前言:
伴隨著音視頻技術高速發展,直播行業異軍突起,在社交、娛樂、電商、教育、醫療等領域高歌猛進,當下,5G和AI時代已至,音視頻技術已經上升到一個全新的高度,新場景、新應用、新標準也必將出現,anyRTC緊跟時代的步伐,成立AI實驗室,將自身的平臺技術跟AI深度結合,全新架構了服務端和客戶端音視頻引擎-下一代音視頻SDK以及下一代音視頻引擎,那么全新的AI音視頻實驗室有哪些核心技術?又能在哪些場景下提供更優質的音視頻服務呢?下面為大家簡單的介紹一下;
點擊查看:anyRTC-AI實驗室
本次文章將由以下幾個方面展開:
- 音視頻目前的發展趨勢
- anyRTC成立AI實驗室的初衷
- anyRTC AI實驗室的功能
- 音視頻功能場景化實施
- 總結
一、音視頻目前的發展趨勢
在年初的時候,我們經歷了一場全球性的“戰役”,但我們仍然心存希望,認為很快就會過去,而在接近年底的時候,我們依然在祈禱著疫情能夠盡快結束,以便恢復我們往常的生活,事實上每年都會有大事件發生,但卻從未像2020年這般貫穿始終過,可以說我們經歷了絕對不平凡的一年,
因為今年疫情的影響所有的辦公、教育、娛樂、都轉戰到了線上,學生們開始在網上上課,大人們開始在家辦公,會議變成了視頻會議,面試也變成了線上面試,正是因為如此所以“音視頻”這三個字也讓廣大的群眾熟悉了起來,
而且隨著5G的來臨,傳輸更高速、資費更便宜、耗電發熱更低,會徹底改變即時通訊的“帶寬”,帶來高可靠超低延時的通訊體驗,這讓視頻這種社交媒介有了具備普及的基礎要求,也給超高清視頻和虛擬現實技術的應用鋪平了道路,
隨著音視頻市場的蓬勃發展,anyRTC也在不斷提升自己在音視頻領域的核心競爭力,在5G和AI雙重的發展下,anyRTC提出了anyRTC音視頻實驗室,目的是為了讓音視頻的交付更加簡單,下面為大家簡單介紹一下;
二、anyRTC成立AI實驗室的初衷
如今的音視頻需求,已經不再是實作功能即可,更多的是要求是服務質量、個性化需求,傳統的技術已經很難有大的優化空間,所以anyRTC在2019年初成立了AI實驗室,專門負責AI在音視頻中的應用,我們從采集(美顏濾鏡)到傳輸(智能傳輸)以及到渲染(影像增強、音頻降噪)深度結合了AI技術,我們時刻秉承著“讓音頻交付更簡單”的理念,造福開發者,為開發者提供更加便捷、易用、專業的音視頻服務,
三、anyRTC AI實驗室的功能
anyRTC AI實驗室包含以下3個模塊:SD-RTN模塊、音頻處理模塊、視頻處理模塊,下面就分別介紹一下3個模塊的功能點和優勢:
1、SD-RTN全球實時傳輸網
SD-RTN(Software Defined Real-time Network) 軟體定義實時網,專為雙向實時音視頻互動而設計,超高清音視頻的傳輸需要穩定的網路和充足的帶寬,任何的網路波動都會對音視頻質量造成影響,在實時通訊的場景下,如何高速地檢測網路狀態并根據網路狀態制定合適的抗性和傳輸策略,一直是學術界和業界的難題,我們的團隊具有豐富的學術界和業界經驗,為此提供了能適應各種復雜場景的高品質高可靠性的解決方案,

功能點
- 擁塞控制
基于延遲和丟包擁塞控制演算法,結合我們豐富的網路狀態資料庫,提出了新的實時擁塞控制演算法,在不同網路場景下都能迅速給出可靠的帶寬預測,
- 損傷抗性
互聯網網路不穩定因素有很多,我們的智能抗性演算法可以在極低的延時下抵御住各種突發性的網路波動及網路損傷,將有限資源的能力最大化,確保優質的播放體驗,
- QoS/QoE最優化
在網路帶寬受限的情況下,清晰度、流暢性和延時不可兼得,我們根據應用的背景關系和網路狀態,實時自動做出最優的取舍,讓最終用戶能獲得最好的體驗,
- 多人通訊流控
多人通訊環境,既要保證重要通話的清晰度,又要兼顧他人的體驗,我們使用了兩套策略:在決策空間有限的情況下使用人工智能進行流控;在更復雜的場景下提供基于主觀體驗調整策略,
- 網路度量
網路策略的制定離不開現網大量資料支持,我們有豐富的去隱私資料集用來提取和學習網路的狀態,可以在離線場景下復現差網狀態,與在線場景下迅速判斷網路狀態,
- 動態路由
網路狀態變化多端,跨運營商、跨區域、跨國等多重復雜網路環境,需要實時對網路狀況進行檢測和調整;基于實時狀態資料進行分析和計算,獲取最優的傳輸線路,
SD-RTN的優勢
| 高延時傳輸方案 | SD-RTN |
|---|---|
| 端到端單向延時 > 1s | 端到端單向延時 < 400ms |
| 基于 TCP 協議,延時不可控 | 基于 UDP 協議,延時可控 |
| 抗丟包能力差,在丟包 2% 時明顯卡頓,達到 30% 可能斷開連接 | 通過定制具有超強抗丟包能力,80% 丟包率也可通話 |
| 層層快取,就近下發 | 基于自定義路由,選擇最優傳輸路徑,實時端到端傳輸 |
| 適用于單向直播、視頻點播等無互動需求場景 | 適用于互動課堂、互動直播、音視頻社交、游戲對講等對實時互動高需求場景 |
SD-RTN是一種可承載任何點到點(peer-to-peer)實時資料傳輸需求的業務架構:只要呼叫開放的API,無論是實時視頻(會議、教育、直播、社交、監控、VR)、檔案傳輸(短視頻、辦公)還是高速資料同步(游戲、AI、IOT、物聯網)都可以很方便的接入SD-RTN的實時資料傳輸云服務,
2、音頻處理模塊
核心技術效果對應與試聽
智能語音增強解決方案,集成了AI智能降噪、回聲消除、混響消除、自動增益等核心技術,該方案創新性地應用深度學習技術,實時分離語音和背景噪聲,清晰提取人聲,有效消除環境中的各類噪音,讓用戶暢享更清晰高效的在線音視頻通話體驗,
anyRTC自19年初成立AI實驗室以來,經過長達一年多的時間,收集公開語音資料資源,以及第三方提供的資料和自己的內部會議來訓練AI模型,噪音抑制功能將分析用戶的音頻輸入,并使用經過特殊訓練的深度神經網路來減少背景聲音,例如鍵盤的敲擊聲、風扇產生的噪音等,目前我們anyRTC已經配備了全套工具和環境,我們現在已經自己采集了很多資料集,并且應用到了我們AI演算法中,下面就是我們anyRTC在AI音頻模型中取得的成就:
-
智能降噪:基于計算聽覺場景分析理論,應用深度學習技術,能夠在不依賴任何硬體的基礎上,實作將人聲和噪音分離,有效抑制環境中的各種噪音,
-
DHS深度嘯叫抑制:基于深度學習技術,智能阻斷聲反饋回路,抑制嘯叫產生,有效解決實時游戲、在線會議等多人實時通話場景下嘯叫問題,
點擊視頻查看看效果
智能降噪演示場景
嘯叫抑制演示場景
anyRTC AI 降噪技術規劃的關鍵策略包括音頻通信核心體驗、聲音場景分類和處理、音頻痛點難點問題及差異化體驗,最終目標則是提升語音可懂度、自然度、舒適度,
3、視頻處理模塊
核心技術
最高支持 1080P,解析度、碼率可自由切換,融合多種領先的視頻編碼處理演算法,畫質更好、碼率更低,支持移動端實時超分,實作低解析度視頻到高解析度視頻的實時重建,全面提升源視頻畫質和解析度,AI 輔助功能:支持實時暗光增強演算法,即使在較暗的環境下,也能提供清晰、明亮的影像,

anyRTC在其他領域也有所涉及:AI 智能傳輸,超解析度,智能插幀,影像增強等,
- AI智能傳輸
由于網路傳輸線路上有丟包,接收的資料有失真,所以 AI 智能傳輸被用來做演算法補償,提升傳輸質量,
- 超解析度
實時通信視頻在接收端提高原有影像的解析度,得到高解析度的影像,該功能有效減少了網路傳輸帶寬,為移動端為用戶帶來極致視頻體驗,
- 智能插幀
智能插幀是通過運動估算,計算出畫面中物體的運動軌跡,生成新的幀來進行插補,可以將普通常見的30fps進行智能插幀計算,可以獲得60fps的順滑視頻,讓眼睛看到的自然形象更為自然,
- 影像增強
圖象增強是數字圖象處理常用的技術之一,圖象增強技術的目的是為了改進圖象的質量,以達到賞心悅目的效果,通常要完成的作業是除去圖象中的噪聲,使邊緣清晰以及突出圖象中的某些性質等,
四、音視頻功能場景化實施
以上就是anyRTC-AI實驗室的功能介紹,最后一起來看一下這些功能在實際場景中的應用,畢竟再好的技術也是要放在最適合他使用的場景中才能發揮最大的效果,
1、在線合唱
在線合唱與以往的合唱不同,以往的合唱都是用戶開啟合唱功能之后先一個人和伴奏演唱,完成之后上傳,其他用戶可以使用這個已經有人聲的伴奏再唱一遍,實作“合唱”,而我們要做到的合唱是兩位用戶同時在線唱歌,合唱的伴奏是同時通過網路發送給兩位歌手的,而且兩位歌手在演唱的同時可以聽到彼此的聲音,
- 第一,合唱場景下對延遲要求是很高的,所以整體的低延遲、QoS 的能力在這個場景里面得到了很明確的體現,包括可以明確知道這個效果好還是不好;
- 第二,對于音質的要求很高,大家聽音樂肯定不希望語音效果是很差的,這是不能接受的,所以我們的高音質能力,包括 AI降噪能力都在這個場景中得到了應用和實踐;
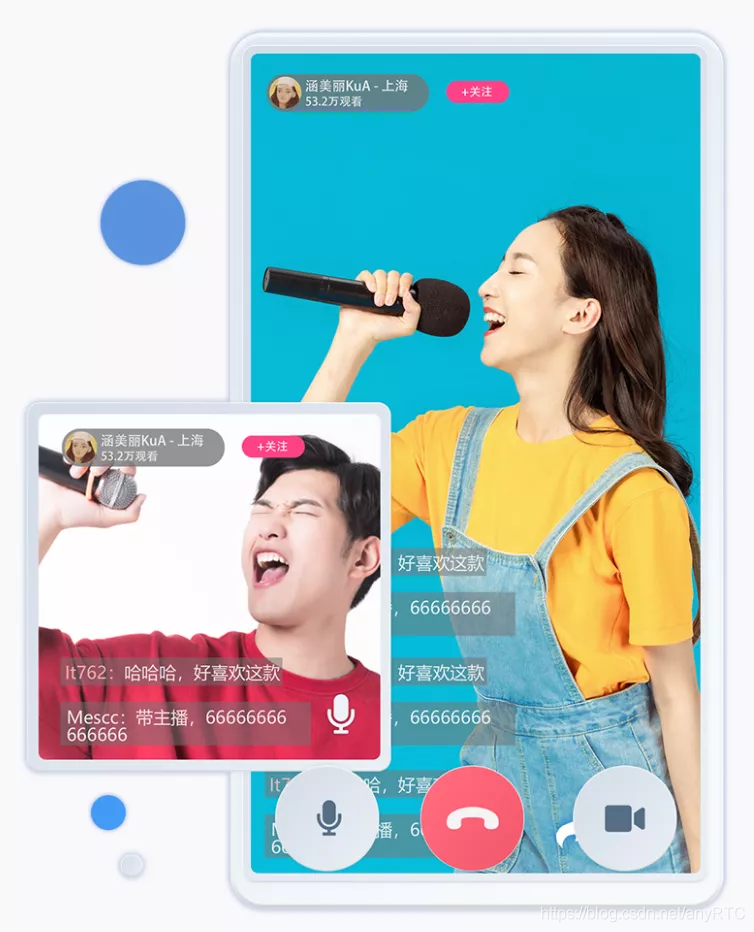
2、主播PK
主播PK就是一個主播在直播時,可以對另一個直播間的主播發起挑戰,一旦挑戰接受,讓兩個直播間的主播就開始進行連麥互動,直播界面一分為二,同時顯示兩個主播的畫面,兩方粉絲也會進入到同一個直播間中,
一般直播場景里,同一個直播頻道,或者說同一個直播間里的主播與用戶是可以進行連麥互動的,而主播之間的PK互動,其實是一種跨直播間連麥,主播PK經常遇到的問題就是兩個主播之間延遲比較高,會影響到觀眾的觀看體驗,而anyRTC使用的旁路推流模式,可以最高限度的降低延遲,主播端直接推流,減少了傳輸程序中的延遲損耗,
- 該場景對視頻質量的要求比較高,anyRTC新一代自研高清視頻編碼和視頻 AI 超分能力也在這個場景得到充分應用;

3、語音聊天室
語音聊天室屬于多人聊天的一種,通常為6-8人一個頻道,玩家可以自由上麥發言,也可以創建子頻道私聊,觀眾人數不限,
語音聊天室適用于多人聊天,狼人殺,語音開黑等場景,
- 在語音聊天的場景中,因為大多數情況下大家都沒有辦法保證在一個安靜的環境的進行聊天,所以 AI
降噪和智能回聲消除的能力就為語音聊天提供了高質量的音頻效果; - QoS 抗弱網和去抖動能力,則保證了聊天室內多人同時上麥后的網路穩定性;
五、總結
anyRTC下一代實時音視頻SDK引擎已深度結合AI,全新架構支持百億級并發,對于anyRTC來說,AI實驗室只是在人工智能領域研究的冰山一角,后續我們會逐步推出更多關于AI技術的應用,挖掘更多的應用場景,為廣大開發者朋友們提供最專業的服務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/239593.html
標籤:其他