基本介紹,模型,隨機變數
- 一. 基本介紹
- 二. 模型
- 三. 隨機變數和概率分布
- 四. 結語
一. 基本介紹
在大學就讀期間,對于資料分析模型這門課,我上下來的感覺就是基礎的統計離散數學,這門課會給你講一些最基礎的統計知識很貼近我們高中的一些數學知識,資料分析模型這課的進階是高等資料分析,
資料分析模型和高等資料分析均是深度學習也就是關于人工智能的基礎課程也是資料科學專業范疇下的,也正是小弟我的專業,大家可以看下我寫的另一份博客—資料分析模型 目錄,從而對這門課有一個更直觀的認識,
這里我把老師推薦這門課的讀物也推薦給大家,感興趣自學的同學可以參考,
Ross, S.M. (2014) Introduction to Probability and Statistics for Engineers and Scientists, 5th ed. Academic Press.
英語不好的同學也可以上網查找其的漢化版以便自學使用,
二. 模型
什么是模型,在資料科學范疇內,模型是數學或邏輯的運算式或者是方程,說白了你也可以理解為給它個輸入,它給你個想要的輸出,
模型沒有絕對的對和錯,但是對于不同的目的,它們可以被稱為相對有用或相對沒用,
- 例子:
- 一個模型A(關于飛機資訊的數學模型)可以呈現相對的機翼和機身的維度
- 一個模型B(備擇模型,alternative model)可以更精準的呈現該飛機的空氣中的流動行為,* 備擇模型:是對于原模型來說是其對立的模型,
如果我們研究飛機的比例,或者飛機的形狀制作,我們利用模型A,如果研究飛機在飛行時的狀態,我們選擇模型A的對立模型,
接下來帶大家看看運用在資料科學里的幾個最基礎的模型,這里目的僅僅大體介紹下常見模型,并非講的深入,后續會分別細講,在此只是帶大家粗略的了解下
一. 分類模型(分類器)

分類器作為分類函式模型將資料按若干類區分開從而預測未來的資料型別,分類器例如決策樹,邏輯回歸,和深度學習里的神經網路,后續我們均會講到,當然這張圖僅僅有男女兩類,我們也可稱這種分類器為binary classifier(二元分類器),根據自變數X(例如發長,喉結,衣服),通過你的模型或數學邏輯方程(y=f(X))來預測因變數y(例如y=0為女生,y=1為男生),
二. 概率分類器

概率分類器,類似于傳統分類器,其區別僅僅是利用概率來分辨屬于哪一類,即計算每個類別的概率,
三. 回歸模型

通過你的的一系列資料(自變數X和因變數Y),你得到了一個方程(模型),帶入自變數到方程(模型)中你獲得預測因變數的數值,如圖假如每個人有自己得時薪,最高時薪100元,那么你可以通過方程和該人的作業資訊來預測其他人的時薪,這里的方程叫做回歸方程(回歸方程有,線性回歸方程,邏輯回歸方程,懲罰回歸方程(嶺回歸,拉索回歸)后續會一一解釋),這里為什么總是強調X值和Y值,X值和Y值作為你的資料(data)來找到符合或者可以解釋這些資料的模型,分類器或者概率分類器和回歸模型均需要有X值和Y值才能找到對應具體的模型,例子,假如你有一組資料均有X值和Y值符合2x+1=y這個函式或者模型,我們都知道該函式是一元一次方程,具體怎樣才能找到a=2,b=1,這個2x+1=y的一元一次方程,我們需要有相關的X值和Y值的資料才能找到該模型的引數,所以用你的資料X值和Y值才能找到具體適合解釋我們具有的資料的模型,這類方法在深度學習里叫做監督式學習,利用計算機找到預測誤差較小的模型,
四. 簇類模型
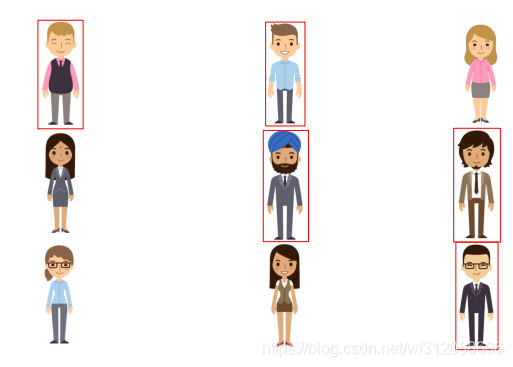
簇類模型的資料是一般沒有因變數y的,在深度學習里因變數y也被稱為標簽也可以叫真值,換句話說簇類模型根據自變數x來通過模型進行分類,對比我們之前提到的分類器,它與簇的區別在于,要找到具體的分類器是需要有因變數y,在深度學習里,有因變數和自變數找到模型的方法叫做可監督學習,只通過自變數找到模型的方法叫做非監督學習,對于簇類模型,根據上圖的例子,我們可以根據人類性別特征(作為因變數x)來進行分類(例如喉結),因為我們沒有因變數y值,我們無法得出是男(預測y值為1)是女(預測y值為0),但我們可以用影像的方式呈現,男性的點會簇集在某個區域A,女性的點會簇集在另外一片區域B(所以叫簇類模型),這樣當我們根據自變數來預測時如果它對應的點在A區域我們認為它是男性,反之為女性,在深度學習里,簇類模型難以訓練找到引數從而找到具體對應的模型,或者說非監督學習難以訓練,好吧先說那么多,我們在此就粗略的回顧溫習下常見的模型,大體知道它們干什么的就行,具體細節后面還會提到,
五. 預測模型(Forecasting)
預測模型和之前講的模型很像,都是預測嘛,但不同點在于,上述的模型均是預測一個值,而預測模型更注重于預測一個值的變化或者預測一系列的值,舉個例子預測房價,你關注的點在于這個房價明天會漲還是會降,漲幅多少,降低多少,或者長期的這個房價的變化幅度,當然了,舉個例子你可以用分類器來作為你的預測模型,例如是否需要買進,或賣出,但它的關鍵點在于,給予過去的資訊,你要盡可能預測準確對于未來一系列的資料,
六. 例外檢測模型(Anomaly Detection)
根據平常的資料檢測一些例外資料,舉個例子,一個人平常每天花費轉賬就100塊,一天晚上他突然花費或轉賬1W塊,那么這個行為被模型檢測為例外,再舉個例子,假如一個記錄步數的軟體給老年人用的,這個軟體記錄了老年人平常每天出去散步多宣告,但突然一天這個軟體記錄該老年人沒出去走多宣告,那么系統會認為這個老年人是不是病了或者摔倒了,
七.推薦系統模型(Recommended system)
例如你逛某寶,該模型會根據你平常關顧的商品來預測你的喜好,進而給你提供相關商品,
以上是幾個最基礎也最常見的模型,在此帶大家了解下,具體里面更深入的知識后續會講,
這里講幾個常見的統計術語:
- 總體(population):說白了就是對于一件事,你有大量的相關可測量的資料,用于找到你的模型,這些資料量往往對我們來說是無窮的,這些資料叫做總體
- 樣本(sample):就是從總體當中挑選有窮盡數量的資料用來找到你的模型,所以資料量不足有時候使你找到的模型不飽和也就是說對于預測新資料不夠準確,當資料量足的時候你找到的模型又過飽和也就是你的模型僅僅局限于預測你挑選的資料,無法預測新資料,當然這里只是簡單的泛化的介紹下非飽和和過飽和概念,導致模型的非飽和,和過飽和的原因還有很多,這里先按下不表,總而言之樣本即為從總體中挑選的資料,
- 模型(model):這里在啰嗦一句,模型在哲學上的含義是對該資料的解釋(當然有許多模型復雜程度是我們無法解釋的),模型在計算機方面的解釋就是一套數學和邏輯的運算式,我們一般利用資料找到的模型沒有對和錯之分,只有相對有用和沒有用,當你有了一大把資料,你想找一個模型可以解釋和預測該類資料,你有兩個問題需要解決,1.這模型長什么樣子,2.這模型的引數是什么換句話說找到在該類模型下找到具體的或適合你資料的模型,當你解決這倆問題你才能認為你找到了該模型,例如之前有提到2x+1=y,a=2,b=1,當你已經知道這個模型是一元一次方程,那么a和b這兩個引數可以通過你的資料找到,那我們怎么知道該模型是一元一次方程呢,早些時候,數學家利用一種泛化的函式嘗試解釋所有型別的資料,根據改變該泛化函式的引數或指數改變來大體近似模擬所有型別的資料,例如廣義泛化函式,連加模型,還有多項式函式等等,利用資料找到模型這就是傳說中的機器學習泛化解釋,只不過在深度學習里,模型是神經網路(你可以把他當作一個萬能的模型也就是泛化模型,可以解釋或者模擬大量不同類別的資料,例如可以預測房價,垃圾分類等不同專案的問題),有些資料是有X值和Y值,通過該資料找到的模型叫做可監督學習,而有寫資料僅僅有X值無Y值,通過此資料找到的模型叫做非監督學習,一般做資料挖掘的人都知道,找和記錄資料都挺耗人力和財力的,資料僅僅有X值是很常見的,這時就要利用資料的關系或者變化該資料來發現一些其他的事情,例子就像上述講的男女分類簇類模型,再舉一個例子:假如給了你許多鳥類照片(X值)但不給你說這是什么鳥(無Y值),我們可以利用轉動照片來創造其他型別的資料創造Y值,這樣我們的模型可以分辨是否該照片有被加工或者被反轉,這就是變化該資料,當然這個方法其實還可以解決過飽和問題,至于為什么后續會再提到,
資料的形式的術語:
1 名義分類資料(categorical nominal data): 離散,有限,無序的數值,例如:性別,國籍
2.有序分類資料(categorical ordinal data):離散,有限,有序的數值,例如:教育水平(小,初,高,大學)
3.離散數值(numeric discrete):數字形式的資料,可列舉,可數的清,有窮數量,例如:幾個正整數,幾個負整數,多少在公司的員工未滿18歲,
4.連續數值(numeric continue):數字形式的資料,不可列舉,數不清,無窮量,例如,大于0的實數,小于0的實數,身高(1米789321),體重,長度, 分類資料一般是定性,而數值資料一般是定量,
三. 隨機變數和概率分布
樣本里隨機采樣獲得樣本,也就是我們的資料,利用該樣本(資料)找到適合的模型,
一. 隨機變數(Random Variables):
假如計算擲出倆個骰子數值和為7的概率,我們其實更注重于是否倆個骰子和是否為7,至于到底是(1,6),(2,5),(3,4),(5,2),(6,1),(4,3)并不是我們這個實驗的目的,這里的(1,6),(2,5),(3,4),(5,2),(6,1),(4,3)便是我們的隨機變數,我們簡單的計算下倆個骰子數值和為7的概率:P{X=7}=P{(1,6),(2,5),(3,4),(5,2),(6,1),(4,3)}=1/6 * 1/6 * 6=6/36,
X=7是我們的實驗目的決定了我們隨機變數為(1,6),(2,5),(3,4),(5,2),(6,1),(4,3)
當計算擲出倆個骰子數值和為12的概率時,即 X=12時, P{X=12}=P{(6,6)}=1/36,我們隨機變數為(6,6)
由我們實驗目的來決定我們的隨機變數,而不是隨機變數來決定我們的實驗目的,那為什么這些變數叫隨機變數呢,這里需要解釋下什么叫做隨機性,變數的隨機性是由于這三點導致的--------實驗的測量錯誤(測量的變數有誤差),測量因素(有些變數的值不是因為誤差而是因為我們有些因素的疏忽導致變數測量不準確)和隨機取樣(隨機從總體內取樣),那么具有該隨機性的變數即為隨機變數,
在離散數學和連續數學領域里,簡單的說,隨機變數就是我們的資料樣本,而這些隨機變數可能會服從或者符合某個概率分布(模型).
二. 概率分布(Probability distribution)
如上述所說,概率分布就是一種模型來解釋我們的資料即隨機變數,寫法: P(X=x), x∈X,X相當于總體,x為樣本.
例如擲一個骰子擲出1的概率是1/6,即P(X=1)=1/6,它的概率分布其實是x軸,x∈X={1,2,3,4,5,6},其對應y軸P(X)的值均為1/6, 6個離散的點,
性質1:
P(X=x)∈[0,1], 對于所有x∈X,滿足:
∑
x
∈
X
P
(
X
=
x
)
=
1
?
\sum_{x∈X} P(X=x) =1\,
x∈X∑?P(X=x)=1
性質2:
P(X∈A1∪A2)=P(X∈A1)+P(X∈A2)-P(X∈A1∩A2)
∪并集(union set), ∩交集(intersection set), 集合是高中數學概念這里不再贅述,
性質3:
聯合概率(joint probability)
當我們研究2個或2個以上的隨機變數關系時,我們會計算它的聯合概率,
假如這里有兩組隨機變數(RVs), X和Y
X={1,2,3}, Y={1,2},那么
X x Y={{1,1},{2,1},{3,1},{1,2},{2,2},{3,2}}, 這樣我們可以定義它為 P(X=x, Y=y) ∈[0,1],
對于P(X=x, Y=y) ∈[0,1], 所有x∈X,y∈Y,滿足:
∑
x
∈
X
,
y
∈
Y
P
(
X
=
x
,
Y
=
y
)
=
1
?
\sum_{x∈X,y∈Y} P(X=x, Y=y) =1\,
x∈X,y∈Y∑?P(X=x,Y=y)=1
如果X和Y這兩類變數互不影響則
P
(
X
=
x
,
Y
=
y
)
=
P
(
X
=
x
)
?
P
(
Y
=
y
)
P(X=x, Y=y) = P(X=x)*P(Y=y)
P(X=x,Y=y)=P(X=x)?P(Y=y)
跟我們上述擲倆骰子(扔出這倆骰子得出倆數值,這兩件事發生的概率互不影響)和為7大同小異的演算法,當X=x時,Y=y時這兩件事共同發生且互不干擾的概率.
那么如果X和Y這倆類變數(兩類事件)互相干擾時,這時需要根據題意去計算,舉個例子,假設骰子A的隨機變數我們定為X,骰子B的隨機變數我們定為Y,我們依舊想算倆個骰子擲出后數值和為7的概率,但是加個小條件,當骰子A拋出1,2,3這三個數值時我們才能擲骰子B,那么我們只能有(1,6),(3,4),(2,5)這三個,那么此時P(X=x,Y=y)=3 * 1/6 * 1/6 * 1/6. 此時P(X=1,2,3)= 3 * 1/6, 那么P(Y)=1/6 * 1/6,不是僅單單1/6.
性質4:
邊緣概率(marginal probability)
P
(
X
=
x
)
=
∑
y
∈
Y
P
(
X
=
x
,
Y
=
y
)
?
P(X=x)= \sum_{y∈Y} P(X=x, Y=y) \,
P(X=x)=y∈Y∑?P(X=x,Y=y)
P(X=x) 被稱為邊緣概率,即所有Y=y,X=x的概率
性質5:
條件概率(conditional probability)
P
(
X
=
x
∣
Y
=
y
)
=
P
(
X
=
x
,
Y
=
y
)
P
(
Y
=
y
)
=
P
(
X
=
x
,
Y
=
y
)
∑
x
∈
X
P
(
X
=
x
,
Y
=
y
)
?
?
P(X=x | Y=y)= \frac{P(X=x,Y=y)}{P(Y=y)}\ = \frac{P(X=x,Y=y)}{\sum_{x∈X} P(X=x, Y=y)\,}\,
P(X=x∣Y=y)=P(Y=y)P(X=x,Y=y)? =∑x∈X?P(X=x,Y=y)P(X=x,Y=y)?
P(X=x | Y=y)為條件概率,翻譯過來的意思是,當給定Y=y的概率時,那么X=x的概率.
這里要注意的是如果兩個隨機變數也相互獨立,那么
P
(
X
=
x
∣
Y
=
y
)
=
P
(
X
)
.
P(X=x | Y=y)= P(X).
P(X=x∣Y=y)=P(X).
舉個例子: 如下圖
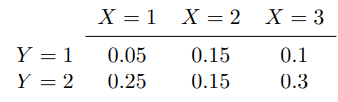
別太糾結P(X=1,Y=1)為啥是0.05,我們默認這些值是對的哈,即P(X=1,Y=1)=0.05, P(X=2,Y=1)=0.15, 等等,
那么,
P(Y=1)=0.05+0.15+0.1=0.3 (邊緣概率).
P(X=1|Y=1)=P(X=1,Y=1)/P(Y=1)=0.05/0.7 (條件概率).
當在同一個分布下的時候,它的隨機變數也互不干擾,這類變數我們稱為獨立同分布(independent and identically distributed, 簡寫i.i.d) 例如上述兩個篩子,拋出第一個篩子的概率分布和拋出第二個篩子的分布相同,且隨機變數X和Y互相獨立,則X,Y為i.i.d, P(X=1)=P(Y=1)=1/6,
即如果X1,X2 是i.i.d,那么P(X1=x)=P(X2=x), 對于所有x1,x2∈X,換句話說,你也可以認為他們的邊緣概率相同,
三. 連續隨機變數(continuous random variables )
我們之前講的隨機變數均為離散隨機變數,例如骰子只能有正整數1,2,3,4,5,6這6個隨機變數. 這次我們叫我們的隨機變數屬于實數,即X符合機率密度函式(probability density function,簡寫pdf) p(x)
那么, 該pdf,對于所有x∈X, 滿足:
1
>
p
(
x
)
>
=
0
,
和
∫
X
p
(
x
)
d
x
=
1
1>p(x)>=0, 和 \int_{X}^{}p(x)\mathrm{d}x=1
1>p(x)>=0,和∫X?p(x)dx=1
如果X 在(a,b)區間內,則為:
P
(
a
<
X
<
b
)
=
∫
a
b
p
(
x
)
d
x
P(a<X<b)=\int_{a}^{b}p(x)\mathrm{d}x
P(a<X<b)=∫ab?p(x)dx
假如(x0-
δ
/
2
\delta/2
δ/2<X<x0+
δ
/
2
\delta/2
δ/2),那么它的概率的影像為陰影部分,即為它的概率:
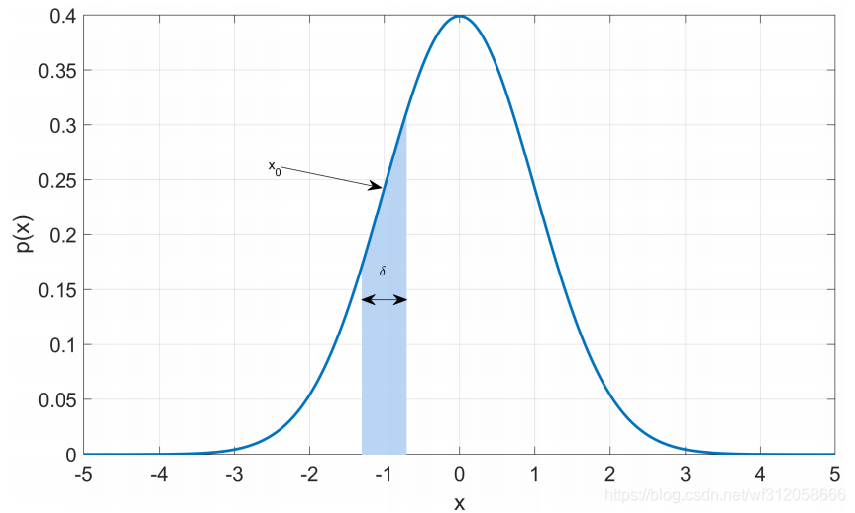
其實也就是連續函式的微積分求反導,算它的陰影面積,P(x0-
δ
/
2
\delta/2
δ/2<X<x0+
δ
/
2
\delta/2
δ/2)=P(x0+
δ
/
2
\delta/2
δ/2)-P(x0-
δ
/
2
\delta/2
δ/2),大面積減去小的面積,我們可以把它的寫法寫的更帥點:
A
δ
=
(
x
0
?
δ
/
2
,
x
0
+
δ
/
2
)
A_{\delta}=(x0-\delta/2,x0+\delta/2)
Aδ?=(x0?δ/2,x0+δ/2)
P
(
x
∈
A
δ
)
=
∫
x
0
?
δ
/
2
x
0
+
δ
/
2
p
(
x
)
d
x
=
[
∫
p
(
x
)
d
x
]
x
=
x
0
+
δ
/
2
?
[
∫
p
(
x
)
d
x
]
x
=
x
0
?
δ
/
2
≈
x
0
?
δ
P(x∈A_{\delta})=\int_{x0-\delta/2}^{x0+\delta/2}p(x)\mathrm{d}x=[\int p(x)\mathrm{d}x]_{x=x0+\delta/2}-[\int p(x)\mathrm{d}x]_{x=x0-\delta/2} \approx x0*\delta
P(x∈Aδ?)=∫x0?δ/2x0+δ/2?p(x)dx=[∫p(x)dx]x=x0+δ/2??[∫p(x)dx]x=x0?δ/2?≈x0?δ
所以當
δ
\delta
δ 趨近于0時:
- A δ A_{\delta} Aδ?趨近于x0,
- P(x∈ A δ A_{\delta} Aδ?)趨近于0,陰影面積就那一細毫,因為dx很小,微元,當 A δ A_{\delta} Aδ?=x0時,P(X=x0)= ∫ x 0 x 0 f ( x ) d x \int_{x0}^{x0}f(x)\mathrm{d}x ∫x0x0?f(x)dx=0, 這一絲的值其實為0,
兩個連續隨機變數 X和Y:
1. 邊緣概率
那么x的邊緣概率為
p
(
x
)
=
∫
p
(
x
,
y
)
d
y
p(x)=\int p(x,y)\mathrm{d}y
p(x)=∫p(x,y)dy
若P(X∈A)=
∫
A
∫
p
(
x
,
y
)
d
y
d
x
\int_{A}\int p(x,y)\mathrm{d}y\mathrm{d}x
∫A?∫p(x,y)dydx,當你算出了p(x)時,我們得到了該x的概率分布,因為x∈A,我們依然要用反導求對應A的面積,
2.聯合概率
兩個連續變數X和Y的聯合概率:
若X,Y獨立則:
P
(
X
∈
A
,
Y
∈
B
)
=
∫
B
∫
A
p
(
x
,
y
)
d
x
d
y
P(X∈A,Y∈B)=\int_{B}\int_{A}p(x,y)\mathrm{d}x \mathrm{d}y
P(X∈A,Y∈B)=∫B?∫A?p(x,y)dxdy
再舉個例子: X1,X2,…Xn互相獨立則
P
(
X
1
∈
a
1
,
X
2
∈
a
2
,
.
.
.
.
,
X
n
∈
a
n
)
=
∫
A
n
∫
A
n
?
1
.
.
.
.
.
∫
A
1
p
(
x
1
,
x
2
,
.
.
.
.
,
x
n
)
d
x
1
d
x
2...
d
x
n
P(X1∈a1,X2∈a2,....,Xn∈an)=\int_{An}\int_{An-1}.....\int_{A1}p(x1,x2,....,xn)dx1dx2...dxn
P(X1∈a1,X2∈a2,....,Xn∈an)=∫An?∫An?1?.....∫A1?p(x1,x2,....,xn)dx1dx2...dxn
若X,Y不獨立,那需要根據題意計算,跟離散變數的聯合概率大同小異,
3.條件概率
P(X|Y)=
p
(
x
,
y
)
p
(
y
)
=
p
(
x
,
y
)
∫
p
(
x
,
y
)
d
x
\frac{p(x,y)}{p(y)}=\frac{p(x,y)}{\int p(x,y)dx}
p(y)p(x,y)?=∫p(x,y)dxp(x,y)?,該公式分母即為y的邊緣概率,
若X,Y獨立,則:
P(X|Y)=P(X)=
∫
p
(
x
,
y
)
d
y
{\int p(x,y)dy}
∫p(x,y)dy
四. 累計連續方程(Cumulative distribution functions, 簡寫cdf)
其實我們上述已經涉及到累計,就是連續函式的反導陰影面積,即多個微元的連加,
對于連續變數來說它的cdf為:
P
(
X
<
=
x
)
=
∫
?
∞
x
p
(
x
)
d
x
P(X<=x)=\int_{-\infty}^{x} p(x)\mathrm{d}x
P(X<=x)=∫?∞x?p(x)dx
對于離散變數來說它的累計方程為:
P
(
X
<
=
x
)
=
∑
P
(
x
)
?
P(X<=x)= \sum_{} P(x) \,
P(X<=x)=∑?P(x)
這里啰嗦一句:
P
(
X
>
x
)
=
1
?
P
(
X
<
=
x
)
P(X>x)=1-P(X<=x)
P(X>x)=1?P(X<=x)
在統計里面,Q( p ) ={P(X<=x)=p}, 如果Q(p=1/2) 則為中部(median), 如果Q(p=1/4)是第一四分位數(first quartile), 如果Q(p=3/4)則為第三四分位數(third quartile).
四. 結語
自習的同學可以看看Ross, S.M. (2014) Introduction to Probability and Statistics for Engineers and Scientists, 5th ed. Academic Press. 第4章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237209.html
標籤:其他
上一篇:k8sV1.18.0版本一鍵部署腳本(全部代碼在下方)
下一篇:Hive自定義磁區器流程