素分別是 A 和 B,因素 A 共有 r 個水平,因素 B 共有 s 個水平,無互動作用的雙因素方差分析的資料結構如下表所示:
(二)分析步驟
- 分析模型與建立假設
在水平組合(Ai , Bj) 下的試驗結果Xij服從 N ( μij , σ2 ),i = 1,2……,r;j = 1,2,……,s,假設這些試驗結果相互獨立,與單因素方差分析模型相類似, 令 μ 稱為一般水平或平均水平,αi = μi - μ 稱為因素A在第i個水平下的效應,βj = μj - μ 稱為因素 B 在第 j 個水平下的效應,若μij = μ + αi + βj,則稱這種方差分析模型為無互動作用的雙方差分析模型,此時只需對(Ai , Bj) 的每種組合各做一次試驗,觀測值記為xij,把原引數μij變換成新引數 αi 和 βj后,無互動作用的雙因素方差分析模型為:
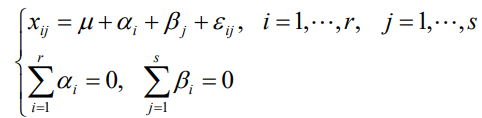
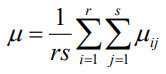
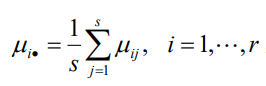
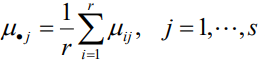
兩個影響因素的原假設與備擇假設如下:
對于因素A,H0A:μ1=μ2=μ3=……=μr;H1A:μ1、μ2、μ3、……、μr不全等,
對于因素B,H0B:μ1=μ2=μ3=……=μs;H1B:μ1、μ2、μ3、……、μs不全等,
我們檢驗因素 A 是否起作用實際上就是檢驗各個 αi 是否均為 0,如都為 0,則因素 A 所對應的各組總體均數都相等,即因素 A 的作用不顯著;對因素 B,也是這樣,因此上述假設等價于:
對于因素A,H0A:α1=α2=α3=……=αr = 0;H1A:μ1、μ2、μ3、……、μr不全為0,
對于因素B,H0B:β1=β2=β3=……=βs = 0;H1B:β1、β2、β3、……、βs不全為0, - 構造檢驗統計量
水平的均值:
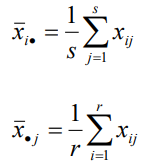
總均值:
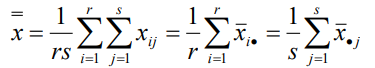
離差平方和的分解:雙因素方差分析同樣要對總離差平方和 SST 進行分解,SST 分解為三部分:SSA 、SSB和 SSE,以分別反映因素 A 的組間差異、因素 B 的組間差異和隨機誤差(即組內差異)的離散狀況,它們的計算公式分別為:
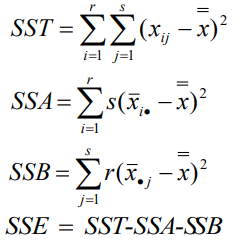
為檢驗因素 A 的影響是否顯著,采用下面的統計量(相關引數可查看方差分析表):
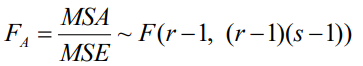
為檢驗因素 B 的影響是否顯著,采用下面的統計量(相關引數可查看方差分析表):
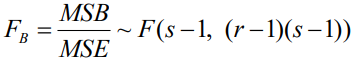
- 判斷與結論
根據給定的顯著性水平α在 F 分布表中查找相應的臨界值Fα,將統計量 F 與Fα進行比較,作出拒絕或不能拒絕原假設H0的決策,決策方式如下:

當然也可比較P-value與α的大小,原理同上,
【例】某公司想知道產品銷售量與銷售方式及銷售地點是否有關,隨機抽樣得下表資料,以 α = 0.05 的顯著性水平進行檢驗,
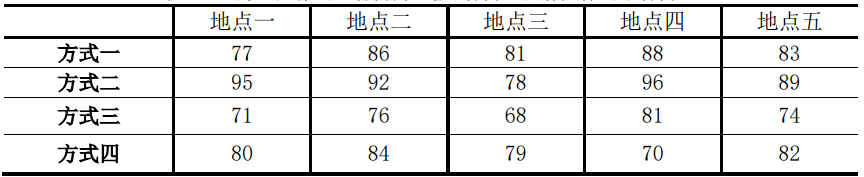
首先針對問題,提出原假設和備擇假設:
對于因素A,H0A:μ1=μ2=μ3=μ4;H1A:μ1、μ2、μ3、μ4不全等,
對于因素B,H0B:μ1=μ2=μ3=μ4=μ5;H1B:μ1、μ2、μ3、μ4、μ5不全等,
根據以上步驟得出方差分析結果如下:
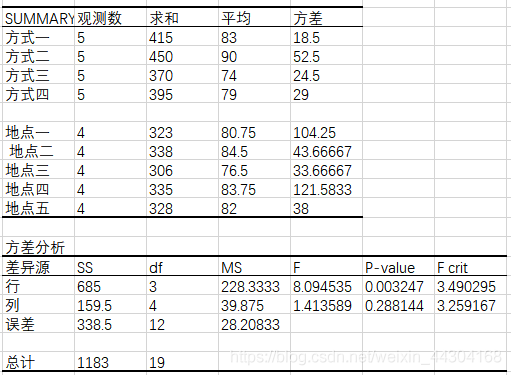
結論:
FA ≥ Fα,拒絕原假設H0A,即銷售方式對銷售量有影響;
FB < Fα,不能拒絕原假設H0B,即銷售地點對銷售量的影響不顯著,
- 有互動作用的雙因素方差分析
方差分析表:
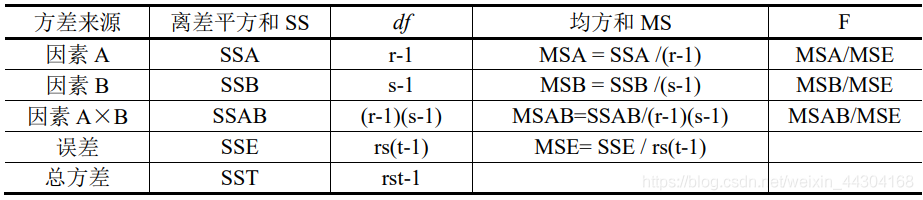
(一)資料結構
設兩個因素分別是 A 和 B,因素 A 共有 r 個水平,因素 B 共有 s 個水平,在水平組合(Ai , Bj) 下的試驗結果Xij服從 N ( μij , σ2 ),i = 1,2……,r;j = 1,2,……,s,假設這些試驗結果相互獨立,為對兩個因素的互動作用進行分析,每個水平組合下至少要進行兩次試驗,不妨假設在每個水平組合( Ai, Bj) 下重復 t 次試驗,每次試驗的觀測值用χijk表示,k=1,2,……,t ,那么有互動作用的雙因素方差分析的資料結構如下表所示:
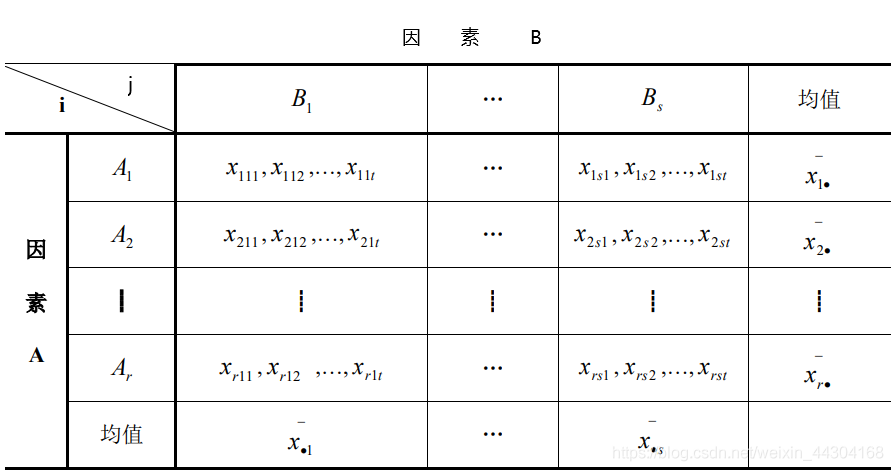
(二)分析步驟
- 分析模型與建立假設:
與無互動作用雙因素方差分析模型一樣, 令 μ 稱為一般水平或平均水平,αi = μi - μ 稱為因素A在第i個水平下的效應,βj = μj - μ 稱為因素 B 在第 j 個水平下的效應,若μij ≠ μ + αi + βj,則稱這種方差分析模型為有互動作用的雙方差分析模型,此時再令γij = μij - μ - αi - βj稱為因素 A 的第 i 水平與因素 B 的第 j 水平的互動效應,且滿足:
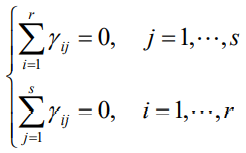
把原引數 μj 變換成新引數 αi、 βj 和 γij 后,有互動作用的雙因素方差分析模型為:
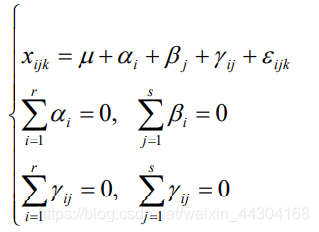
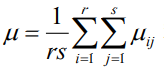
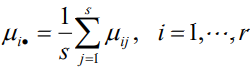
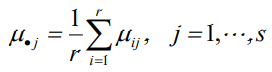
這里i = 1,2……,r;j = 1,2,……,s;k=1,2,……,t ;,隨機誤差 εijk 相互獨立,都服從N(0,σ2)的分布,與前面的分析思路相同,我們檢驗因素 A、因素 B 以及兩者的互動效應是否起作用實際上就是檢驗各個 αi、 βj 和 γ~ij 是否都為 0,故對此模型要檢驗的假設有有三個:
對于因素A,H0A:α1=α2=α3=……=αr = 0;H1A:μ1、μ2、μ3、……、μr不全為0,
對于因素B,H0B:β1=β2=β3=……=βs = 0;H1B:β1、β2、β3、……、βs不全為0,
對因素 A 和 B 的互動效應:H0C:對一切 i , j 有 γij = 0;H1C:對一切 i , j 有 γij 不全為零, - 構建檢驗統計量
水平的均值:
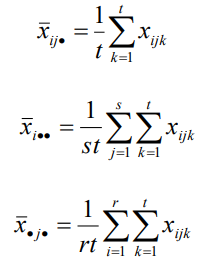
總均值:
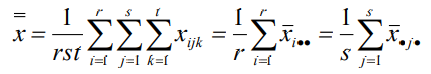
離差平方和的分解:與無互動作用的雙因素方差分析不同,總離差平方和 SST 將被分解為四個部分:SSA、SSB、SSAB 和 SSE,以分別反映因素 A 的組間差異、因素 B 的組間差異、因素 AB 的互動效應和隨機誤差的離散狀況,它們的計算公式分別表示如下:
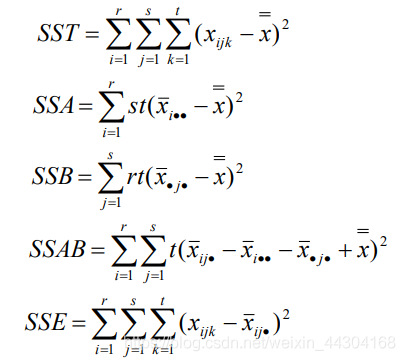
構造檢驗統計量:
①為檢驗因素 A 的影響是否顯著,采用下面的統計量:
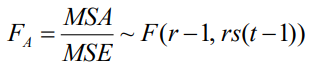
②為檢驗因素 B 的影響是否顯著,采用下面的統計量:
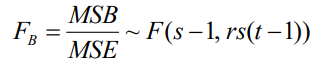
③為檢驗因素 A、B 互動效應的影響是否顯著,采用下面的統計量:
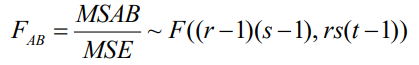
(三)判斷與結論
根據給定的顯著性水平 α 在 F 分布表中查找相應的臨界值 Fα,將統計量 F 與 Fα 進行比較,作出拒絕或不能拒絕原假設H0的決策,
若 FA ≥ Fα(r -1,rs(t-1)),則拒絕原假設H0A,表明因素 A 對觀察值有顯著影響,否則,不能拒絕原假設H0A;
若 FB ≥ F α(s-1,rs(t-1)),則拒絕原假設H0B,表明因素 B 對觀察值有顯著影響,否則,不能拒絕原假設H0B;
若 FAB ≥ F α ((r-1)(s-1), rs(t-1)),則拒絕原假設H0C,表明因素 A、B 的互動效應對觀察值有顯著影響,否則,不能拒絕原假設H0C,
當然也可比較P-value與α的大小,原理同上,
【例】電池的板極材料與使用的環境溫度對電池的輸出電壓均有影響,今材料型別與環境溫度都取了三個水平,測得輸出電壓資料如下表所示,問不同材料、不同溫度及它們的互動作用對輸出電壓有無顯著影響(α=0.05),
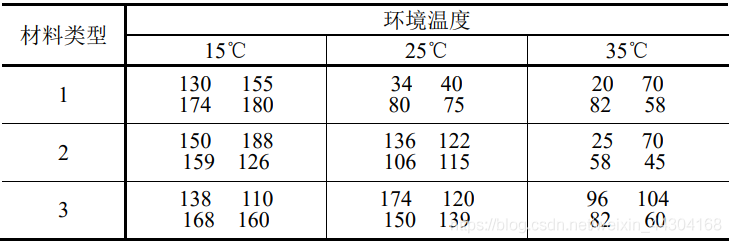
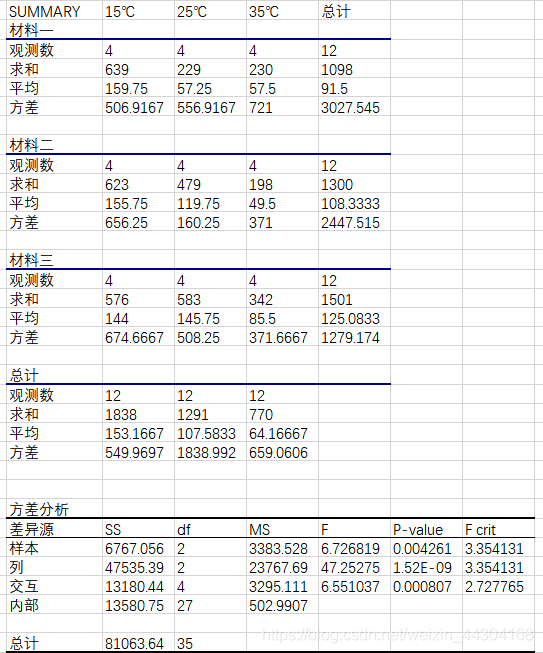
首先針對問題,提出原假設和備擇假設:
對因素 A: H0A : αi = 0;H1A : αi 不全為零(i, j = 1,2,3);
對因素 B: H0B : βj = 0;H1B : βj 不全為零(i, j = 1,2,3);
對因素 A 和 B 的互動效應:H0C : γij = 0;H1C : γij不全為零(i, j = 1,2,3) ,
根據以上分析步驟得出分析結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237202.html
標籤:其他
上一篇:論公眾號內卷