今天試了試pycaret這個機器學習庫,感覺簡直是個建模寶藏啊,從資料預處理、特征工程、建模、自動優化、模型部署,所有功能基本全部覆寫,它的原理大概就是封裝了Sklearn,XGBoost,LightGBM,Spacy,Shap,PyOD,Gensim,WordCloud等工具,幾乎包括機器學習所有的使用場景和方法(不含深度學習),例外檢測Anomaly Detection,關聯規則Association Rules,分類Classification,回歸Regression,聚類Clustering,自然語言處理NLP等,其中支持最豐富的還是分類和回歸,
我覺得做一些單機版的機器學習建模用pycaret這樣的工具就很方便了,最吸引我的其實是它的上層的API介面設計,總之,強烈推薦初學者使用,
比方說注冊資料叫做setup:
eg1 = setup(data, target = 'charges', silent=True,
categorical_features=['sex', 'smoker', 'region', 'children'],
numeric_features=['age', 'bmi'])建模直接叫做create model,演算法名字作為變數傳進去,這樣的話擴展性非常強了,以后增加演算法的話這個呼叫方式也不用改:
xgboost = create_model('xgboost')還有一個比較有意思的是它封裝的自動調參功能,直接就叫做tune_model:
xgboost = tune_model('xgboost')
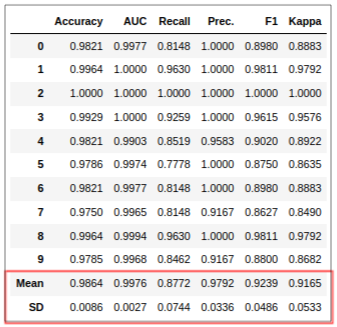
會把調參后的一些結果直接列出來,
還有一個比較牛逼的點是模型融合,直接把要融合的模型放到串列里,然后blend_model就好了,
xgboost=blend_models(estimator_list=[classification_dt, classification_xgb])
最后想比較多個模型的性能,直接輸入compare_models:
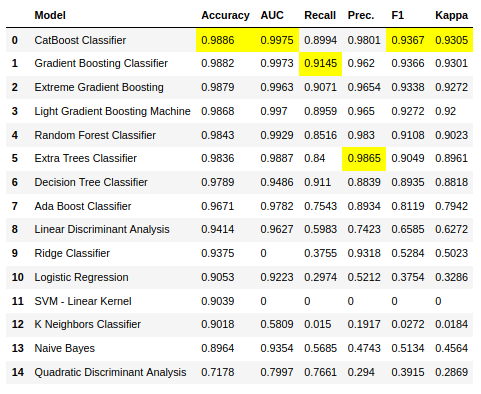
是不是感覺很方便,搞一個全鏈路訓練加預測估計就10行代碼就搞定了,
鏈接奉上:https://github.com/pycaret/pycaret
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/239157.html
標籤:AI
上一篇:Kubernetes — 在 OpenStack 上使用 kubeadm 部署高可用集群
下一篇:SQL 表值函式之字串拆分