從零開始,手把手,一文kaggle競賽速度入門! 泰坦尼克
- 1. 前言
- 2. 如何開始kaggle競賽
- 2.1進入網站注冊賬號
- 2.2進入到比賽界面
- 2.3了解專案
- 3. 資料匯入與預處理
- 4. 訓練決策樹模型
- 4.1決策樹模型
- 4.2python實作決策樹
- 5. 提交結果
- 6.完整原始碼
- 7.可以改進的地方
- 8.貢獻者介紹
1. 前言
網上并不缺乏kaggle競賽的教程,但對于相當一部分人來說,在跟著進行第一個競賽的程序中,就逐漸放棄了,筆者也是在初次競賽時,遇到了很多的麻煩,在跟著大佬一步步操作的時候,困難的去理解每一步的意義,這給了我很大的阻力,
在后面的學習生活中,我逐漸明白了,對于入門來說,走完一個完整的流程是最重要和基礎的,至于優化,那是后面的事,
基于此,本文力求用最少的代碼,手把手,圖文結合的帶你去進行一次完整的kaggle競賽體驗,從進入網頁,到提交預測獲取成績,
我相信推開了門,自然有各種方法去尋找寶藏,當然,我們后續,也會有內容更豐富的泰坦尼克競賽案例推出,
2. 如何開始kaggle競賽
2.1進入網站注冊賬號
kaggle
進入kaggle官網(最好有vpn),首先點擊右上角register注冊賬號
2.2進入到比賽界面
注冊完賬號后,直接搜索titanic進入比賽主頁面
接著進入到比賽的主頁面
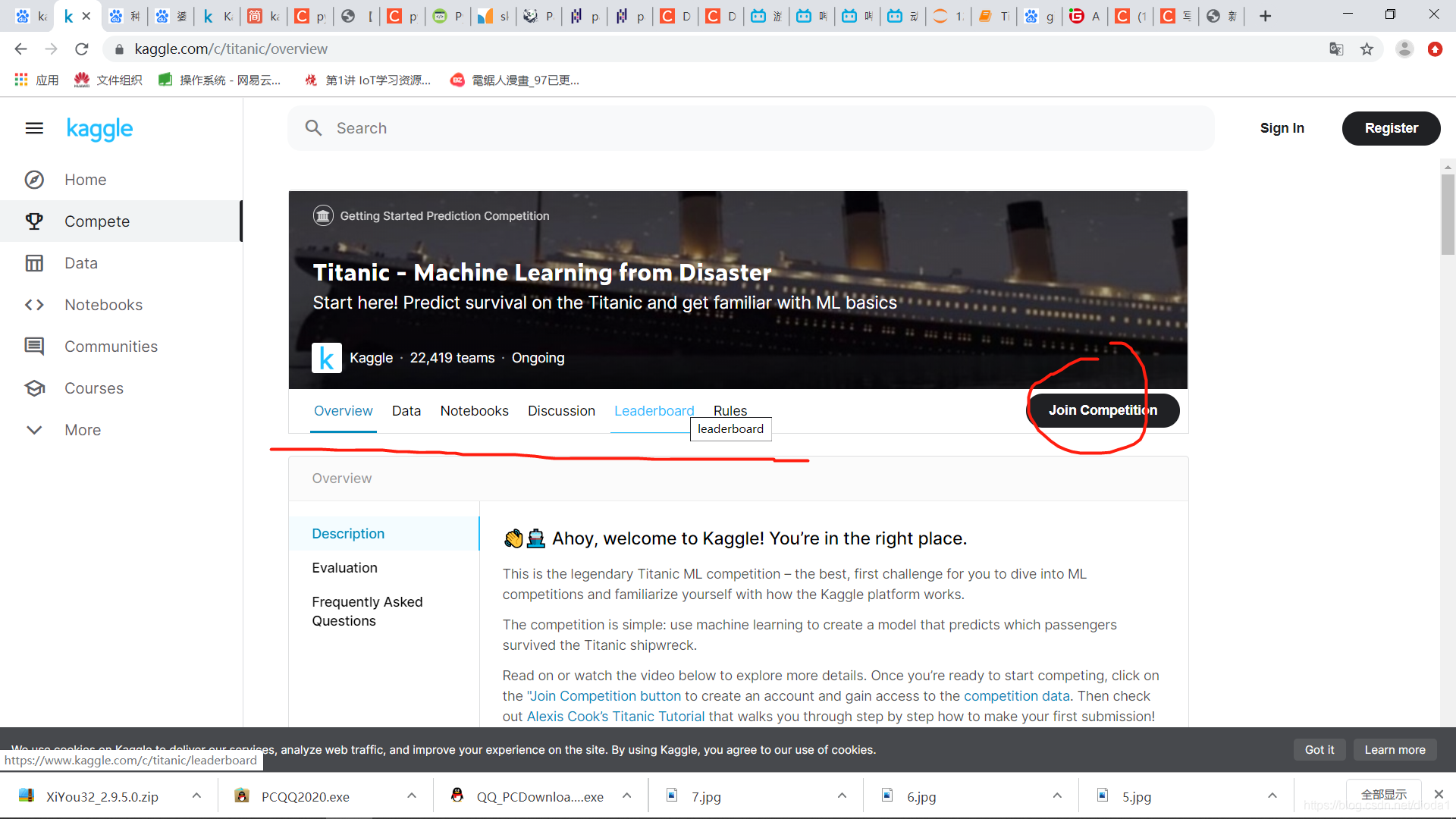
其中右上角的join competition可以參加比賽,左側紅線上的欄目分別是:
overview 對于該專案的一些大致介紹
data 該專案的資料
notebook 前人的筆記,也是你提升的重要渠道
discussion 關于該專案的一些討論,另一條提升你模型的途徑
leaderboard 主要是一個各隊伍結果的排行榜
rules 一些規矩
其中,對于初學者來說,要完整實作一遍流程,最重要的是我加粗的兩條,即overview與data,
2.3了解專案
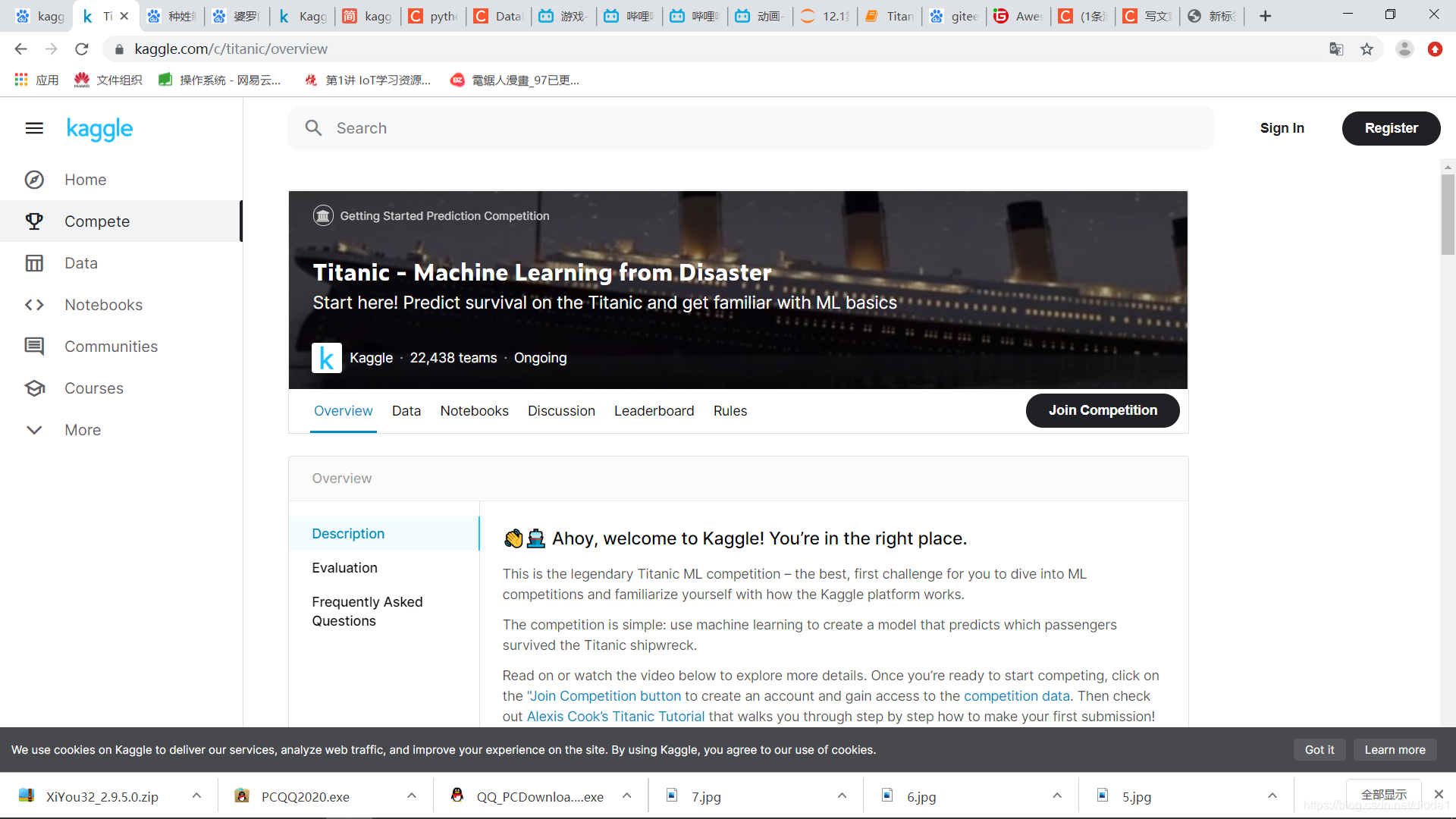
你可以去overview上仔細查看這個專案,或者一句話總結這個專案:通過乘客身上諸如性別、年齡等多個特征來對乘客是否在泰坦尼克事件中存活做出預測
3. 資料匯入與預處理
資料匯入
進入data欄準備下載資料:鏈接
在上述頁面可以看到資料概覽,向下翻就能找到資料下載的方法,如圖:
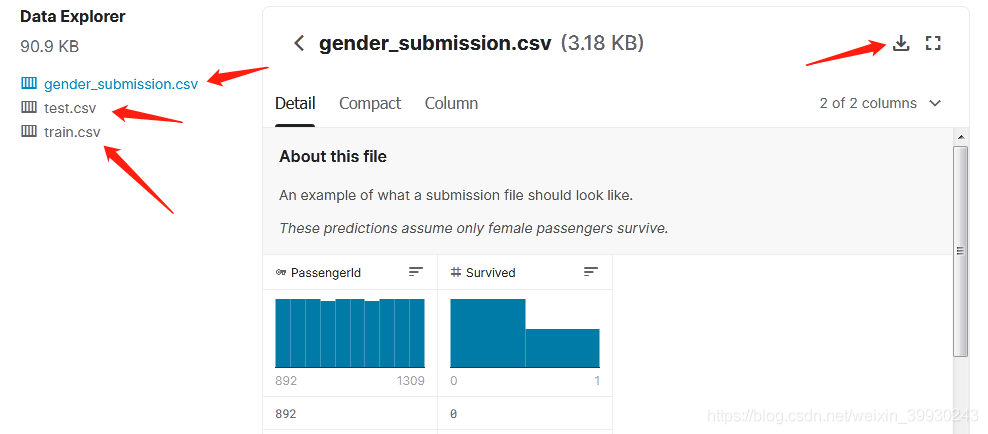 這里的資料略有不同,可以看到三個檔案:
這里的資料略有不同,可以看到三個檔案:
第一個檔案為我們提供了最后提交模型預測結果檔案的模板
test.csv檔案給出了不包含標簽列的測驗資料(也就是說不包含Survival資料)
train.csv檔案就是我們用來訓練模型的資料,
登錄賬號,就可以下載了(可能會需要科學手段)
加載好資料后,就正式開始我們的kaggle之旅!!
在對資料有了初步認識之后,開始進行預處理:
資料預處理
我們直接選定[‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’]等指標來對存活結果進行預測(你當然可以做更多的作業來選擇合適的特征,這里為了簡單直接選定特征),然后,我們這里將test資料與train資料都進行處理:用0和1代替男女,用均值填充缺失資料,
#讀取訓練資料集
df_total = pd.read_csv('train.csv', index_col='PassengerId')
#選取指定特征
df_total = df_total[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']]
#one-hot處理
df_total['Sex'] = df_total['Sex'].map({'male': 0, 'female': 1})
df_total = df_total.dropna()
#劃分資料和標簽
X = df_total.drop('Survived', axis=1)
y = df_total['Survived']
#讀取測驗資料
X_test = pd.read_csv('test.csv', index_col='PassengerId')
X_test = X_test[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
X_test['Sex'] = X_test['Sex'].map({'male': 0, 'female': 1})
#用列均值填充缺失資料
X_test['Age'] = X_test['Age'].fillna(X_test['Age'].mean())
X_test['Fare'] = X_test['Fare'].fillna(X_test['Fare'].mean())
4. 訓練決策樹模型
接下來資料處理以后我們使用處理好的訓練資料集來對模型進行訓練,判斷船上的游客是否能夠生存,我們使用的是決策樹和邏輯回歸模型,
4.1決策樹模型
決策樹(Decision Tree)是一種基本的分類與回歸方法,當決策樹用于分類時稱為分類樹,用于回歸時稱為回歸樹,決策樹模型呈現樹形結構,在分類問題中,表示基于特征對實體進行分類的程序,它是定義在特征空間與類空間上的條件概率分布,決策樹節點目前主要的劃分方法主要是通過資訊增益,資訊增益比或者基尼指數,本篇文章將使用基尼指數來對模型進行訓練,
4.2python實作決策樹
在python中,我們可以呼叫sklearn包來實作決策樹模型的訓練,代碼如下
#決策樹
from sklearn import tree
model = tree.DecisionTreeClassifier(random_state=30)
model.fit(X, y)
模型構建好后,我們針對測驗集進行預測,代碼如下
y_predict = model.predict(X_test)
5. 提交結果
我們要將模型對測驗集的預測結果提交到kaggle,看看我們的模型效果如何~
(同時還能看到自己在官方的排名)
通過下面的代碼來自動生成提交檔案:
#根據模板生成提交檔案
submit = pd.concat([pd.Series(range(892,1310)),pd.Series(y_predict)], axis=1)
submit.columns = ['PassengerId', 'Survived']
submit = submit.set_index('PassengerId')
submit.to_csv('my_submition.csv')
點擊下圖的紅框進入提交頁面:
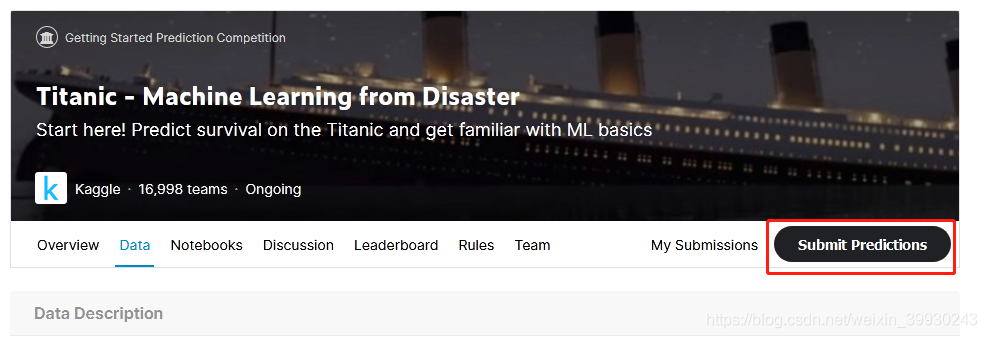 提交頁面長這樣:
提交頁面長這樣:
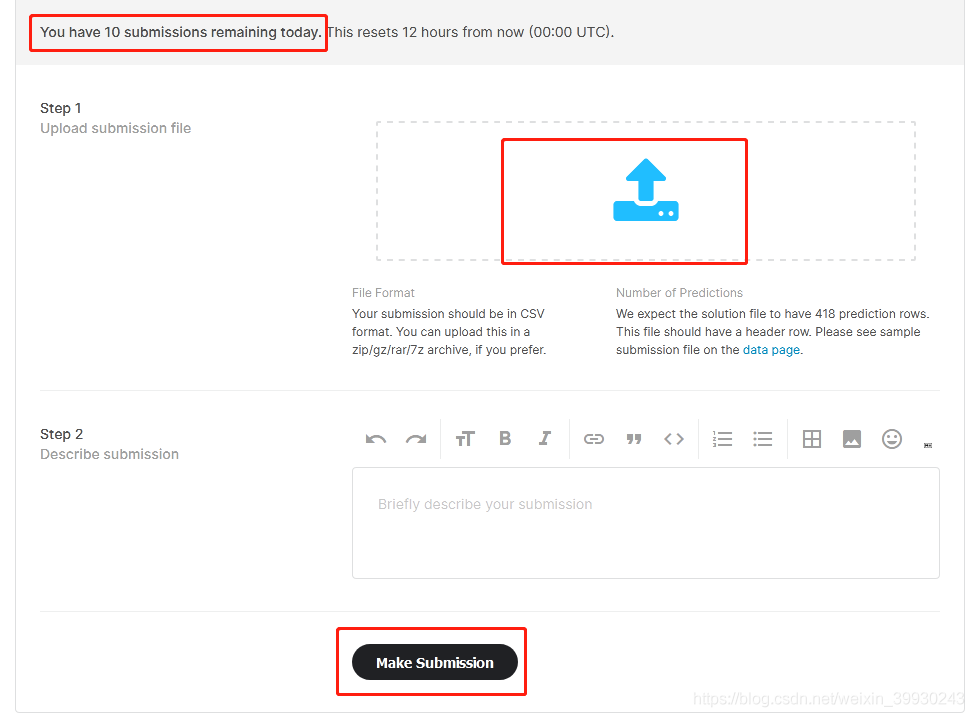
可以看到自己當天還剩余多少提交次數
點擊上傳的空白處,選擇本地檔案,即可將結果上傳(需要科學上網才能順利上傳)
檔案上傳成功后點擊最下面的Make Submission即可
 接下來就要到最激動人心的時刻啦!!
接下來就要到最激動人心的時刻啦!!
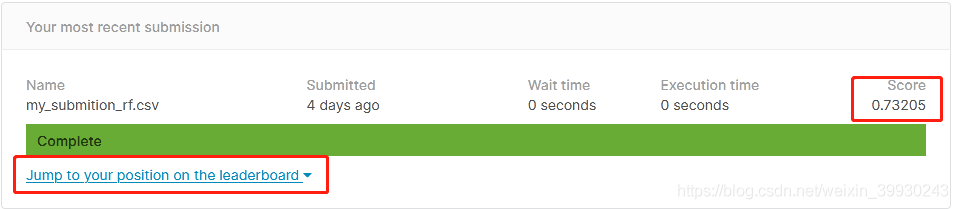
官網會自動給出你提交的結果的準確率:
score給出了準確率,我們這里的未經調參的決策樹演算法得到了73%左右的準確率~差強人意
點擊下面的一排藍字可以看到在所有提交者中的排名,
**好啦,本次初探kaggle競賽就進行到這里,相信你對kaggle競賽的基本流程有了一定的了解!
快去開始你的第一次kaggle競賽吧!
有幫助的話,幫忙點個贊再走~~
**
6.完整原始碼
import numpy as np
import pandas as pd
df = pd.read_csv('train.csv', index_col='PassengerId')
df = df[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']]
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
df = df.dropna()
X = df.drop('Survived', axis=1)
y = df['Survived']
X_test = pd.read_csv('test.csv', index_col='PassengerId')
X_test = X_test[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
X_test['Sex'] = X_test['Sex'].map({'male': 0, 'female': 1})
X_test['Age'] = X_test['Age'].fillna(X_test['Age'].mean())
X_test['Fare'] = X_test['Fare'].fillna(X_test['Fare'].mean())
#決策樹
from sklearn import tree
model = tree.DecisionTreeClassifier(random_state=30)
model.fit(X, y)
y_predict = model.predict(X_test)
submit = pd.concat([pd.Series(range(892,1310)),pd.Series(y_predict)], axis=1)
submit.columns = ['PassengerId', 'Survived']
submit = submit.set_index('PassengerId')
submit.to_csv('my_submition.csv')
7.可以改進的地方
本文重心在于速度完成一次完整的kaggle競賽體驗,而不在于獲得一次最好的結果,故可以改進的地方有很多,現粗略總結如下:
1,缺少對資料的總體分析與可視化
2,對于具體特征選取,沒有做進一步的分析,而是直接給出了選擇
3,資料清洗過于簡單暴力,沒有做深一步的研究
4,模型使用了簡單的決策樹,沒有對引數進行優化,沒有嘗試更多的模型
5,缺少可視化,專案可讀性不夠
8.貢獻者介紹
我們是深大應用統計的在讀研究生,此前在課堂和論文中都學習過機器學習知識,于是便想把我們所得記錄下來,同時在實踐中鍛煉自己,本文只是一個簡單的開始,接下來我們會做更多的內容,除了在評論區交流,你還可以通過如下途徑聯系我們:
舒適黃狗,491447816@qq.com
ZX,2686676053@qq.com
yzh, 554653501@qq.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/238040.html
標籤:其他
下一篇:系統分析師考試總結