文章目錄
- 前言
- 一、樣例輸入輸出
- 1.樣例輸入
- 2.樣例輸出
- 二、程式步驟
- 1.引入maven依賴
- 2.配置properties檔案
- 3.實作步驟
- 二、總結
前言
本文通過僅使用HDFS的原生Java-API,不呼叫MapReduce,對文本單詞進行詞頻統計,輸入和輸出檔案位置均存放在HDFS上,
本程式使用到了properties組態檔指定連接配置、輸入輸出地址以及類名等,注意,當把類名寫入組態檔并使用時,不能用new,而需要使用Java中的反射來獲取類,
一、樣例輸入輸出
1.樣例輸入

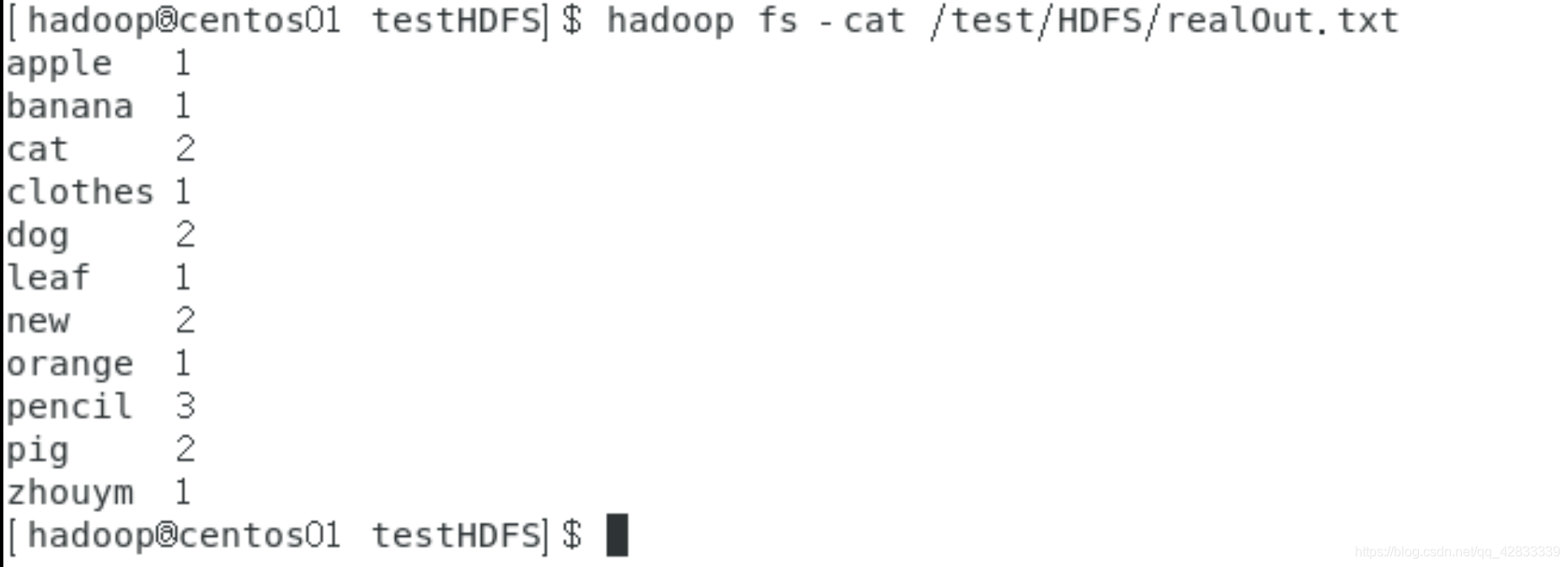
2.樣例輸出
二、程式步驟
1.引入maven依賴
首先需要創建一個普通的maven專案,然后引入Hadoop和Junit的maven依賴,Junit主要用于單元測驗(本來只有main程式可以運行的,匯入Junit之后可以在任意函式前加@Test之后便可直接運行該程式),因此Junit可以根據具體需要和偏好決定是否匯入,
maven依賴添加于pom.xml之中,具體配置如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<!--HDFS-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>
2.配置properties檔案
ADDRESS=hdfs://centos01:9000
USER=hadoop
INPUT_FILE=/test/HDFS/inputWords.txt
OUTPUT_FILE=/test/HDFS/realOut.txt
CONTEXT_CLASS=wordCount.Context
將該組態檔放在resources目錄下,
3.實作步驟
本專案的大致邏輯和實作步驟是:
1)從properties檔案中讀入引數,如用戶名、hdfs連接地址和埠號等,進行連接并獲取FileSystem;
public class myConnection {
public static FileSystem fileSystem(Properties properties) throws URISyntaxException, IOException, InterruptedException {
URI address=new URI(properties.getProperty(Constants.ADDRESS.getValue()));
String user=properties.getProperty(Constants.USER.getValue());
Configuration conf=new Configuration();
FileSystem System=FileSystem.get(address,conf,user);
return System;
}
}
2)新建Context類,用于將原資料存入TreeMap(不使用HashMap的原因是HashMap本身是無序的,想要在輸出時排好順序),該類還包含分割和詞頻統計方法;
public class Context {
private TreeMap<String,Integer> map=new TreeMap<String,Integer>();
public void write(String vocabulary,int num)
{
vocabulary=vocabulary.toLowerCase();
if(map.containsKey(vocabulary))
shuffle(vocabulary);
else
map.put(vocabulary,num);
}
public void write(String vocabulary)
{
if(map.containsKey(vocabulary))
shuffle(vocabulary);
else
map.put(vocabulary,1);
}
public void shuffle(String key)
{
map.put(key,map.get(key)+1);
}
public TreeMap<String,Integer> read()
{
return map;
}
}
3)使用Context類,將從HDFS上讀取的源資料進行分割和詞頻統計操作并存入Context.java中的TreeMap中,
public class Reader {
public static Context read(Properties properties,FileSystem fileSystem) throws URISyntaxException, IOException, InterruptedException, ClassNotFoundException, IllegalAccessException, InstantiationException {
Path path=new Path(properties.getProperty(Constants.INPUT_FILE.getValue()));
FSDataInputStream in = fileSystem.open(path);
BufferedReader reader=new BufferedReader(new InputStreamReader(in));
String line="";
String contextClassName=properties.getProperty(Constants.CONTEXT_CLASS.getValue());
Class clazz=Class.forName(contextClassName);
Context context= (Context) clazz.newInstance();
while((line=reader.readLine())!=null)
{
//System.out.println(line);
String[] S=line.split(" ");
for(String s:S)
{
System.out.println(s);
context.write(s,1);
}
}
reader.close();
return context;
}
}
4)將結果輸出到properties中的指定HDFS路徑,
public static boolean output(Properties properties,FileSystem fileSystem,Context context) throws IOException {
TreeMap<String,Integer> myMap=context.read();
Iterator<Map.Entry<String, Integer>> it=myMap.entrySet().iterator();
FSDataOutputStream out = null;
Path outputPath=new Path(properties.getProperty(Constants.OUTPUT_FILE.getValue()));
if(fileSystem.exists(outputPath))
fileSystem.delete(outputPath);
out = fileSystem.create(outputPath);
while (it.hasNext())
{
java.util.Map.Entry<String,Integer> entry=it.next();
out.write((entry.getKey()+"\t"+entry.getValue()+"\n").getBytes());
}
out.flush();
out.close();
fileSystem.close();
return true;//若成功回傳true
}
二、總結
以上就是本文要講的內容,本文通過僅使用HDFS的原生Java-API,不呼叫MapReduce,對來自HDFS文本單詞進行詞頻統計操作,并上傳到HDFS上,
最后附上本專案的github地址,供大家參考,github專案地址
第一次寫博客,如有不足之處還請大家多多指教、多多包涵,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/238035.html
標籤:其他
上一篇:某某哲統計學宇宙的Readme
下一篇:語 法 分 析