Hive preceding and following理解
在講解hive開窗函式前我們來看看Hive視窗函式preceding and following是怎么回事
Hive視窗函式中,有一個功能是統計當前行之前或之后指定行作為一個聚合,關鍵字是 preceding 和 following,舉例說明其使用方法.
常規的視窗函式比較簡單,這里介紹一下分組的,重點是分組排序之后的rows between用法,
關鍵是理解rows between中關鍵字含義:
| 關鍵字 | 含義 |
|---|---|
| preceding | 往前 |
| following | 往后 |
| current row | 當前行 |
| unbounded | 開始行 |
| unbounded preceding | 表示從前面的起點 |
| unbounded following | 表示到后面的終點 |
案例
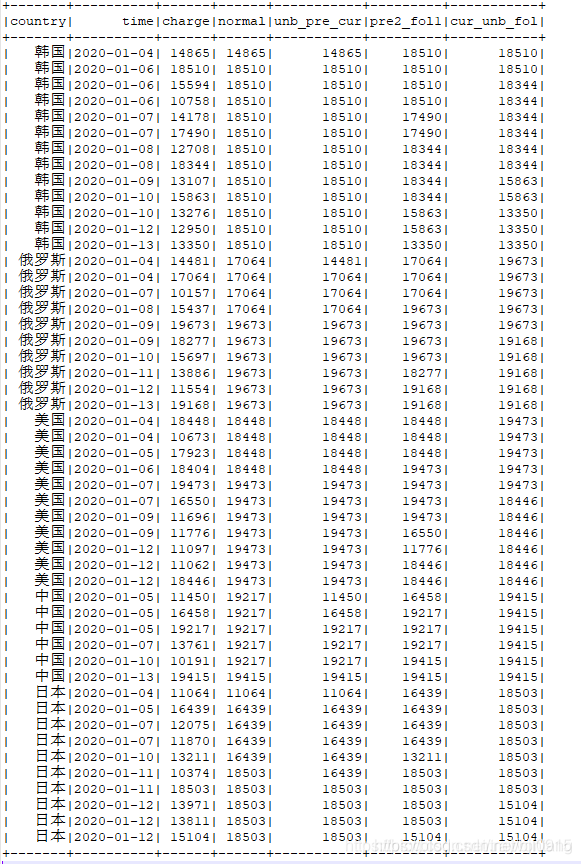
select country,time,charge,
max(charge) over (partition by country order by time) as normal,
max(charge) over (partition by country order by time rows between unbounded preceding and current row) as unb_pre_cur,
max(charge) over (partition by country order by time rows between 2 preceding and 1 following) as pre2_fol1,
max(charge) over (partition by country order by time rows between current row and unbounded following) as cur_unb_fol
from temp
*默認是在分組類的當前行之前的行中計算,
rows between unbounded preceding and current row和默認的一樣
rows between 2 preceding and 1 following表示在當前行的前2行和后1行中計算
rows between current row and unbounded following表示在當前行和到最后行中計算
rows between對于avg、min、max、sum這幾個視窗函式的含義基本是一致的,注意查看當前結果
在 hive 環境中創建臨時表
create table tmp_student
(
name string,
class tinyint,
cooperator_name string,
score tinyint
)row format delimited fields terminated by '|';
加載測驗資料
load data local inpath ‘text.txt’ into table tmp_student;
其中text.txt中內容為:
adf|3|測驗公司1|45
xx|3|測驗公司2|55
cfe|2|測驗公司2|74
3dd|3|測驗公司5|n
fda|1|測驗公司7|80
gds|2|測驗公司9|92
ffd|1|測驗公司10|95
dss|1|測驗公司4|95
ddd|3|測驗公司3|99
gf|3|測驗公司9|99
查看是否加載成功
hive> select * from tmp_student;
adf 3 測驗公司1 45
xx 3 測驗公司2 55
cfe 2 測驗公司2 74
3dd 3 測驗公司5 NULL
fda 1 測驗公司7 80
gds 2 測驗公司9 92
ffd 1 測驗公司10 95
dss 1 測驗公司4 95
ddd 3 測驗公司3 99
gf 3 測驗公司9 99
Time taken: 1.314 seconds, Fetched: 10 row(s)
下面來練習preceding and following函式用法,執行下面sql
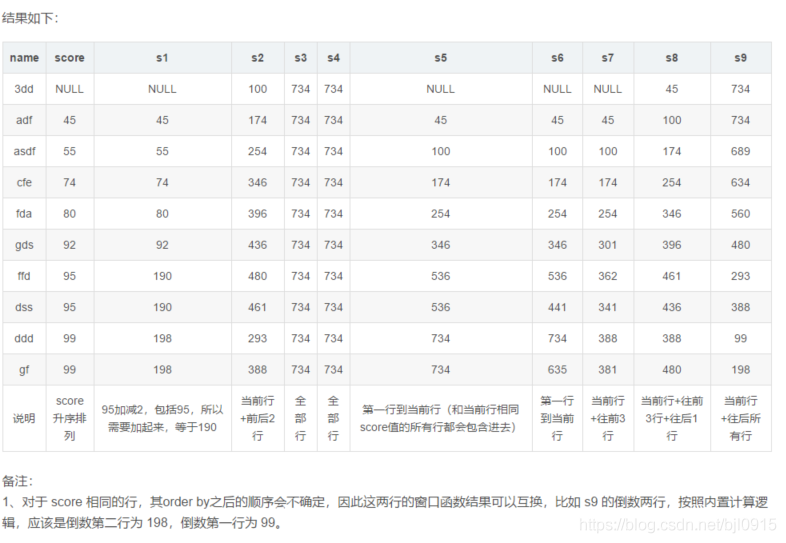
select
name,
score,
sum(score) over(order by score range between 2 preceding and 2 following) s1, -- 當前行的score值加減2的范圍內的所有行
sum(score) over(order by score rows between 2 preceding and 2 following) s2, -- 當前行+前后2行,一共5行
sum(score) over(order by score range between unbounded preceding and unbounded following) s3, -- 全部行,不做限制
sum(score) over(order by score rows between unbounded preceding and unbounded following) s4, -- 全部行,不做限制
sum(score) over(order by score) s5, -- 第一行到當前行(和當前行相同score值的所有行都會包含進去)
sum(score) over(order by score rows between unbounded preceding and current row) s6, -- 第一行到當前行(和當前行相同score值的其他行不會包含進去,這是和上面的區別)
sum(score) over(order by score rows between 3 preceding and current row) s7, -- 當前行+往前3行
sum(score) over(order by score rows between 3 preceding and 1 following) s8, --當前行+往前3行+往后1行
sum(score) over(order by score rows between current row and unbounded following) s9 --當前行+往后所有行
from
tmp.tmp_student
order by
score;
得到相關結果如下
 通過上面的練習我們主要是對preceding and following有了一個比較全面的理解,所謂開窗函式其實就相當于flink中的滾動視窗,統計分析都是基于這個滾動視窗內完成的
通過上面的練習我們主要是對preceding and following有了一個比較全面的理解,所謂開窗函式其實就相當于flink中的滾動視窗,統計分析都是基于這個滾動視窗內完成的
Flink視窗說明
視窗函Windowing functions
-
FIRST_VALUE(col, bool DEFAULT)
回傳分組視窗內第一行col的值,DEFAULT默認為false,如果指定為true,則跳過NULL后再取值,對于FIRST_VALUE每個分組第一行資料的FIRST_VALUE(col, bool DEFAULT) 就等于col,接下來幾行資料會參考第一行資料是否為NULL根據True/False進行取舍.
WITH tmp AS (
SELECT 1 AS group_id, 'a' AS col
UNION ALL
SELECT 1 AS group_id, 'b' AS col
UNION ALL
SELECT 1 AS group_id, 'c' AS col
UNION ALL
SELECT 2 AS group_id, NULL AS col
UNION ALL
SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id, col, FIRST_VALUE(col) OVER (PARTITION BY group_id ORDER BY col) AS col_new
FROM tmp;
回傳結果為:
group_id col col_new
1 a a
1 b a
1 c a
2 NULL NULL
2 e NULL
如果是True
WITH tmp AS (
SELECT 1 AS group_id, NULL AS col
UNION ALL
SELECT 1 AS group_id, 'b' AS col
UNION ALL
SELECT 1 AS group_id, 'c' AS col
UNION ALL
SELECT 2 AS group_id, NULL AS col
UNION ALL
SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id, col, FIRST_VALUE(col, true) OVER (PARTITION BY group_id ORDER BY col) AS col_new
FROM tmp;
回傳結果為:
group_id col col_new
1 NULL NULL
1 b b
1 c b
2 NULL NULL
2 e e
- LAST_VALUE(col, bool DEFAULT)
回傳分組視窗內第后一行col的值,DEFAULT默認為false,如果指定為true,則跳過NULL后再取值.
WITH tmp AS (
SELECT 1 AS group_id, 'a' AS col
UNION ALL
SELECT 1 AS group_id, NULL AS col
UNION ALL
SELECT 1 AS group_id, 'c' AS col
UNION ALL
SELECT 2 AS group_id, 'd' AS col
UNION ALL
SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id, col, LAST_VALUE(col) OVER (PARTITION BY group_id ORDER BY col DESC) AS col_new FROM tmp;
回傳結果為:
group_id col col_new
1 c c
1 a a
1 NULL NULL
2 e e
2 d d
如果是True
WITH tmp AS (
SELECT 1 AS group_id, 'a' AS col
UNION ALL
SELECT 1 AS group_id, NULL AS col
UNION ALL
SELECT 1 AS group_id, 'c' AS col
UNION ALL
SELECT 2 AS group_id, 'd' AS col
UNION ALL
SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id, col, LAST_VALUE(col, true) OVER (ORDER BY group_id,col DESC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS col_new FROM tmp;
回傳結果為:
group_id col col_new
1 c a
1 a a
1 NULL e
2 e d
2 d d
開窗函式不同于group by函式,開窗函式能夠把所有的記錄都顯示出來,一般select所選擇的列也都與over里面的分組和排序欄位相同,這樣才能比較清楚地看到當前記錄在聚合函式中的區別和貢獻,上面兩個視窗函式我們針對最后一個案例進行說明下.
使用了開窗函式首先要確定視窗的大小,根據上面的PRECEDING和FOLLOWING講解我們可以知道在分析時候視窗大小為[前一行,當前行,后一行],那么對于第一行1 c取出last_value就是從[空值,c,a]取出集合中最后一個就是a,同理對于第二行1 a取出last_value就是從[c,a,Null]中取出最后一個Null跳過再取得到a,對于2 e從集合[Null,e,d]last_value=d*
- LEAD(col, n, DEFAULT)
回傳分組視窗內往下第n行col的值,n默認為1,往下第n沒有時回傳DEFAULT(DEFAULT默認為NULL)使用分組后那么分組之間就不交叉計算.
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
LEAD(col) over(partition by group_id order by col) as col_new
FROM tmp;
回傳結果
group_id col col_new
1 a b
1 b c
1 c NULL
2 d e
2 e NULL
等同于
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
LAST_VALUE(col) over(partition by group_id order by col rows between 1 FOLLOWING and 1 FOLLOWING) as col_new
FROM tmp;
其中rows between 1 FOLLOWING and 1 FOLLOWING為從往后一行開始到往后一行結束=往后一行
回傳結果
group_id col col_new
1 a b
1 b c
1 c NULL
2 d e
2 e NULL
使用LEAD默認值
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
LEAD(col, 2, 'z') over(partition by group_id order by col) as col_new
FROM tmp;
回傳結果
group_id col col_new
1 a c
1 b z
1 c z
2 d z
2 e z
- LAG(col, n, DEFAULT)
回傳分組視窗內往上第n行col的值,n默認為1,往上第n沒有時回傳DEFAULT(DEFAULT默認為NULL)
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
LAG(col) over(partition by group_id order by col) as col_new
FROM tmp;
等同于
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
FIRST_VALUE(col) over(partition by group_id order by col rows BETWEEN 1 PRECEDING and 1 PRECEDING) as col_new
FROM tmp;
回傳結果都是
group_id col col_new
1 a NULL
1 b a
1 c b
2 d NULL
2 e d
使用默認值
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'd' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
LAG(col, 2, 'zz') over(partition by group_id order by col) as col_new
FROM tmp;
回傳結果
group_id col col_new
1 a zz
1 b zz
1 c a
2 d zz
2 e zz
OVER詳解 The OVER clause
** FUNCTION(expr) OVER([PARTITION BY statement] [ORDER BY statement] [window clause]) **
中括號為可選引數
FUNCTION:包括標準聚合函式(COUNT/SUM/MIN/MAX/AVG)和一些分析函式(RANK/ROW_NUMBER/DENSE_RANK等)
PARTITION BY:可以由一個或者多個列組成
ORDER BY:可以由一個或者多個列組成
window clause:(ROWS | RANGE) BETWEEN (UNBOUNDED PRECEDING | num PRECEDING | CURRENT ROW) AND (UNBOUNDED PRECEDING | num PRECEDING | CURRENT ROW)
當window clause 未指定時默認為RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,即分組內第一行至當前行作為視窗
當 window clause和ORDER BY都未指定時,默認為ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
**即分組內第一行至最后一行作為視窗.**
標準聚合函式
COUNT(expr) OVER()
回傳視窗內行數
WITH tmp AS
(
SELECT 1 AS group_id, 'a' AS col
UNION ALL SELECT 1 AS group_id, 'b' AS col
UNION ALL SELECT 1 AS group_id, 'c' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
UNION ALL SELECT 2 AS group_id, 'e' AS col
)
SELECT group_id,
col,
count(col) over(partition by group_id) as cnt1,
count(col) over(partition by group_id order by col) as cnt2,
count(col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as cnt3,
count(distinct col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as cnt4
FROM tmp;
回傳結果為
group_id col cnt1 cnt2 cnt3 cnt4
1 a 3 1 3 3
1 b 3 2 2 2
1 c 3 3 1 1
2 e 2 2 2 1
2 e 2 2 1 1
SUM(expr) OVER()
回傳視窗內求和值
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
)
SELECT group_id,
col,
SUM(col) over(partition by group_id) as sum1,
SUM(col) over(partition by group_id order by col) as sum2,
SUM(col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as sum3,
SUM(distinct col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as sum4
FROM tmp;
回傳結果為
group_id col sum1 sum2 sum3 sum4
1 1 6 1 6 6
1 2 6 3 5 5
1 3 6 6 3 3
2 4 8 8 8 4
2 4 8 8 4 4
MIN(expr) OVER()
回傳視窗內最小值
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
MIN(col) over(partition by group_id) as min1,
MIN(col) over(partition by group_id order by col) as min2,
MIN(col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as min3
FROM tmp;
group_id col min1 min2 min3
1 1 1 1 1
1 2 1 1 2
1 3 1 1 3
2 4 4 4 4
2 5 4 4 5
MAX(expr) OVER()
回傳視窗內最大值
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
MAX(col) over(partition by group_id) as max1,
MAX(col) over(partition by group_id order by col) as max2,
MAX(col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as max3
FROM tmp;
回傳結果為
group_id col max1 max2 max3
1 1 3 1 3
1 2 3 2 3
1 3 3 3 3
2 4 5 4 5
2 5 5 5 5
AVG(expr) OVER()
回傳視窗內平均值
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
)
SELECT group_id,
col,
AVG(col) over(partition by group_id) as avg1,
AVG(col) over(partition by group_id order by col) as avg2,
AVG(col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as avg3,
AVG(distinct col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as avg4
FROM tmp;
回傳結果為
|group_id|col|avg1|avg2|avg3|avg4|
|1|1|2.0|1.0|2.0|2.0|
|1|2|2.0|1.5|2.5|2.5|
|1|3|2.0|2.0|3.0|3.0|
|2|4|4.0|4.0|4.0|4.0|
|2|4|4.0|4.0|4.0|4.0|
分析函式 Analytics functions
RANK() OVER()
回傳分組內排名(不支持自定義視窗)
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
RANK() over(partition by group_id order by col desc) as r
FROM tmp;
回傳結果為
|group_id|col|r|
|1|3|1|
|1|3|1|
|1|1|3|
|2|5|1|
|2|4|2|
ROW_NUMBER() OVER()
回傳分組內行號(不支持自定義視窗)
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
ROW_NUMBER() over(partition by group_id order by col desc) as r
FROM tmp;
回傳結果為
|group_id|col|r|
|1|3|1|
|1|3|2|
|1|1|3|
|2|5|1|
|2|4|2|
DENSE_RANK() OVER()
回傳分組內排名(排名相等不會留下空位,不支持自定義視窗)
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
DENSE_RANK() over(partition by group_id order by col desc) as r
FROM tmp;
回傳結果為
|group_id|col|r|
|1|3|1|
|1|3|1|
|1|1|2|
|2|5|1|
|2|4|2|
CUME_DIST() OVER()
回傳分組內累計分布值,即分組內小于(或者大于)等于當前值行數/分組內總行數
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
CUME_DIST() over(partition by group_id order by col asc) as d1,
CUME_DIST() over(partition by group_id order by col desc) as d2
FROM tmp;
回傳結果為
|group_id|col|d1|d2|
|1|3|1.0|0.6666666666666666|
|1|3|1.0|0.6666666666666666|
|1|1|0.3333333333333333|1.0|
|2|5|1.0|0.5|
|2|4|0.5|1.0|
PERCENT_RANK() OVER()
回傳百分比排序值,即分組內當前行的RANK值-1/分組內總行數-1
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
RANK() over(partition by group_id order by col asc) as r1,
PERCENT_RANK() over(partition by group_id order by col asc) as p1,
RANK() over(partition by group_id order by col desc) as r2,
PERCENT_RANK() over(partition by group_id order by col desc) as p2
FROM tmp;
回傳結果為
|group_id|col|r1|p1|r2|p2|
|1|3|2|0.5|1|0.0|
|1|3|2|0.5|1|0.0|
|1|1|1|0.0|3|1.0|
|2|5|2|1.0|1|0.0|
|2|4|1|0.0|2|1.0|
NTILE(INTEGER x) OVER()
回傳磁區編號(將有序磁區劃分為x個組,稱為bucket,并為磁區中的每一行分配一個bucket編號)
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
col,
NTILE(2) over(partition by group_id order by col asc) as bucket_id
FROM tmp;
回傳結果為
|group_id|col|bucket_id|
|1|1|1|
|1|3|1|
|1|3|2|
|1|3|2|
|2|4|1|
|2|5|2|
OVER子句也支持聚合函式
Hive 2.1.0及之后版本,OVER子句也支持聚合函式,如:
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 5 AS col
)
SELECT group_id,
RANK() over(order by sum(col) desc) as r
FROM tmp
group by group_id;
結果為
|group_id|r|
|2|1|
|1|2|
window clause 的另一種寫法
將window子句寫在from后面,在over后使用別名進行參考,如下:
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
)
SELECT group_id,
col,
AVG(col) over w1 as avg1,
AVG(distinct col) over(partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following) as avg2
FROM tmp
WINDOW w1 AS (partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following);
結果為
|group_id|col|avg1|avg2|
|1|1|2.0|2.0|
|1|2|2.5|2.5|
|1|3|3.0|3.0|
|2|4|4.0|4.0|
|2|4|4.0|4.0|
WITH tmp AS
(
SELECT 1 AS group_id, 1 AS col
UNION ALL SELECT 1 AS group_id, 2 AS col
UNION ALL SELECT 1 AS group_id, 3 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
UNION ALL SELECT 2 AS group_id, 4 AS col
)
SELECT group_id,
col,
AVG(col) over w1 as avg1,
AVG(distinct col) over w2 as avg2
FROM tmp
WINDOW w1 AS (partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following),
w2 AS (partition by group_id order by col rows between CURRENT ROW and UNBOUNDED following);
結果為
|group_id|col|avg1|avg2|
|1|1|2.0|2.0|
|1|2|2.5|2.5|
|1|3|3.0|3.0|
|2|4|4.0|4.0|
|2|4|4.0|4.0|
本文完.
Any suggestions and criticisms will be sincerely welcomed.
資料
https://blog.csdn.net/happyrocking/article/details/105369558
https://docs.aws.amazon.com/redshift/latest/dg/redshift
https://www.jianshu.com/p/3f3cf58472ca
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237610.html
標籤:其他