想要獲取完整代碼,請訪問面包多進行支持哦,僅需一口奶茶的錢!
一、實驗目的
實作基于蒙特卡洛法的21點問題的最優解,了解強化學習的基本原理,理解蒙特卡洛法并撰寫相應的代碼,
二、實驗內容
賭場上流行的21點紙牌游戲的目的是獲得其數值之和盡可能大而不超過21的牌,所有的人形牌面都算作10,而A可以算作1或11,我們的實驗僅考慮每個玩家獨立與莊家競爭的版本,游戲開始時,莊家和玩家都有兩張牌,莊家的一張牌面朝上,另一張牌面朝下,如果玩家有21張牌(一張A和一張10牌),則稱為自然牌,他就贏了,除非莊家也有自然牌,在這種情況下,游戲是平局,如果玩家沒有自然牌,那么他可以要求額外的牌,單張發牌(hits),直到他停止(sticks)或超過21(goes bust),如果他破產,那么他輸了,如果他堅持,那么就輪到莊家的回合,莊家hits或sticks或者goes bust;在牌數字和為17或更多的時候,莊家就停止發牌,贏、輸、或平局由誰的最終和值更接近21決定,
三、實驗程序
本次實驗需要匯入如下包:
import gym
import numpy as np
from collections import defaultdict
import matplotlib
import matplotlib.pyplot as plt
運用gym自帶的21點游戲進行接下來的編程:
env = gym.make('Blackjack-v0')
observation = env.reset()
print(env.action_space, env.observation_space, sep='\n')
這段代碼回傳了玩家的當前點數之和 ∈{0,1,…,31} ,莊家朝上的牌點數之和 ∈{1,…,10} ,及玩家是否有能使用的ace(no =0 、yes =1 ),和智能體可以執行兩個潛在動作:STICK = 0,HIT = 1,
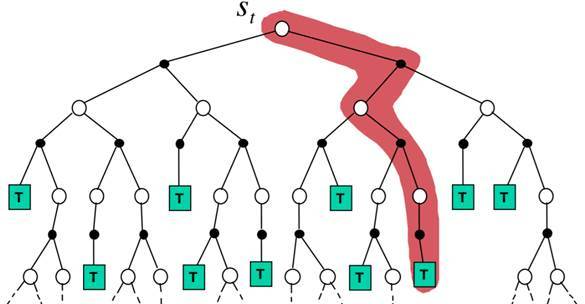
本次實驗采用On-policy first-visit MC control,On-policy方法在一定程度上解決了exploring starts這個假設,讓策略既greedy又exploratory,最后得到的策略也一定程度上達到最優,如下圖所示:

我們定義一個嵌套函式:
def make_epsilon_greedy_policy(Q_table, nA, epsilon):
def generate_policy(observation):
prob_A = np.ones(nA) * epsilon / nA
optimal_a = np.argmax(Q_table[observation])
prob_A[optimal_a] += (1.0 - epsilon)
return prob_A
return generate_policy
MC演算法是逐幕進行的,所以我們要根據策略來生成一幕資料,
這里要注意:generate_policy是一個函式即make_epsilon_greedy_policy的回傳值,generate_policy的回傳值是 π \piπ ,這里回圈了1000次只是為了確保能獲得完整的一幕,
接下來是MC控制的主體部分,我們要回圈足夠多的次數使得價值函式收斂,每次回圈都首先根據策略生成一幕樣本序列,然后遍歷每個“狀態—價值”二元組,并用所有首次訪問的回報的平均值作為估計.
這里要注意:Return和Count是字典,每個“狀態—價值”二元組是一個key,該二元組每一幕的回報是它的value,隨著越來越多的迭代,根據大數定律,它的平均值會收斂到它的期望值,并且在下一輪迭代生成另外一幕樣本序列的時候,generate_policy函式會根據Q_table更新,
def MC_control(env, iteration_times=500000, epsilon=0.1, discount_factor=1.0):
Return, Count, Q_table = defaultdict(float), defaultdict(float), defaultdict(lambda: np.zeros(env.action_space.n))
policy = make_epsilon_greedy_policy(Q_table, env.action_space.n, epsilon)
for i in range(iteration_times):
if i % 1000 == 0:
print(str(i) + "次")
trajectory = generate_one_episode(env, policy)
s_a_pairs = set([(x[0], x[1]) for x in trajectory])
for state, action in s_a_pairs:
s_a = (state, action)
first_visit_id = next(i for i, x in enumerate(trajectory) if x[0] == state and x[1] == action)
G = sum([x[2] * (discount_factor ** i) for i, x in enumerate(trajectory[first_visit_id:])])
Return[s_a] += G
Count[s_a] += 1.
Q_table[state][action] = Return[s_a] / Count[s_a]
return policy, Q_table
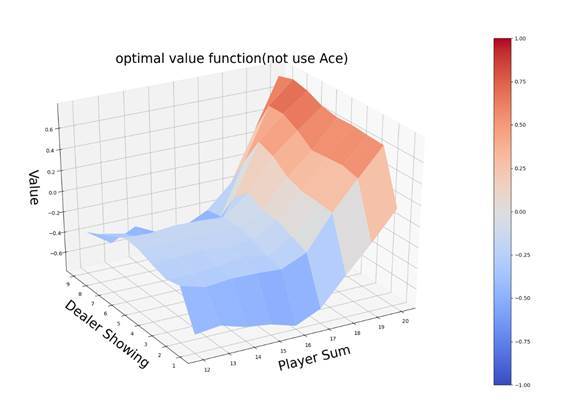
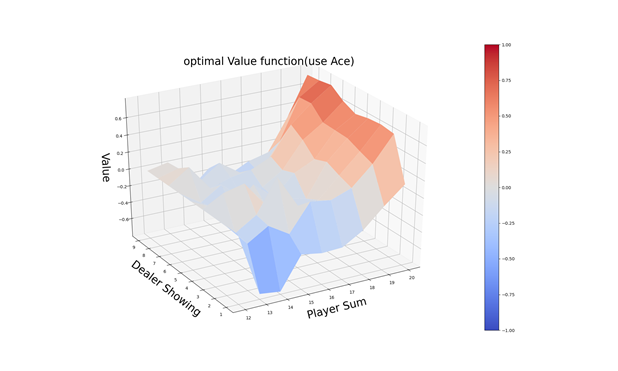
接下來是將價值函式可視化:
def plot_value_function(Q_table):
x = np.arange(12, 21)
y = np.arange(1, 10)
X, Y = np.meshgrid(x, y)
Z_noace = np.apply_along_axis(lambda x: Q_table[(x[0], x[1], False)], 2, np.dstack([X, Y]))
Z_ace = np.apply_along_axis(lambda x: Q_table[(x[0], x[1], True)], 2, np.dstack([X, Y]))
def plot_surface(X, Y, Z, title):
代碼過長略
實驗結束,想要獲取完整代碼,請訪問面包多進行購買
四、實驗結果
運行如上代碼,在代碼檔案RL中,輸出圖所示:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237490.html
標籤:其他