看到一篇關于尋路優化的文章,簡單翻譯了一下,原文在這里
- 譯文并未照搬原文翻譯,多處是意譯
- 原文圖片已經失效,不過其他轉載網址仍有圖片,我對應著補了一下
尋路對很多游戲來講都是不可或缺的元素,在一般的游戲中,使用一些基本的尋路演算法(譬如 BFS, Dijkstra 或者 A* 等等)就可以很好的解決尋路問題,但是在另一些游戲中,尤其是在游戲地圖比較龐大的情況下,這些基本尋路演算法需要耗費大量的時間進行尋路,進而造成游戲卡頓,這使得尋路優化變得非常重要.
在這篇文章中,我會簡單介紹一下 A* 演算法以及該演算法的一些改進點,我也會講解一些常用的 A* 衍生演算法以及 HPA 演算法的一些實作要點.
重溫 A* 演算法
A* 演算法用于尋找從開始點至目標點之間的一條可達路徑.A* 演算法在尋路程序中會使用一種簡單的方法來評估當前節點與目標點之間的距離.通過將已經經過的路徑距離和預估的路徑距離相加,演算法會首先擴展搜索那些最有"前途"(與目標點距離最短)的節點.A* 演算法的尋路方式保證其一定可以找到最優路徑.
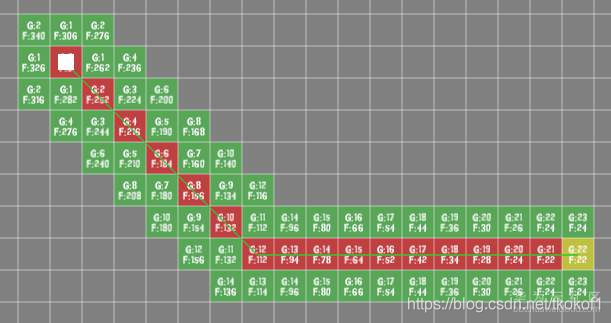
從上圖中我們可以看出,從白色的開始點出發,A* 演算法搜索了開始點附近的所有節點并沿著離目標點最近的節點找到了一條可達路徑.當 A* 演算法找到目標點后,他就通過回溯父節點的方式來重建路徑.
以下是我們實作 A* 演算法的方式:
-
將開始點放入開放串列(open list)中
-
當開放串列不為空時我們重復執行以下操作:
-
從開放串列中取出 F 值最小的節點并將他放入關閉串列中(我們后續不會再考慮關閉串列中的節點)
-
對于該節點每一個不在關閉串列中的相鄰節點:
-
將該節點設定為當前相鄰節點的父節點(主要用于后面的節點回溯)
-
計算當前相鄰節點的 G 值(從開始點到當前相鄰點的距離)并將其加入到開放串列中
-
計算當前相鄰節點的 F 值(通過將當前相鄰節點的 H 值(當前相鄰節點到目標點的預估距離)與當前相鄰節點的 G 值相加)
基本優化
存在很多調整方法可以優化 A* 演算法,這些方法能讓 A* 演算法執行的更快(但是加速程度不如一些對 A* 進行演算法層面優化的方法),另外的,這些方法在某些情況下也并不一定能得到最優的尋路結果,但是對于較空曠(不包含大量阻擋)的游戲地圖,這些方法的尋路結果也已經足夠好了.如果你想加速 A* 演算法但是又不想對其實作進行大幅改動的話,你可以參考以下的幾點建議:
-
使用有序串列. A* 演算法的每一次搜索都需要找到具有最低 F 值的節點,通過使用有序串列,我們就可以在串列的頭部位置方便的找到該節點(譯注:原文中的意思是使用無序串列,疑有誤或者有其他指代意義,譯文改為有序串列)
-
使用 字典(或者說優先級佇列) 或者 堆 來替代 串列 也可以加速 A* 演算法.在這些資料結構中遍歷元素非常之快,這會非常有助于你在其中搜索某一節點,同樣的,在有序字典或者最小堆中,我們也能很方便的找到具有最低 F 值的節點.
-
分幀尋路.如果你的游戲并不需要在一幀中就獲取完整的尋路結果,那么我們就可以使用分幀尋路來優化 A* 演算法.我們可以設定一個回圈上限,如果 A* 演算法在該回圈限制內沒能完成尋路,我們便暫停當前尋路,并在下一幀繼續.(譯注:原文的意思應該是分段尋路,方法是如果在設定的回圈限制內不能完成尋路的話,下一幀就從最后一個搜索節點開始重新尋路,這種方法并不一定能正確得到尋路結果,譯文調整為分幀尋路)
-
節點中保存 is_open 或者 is_close 變數.你可以在節點中保存一個變數,用以表示節點是否在開放串列中或者關閉串列中.通過這種方式,當你需要搜索一個串列中的節點時,你就可以不用在整個串列中搜索節點,而是直接檢查對應的變數值即可.這種方法可以大幅減少檢查節點是否在串列中的開銷.
-
在開始實際尋路之前先進行一次低層級的尋路.你可以在原游戲地圖的基礎上預先構建一張由部分節點構成的地圖,然后在實際真實尋路之前,先在這張低層級地圖上進行尋路,這樣你就可以獲取到一條由部分節點構成的尋路路徑,之后你就可以分幀來搜尋這些(部分)節點之間的路徑,與上述的分幀尋路不同的是,你不用限制回圈上限,而是一幀一幀的來尋找(部分)節點之間的路徑.
演算法優化
所謂演算法優化,是指那些會改變演算法搜尋節點方式的優化.每一個對于演算法搜尋節點方式(基于地圖分布方式或者角色移動方式)的微小改變都可能極大的改善尋路演算法的效率.值得一提的是,根據游戲地圖的動態程度不同,演算法優化的效果也不盡相同.目前有很多關于 A* 的演算法優化方式,我們這里只會談論其中的兩種: HPA 和 JPS.
HPA
分層尋路會將原始地圖預處理成一張更低層級的地圖,其中原始地圖會被分為多個簇(塊),這些簇之間的距離和最優路徑會被預先計算并快取起來.實際尋路時,首先在更低層級的地圖上(即簇之間)進行尋路,然后,我們根據之前預先計算快取的(簇之間的)最優路徑來獲得一條到達目標點的路徑.
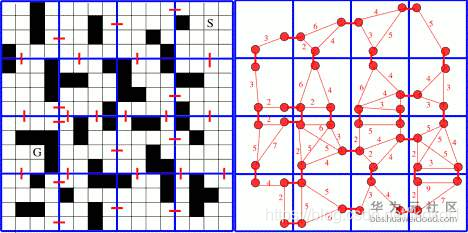
正如我們在上圖中所看到的,各個網格(節點)都按簇的方式進行劃分,并且在這些簇上有用于連接相鄰簇的出口,一旦我們將簇的出口(也是網格,或者說節點)進行相連,我們就可以得到簇從一條邊(出口)到另一條邊(出口)的距離,這些可以預計算的距離對于我們后面搜索路徑非常有幫助.
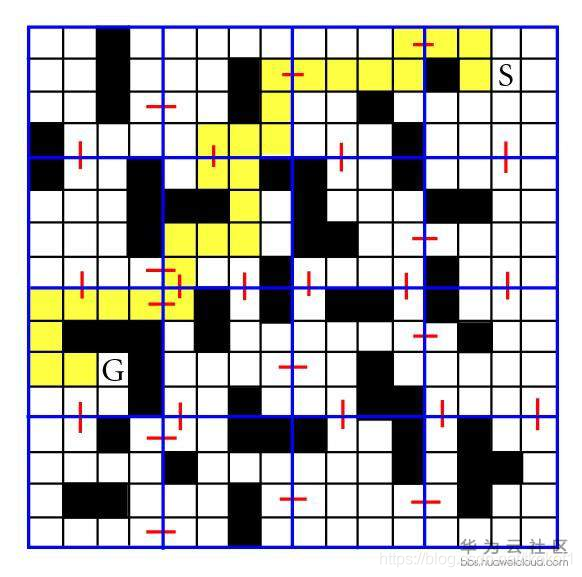
現在,我們來看個例子,我們想尋找一條從 S 到 G 的路徑,我們首先在低層級地圖上(各個簇之間)進行一次 A* 尋路,然后,我們可以根據預計算資料(簇之間的連通資料)快速的得到一條完整的路徑.
記住一點:你可以自定義網格和簇的創建方式,這聽起來似乎很當然,但是這意味著你可以根據你游戲地圖的分布方式來創建網格(和簇).通過自定義網格(和簇),你可以使一些簇變得更大,以使這些簇可以適應整個房間或者其他一些地圖區域.
演算法利弊:
每一種優化都有適合的使用情境,如果使用不當,優化效果就會大打折扣. 譬如在動態地圖中, HPA 便 需要不時的重新計算簇之間的距離和路徑,這會消耗很多的時間. 類似的, HPA 也并不是在空曠地圖中尋路的最佳選擇,不過這并不是說 HPA 在空曠地圖上的尋路表現糟糕,而是說另一些尋路演算法(譬如 JPS)更適用于這種情況.
JPS
JPS 演算法的基本思路就是持續"擴展"節點直到到達無法繼續"擴展"的區域為止.如果你仔細想一想就會發現, JPS 演算法的內涵思想其實挺簡單的:如果我們可以通過其他節點以更短的距離達到某一節點,那么我們完全可以不在(開放)串列中添加這個節點(因為這個節點在擴展其他節點時會被評估是否要加到開放串列中).
和 HPA 不同的是, JPS 不需要預計算任何資料,他的優勢在于遍歷開放串列和關閉串列的開銷很小.需要注意的是, JPS 只支持規則網格(節點)的尋路,即使你的游戲地圖包含不同尋路成本(距離)的網格或者區域, JPS 也只會把他們當做統一成本(距離)的網格或者區域.不過也正因為只支持規則網格的關系,JPS 才能夠跳過網格的某些擴展方向,?而相對應的, A* 演算法則需要擴展網格的所有可能方向.在 JPS 中,演算法僅需要擴展被其稱為 跳躍點(jump point) 的節點,接下來我會解釋 JPS 是如何找到這些跳躍點的.
在講解 JPS 演算法的細節之前,我們先聊聊 JPS 的演算法基礎: 鄰點裁剪(neighbour pruning)
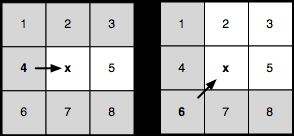
假設節點 x 正在通過其父節點進行擴展,上圖中我們用箭頭來表示這個"父子"關系.如圖所示,對于其中各個灰色節點而言,我們都可以不經過 x 節點,而是通過 x 的父節點(即 4 號節點)來進行訪問(譯注:意思是這些節點如果經過 x 節點來訪問,其成本(距離)將小于或等于僅經過 x 父節點(4 號節點)來訪問,所以在擴展 x 節點時,我們可以直接忽略這些節點而不進行擴展).現在我們來說下什么是強制鄰點(forced neighbour):
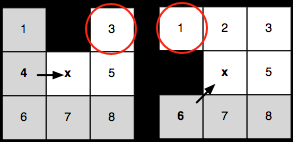
強制鄰點是指無法從 x 節點擴展到的節點,如上圖所示,如果沿著灰色網格的箭頭方向,我們無法到達紅圈中的節點(譯注:這里說的有些籠統,我們可以簡單這么理解,由于阻擋的存在,我們已經不能直接經
x 父節點訪問到紅圈節點),這些節點便稱為強制鄰點.記住,如果正在擴展的節點旁邊有阻擋的話,阻擋"后面"的節點便是強制鄰點.
演算法流程
暫略(譯注:原文在這里通過示例描述了 JPS 演算法在 水平方向 與 對角方向 搜索節點的流程,但是描述的比較簡略,也存在一些錯誤,在此暫時省略翻譯,有興趣的朋友可以閱讀這篇文章來了解 JPS 的演算法流程)
演算法利弊
正如之前所說,JPS 不能用于非規則網格地圖的尋路;對于其適用的規則網格地圖,地圖的空曠程度越高,JPS 的效率也會越高.另外, JPS 也不需要預處理任何資料,并且支持動態地圖.
如果你發現自己仍然不太理解 JPS 的演算法步驟,你可以在這個網站上直觀的查看 A*, Djikstra, JPS 等尋路演算法的運行方式.
優化實作
現在,我們來看一個簡單的尋路優化的實作方式,基本思想就是避免開放串列和關閉串列的遍歷.我們首先需要創建一個節點陣列.

通過這個節點陣列,我們就可以通過網格的位置(索引)直接訪問節點資料,這對于節點遍歷非常有用.一旦我們有了節點資料,我們就可以執行 A* 演算法了,我們要做的第一步就是在該陣列中填充原始節點,我們使用的填充函式是
std::fill(first item, last item, Node).

注意,size 的大小為 width * height.我們接下來需要為開放串列創建優先級佇列.正如我們之前所說,優先級佇列可以讓具有最低 F 值的節點位于佇列頭部,這樣我們就不需要去遍歷搜索該節點了.

如果你不知道上述代碼里模板引數中的 compare 是什么,你可以簡單理解是一種定義了如何比較節點的簡單資料結構.
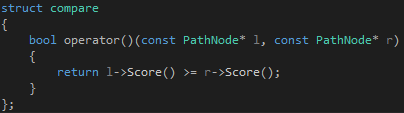
下一步就是創建 firstNode 節點指標,并將其加入開放串列中.我使用了 DistanceTo 函式來計算節點的啟發式距離(到目標點的評估距離,即節點的 H 值).
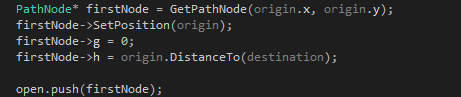
其中 GetPathNode 函式用于通過給定節點位置(索引)獲取對應的節點指標.

代碼寫到這里,我們就已經準備好進行 while 回圈了,我們會使用節點指標來進行回圈操作并檢查這些節點指標是否已經在開放串列或者關閉串列中.
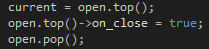
我們將當前節點的分值設定為最低,并且將其 on_close 變數設定為 true,正常來說,我們應該將節點放置于關閉串列中,但是設定節點變數資料是效率更高的一種方式.OK,現在是時候擴展相鄰節點了,擴展之前我們需要檢查相鄰節點是否已經處于關閉串列中.
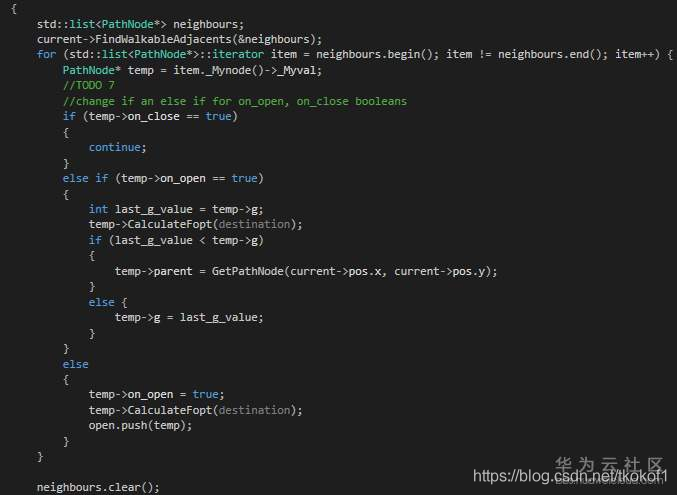
回圈中我們創建了一個指向當前評估節點的指標 temp,然后我們檢查他的 on_close 和 on_open 變數以獲知其是否在關閉串列中或是在開放串列中.使用這種方法我們就避免了在傳統 A* 演算法中最大的一個性能問題:遍歷串列以檢查某一節點是否存在.代碼的其他部分和一般的 A* 演算法沒有什么區別,值得一提的一點是,如果我們找到了一條到某一節點更短的路徑,我們需要重新設定該節點的父節點.
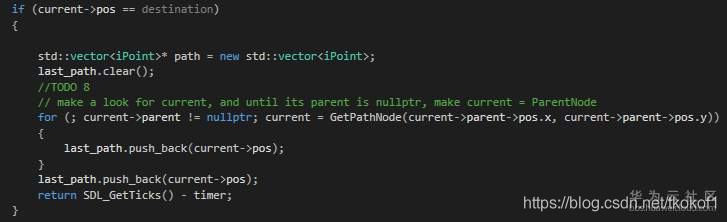
CalculateFopt 是一個用來計算節點 G 值 和 H 值 的函式,方法上主要是檢查了節點間是對角距離還是水平(或垂直)距離.我們需要做的最后一件事是,當我們搜索到目標點后,如何回溯節點直到回傳開始點:
我們可以首先保存當前節點,然后一直回溯節點的父節點直到父節點為空.至此,我們僅通過節點陣列便完成了所有的尋路操作(而沒有使用節點串列)!
優化總結
我嘗試在 120x120 的地圖上進行最"困難"的路徑搜索,結果顯示,使用優化過的 A* 演算法尋路,時間花費最多是在 20ms 左右,而普通的 A* 演算法則需要 200 ~ 600 ms.
你可以在 github 上下載工程檔案并自己嘗試下~
參考
- http://zerowidth.com/2013/05/05/jump-point-search-explained.html
- http://www.gameaipro.com/GameAIPro/GameAIPro_Chapter17_Pathfinding_Architecture_Optimizations.pdf
- http://www.intelligence.tuc.gr/~robots/ARCHIVE/2015w/Projects/LAB51326924/jps.html
- https://gamedevelopment.tutsplus.com/tutorials/how-to-speed-up-a-pathfinding-with-the-jump-point-search-algorithm–gamedev-5818
- http://aigamedev.com/open/review/near-optimal-hierarchical-pathfinding/
- https://qiao.github.io/PathFinding.js/visual/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/238007.html
標籤:AI
上一篇:微服務的隱性收益