最近將huggingface的transformers(v4.0.1)庫中的GPT2模型原始碼詳細學習了一遍,因此將學習程序中,對于GPT2模型原始碼的一些學習筆記記錄在此篇博客之中,以供之后參考,
GPT2模型是OpenAI組織在2018年于GPT模型的基礎上發布的新預訓練模型,其論文原文為 language_models_are_unsupervised_multitask_learners
GPT2模型的預訓練語料庫為超過40G的近8000萬的網頁文本資料,GPT2的預訓練語料庫相較于GPT而言增大了將近10倍,
一、GPT2與GPT的模型結構區別
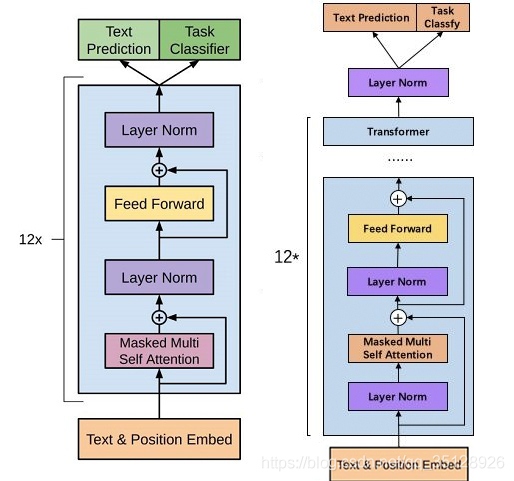
從上方的GPT2與GPT的模型結構對比圖中可以看出,GPT2的模型結構(右)較GPT的模型結構(左)有所改動,在GPT2中的一個Transformer Block層中,第一個LayerNormalization模塊被移到了Msaked-Multi-Self-Attention模塊之前, 第二個LayerNormalization模塊也被移到了Feed-Forward模塊之前; 同時Residual-connection的位置也調整到了Msaked-Multi-Self-Attention模塊與Feed-Forward模塊之后,
接下來,將從transformers庫中的GPT2模型原始碼層面深入理解GPT2模型的結構,
二、GPT2模型原始碼
要理解transformers庫中的GPT2模型原始碼,便要理解其最主要的幾部分,分別為 GPT2LMHeadModel類、GPT2Model類、Block類、MLP類與Attention類,
其中,一個Transformer的Block類中包含了Attention類與MLP類,而在GPT2Model類中又以Block類為基礎構建了12層Block的模型主體結構,
1. GPT2LMHeadModel類、GPT2Model類
GPT2LMHeadModel類為用來進行自回歸預訓練的類,其可以傳入labels張量來計算自回歸交叉熵損失值loss,繼而利用自回歸交叉熵損失值loss來優化整個GPT2模型,
雖然GPT2LMHeadModel類用來進行自回歸預訓練,但其也可在下游任務或其他情景中被使用,此時便不需要為GPT2LMHeadModel類傳入labels張量,
官方給出的一個以呼叫GPT2LMHeadModel類來使用GPT2模型的例子如下所示:
#!/usr/bin/env Python
# coding=utf-8
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
# 初始化GPT2模型的Tokenizer類.
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 初始化GPT2模型, 此處以初始化GPT2LMHeadModel()類的方式呼叫GPT2模型.
model = GPT2LMHeadModel.from_pretrained('gpt2')
# model.config.use_return_dict = None
# print(model.config.use_return_dict)
# GPT模型第一次迭代的輸入的背景關系內容, 將其編碼以序列化.
# 同時, generated也用來存盤GPT2模型所有迭代生成的token索引.
generated = tokenizer.encode("The Manhattan bridge")
# 將序列化后的第一次迭代的背景關系內容轉化為pytorch中的tensor形式.
context = torch.tensor([generated])
# 第一次迭代時還無past_key_values元組.
past_key_values = None
for i in range(30):
'''
此時模型model回傳的output為CausalLMOutputWithPastAndCrossAttentions類,
模型回傳的logits以及past_key_values物件為其中的屬性,
CausalLMOutputWithPastAndCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
cross_attentions=transformer_outputs.cross_attentions,
)
'''
output = model(context, past_key_values=past_key_values)
past_key_values = output.past_key_values
# 此時獲取GPT2模型計算的輸出結果hidden_states張量中第二維度最后一個元素的argmax值, 得出的argmax值即為此次GPT2模型迭代
# 計算生成的下一個token. 注意, 此時若是第一次迭代, 輸出結果hidden_states張量的形狀為(batch_size, sel_len, n_state);
# 此時若是第二次及之后的迭代, 輸出結果hidden_states張量的形狀為(batch_size, 1, n_state), all_head_size=n_state=nx=768.
token = torch.argmax(output.logits[..., -1, :])
# 將本次迭代生成的token的張量變為二維張量, 以作為下一次GPT2模型迭代計算的背景關系context.
context = token.unsqueeze(0)
# 將本次迭代計算生成的token的序列索引變為串列存入generated
generated += [token.tolist()]
# 將generated中所有的token的索引轉化為token字符.
sequence = tokenizer.decode(generated)
sequence = sequence.split(".")[:-1]
print(sequence)
從上述代碼中可以看出,context即為每次迭代輸入模型中的input_ids張量;past_key_values為GPT2模型中12層Block模塊計算后得到的存盤12個present張量的presents元組,每一個present張量存盤著past_key張量與這次迭代的key張量合并后的新key張量、以及past_value張量與這次迭代的value張量合并后的新value張量,一個present張量的形狀為(2, batch_size, num_head, sql_len+1, head_features),其中key張量、past_key張量、value張量、past_value張量、present張量皆是在Attention模塊中被計算與使用的,
past_key_values機制是GPT2中最重要的機制,其可以防止模型在文本生成任務中重新計算上一次迭代中已經計算好的背景關系的值,大大提高了模型在文本生成任務中的計算效率,但要特別注意的是,在第一次迭代時由于不存在上一次迭代回傳的past_key_values值,因此第一次迭代時past_key_values值為None,
因此GPT2LMHeadModel類不僅可以用來進行自回歸預訓練(傳入labels),也可以用來進行下游任務如文本生成等,GPT2原始碼中GPT2LMHeadModel類部分的代碼如下所示:
class GPT2LMHeadModel(GPT2PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.masked_bias", r"lm_head\.weight"]
def __init__(self, config):
super().__init__(config)
# 初始化GPT2Model(config)類.
self.transformer = GPT2Model(config)
# self.lm_head為將GPT2Model(config)計算輸出的hidden_states張量的最后一個維度由768維(config.n_embd)投影為
# 詞典大小維度(config.vocab_size)的輸出層, 此時hidden_states張量的形狀將會由(batch_size, 1, n_embed)投影變為
# lm_logits張量的(batch_size, 1, vocab_size).
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# 重新初始化權重矩陣.
self.init_weights()
def get_output_embeddings(self):
return self.lm_head
def prepare_inputs_for_generation(self, input_ids, past=None, **kwargs):
token_type_ids = kwargs.get("token_type_ids", None)
# only last token for inputs_ids if past is defined in kwargs
if past:
input_ids = input_ids[:, -1].unsqueeze(-1)
if token_type_ids is not None:
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
attention_mask = kwargs.get("attention_mask", None)
position_ids = kwargs.get("position_ids", None)
if attention_mask is not None and position_ids is None:
# create position_ids on the fly for batch generation
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
if past:
position_ids = position_ids[:, -1].unsqueeze(-1)
else:
position_ids = None
return {
"input_ids": input_ids,
"past_key_values": past,
"use_cache": kwargs.get("use_cache"),
"position_ids": position_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
@add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint="gpt2",
output_type=CausalLMOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
past_key_values=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
``labels = input_ids`` Indices are selected in ``[-100, 0, ..., config.vocab_size]`` All labels set to
``-100`` are ignored (masked), the loss is only computed for labels in ``[0, ..., config.vocab_size]``
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# 此時回傳的transformer_outputs中為:
# <1> 第一個值為GPT2模型中經過12層Block模塊計算后得到的最終hidden_states張量,
# 形狀為(batch_size, 1, n_state), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為GPT2模型中12層Block模塊計算后得到的存盤12個present張量的presents元組, 每一個present張量存盤著
# past_key張量與這次迭代的key張量合并后的新key張量, 以及past_value張量與這次迭代的value張量合并后的新value張量,
# 一個present張量形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_hidden_states為True, 則第三個值為GPT2模型中12層Block模塊計算后得到的存盤12個隱藏狀態張量hidden_states
# 的all_hidden_states元組.
# <4> 若output_attentions為True, 則第四個值為GPT2模型中12層Block模塊計算后得到的存盤12個注意力分數張量w
# 的all_self_attentions元組.
# <5> 若此時進行了Cross Attention計算, 則第五個值為GPT2模型中12層Block模塊計算后得到的存盤12個交叉注意力分數張量
# cross_attention的all_cross_attentions元組,
# 其中每個交叉注意力分數張量cross_attention形狀為(batch_size, num_head, 1, enc_seq_len).
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
# self.lm_head()輸出層將GPT2Model(config)計算輸出的hidden_states張量的最后一個維度由768維(config.n_embd)
# 投影為詞典大小維度(config.vocab_size)的輸出層, 此時hidden_states張量的形狀將會由(batch_size, 1, n_embed)投影變為
# lm_logits張量的(batch_size, 1, vocab_size).
lm_logits = self.lm_head(hidden_states)
loss = None
# 若此時labels也輸入進了GPT2LMHeadModel()類中, 則此時會使用自回歸的方式計算交叉熵損失,
# 即此時的shift_logits為將GPT2Model(config)計算輸出的hidden_states張量的最后一個維度由768維(config.n_embd)投影為
# 詞典大小維度(config.vocab_size)所得到的lm_logits張量的切片lm_logits[..., :-1, :].contiguous(),即取(1, n-1)的lm_logits值;
# 此時的shift_labels為將輸入的labels張量的切片labels[..., 1:].contiguous(), 即取(2, n)的label值;
# 因此利用(1, n-1)的lm_logits值與(2, n)的label值即可計算此時自回歸預訓練的交叉熵損失值.
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
# <1> 若loss不為None, 則代表此時輸入了labels張量, 進行了自回歸的交叉熵損失計算, 則此時第一個值為
# 自回歸交叉熵損失loss.
# <2> 第二個值將GPT2Model(config)計算輸出的hidden_states張量的最后一個維度由768維(config.n_embd)投影為
# 詞典大小維度(config.vocab_size)的lm_logits張量, 其形狀為(batch_size, 1, vocab_size).
# <3> 第三個值為GPT2模型中12層Block模塊計算后得到的存盤12個present張量的presents元組, 每一個present張量存盤著
# past_key張量與這次迭代的key張量合并后的新key張量, 以及past_value張量與這次迭代的value張量合并后的新value張量,
# 一個present張量形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <4> 若output_hidden_states為True, 則第四個值為GPT2模型中12層Block模塊計算后得到的存盤12個隱藏狀態張量hidden_states
# 的all_hidden_states元組.
# <5> 若output_attentions為True, 則第五個值為GPT2模型中12層Block模塊計算后得到的存盤12個注意力分數張量w
# 的all_self_attentions元組.
# <6> 若此時進行了Cross Attention計算, 則第六個值為GPT2模型中12層Block模塊計算后得到的存盤12個交叉注意力分數張量
# cross_attention的all_cross_attentions元組,
# 其中每個交叉注意力分數張量cross_attention形狀為(batch_size, num_head, 1, enc_seq_len).
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithPastAndCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
cross_attentions=transformer_outputs.cross_attentions,
)
GPT2LMHeadModel類中的代碼程序詳細說明可參考上方GPT2LMHeadModel原始碼中的注釋部分,
從GPT2LMHeadModel類的代碼中可以看出,其主體為呼叫GPT2Model類以及一個輸出層self.lm_head,GPT2Model類用來進行12層Block的計算,而輸出層self.lm_head則將GPT2Model類輸出的最后一個Block層的隱藏狀態hidden_states張量的最后一個維度由768維(config.n_embd)投影為詞典大小(config.vocab_size),hidden_states張量經過輸出層投影后即為lm_logits張量,
當使用GPT2LMHeadModel類來進行自回歸預訓練時,其可以傳入labels張量,當GPT2LMHeadModel類中使用GPT2Model類與輸出層self.lm_head計算得出了最終的lm_logits值時,lm_logits張量便可以與傳入的labels張量利用自回歸的方式 (即取(1, n-1)的lm_logits值與(2, n)的label值) 來計算自回歸交叉熵損失值loss,自回歸交叉熵損失值loss便可以用來反向傳播計算梯度,最終優化整個GPT2模型,
需要注意的是此時代碼中的config為transformers庫中的configuration_gpt2模塊中的GPT2Config類,GPT2Config類中保存了GPT2模型中的各種超引數,若在使用GPT2模型時需要修改某一超引數,則只需在傳入GPT2模型中的config(GPT2Config類)中修改對應超引數即可,
GPT2Model類的代碼如下所示:
class GPT2Model(GPT2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.wte = nn.Embedding(config.vocab_size, config.n_embd)
self.wpe = nn.Embedding(config.n_positions, config.n_embd)
self.drop = nn.Dropout(config.embd_pdrop)
self.h = nn.ModuleList([Block(config.n_ctx, config, scale=True) for _ in range(config.n_layer)])
self.ln_f = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
self.init_weights()
def get_input_embeddings(self):
return self.wte
def set_input_embeddings(self, new_embeddings):
self.wte = new_embeddings
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
"""
for layer, heads in heads_to_prune.items():
self.h[layer].attn.prune_heads(heads)
@add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint="gpt2",
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
past_key_values=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# input_ids與inputs_embeds只能輸入一個,有input_ids變只需將input_ids輸入嵌入層即可變為類似inputs_embeds的張量,
# 有inputs_embeds變不需要input_ids
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
# 下方是確保輸入的input_ids、token_type_ids、position_ids等張量的形狀為正確的樣式:
# <1> 若為模型第一次迭代, 則此時input_ids、token_type_ids、position_ids等張量的正確形狀為 (batch_size, seq_len),
# <2> 若為模型第二次及之后的迭代, 則此時input_ids、token_type_ids、position_ids等張量的正確形狀為 (batch_size, 1).
# 最后, 將輸入的input_ids、token_type_ids、position_ids等張量的形狀保存到input_shape中.
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
batch_size = input_ids.shape[0]
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
batch_size = inputs_embeds.shape[0]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if token_type_ids is not None:
token_type_ids = token_type_ids.view(-1, input_shape[-1])
if position_ids is not None:
position_ids = position_ids.view(-1, input_shape[-1])
if past_key_values is None:
past_length = 0
# 若此時為GPT2模型第一次迭代, 則不存在上一次迭代回傳的past_key_values串列(包含12個present的串列,
# 也就是代碼中的presents串列), 則此時past_key_values串列為一個包含12個None值的串列.
past_key_values = [None] * len(self.h)
else:
past_length = past_key_values[0][0].size(-2)
if position_ids is None:
device = input_ids.device if input_ids is not None else inputs_embeds.device
'''<1> GPT2Model第一次迭代時輸入GPT2Model的forward()函式中的past_key_values引數為None, 此時past_length為0,
input_shape[-1] + past_length就等于第一次迭代時輸入的文本編碼(input_ids)的seq_len維度本身,
此時創建的position_ids張量形狀為(batch_size, seq_len).
<2> 若為GPT2Mode第二次及之后的迭代時, 此時past_length為上一次迭代時記錄保存下來的past_key_values中
張量的seq_len維度, 而input_shape[-1] + past_length則等于seq_len + 1, 因為在第二次及之后的迭代中,
輸入的文本編碼(input_ids)的seq_len維度本身為1,即第二次及之后的迭代中每次只輸入一個字的文本編碼,
此時創建的position_ids張量形狀為(batch_size, 1).'''
position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
# Attention mask.
# attention_mask張量為注意力遮罩張量, 其讓填充特殊符[PAD]處的注意力分數極小,其embedding嵌入值
# 基本不會在多頭注意力聚合操作中被獲取到.
if attention_mask is not None:
assert batch_size > 0, "batch_size has to be defined and > 0"
attention_mask = attention_mask.view(batch_size, -1)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask = attention_mask[:, None, None, :]
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
attention_mask = (1.0 - attention_mask) * -10000.0
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length],
# 若此時有從編碼器encoder中傳入的編碼器隱藏狀態encoder_hidden_states, 則獲取編碼器隱藏狀態encoder_hidden_states
# 的形狀(encoder_batch_size, encoder_sequence_length), 同時定義編碼器隱藏狀態對應的attention_mask張量(即encoder_attention_mask).
if self.config.add_cross_attention and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# head_mask has shape n_layer x batch x n_heads x N x N
# prune_heads()可結合 https://github.com/huggingface/transformers/issues/850 理解.
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
# 將input_ids、token_type_ids、position_ids等張量輸入嵌入層self.wte()、 self.wpe()中之后獲取其嵌入形式張量
# inputs_embeds、position_embeds與token_type_embeds.
if inputs_embeds is None:
inputs_embeds = self.wte(input_ids)
position_embeds = self.wpe(position_ids)
hidden_states = inputs_embeds + position_embeds
if token_type_ids is not None:
token_type_embeds = self.wte(token_type_ids)
hidden_states = hidden_states + token_type_embeds
'''<1> GPT2Model第一次迭代時輸入GPT2Model的forward()函式中的past_key_values引數為None, 此時past_length為0,
此時hidden_states張量形狀為(batch_size, sel_len, n_embd),config的GPT2Config()類中n_emb默認為768.
<2> 若為GPT2Mode第二次及之后的迭代時, 此時past_length為上一次迭代時記錄保存下來的past_key_values中
張量的seq_len維度, 而input_shape[-1] + past_length則等于seq_len + 1, 因為在第二次及之后的迭代中,
輸入的文本編碼(input_ids)的seq_len維度本身為1,即第二次及之后的迭代中每次只輸入一個字的文本編碼,
此時hidden_states張量形狀為(batch_size, 1, n_embd),config的GPT2Config()類中n_emb默認為768.'''
hidden_states = self.drop(hidden_states)
output_shape = input_shape + (hidden_states.size(-1),)
# config對應的GPT2Config()類中的use_cache默認為True.
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
all_hidden_states = () if output_hidden_states else None
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
'''此處past_key_values元組中一共有12個元素(layer_past), 分別對應GPT2模型中的12層Transformer_Block,
每一個layer_past都為模型上一次迭代中每個Transformer_Block保留下來的present張量, 而每個present張量保存著
Transformer_Block中Attention模塊將本次迭代的key張量與上一次迭代中的past_key張量(layer_past[0])合并、
將本次迭代的value張量與上一次迭代中的past_value張量(layer_past[1])合并所得的新的key張量與value張量,
之后保存著本次迭代中12層Transformer_Block每一層中回傳的present張量的presents元組, 便會被作為下一次迭代中
的past_key_values元組輸入進下一次迭代的GPT2模型中,
新的key張量與value張量詳細決議如下:'''
'''第一次迭代時query、key、value張量的seq_len維度處的維度數就為seq_len而不是1, 第二次之后seq_len維度的維度數皆為1.'''
'''<1> 本次迭代中新的key張量
此時需要通過layer_past[0].transpose(-2, -1)操作將past_key張量的形狀變為(batch_size, num_head, head_features, sql_len),
而此時key張量的形狀為(batch_size, num_head, head_features, 1), 這樣在下方就方便將past_key張量與key張量在最后
一個維度(dim=-1)處進行合并, 這樣就將當前token的key部分加入了past_key的seq_len部分, 以方便模型在后面預測新的token,
此時新的key張量的形狀為: (batch_size, num_head, head_features, sql_len+1), new_seq_len為sql_len+1,
<2> 本次迭代中新的value張量
而此時past_value(layer_past[1])不用變形, 其形狀為(batch_size, num_head, sql_len, head_features),
而此時value張量的形狀為(batch_size, num_head, 1, head_features), 這樣在下方就方便將past_value張量與value張量
在倒數第二個維度(dim=-2)處進行合并, 這樣就將當前token的value部分加入了past_value的seq_len部分,
以方便模型在后面預測新的token,
此時新的value張量的形狀為: (batch_size, num_head, sql_len+1, head_features), new_seq_len為sql_len+1,'''
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states.view(*output_shape),)
if getattr(self.config, "gradient_checkpointing", False):
def create_custom_forward(module):
def custom_forward(*inputs):
# checkpointing only works with tuple returns, not with lists
return tuple(output for output in module(*inputs, use_cache, output_attentions))
return custom_forward
outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(block),
hidden_states,
layer_past,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
)
else:
# 此時回傳的outputs串列中的元素為:
# <1> 第一個值為多頭注意力聚合操作結果張量hidden_states輸入前饋MLP層與殘差連接之后得到的hidden_states張量,
# 形狀為(batch_size, 1, n_state), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為上方的present張量, 其存盤著past_key張量與這次迭代的key張量合并后的新key張量, 以及
# past_value張量與這次迭代的value張量合并后的新value張量, 其形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_attentions為True, 則第三個值為attn_outputs串列中的注意力分數張量w.
# <4> 若此時進行了Cross Attention計算, 則第四個值為'交叉多頭注意力計算結果串列cross_attn_outputs'中的
# 交叉注意力分數張量cross_attention, 其形狀為(batch_size, num_head, 1, enc_seq_len).
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
hidden_states, present = outputs[:2]
if use_cache is True:
presents = presents + (present,)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (outputs[3],)
# 將PT2模型中12層Block模塊計算后得到的最終hidden_states張量再輸入進LayerNormalization層中進行計算.
hidden_states = self.ln_f(hidden_states)
hidden_states = hidden_states.view(*output_shape)
# Add last hidden state, 即將上方最后一層Block()回圈結束之后得到的結果隱藏狀態張量hidden_states
# 也添加入元組all_hidden_states中.
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# 此時回傳的元素為:
# <1> 第一個值為GPT2模型中經過12層Block模塊計算后得到的最終hidden_states張量,
# 形狀為(batch_size, 1, n_state), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為GPT2模型中12層Block模塊計算后得到的存盤12個present張量的presents元組, 每一個present張量存盤著
# past_key張量與這次迭代的key張量合并后的新key張量, 以及past_value張量與這次迭代的value張量合并后的新value張量,
# 一個present張量形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_hidden_states為True, 則第三個值為GPT2模型中12層Block模塊計算后得到的存盤12個隱藏狀態張量hidden_states
# 的all_hidden_states元組.
# <4> 若output_attentions為True, 則第四個值為GPT2模型中12層Block模塊計算后得到的存盤12個注意力分數張量w
# 的all_self_attentions元組.
# <5> 若此時進行了Cross Attention計算, 則第五個值為GPT2模型中12層Block模塊計算后得到的存盤12個交叉注意力分數張量
# cross_attention的all_cross_attentions元組,
# 其中每個交叉注意力分數張量cross_attention形狀為(batch_size, num_head, 1, enc_seq_len).
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
GPT2Model類中的代碼程序詳細說明可參考上方GPT2Model原始碼中的注釋部分,
在GPT2Model類中,模型的主體包含了詞嵌入層self.wte、絕對位置嵌入層self.wpe、Dropout層self.drop、包含12個Block模塊的ModuleList層self.h以及最后的LayerNormalization層self.ln_f,
GPT2Model類中,會對輸入的input_ids張量、token_type_ids張量、position_ids張量、attention_mask張量等進行形狀、embedding嵌入等方面的預處理,
input_ids張量、token_type_ids張量、position_ids張量經過嵌入層后變為三維的inputs_embeds張量、position_embeds張量、token_type_embeds張量,這三個張量相加即為一開始輸入GPT2模型中的hidden_states張量,
而attention_mask張量則會擴展為四維張量以便與Attention類中的注意力分數張量w形狀相同直接相加,然而在文本生成任務中一般不會添加填充特殊符[PAD]即無需用到attention_mask張量,因此在用GPT2模型進行文本生成任務時attention_mask一般為None,
而GPT2Model類中最主要的部分便是回圈ModuleList層中的12個Block模塊以及past_key_values元組中12個layer_past張量進行運算,這部分即為GPT2模型主體結構部分的運算程序,
2. Block類
GPT2模型原始碼中Block類的代碼如下所示:
class Block(nn.Module):
def __init__(self, n_ctx, config, scale=False):
super().__init__()
# config對應的GPT2Config()類中, n_embd屬性默認為768, 因此此處hidden_size即為768.
hidden_size = config.n_embd
# config對應的GPT2Config()類中, n_inner屬性默認為None, 因此此處inner_dim一般都為4 * hidden_size.
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
# 此處n_ctx即等于config對應的GPT2Config()類中的n_ctx屬性, 其值為1024.
self.attn = Attention(hidden_size, n_ctx, config, scale)
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
if config.add_cross_attention:
self.crossattention = Attention(hidden_size, n_ctx, config, scale, is_cross_attention=True)
self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.mlp = MLP(inner_dim, config)
def forward(
self,
hidden_states,
layer_past=None,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
use_cache=False,
output_attentions=False,
):
'''
<1> 此時的隱藏狀態hidden_states的形狀為 (batch_size, 1, nx), 此時nx = n_state = n_embed = all_head_size = 768,
即此時隱藏狀態hidden_states的形狀為(batch_size, 1, 768),
<2> 此時layer_past為一個存盤著past_key張量與past_value張量的大張量, 其
形狀為(2, batch_size, num_head, sql_len, head_features).
<3> attention_mask張量為注意力遮罩張量, 其讓填充特殊符[PAD]處的注意力分數極小,
其embedding嵌入值基本不會在多頭注意力聚合操作中被獲取到.
'''
# 將此時輸入的隱藏狀態hidden_states先輸入進LayerNormalization層進行層標準化計算后,
# 再將標準化結果輸入進'多頭注意力計算層self.attn()'中進行多頭注意力聚合操作計算.
# 此時回傳的attn_outputs串列中:
# <1> 第一個值為多頭注意力聚合操作結果張量a, 形狀為(batch_size, 1, all_head_size), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為上方的present張量, 其存盤著past_key張量與這次迭代的key張量合并后的新key張量, 以及
# past_value張量與這次迭代的value張量合并后的新value張量, 其形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_attentions為True, 則第三個值為attn_outputs串列中的注意力分數張量w.
attn_outputs = self.attn(
self.ln_1(hidden_states),
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
# 此時的attn_output張量為回傳的attn_outputs串列中第一個值:
# 多頭注意力聚合操作結果張量a, 形狀為(batch_size, 1, all_head_size), all_head_size=n_state=nx=n_embd=768.
attn_output = attn_outputs[0] # output_attn串列: a, present, (attentions)
outputs = attn_outputs[1:]
# residual connection, 進行殘差連接.
# 此時attn_output張量形狀為(batch_size, 1, all_head_size), all_head_size=n_state=nx=n_embd=768.
# hidden_states的形狀為(batch_size, 1, 768).
hidden_states = attn_output + hidden_states
if encoder_hidden_states is not None:
# add one self-attention block for cross-attention
assert hasattr(
self, "crossattention"
), f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers by setting `config.add_cross_attention=True`"
'''此時self.crossattention()的Cross_Attention運算程序與self.attn()的Attention運算程序幾乎相同, 其不同點在于:
<1> self.attn()的Attention運算是將LayerNormalization之后的hidden_states通過'self.c_attn = Conv1D(3 * n_state, nx)
(第165行代碼)'將hidden_states的形狀由(batch_size,1, 768)投影為(batch_size,1, 3 * 768), 再將投影后的hidden_states
在第三維度(dim=2)上拆分為三份分別賦為query、key、value, 其形狀都為(batch_size, 1, 768);
此時n_state = nx = num_head*head_features = 768.
之后經過split_heads()函式拆分注意力頭且key、value張量分別與past_key、past_value張量合并之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, sql_len+1),
value張量的形狀變為(batch_size, num_head, sql_len+1, head_features).
<2> self.crossattention()的Cross_Attention運算程序則是將LayerNormalization之后的hidden_states通過
'self.q_attn = Conv1D(n_state, nx)(第163行代碼)'將hidden_states的形狀由(batch_size,1, 768)投影為(batch_size,1, 768),
將此投影之后的hidden_states賦值作為query張量;
再將此時從編碼器(encoder)中傳過來的編碼器隱藏狀態encoder_hidden_states通過'self.c_attn = Conv1D(2 * n_state, nx)
(第162行代碼)'將encoder_hidden_states的形狀由(batch_size, enc_seq_len, 768)投影為(batch_size, enc_seq_len, 2 * 768),
將投影后的encoder_hidden_states在在第三維度(dim=2)上拆分為兩份分別賦為key、value,
其形狀都為(batch_size, enc_seq_len, 768); 此時n_state = nx = num_head*head_features = 768.
之后經過split_heads()函式拆分注意力頭之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, enc_seq_len),
value張量的形狀變為(batch_size, num_head, enc_seq_len, head_features).
此時計算出的cross_attention張量形狀為(batch_size, num_head, 1, enc_seq_len).'''
# 此時將上方的隱藏狀態hidden_states(Attention運算結果+Attention運算前的hidden_states)先輸入進LayerNormalization
# 層進行層標準化計算后, 再將標準化結果輸入進'交叉多頭注意力計算層self.crossattention()'中與編碼器傳入的隱藏狀態
# encoder_hidden_states進行交叉多頭注意力聚合操作計算.
# 此時回傳的cross_attn_outputs串列中:
# <1> 第一個值為與編碼器傳入的隱藏狀態encoder_hidden_states進行交叉多頭注意力聚合操作的結果張量a,
# 形狀為(batch_size, 1, all_head_size), all_head_size=n_state=nx=n_embd=768,
# <2> 第二個值仍為present張量, 但由于此時是做'交叉多頭注意力計算self.crossattention()',此時輸入進self.crossattention()
# 函式的引數中不包含layer_past(來自past_key_values串列)的past_key與past_value張量, 因此此時的present為(None,),
# 詳細代碼可見本腳本代碼357行, 因此此處用不到'交叉多頭注意力計算結果串列cross_attn_outputs'中的present,
# 將其舍棄(代碼第528行),
# <3> 若output_attentions為True, 則第三個值為: 交叉注意力分數張量w, 即cross attentions,
# cross_attention張量形狀為(batch_size, num_head, 1, enc_seq_len).
cross_attn_outputs = self.crossattention(
self.ln_cross_attn(hidden_states),
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
)
attn_output = cross_attn_outputs[0]
# residual connection
hidden_states = hidden_states + attn_output
# cross_attn_outputs[2:] add cross attentions if we output attention weights,
# 即將'交叉多頭注意力計算結果串列cross_attn_outputs'中的交叉注意力分數張量cross_attention保存為此時的
# outputs串列中的最后一個元素.
outputs = outputs + cross_attn_outputs[2:]
feed_forward_hidden_states = self.mlp(self.ln_2(hidden_states))
# residual connection
hidden_states = hidden_states + feed_forward_hidden_states
outputs = [hidden_states] + outputs
# 此時回傳的outputs串列中的元素為:
# <1> 第一個值為多頭注意力聚合操作結果張量hidden_states輸入前饋MLP層與殘差連接之后得到的最終hidden_states張量,
# 形狀為(batch_size, 1, n_state), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為上方的present張量, 其存盤著past_key張量與這次迭代的key張量合并后的新key張量, 以及
# past_value張量與這次迭代的value張量合并后的新value張量, 其形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_attentions為True, 則第三個值為attn_outputs串列中的注意力分數張量w.
# <4> 若此時進行了Cross Attention計算, 則第四個值為'交叉多頭注意力計算結果串列cross_attn_outputs'中的
# 交叉注意力分數張量cross_attention, 其形狀為(batch_size, num_head, 1, enc_seq_len).
return outputs # hidden_states, present, (attentions, cross_attentions)
Block類中的代碼程序詳細說明可參考上方Block類原始碼中的注釋部分,
Block類中,主要結構為兩個LayerNormalization層self.ln_1與self.ln_2、一個Attention模塊層self.attn、一個前饋層self.mlp;Attention層用來進行多頭注意力聚合操作,前饋層用來進行全連接投影操作,
2.1 運算程序詳述_交叉多頭注意力聚合操作Cross_Attention與多頭注意力聚合操作Masked_Multi_Self_Attention
若此時有編碼器(encoder)中傳過來的編碼器隱藏狀態encoder_hidden_states張量、encoder_attention_mask張量傳入Block類中且config中的add_cross_attention超引數為True,則此時除了要進行GPT2中默認的Masked_Multi_Self_Attention計算之外,還需要和編碼器(encoder)中傳過來的編碼器隱藏狀態encoder_hidden_states張量進行Cross_Attention計算程序(self.crossattention),
其中self.crossattention的Cross_Attention運算程序與self.attn的Masked_Multi_Self_Attention運算程序幾乎相同, 其不同點在于:
<1> self.attn的Masked_Multi_Self_Attention運算程序
self.attn的Masked_Multi_Self_Attention運算是將LayerNormalization之后的hidden_states張量通過Attention類中的 self.c_attn = Conv1D(3 * n_state, nx) 操作將hidden_states張量的形狀由 (batch_size, 1, 768) 投影為 (batch_size, 1, 3 * 768),再將投影后的hidden_states張量在第三維度(dim=2)上拆分為三份,將其分別賦為query、key、value,其形狀都為(batch_size, 1, 768),此時n_state = nx = num_head*head_features = 768,
之后經過Attention類中的split_heads()函式拆分注意力頭且key、value張量分別與past_key、past_value張量合并之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, sql_len+1),
value張量的形狀變為(batch_size, num_head, sql_len+1, head_features).
之后便會利用得到的query、key、value進行多頭注意力聚合操作,此時計算出的注意力分數張量w的形狀為 (batch_size, num_head, 1, sql_len+1),
<2> self.crossattention的Cross_Attention運算程序
self.crossattention的Cross_Attention運算程序則是將LayerNormalization之后的hidden_states張量通過Attention類中的 self.q_attn = Conv1D(n_state, nx) 操作將hidden_states張量的形狀由(batch_size, 1, 768)投影為(batch_size, 1, 768),將此投影之后的hidden_states張量賦為query張量,
再將此時從編碼器(encoder)中傳過來的編碼器隱藏狀態 encoder_hidden_states 通過 Attention類中的 self.c_attn = Conv1D(2 * n_state, nx) 操作將encoder_hidden_states張量的形狀由(batch_size, enc_seq_len, 768)投影為(batch_size, enc_seq_len, 2 * 768),將投影后的encoder_hidden_states張量在在第三維度(dim=2)上拆分為兩份分別賦為key、value,其形狀都為(batch_size, enc_seq_len, 768),此時n_state = nx = num_head*head_features = 768,
之后經過Attention類中的split_heads()函式拆分注意力頭之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, enc_seq_len),
value張量的形狀變為(batch_size, num_head, enc_seq_len, head_features).
之后便會利用此時得到的query、key、value張量進行交叉多頭注意力聚合操作,此時計算出的cross_attention張量形狀為(batch_size, num_head, 1, enc_seq_len),
3. Attention類
而在GPT2模型主體結構的每一個Block模塊運算程序中,都包含Attention模塊與MLP模塊的運算,GPT2模型原始碼中Attention類的代碼如下所示:
class Attention(nn.Module):
def __init__(self, nx, n_ctx, config, scale=False, is_cross_attention=False):
super().__init__()
n_state = nx # in Attention: n_state=768 (nx=n_embd)
# [switch nx => n_state from Block to Attention to keep identical to TF implem]
# 利用斷言函式判斷此時隱藏狀態的維度數n_state除以注意力頭數config.n_head之后是否能整除.
assert n_state % config.n_head == 0
# 下方的self.register_buffer()函式的操作相當于創建了兩個Attention類中的self屬性, 即為self.bias屬性
# 與self.masked_bias屬性;
# 其中self.bias屬性為一個下三角矩陣(對角線下元素全為1, 對角線上元素全為0), 其形狀為(1, 1, n_ctx, n_ctx),
# 也即形狀相當于(1, 1, 1024, 1024);
# 而self.masked_bias屬性則為一個極大的負數-1e4;
self.register_buffer(
"bias", torch.tril(torch.ones((n_ctx, n_ctx), dtype=torch.uint8)).view(1, 1, n_ctx, n_ctx)
)
self.register_buffer("masked_bias", torch.tensor(-1e4))
self.n_head = config.n_head
self.split_size = n_state
self.scale = scale
self.is_cross_attention = is_cross_attention
if self.is_cross_attention:
# self.c_attn = Conv1D(2 * n_state, nx)相當于全連接層, 其將輸入張量的最后一個維度的維度數由nx(768)投影為
# 2 * n_state(2*768), 此時n_state = nx = num_head*head_features = 768.
self.c_attn = Conv1D(2 * n_state, nx)
# self.q_attn = Conv1D(n_state, nx)相當于全連接層, 其將輸入張量的最后一個維度的維度數由nx(768)投影為
# n_state(768), 此時n_state = nx = num_head*head_features = 768.
self.q_attn = Conv1D(n_state, nx)
else:
# self.c_attn = Conv1D(3 * n_state, nx)相當于全連接層, 其將輸入張量的最后一個維度的維度數由nx(768)投影為
# 2 * n_state(2*768), 此時n_state = nx = num_head*head_features = 768.
self.c_attn = Conv1D(3 * n_state, nx)
# 此處self.c_proj()為Conv1D(n_state, nx)函式(all_head_size=n_state=nx=768), 相當于一個全連接層的作用,
# 其將此時的多頭注意力聚合操作結果張量a的最后一個維度all_head_size由n_state(768)的維度數投影為nx(768)的維度數.
self.c_proj = Conv1D(n_state, nx)
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
self.pruned_heads = set()
# prune_heads()可結合 https://github.com/huggingface/transformers/issues/850 理解.
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.n_head, self.split_size // self.n_head, self.pruned_heads
)
index_attn = torch.cat([index, index + self.split_size, index + (2 * self.split_size)])
# Prune conv1d layers
self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, dim=1)
self.c_proj = prune_conv1d_layer(self.c_proj, index, dim=0)
# Update hyper params
self.split_size = (self.split_size // self.n_head) * (self.n_head - len(heads))
self.n_head = self.n_head - len(heads)
self.pruned_heads = self.pruned_heads.union(heads)
def merge_heads(self, x):
# 此時x為: 利用計算得到的注意力分數張量對value張量進行注意力聚合后得到的注意力結果張量.
# x的形狀為(batch_size, num_head, sql_len, head_features).
# 此時先將注意力結果張量x的形狀變為(batch_size, sql_len, num_head, head_features)
x = x.permute(0, 2, 1, 3).contiguous()
# new_x_shape為(batch_size, sql_len, num_head*head_features) =》(batch_size, sql_len, all_head_size)
new_x_shape = x.size()[:-2] + (x.size(-2) * x.size(-1),)
# 此時將注意力結果張量x的注意力頭維度num_head與注意力特征維度head_features進行合并變為all_head_size維度,
# 注意力結果張量x的形狀變為(batch_size, sql_len, all_head_size).
return x.view(*new_x_shape) # in Tensorflow implem: fct merge_states, (batch_size, sql_len, all_head_size).
def split_heads(self, x, k=False):
# 此時new_x_shape為: (batch_size, sql_len, num_head, head_features)
new_x_shape = x.size()[:-1] + (self.n_head, x.size(-1) // self.n_head)
# 將輸入的張量x(可能為query、key、value張量)變形為: (batch_size, sql_len, num_head, head_features).
x = x.view(*new_x_shape) # in Tensorflow implem: fct split_states
# 若此時輸入的張量為key張量,則需要將key張量再變形為(batch_size, num_head, head_features, sql_len).
# 因為此時key張量需要以[query * key]的形式與query張量做內積運算, 因此key張量需要將head_features變換到第三維度,
# 將sql_len變換到第四維度,這樣[query * key]內積運算之后的注意力分數張量的形狀才能符合(batch_size, num_head, sql_len, sql_len).
if k:
return x.permute(0, 2, 3, 1) # (batch_size, num_head, head_features, sql_len)
# 若此時輸入的張量為query張量或value張量, 則將張量維度再變換為(batch_size, num_head, sql_len, head_features)即可,
# 即將sql_len與num_head調換維度.
else:
return x.permute(0, 2, 1, 3) # (batch_size, num_head, sql_len, head_features)
def _attn(self, q, k, v, attention_mask=None, head_mask=None, output_attentions=False):
'''
此時query張量形狀為: (batch_size, num_head, 1, head_features)
key張量的形狀為: (batch_size, num_head, head_features, sql_len+1)
value張量的形狀為: (batch_size, num_head, sql_len+1, head_features)
此時key張量以[query * key]的形式與query張量做內積運算, key張量已在split_heads()操作與past_key合并操作中
提前將head_features變換到第三維度, 將sql_len+1變換到第四維度,這樣[query * key]內積運算之后的注意力分數張量w的
形狀才能符合(batch_size, num_head, 1, sql_len+1).
'''
w = torch.matmul(q, k) # 注意力分數張量w: (batch_size, num_head, 1, sql_len+1)
# 對注意力分數張量w中的值進行縮放(scaled), 縮放的除數為注意力頭特征數head_features的開方值.
if self.scale:
w = w / (float(v.size(-1)) ** 0.5)
# 此時nd與ns兩個維度相當于1與seq_len+1
nd, ns = w.size(-2), w.size(-1)
# 此處的操作為利用torch.where(condition, x, y)函式,將注意力分數張量w在mask.bool()條件張量為True(1)的相同位置的值
# 保留為w中的原值, 將在mask.bool()條件張量為True(0)的相同位置的值變為self.masked_bias(-1e4)的值.
'''<1> GPT2Model第一次迭代時輸入GPT2Model的forward()函式中的past_key_values引數為None, 此時nd與ns維度才會相等,
在nd與ns維度相等的情況下此操作的結果等價于讓注意力分數張量w與attention_mask張量相加的結果,
<2> 若為GPT2Mode第二次及之后的迭代時, nd與ns兩個維度相當于1與seq_len+1, 此時對self.bias進行切片操作時,
ns - nd等于seq_len+1 - 1即結果為seq_len, 即此時切片操作相當于self.bias[:, :, seq_len : seq_len+1, :seq_len+1],
此操作的意義在于對此次迭代中, 最新的token的注意力分數上添加GPT2中的下三角形式的注意力遮罩.'''
if not self.is_cross_attention:
# if only "normal" attention layer implements causal mask
# 此時self.bias屬性為一個下三角矩陣(對角線下元素全為1, 對角線上元素全為0), 其形狀為(1, 1, n_ctx, n_ctx),
# 也即形狀相當于(1, 1, 1024, 1024);但此處對self.bias進行切片操作時, ns - nd等于seq_len+1 - 1即結果為seq_len,
# 即此時切片操作相當于self.bias[:, :, seq_len : seq_len+1, :seq_len+1],
'''此時mask張量(經過大張量self.bias切片獲得)的形狀為(1, 1, 1, seq_len + 1).'''
mask = self.bias[:, :, ns - nd: ns, :ns]
'''此操作的意義在于對此次迭代中, 最新的token的注意力分數上添加GPT2中的下三角形式注意力遮罩.'''
w = torch.where(mask.bool(), w, self.masked_bias.to(w.dtype))
# 讓注意力分數張量w與attention_mask張量相加, 以達到讓填充特殊符[PAD]處的注意力分數為一個很大的負值的目的,這樣在下面將
# 注意力分數張量w輸入Softmax()層計算之后, 填充特殊符[PAD]處的注意力分數將會變為無限接近0的數, 以此讓填充特殊符[PAD]
# 處的注意力分數極小, 其embedding嵌入值基本不會在多頭注意力聚合操作中被獲取到.
if attention_mask is not None:
# Apply the attention mask
w = w + attention_mask
# 注意力分數張量w: (batch_size, num_head, 1, sql_len+1).
# 將注意力分數張量w輸入進Softmax()層中進行歸一化計算, 計算得出最終的注意力分數,
# 再將注意力分數張量w輸入進Dropout層self.attn_dropout()中進行正則化操作, 防止過擬合.
w = nn.Softmax(dim=-1)(w)
w = self.attn_dropout(w)
# Mask heads if we want to, 對注意力頭num_head維度的mask操作.
if head_mask is not None:
w = w * head_mask
# 多頭注意力聚合操作: 注意力分數張量w與value張量進行內積
# 注意力分數張量w形狀: (batch_size, num_head, 1, sql_len+1)
# value張量形狀: (batch_size, num_head, sql_len+1, head_features)
# 多頭注意力聚合操作結果張量形狀: (batch_size, num_head, 1, head_features), head_features=768.
outputs = [torch.matmul(w, v)]
# 若同時回傳注意力分數張量w, 則將w張量添加入outputs串列中.
if output_attentions:
outputs.append(w)
return outputs
def forward(
self,
hidden_states,
layer_past=None,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
use_cache=False,
output_attentions=False,
):
# <1> 此時的隱藏狀態hidden_states的形狀為 (batch_size, 1, nx), 此時nx = n_state = n_embed = head_features = 768,
# 即此時隱藏狀態hidden_states的形狀為(batch_size, 1, 768),
# <2> 此時layer_past為一個存盤著past_key張量與past_value張量的大張量, 其
# 形狀為(2, batch_size, num_head, sql_len, head_features).
# <3> attention_mask張量為注意力遮罩張量, 其讓填充特殊符[PAD]處的注意力分數極小,
# 其embedding嵌入值基本不會在多頭注意力聚合操作中被獲取到.
if encoder_hidden_states is not None:
assert hasattr(
self, "q_attn"
), "If class is used as cross attention, the weights `q_attn` have to be defined. " \
"Please make sure to instantiate class with `Attention(..., is_cross_attention=True)`."
'''self.crossattention()的Cross_Attention運算程序則是將LayerNormalization之后的hidden_states通過
'self.q_attn = Conv1D(n_state, nx)(第168行代碼)'將hidden_states的形狀由(batch_size,1, 768)投影為(batch_size,1, 768),
將此投影之后的hidden_states賦值作為query張量;
再將此時從編碼器(encoder)中傳過來的編碼器隱藏狀態encoder_hidden_states通過'self.c_attn = Conv1D(2 * n_state, nx)
(第164行代碼)'將encoder_hidden_states的形狀由(batch_size, enc_seq_len, 768)投影為(batch_size, enc_seq_len, 2 * 768),
將投影后的encoder_hidden_states在在第三維度(dim=2)上拆分為兩份分別賦為key、value,
其形狀都為(batch_size, enc_seq_len, 768); 此時n_state = nx = num_head*head_features = 768.
之后經過split_heads()函式拆分注意力頭之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, enc_seq_len),
value張量的形狀變為(batch_size, num_head, enc_seq_len, head_features).
此時計算出的cross_attention張量形狀為(batch_size, num_head, 1, enc_seq_len).'''
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
'''此時隱藏狀態hidden_states的形狀為(batch_size, 1, 768), 將其輸入進全連接層self.c_attn中后,
其Conv1D(3 * n_state, nx)操作(nx=n_state=768)便會將hidden_states的第三維度數由 768維 投影為 3 * 768維,
此時的hidden_states張量的形狀為(batch_size, 1, 3 * 768), 最后將hidden_states張量在第三個維度(維度數3 * 768)上
切分為三塊, 將這切分出的三塊各當成query, key, value張量, 則每個張量的形狀都為(batch_size, 1, 768).
此時n_state = nx = num_head*head_features = 768.
之后經過split_heads()函式拆分注意力頭且key、value張量分別與past_key、past_value張量合并之后:
query張量的形狀變為(batch_size, num_head, 1, head_features),
key張量的形狀變為(batch_size, num_head, head_features, sql_len+1),
value張量的形狀變為(batch_size, num_head, sql_len+1, head_features).'''
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
'''第一次迭代時query、key、value張量的seq_len維度處的維度數就為seq_len而不是1, 第二次之后seq_len維度的維度數皆為1.'''
# 此時經過'注意力頭拆分函式split_heads()'之后的query、key、value三個張量的形狀分別為:
# query: (batch_size, num_head, 1, head_features)
# key: (batch_size, num_head, head_features, 1)
# value: (batch_size, num_head, 1, head_features)
query = self.split_heads(query)
key = self.split_heads(key, k=True)
value = self.split_heads(value)
if layer_past is not None:
'''第一次迭代時query、key、value張量的seq_len維度處的維度數就為seq_len而不是1, 第二次之后seq_len維度的維度數皆為1.'''
'''<1> 本次迭代中新的key張量
此時需要通過layer_past[0].transpose(-2, -1)操作將past_key張量的形狀變為(batch_size, num_head, head_features, sql_len),
而此時key張量的形狀為(batch_size, num_head, head_features, 1), 這樣在下方就方便將past_key張量與key張量在最后
一個維度(dim=-1)處進行合并, 這樣就將當前token的key部分加入了past_key的seq_len中, 以方便模型在后面預測新的token,
此時新的key張量的形狀為: (batch_size, num_head, head_features, sql_len+1), new_seq_len為sql_len+1,
<2> 本次迭代中新的value張量
而此時past_value不用變形, 其形狀為(batch_size, num_head, sql_len, head_features), 而此時value張量的形狀為
(batch_size, num_head, 1, head_features), 這樣在下方就方便將past_value張量與value張量在倒數第二個
維度(dim=-2)處進行合并, 這樣就將當前token的value部分加入了past_value的seq_len中, 以方便模型在后面預測新的token,
此時新的value張量的形狀為: (batch_size, num_head, sql_len+1, head_features), new_seq_len為sql_len+1,
'''
past_key, past_value = layer_past[0].transpose(-2, -1), layer_past[1] # transpose back cf below
key = torch.cat((past_key, key), dim=-1)
value = torch.cat((past_value, value), dim=-2)
# config對應的GPT2Config()類中的use_cache默認為True.但此時若為Cross_Attention運算程序, 則此時不會指定use_cache,
# 而此時use_cache屬性即為False(因為Attention類中use_cache屬性默認為False, 除非指定config對應的GPT2Config()類
# 中的use_cache屬性其才會為True).
if use_cache is True:
# 若use_cache為True, 此時將key張量的最后一個維度與倒數第二個維度互換再與value張量進行stack合并,
# 此時key.transpose(-2, -1)的形狀為(batch_size, num_head, sql_len+1, head_features),
# 此時torch.stack()操作后的present張量形狀為(2, batch_size, num_head, sql_len+1, head_features),
'''present張量形狀: (2, batch_size, num_head, sql_len+1, head_features),
即present張量是用來存盤此次迭代中的key張量與上一次迭代中的past_key張量(layer_past[0])合并、
本次迭代的value張量與上一次迭代中的past_value張量(layer_past[1])合并后所得的新的key張量與value張量的.'''
present = torch.stack((key.transpose(-2, -1), value)) # transpose to have same shapes for stacking
else:
present = (None,)
'''此時query張量形狀為: (batch_size, num_head, 1, head_features)
key張量的形狀為: (batch_size, num_head, head_features, sql_len+1)
value張量的形狀為: (batch_size, num_head, sql_len+1, head_features)'''
# 若output_attentions為True, 則self._attn()函式回傳的attn_outputs串列中的第二個值為注意力分數張量w.
attn_outputs = self._attn(query, key, value, attention_mask, head_mask, output_attentions)
# 此時self._attn()函式回傳的attn_outputs串列中的第一個元素為多頭注意力聚合操作結果張量a,
# a張量的形狀為(batch_size, num_head, 1, head_features);
# 若output_attentions為True, 則此時self._attn()函式回傳的attn_outputs串列中的第二個元素為
# 注意力分數張量w, 其形狀為(batch_size, num_head, 1, seq_len + 1).
a = attn_outputs[0]
'''此時經過'多頭注意力頭合并函式self.merge_heads()'后的多頭注意力聚合操作結果張量a的形狀
變為(batch_size, 1, all_head_size), 其中 all_head_size 等于 num_head * head_features, head_features=768.
all_head_size維度的維度數為768,等于n_state,也等于nx, 即all_head_size=n_state=nx=768.'''
a = self.merge_heads(a)
# 此處self.c_proj()為Conv1D(n_state, nx)函式(all_head_size=n_state=nx=768), 相當于一個全連接層的作用,
# 其將此時的多頭注意力聚合操作結果張量a的最后一個維度all_head_size由n_state(768)的維度數投影為nx(768)的維度數.
a = self.c_proj(a)
a = self.resid_dropout(a) # 殘差dropout層進行正則化操作, 防止過擬合.
# 此時多頭注意力聚合操作結果張量a的形狀為(batch_size, 1, all_head_size),
# 其中 all_head_size 等于 num_head * head_features;all_head_size維度的維度數為768,
# 等于n_state,也等于nx, 即all_head_size=n_state=nx=n_embed=768.
outputs = [a, present] + attn_outputs[1:]
# 此時回傳的outputs串列中:
# <1> 第一個值為多頭注意力聚合操作結果張量a, 形狀為(batch_size, 1, all_head_size), all_head_size=n_state=nx=n_embd=768.
# <2> 第二個值為上方的present張量, 其存盤著past_key張量與這次迭代的key張量合并后的新key張量, 以及
# past_value張量與這次迭代的value張量合并后的新value張量, 其形狀為(2, batch_size, num_head, sql_len+1, head_features).
# <3> 若output_attentions為True, 則第三個值為attn_outputs串列中的注意力分數張量w,
# 其形狀為(batch_size, num_head, 1, seq_len + 1).
return outputs # a, present, (attentions)
Attention類中的代碼程序詳細說明可參考上方Attention類原始碼中的注釋部分,
Attention類中的merge_heads()函式用來將多頭注意力聚合操作結果張量a的注意力頭維度進行合并,令多頭注意力聚合操作結果張量a的形狀由(batch_size, num_head, 1, head_features)變為(batch_size, 1, all_head_size), split_heads()函式用來對query張量、key張量與value張量進行注意力頭拆分, 而prune_heads()函式則可以用來洗掉一些注意力頭,
而Attention類中最核心的函式為_attn()函式, _attn()函式即為用來對query、key、value三個張量進行多頭注意力聚合操作的函式,
3.1 交叉多頭注意力聚合操作Cross_Attention與多頭注意力聚合操作Masked_Multi_Self_Attention
而在Attention()類的forward()函式中一開始便會判斷是否傳入了編碼器(encoder)中傳過來的編碼器隱藏狀態encoder_hidden_states張量,若此時傳入了編碼器隱藏狀態encoder_hidden_states張量,則此時Attention()類中會進行 ‘交叉多頭注意力聚合操作Cross_Attention’ 的計算程序;若此時未傳入編碼器隱藏狀態encoder_hidden_states張量,則此時Attention()類中便會進行GPT2中默認的 ‘多頭注意力聚合操作Masked_Multi_Self_Attention’ 計算程序,
3.2 layer_past張量
此外,此時Attention類的forward()函式中也會判斷是否傳入了layer_past張量,關于layer_past張量的具體含義可參考GPT2Model類的forward()函式中 ‘for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):’ 一行代碼下的注釋,同時參考Attention類的forward()函式中 ‘if use_cache is True:’ 一行代碼下對于 present 張量的注釋,
此時若Attention類的forward()函式中傳入了layer_past張量,則必為進行GPT2中默認的 ‘多頭注意力聚合操作Masked_Multi_Self_Attention’ 計算程序,因為在進行 ‘交叉多頭注意力聚合操作Cross_Attention’ 的計算程序時無需用到layer_past張量,
此時,根據layer_past張量中保存的past_key張量與past_value張量計算當前迭代中新的key張量與value張量的程序為:
<1> 當前迭代中新的key張量
此時需要通過layer_past[0].transpose(-2, -1)操作將past_key張量的形狀變為(batch_size, num_head, head_features, sql_len),而此時key張量的形狀為(batch_size, num_head, head_features, 1),便可將past_key張量與key張量在最后一個維度(dim=-1)處進行合并,這樣就將當前token的key部分加入了past_key的seq_len中,以方便模型在后面預測新的token,此時新的key張量的形狀為: (batch_size, num_head, head_features, sql_len+1),new_seq_len為sql_len+1,
<2> 當前迭代中新的value張量
而此時past_value張量不用變形,其形狀為(batch_size, num_head, sql_len, head_features),而此時value張量的形狀為(batch_size, num_head, 1, head_features),便可將past_value張量與value張量在倒數第二個維度(dim=-2)處進行合并,這樣就將當前token的value部分加入了past_value的seq_len中,以方便模型在后面預測新的token,此時新的value張量的形狀為: (batch_size, num_head, sql_len+1, head_features),new_seq_len為sql_len+1,
4. MLP類
GPT2模型原始碼中MLP類的代碼如下所示:
class MLP(nn.Module):
def __init__(self, n_state, config): # in MLP: n_state=3072 (4 * n_embd)
super().__init__()
# 此時nx=n_embed=768;
# 而n_state實際為inner_dim,即n_state為4 * n_embd等于3072,
nx = config.n_embd
# self.c_fc = Conv1D(n_state, nx)相當于全連接層, 其將輸入張量的最后一個維度的維度數由nx(768)投影為
# n_state(3072), 此時n_state=3072.
self.c_fc = Conv1D(n_state, nx)
# self.c_proj = Conv1D(nx, n_state)相當于全連接層, 其將輸入張量的最后一個維度的維度數由n_state(3072)投影為
# nx(768), 此時n_state=3072.
self.c_proj = Conv1D(nx, n_state)
# 激活函式gelu.
self.act = ACT2FN[config.activation_function]
# 殘差dropout層進行正則化操作, 防止過擬合.
self.dropout = nn.Dropout(config.resid_pdrop)
def forward(self, x):
h = self.act(self.c_fc(x))
h2 = self.c_proj(h)
return self.dropout(h2)
MLP類中的代碼程序詳細說明可參考上方MLP類原始碼中的注釋部分,
GPT2模型主體結構的每一個Block模塊運算程序中,都包含Attention模塊與MLP模塊的運算,MLP類實質上就為一個兩層全連接層模塊,這里會將Attention類輸出的結果hidden_states張量輸入進MLP類中進行前饋神經網路運算,將MLP類的輸出結果再輸入殘差連接residual_connection之后,GPT2模型結構中一個Block模塊的運算程序即結束,之后將會進行下一個Block模塊的運算,
結語
以上便是GPT2模型原始碼中最主要的幾部分:GPT2LMHeadModel類、GPT2Model類、Block類、Attention類與MLP類的詳細代碼程序,
添加了詳細代碼程序注釋的python檔案可從百度網盤modeling_gpt2_詳細代碼程序注釋中獲取(提取碼: zhsl),希望本篇GPT2模型原始碼的學習筆記能夠對大家起到幫助,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/239598.html
標籤:其他