之前看過2遍西瓜書的強化學習部分,盡管看了2遍,但是你問我看懂了什么,我還是一頭霧水,發現一個問題,你給了Q-learning或者DQN的偽代碼,去做一個實戰,確實可以復現,但是就是對背后的原理理解的很模糊,后來又去網上找了一些資料,比如知乎上對DQN的理解,看了之后對于DRL理解更進一步了,但還是有一些不理解的地方,因此后來我決定重新再來,去找李宏毅老師的DRL課程從頭開始學,接下來是我的筆記部分,2020/11/21
# 理論部分學習李宏毅筆記(github版)+葉強pdf、Morvan
# 實踐部分學習葉強gym撰寫+Q-learning、Sarsa、DQN、DDQN的實戰、Morvan
# PER、Duling 學習劉建平博客園、Morvan
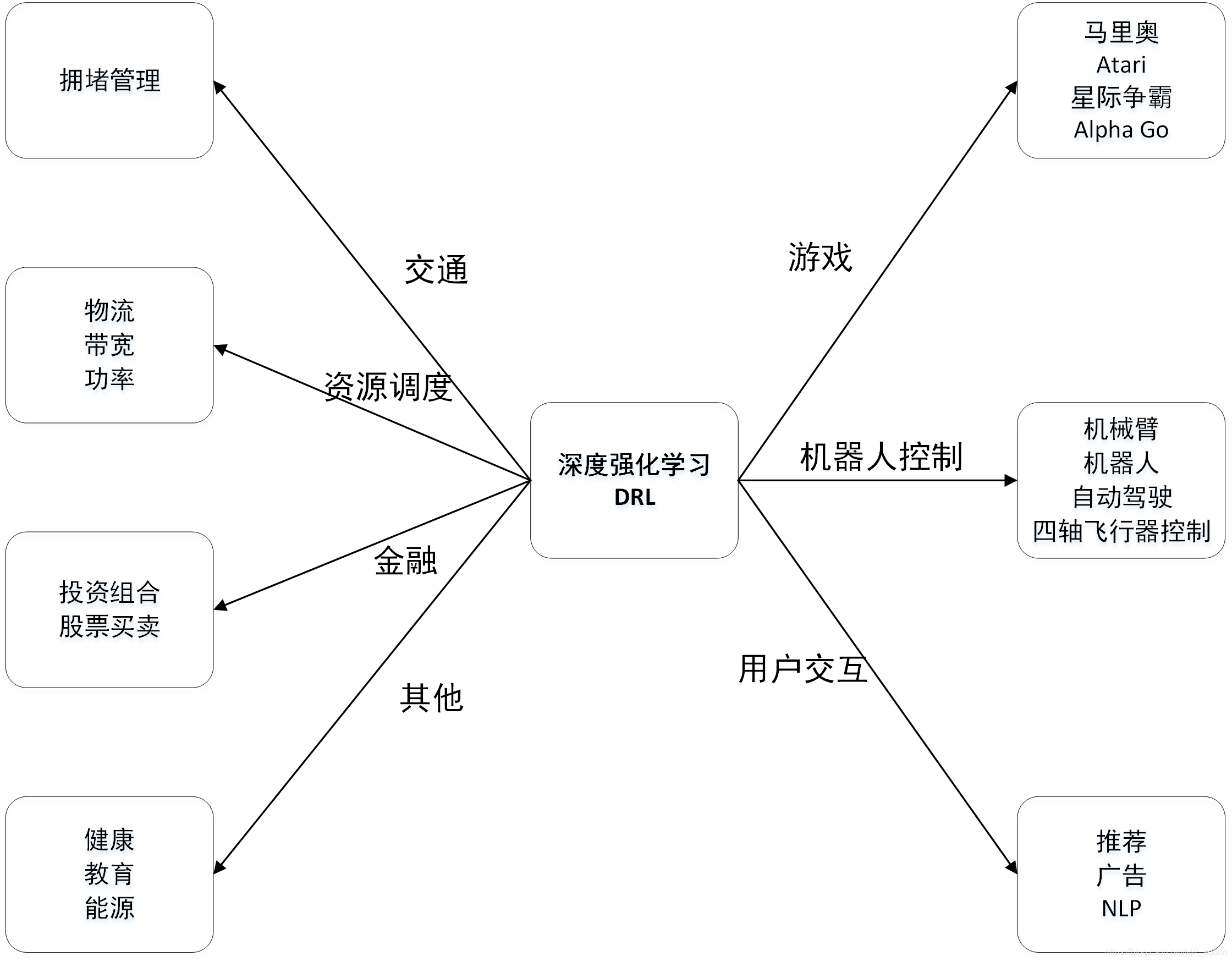
DLR發展現狀及展望:https://www.xianjichina.com/special/detail_440829.html
Part 1:RL簡介
1.1、監督學習與強化學習
機器學習分為監督學習、無監督學習、版監督學習、強化學習四大類(有的也認為是三大類),他們之間各有區別,各有聯系,
1.1.1、監督學習的特點:
1、輸入的樣本服從獨立同分布,即樣本之間無關聯,否則輸出結果的穩定性很差,關于這里,我的理解是,由于輸入樣本之間若有關聯性,那么學習器可能會學習到這個特性,將這個特性當成一種特征,那么當一批無關聯的樣本進行預測時,由于沒有這個特征,因此就會有錯誤的預測結果,導致識別率很低,一批有關聯的樣本進行預測,則又會有正確的預測結果,導致識別率很高,而我們實際用于訓練和測驗的樣本是不一樣的,測驗的樣本往往是無關聯的,那么訓練好的學習器就會做出錯誤的判斷,
2、監督學習有監督信號(即標簽),它能通過loss fuction來及時調整學習器的引數,從而糾正預測值,理論上最終預測值能被糾正到接近標簽的效果,因為由于大部分學習器模型比較復雜,無法求出決議解,因此只能通過有限次迭代來降低損失函式的值,這樣的解為數值解,而決議解就是模型比較簡單時,我們可以直接求出損失函式最小值時的引數解,
1.1.2、強化學習的特點:
1、輸入樣本之間具有時間連續性,其是一系列的序列<sj,sj',r,a>,相鄰樣本在時間上有連續性,
2、強化學習任務并沒有監督信號,只有獎勵信號,有時候獎勵只有到最終時刻才會得到,拿Agent尋寶宮而言,只有最終尋到寶藏才會有獎勵,因此之前的程序Agent得不到任何反饋去調整,去試錯,在最終拿到寶藏,獲得獎勵后,才會去反省自己,進行調整,在下一次試驗時,努力縮短尋寶的時間,因此RL可以看成是具有“延遲標簽信號”的監督學習問題,
3、強化學習中Agent的試錯是一個探索(exploration)和利用(exploitation),探索就是說把試驗的機會平均分配給每一種動作,這樣做的好處就是可能可以探索到最高的獎勵,壞處就是也可能探索到無獎勵、負獎勵,利用就是選擇當下Agent所知道的動作中,能帶來最高獎勵的動作,這樣做的好處就是一定可以帶來穩定的較不錯的收入,壞處就是Agent并沒有獲取最高的獎勵,顯然探索和利用是矛盾的,因此我們在探索和利用中進行折中,以一定概率進行探索,另一份概率進行利用,舉個例子,比如Agent想選擇一加奶茶店喝奶茶,假設全國所有奶茶每杯10元,一共6種奶茶店(一點點、蜜雪冰城、茶百道、古茗、阿姨奶茶、大臺北),但Agent不知道有幾家,然后Agent有60元,想買個6杯,純探索就是Agent把6家奶茶店都逛了一遍,都喝一遍,然后就知道了哪家是最好喝的,比如一點點最好喝,茶百道最難喝(只是比如),純利用就是說,Agent只知道大臺北和古茗的味道如何,比如大臺北比古茗更好喝,所以Agent將60元全部給了大臺北,買了它家的6杯奶茶,事實上,純利用雖然喝到了還不錯的奶茶,但并沒有享受到一點點最好喝的待遇,;而純探索雖然喝到了很難喝的茶百道,但是他心中有了一個口感質量的排序,那么想要擁有最大享受的花法,就是一部分用于探索,一部分用于利用,這就是-貪心策略,
是一個0-1之間的值,一般設定為0.1,即10%的概率隨機選擇一家奶茶店,90%的概率選擇當前最好的奶茶店,通過不斷試錯,Agent才能慢慢理解這個環境,
1.1.3、強化學習的優勢:
前面也說了,強化學習的標簽是延遲的,也就是說無法獲取及時的調整,因此很難訓練出好的結果,既然這么難,為何還要研究呢?監督學習不是更香嗎?
監督學習的標簽是人為設定的,這就決定了學習器不可能超越人類,而強化學習會在環境中不斷探索,一步步走向最優,升級自己,他有超越人類的潛質,比如家喻戶曉的Alphago戰勝圍棋大師等傳奇故事,
1.2、強化學習的基本結構:
1.2.1、基本結構:
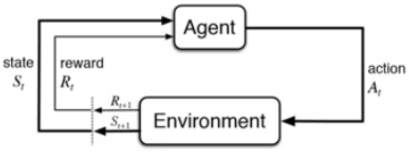
如上圖所示:
step1:智能體Agent在環境Environment中獲取狀態St:,
step2:Agent依據決策policy做出相應動作At,接下來環境做出反饋:1、提供下一個狀態S',2、提供轉移到S‘后對應的當前獎勵Rt+1,
step3:Agent收下獎勵,并更新到指定狀態S’,
step4:回到step2,
Note:
1、Agent存在的目的就是最大化期望累計獎賞,為什么要最大化期望累積獎賞呢?因為對于我們要達到的最終狀態,我們一定會設定最高的獎勵,而其余狀態我們一般不設定獎勵或者較低的獎勵甚至是負獎勵,累積獎勵代表著當前獎勵和對未來將達到狀態的獎勵的預測,期望累積獎勵則能更加準確描述這個值,值函式就是用來描述當前狀態的期望累積獎勵,這一點我們也可以從值函式與未來狀態值函式的貝爾曼等式關系中得出,說明值函式是有一定預測未來的能力的,
那么我們站在任意一個狀態上,Agent就會開始思考:為了達到最終目標,即最大那個獎勵,我們的狀態值函式一定要越大越好,因為值函式定義中,當前獎勵是固定的,狀態值函式越大,那么也就是對未來的預期值越大,而由于只有最終狀態才會有大的獎勵,其余狀態都是負獎勵,因此在負獎勵狀態中徘徊反倒會減小獎勵的預期值,故只有盡快到達最終狀態才會使得預期值增大,等價于當前狀態可以更快到達最終目標,
那么當狀態值函式達到最大的時候,意味著在到達最終目的地獲取最大獎勵的同時,這一路上獲取的負獎勵一定要最小,即最優路徑的概念就出來了,當每個狀態的值函式都達到最大時,將Agent放在任意一個狀態,他都能找到最佳路徑,實作目標,
2、Environment 跟 Reward 不是我們可以控制的,Environment 跟 Reward是在開始學習之前,就已經事先給定的,我們唯一能做的事情是調整policy,使得Agent可以得到最大的Reward,policy 決定了Agent的行為,Policy 就是給一個外界的輸入,然后它會輸出Agent現在應該要執行的動作,
3、“一開始,我對于RL的目的是為了讓Agent獲取更多的獎勵”,這句話不理解,后來在懸崖尋路中,設定每一個格子獎勵為-1,終點為0,我發現有的路徑完成整個序列的獎賞-256、-50等等,而最大的值是-12,而這個最大值對應的就是最優路徑,就是我們RL任務的目的----就是要找出這樣-12的路徑,而這個-12、-256、-50是起始點處開始跑到終點獲取的,因此我們的目標就是讓這個起始點處獲取的這個獎勵為-12,即最大累計獎賞,當這個點求出的獎賞為-12,那我們就知道他一定走了最優路徑,那就要做2件事,一是要求出每個點能獲取的獎勵是多少,2是讓這個獎勵最大化,
對于強化學習任務,我們的目的是最大化累計獎賞(無衰減),也就是說我們要尋找一個最優策略policy,去最大化Agent拿到的獎賞,但是呢,一個Agent放在任意一個狀態上,想要尋找到底最終目的路線,我們一開始是不知道的,因此最大化累計獎賞無法實作,那我們將目標轉移到最大化期望累計獎賞,這個期望累計獎賞的設計需要滿足2個條件,第一個是這是一個估計值,因此用期望E來估計,因為實際上獎勵并不只是一個標量,獎勵其實是一個隨機變數,G其實是一個隨機變數,因為Agent在給定同樣的狀態會做什么樣的行為,這件事情是有隨機性的,環境在給定同樣的觀測要采取什么樣的動作,要產生什么樣的觀測,本身也是有隨機性的,所以G 是一個隨機變數,你能夠計算的是 G的期望值來估計G,第二個是這個值需要有一定預測未來獎勵的能力(依靠γ衰減),
那么RL的目標就變成了2個小目標:第一個是如何去盡量精確的估計出這個期望累計獎賞,第二個是如何最大化這個期望累計獎賞,
前者就是規劃的預測問題,也叫策略評估,我們用值函式表示,在model-based中,我們采用貝爾曼公式,用動態規劃去求解,在model-free中,我們采用矩估計的思想,通過一步步逼近累計獎賞(衰減)來估計出期望累計獎賞的真實值,
后者就是規劃的控制問題,目的在于得出最佳策略與最大值函式,在model-based中,我們采用貪心策略改善策略的方式完成策略迭代求出最優策略,或者求解貝爾曼最優等式的方法迭代出最大值函式,然后求解出最優策略,model-free中,MC通過貪心策略加以改善,從而求出最優策略;TD通過將行為策略和目標策略無限逼近的方式得出最優策略,
通過完成這2個小目標,最后求出RL的最優策略,
1.2.2、實際流程:
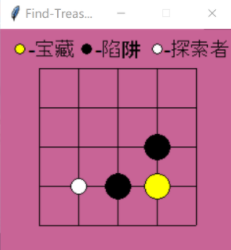
上圖是我用Q-learning(暫時忽略這個,暫時理解為一個RL的演算法)演算法實作的Agent探寶游戲(具體可見:https://blog.csdn.net/MR_kdcon/article/details/109612413),Agent落入陷進得-1分,找到寶藏+1分,其余不得分,踩入陷阱或者找到寶藏游戲結束,Agent剛開始是個“瞎子”,不知道干嘛,于是開始一次次的實驗,一次次的試錯,每一個格點都是一個觀測值observation,Agent可以執行4個動作(上下左右),前幾次實驗,Agent從左上角開始,一步步前進,但他也沒有反饋信號,也不知道走的對不對,當落入陷進或者找到寶藏后,拿到了延遲的監督信號,然后開始反思,下一次實驗想要最大化獎賞,就要避開陷進,尋找寶藏,比如上圖這個局面,Agent上次實驗可能會選擇向右走,導致獎勵為-1,那么當這次來到同樣的地方,為了最大化獎賞,他就不會選擇向右的動作,這就是Agent慢慢提升能力的地方,通過多次這樣的試錯,他就會慢慢理解這個環境,最終不僅完美避開陷阱,還以最短路徑找到寶藏,這個最短路徑就Agent通過訓練學習到的最優策略,
1.3、強化學習中的角色:
1.3.1、動作空間Action、狀態空間State:
Agent和環境的互動程序中,Agent根據當前觀測值會做出某個動作a(所有動作的集合為動作空間Action),每一步都會獲得reward、新的觀測值observation(觀測值的集合就是狀態空間State),因此強化學習程序就是個時間序列,即<s0,a0,r1,s1,a1,r2......>,這樣的一個序列為一次實驗或一條軌跡,Agent就是要在多條軌跡中,為了最大化獎賞而學習到最優策略,
1.3.2、獎勵Reward:
獎賞Reward分為當前獎賞(即上圖中環境及時給出的Rt+1)和期望累計獎賞(有T步累計獎賞![]() 和
和折扣累計獎賞
![]() ),事實上,Agent的目的,或者說做出下一步決策的依據就是最大化期望累計獎賞,其實就和我們人類思維一樣,你的下一步決策一定會考慮我這么做之后,長期的收益應該要最大化,而RL的目的就是讓Agent學習人類的思維方式并超越人類,以
),事實上,Agent的目的,或者說做出下一步決策的依據就是最大化期望累計獎賞,其實就和我們人類思維一樣,你的下一步決策一定會考慮我這么做之后,長期的收益應該要最大化,而RL的目的就是讓Agent學習人類的思維方式并超越人類,以折扣獎賞為例,可以看到越是未來,其比重越低,這其實就和我們認知的一樣,當前的獎勵自然要更加注重一些,但長遠的獎勵也不能不考慮,
Note:在RL的實踐中,演算法大同小異,一個可以施展身手的就是獎勵的設定,我把獎勵設定為4種:
①:真終點獎勵,即想要誘導至終點的那份獎勵,一般設為大于等于0即可,
②:無獎勵,即起點走向終點程序中的路程段,一般設為0,有一種RL任務會設定障礙,那么障礙處的獎勵也一般設為無獎勵,
③:漸進式獎勵,比如像經典RL游戲,Moutaincar中,為了誘導小車快速上坡,可以從低到高設定獎勵逐級遞增,
④:偽終點獎勵,即陷阱、懸崖,為了讓Agent避免走入某個區域,可以把這個區域的獎勵設成負數即可,
1.3.3、智能體Agent:
一個Agent由以下1個或多個組成:決策函式、價值函式、模型
1.3.3.1、決策函式:
決策函式的自變數是當前狀態,輸出是下一個動作,policy function分為隨機性策略和確定性策略,RL一般采用前者,
1.3.3.1.1、隨機性策略:
(a | s)=P[At=a | St=s] ,當你輸入一個狀態s的時候,輸出是一個概率,這個概率就是你所有行為的一個概率,然后你可以進一步對這個概率分布進行采樣,得到真實的你采取的行為,比如50%采取動作a1,40%采取動作a2,10%采取動作a3,
1.3.3.1.2、確定性策略:
![]() ,無論狀態如何,都一律采取最大化策略所對應的動作,比如上面這個50%采取動作a1,40%采取動作a2,10%采取動作a3,確定性策略就會直接采取a1,
,無論狀態如何,都一律采取最大化策略所對應的動作,比如上面這個50%采取動作a1,40%采取動作a2,10%采取動作a3,確定性策略就會直接采取a1,
1.3.3.2、價值函式:
在當前已知的策略下的期望累計獎賞,
1.3.3.2.1、狀態值函式:
![]() 用于衡量狀態s時,在策略
用于衡量狀態s時,在策略下的期望累計獎賞,等價于當前狀態s的好壞(即狀態值函式越大,表明當前狀態更好,反之,狀態很差)
1.3.3.2.2、動作-狀態值函式(Q函式):
![]() 比狀態值函式多了一個動作,用于衡量在當前狀態s執行動作a后,在策略
比狀態值函式多了一個動作,用于衡量在當前狀態s執行動作a后,在策略下的期望累積獎賞,Q函式常用于演算法中,因為從Q中我們能更好地提煉出最優動作a,
為什么要用累計獎賞來評估狀態的價值或者在狀態s執行動作a的價值呢?而不是用當前獎勵來評估?
舉個例子,如下圖所示:
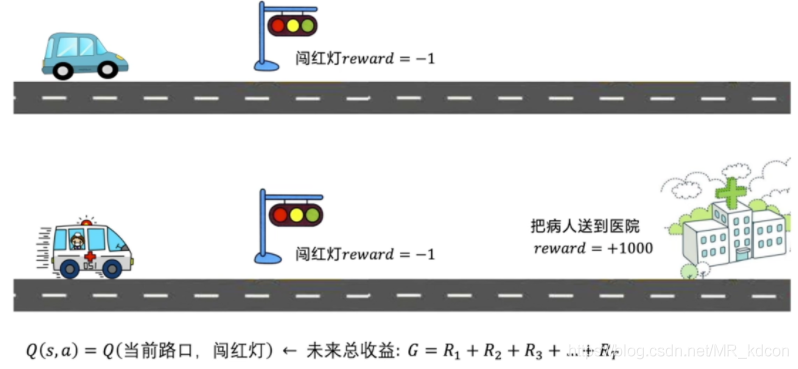
在路口這個狀態時,如果執行闖紅燈這個動作,如果用當前獎賞的話,就是-1.如圖救護車,如果闖了紅燈,但是闖了之后,由于病人得到了及時的救助,最后終止狀態獲得+1000的獎勵,那么真正能表達這個狀態動作對價值的應該是這個當前收益和未來收益的總和,這是因為現實中,獎賞是有延遲的,這就是為什么我們在評估當前狀態(或狀態動作對)時要用累計獎賞的原因,
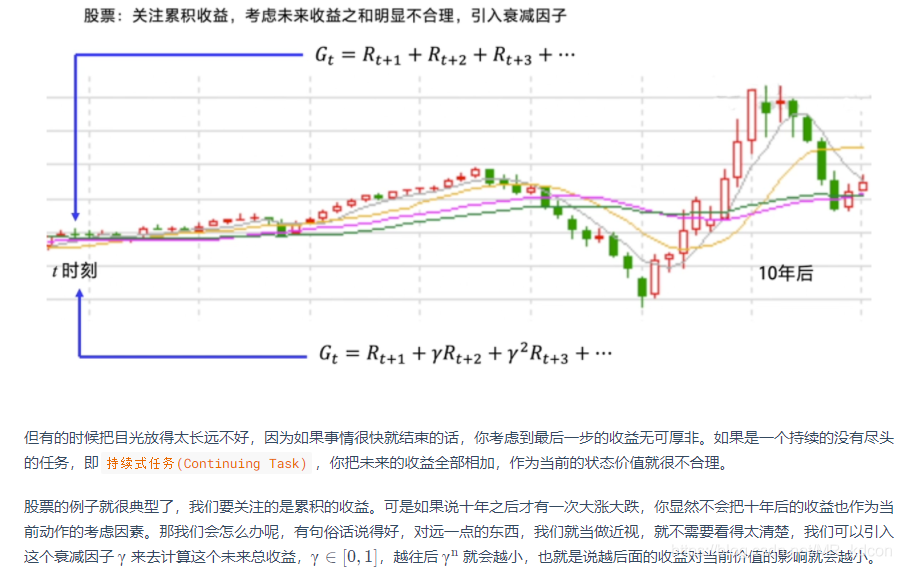
在累計獎賞中引入折扣因子的原因:
1.3.3.3、模型:
RL根據有無模型,可分為model-based和model-free兩類
1.3.3.3.1、有模型:
當狀態s,動作a確定后,下個狀態以及獎勵也就確定了
1.3.3.3.2、無模型:典型的如Q-learning、Sarsa演算法
1.4、強化學習的分類:
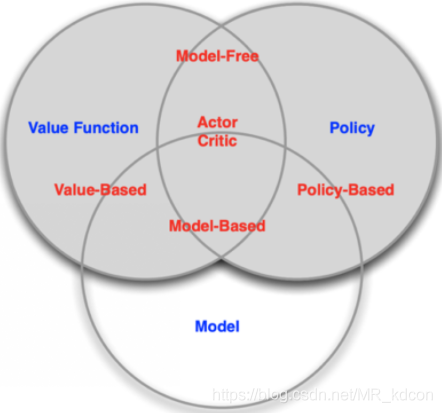
1.4.1、第一種分類方式policy-based、value-based、actor-critic:
1.4.1.1、policy-based
基于策略的方法,輸入是狀態,輸出是執行下個動作的概率(a | s),因此他直接學習到的就是策略,
1.4.1.2、value-based
基于值函式的方法,輸入是狀態,輸出是值函式的大小,然后選擇值函式最大對應的動作為下個動作,因此他直接學習到的是值函式,間接學習策略,
1.4.1.3、actor-critic
這種方式是上面2種方式的結合,
來看一下基于策略和基于價值的區別:
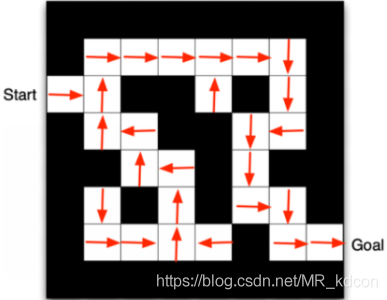

左圖是policy-based訓練后的結果,箭頭arrow代表當前狀態的策略;當Agent處于某個observation,會直接輸出下個動作的概率,然后執行,
右圖是value-based訓練后的結果,數值代表當前狀態的價值大小或狀態好壞,當Agent處于某個observation,如-15,他會將上下2個值函式的大小進行比較,選擇最大那個值對應的動作(因為我們要最大化期望累計獎賞,故要去選擇價值函式大的那個狀態),然后執行,
1.4.2、model-based和model-free:
RL可以用馬爾科夫四元組<S A P R>表示,S表示狀態空間,R表示動作空間,P表示在observation執行動作a后,到下個狀態observation'的概率,R表示在observation執行動作a后,到下個狀態的獎勵,
1.4.2.1、model-based:
基于模型的方式對四元組是確定的,因此可以對值函式用動態規劃去求解貝爾曼等式,最后得出每個狀態下的值函式大小,這成為策略評估,然后通過策略迭代和值迭代可以求出最優策略,其偽代碼如下所示:


策略迭代是用貝爾曼等式用動態規劃不斷進行評估獲取每個狀態的值函式大小,然后進行改進,獲取第一代版本的策略,然后以相同的方式不斷迭代,當策略變換不大的時候,輸出為最優策略,這個程序中不需要去和環境互動,不需要去試錯,就能獲得每個狀態的最優策略,然后根據最優策略去執行動作,相當于對環境建了模,在模擬環境中不斷學習,提升策略,最終得到最優策略,
值迭代是直接求取最優貝爾曼等式,用動態規劃求解每個狀態的最優值函式,當值函式變化不大的時候,輸出最優值函式,和策略迭代一樣,這個程序不需要和環境互動,就能獲得最優策略,然后根據最優策略(即建立好的模型)在環境中執行最優動作,
1.4.2.2、model-free:
基于模型的方式對四元組中P、R是未知的,因此不能使用動態規劃求解其貝爾曼等式,只能通過多次試驗,不斷與環境互動,不斷試錯,每次都要等待獲取下個狀態及獎勵,不斷去優化策略,
1.4.2.3、總結:
可以看出model-based不需要多次試驗,直接進行建模,然后利用訓練好的模型在真實環境中實作,model-free需要多次試驗,多次采集樣本進行不斷更新策略,因此model-based有利于解決資料匱乏下的強化學習任務,但模型畢竟不是真實世界,存在一定的誤差,從偽代碼也可以看出,迭代停止的條件是變化很小,因此不一定能收斂到全域最小,而可能是區域最小,而model-free卻可以不斷更新策略,通過訓練不斷接近全域最小,
1.5、近幾年強化學習發展的原因:
1、算力(GPU、TPU)的提升,我們可以更快地做更多的 trial-and-error 的嘗試來使得Agent在Environment里面獲得很多資訊,取得更大的Reward,
2、我們有了深度強化學習(DRL)這樣一個端到端的訓練方法,可以把特征提取和價值估計或者決策一起優化,這樣就可以得到一個更強的決策網路,(DRL就是不需要手工設計特征,僅需要輸入State讓系統直接輸出Action的一個end-to-end training的強化學習方法,通常使用神經網路來擬合 value function 或者 policy network,)
Part2:馬爾科夫決策程序(MDP):
2.1、馬爾科夫性質:
MDP基于馬爾科夫性質:未來只取決于當前,或者說物體下一個時刻的狀態僅僅取決于當前的狀態和動作,

Note:
這里的狀態時完全可觀察的(即上帝視角),具體來說,我們的人眼就是不完全可觀察的,我們并不能觀測眼前的車子出于什么物理位置,其速度是多少,因此不知道下一個時刻它的位置及狀態,而上帝視角呢?它是完全可觀察的,他明確知道所有物體的狀態,包括位置、速度等,因此他知道車子下一時刻的具體位置和速度是多少,
舉個例子:
鉛球從手中釋放,接下來我們知道他會做自由落體(忽略空氣阻力)運動,我們知道落地前任意時刻的速度是v,位置是h,那么根據公式,我們就知道下個時刻他的位置及速度,這就是簡單的馬爾科夫程序,
強化學習中Agent與環境互動的程序就可以用MDP來描述,MDP是RL的基本框架,但實際上環境中的狀態都是不完全可觀測的,但那個部分可觀測的也可以用MDP來描述,
馬爾科夫程序(或馬爾科夫鏈)、馬爾科夫獎勵程序是MDP的基礎,因此理解MDP之前需要理解這兩塊內容:
2.2、馬爾科夫程序(MP):
可以用一個二元tuple表示(S,P)
S是狀態空間
P是狀態轉移矩陣
2.2.1、馬爾科夫鏈:
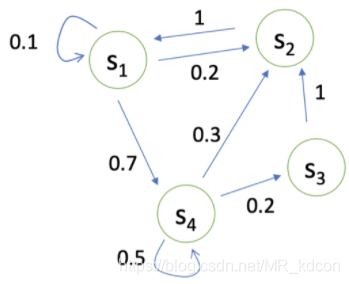
如上圖所示就是馬爾科夫鏈,表示了一個狀態之間轉移的程序,比如s1狀態時候,10%概率會轉移到自身,20%的概率會轉移到s2,70%的概率會轉移到s4,
通過對這條鏈進行采樣,就會得到許多條軌跡,
比如從s1開始:
s1->s4->s2->s1
s1->s2->s1
s1->s4->s3->s2
這就是采樣程序,當軌跡的最后一個狀態是中止狀態時,我們稱這段序列為完整序列,
2.2.2、狀態轉移矩陣:
這個轉移的概率可以用一個狀態轉移矩陣表示,如下圖所示:
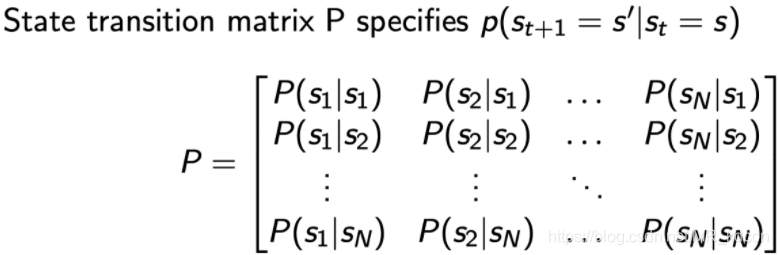
Note:每一行加起來為1.
2.3、馬爾科夫獎勵程序(MRP):
用一個四元tuple表示(S,P,R,)

MRP=馬爾科夫鏈 + 期望累積獎賞
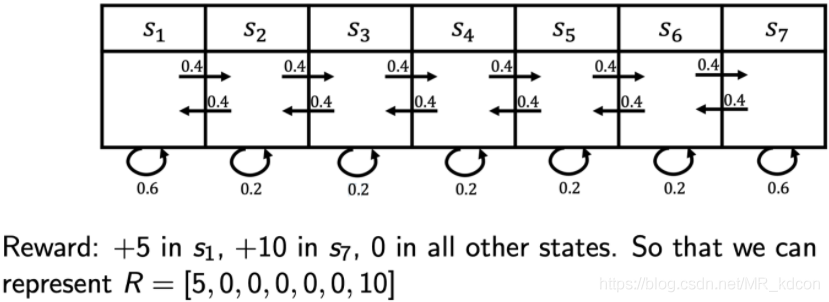
如上圖所示, 上面部分是馬爾科夫鏈,下面文字部分說明了即時獎勵的大小,因為狀態有限,所以用一個vector來表示,
特別要注意一下獎賞的定義:表示當我到達當前狀態s后(或離開當前狀態時,也就是說到達狀態s后,不會立即獲得獎勵,而是離開的時候獲得環境對該狀態的獎勵),獲取的獎勵,如下圖所示:這里的r表示離開狀態s時獲取環境對狀態s的獎勵,
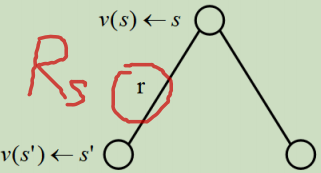
比如S7的獎賞R7=10,根據定義,他表示當我到達S7的時候,我下一個時刻獲得的獎賞是10,
為了更好地描述MRP的程序,需要知道幾個概念:期望累計獎勵、狀態值函式、貝爾曼等式、動態規劃
2.3.1、期望累計獎勵:
識訓(return)定義:![]()
Note:
1、從某個狀態開始,直到中止狀態程序中獲得的獎勵之和,
2、期望累積獎賞:對識訓求期望E,
3、識訓中包含了對未來的預測,
其中是折扣因子(一般取0.9),從期望累計獎賞可以看出:
1、的設計既注重當下利益,又不失長遠目光,這就像我們人類思考問題的方式一樣,數學上看,可以避免識訓的獲取因陷入回圈而無法求解,
2、關于折扣因子,越往后,折扣因子越小,那是因為我們對未來的估計不一定準確,因此需要削減得厲害一點,而前面時間步的折扣因子大,那是因為當下的獎勵更重要,畢竟Rt+1是直接拿到手的,
3、當=0時,只注重當下利益,屬于“短見”;當
=1,可以看到長遠的利益,屬于“遠見”,實際中設計者可以自行設計
的值,
2.3.2、狀態值函式:
定義: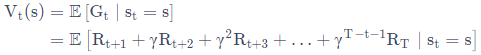

狀態值函式V(s)用于衡量狀態s的好壞,代表狀態s的價值,其值代表了在狀態s的期望累積獎賞,值越大,表明狀態s越好,能獲得一個很好的長遠收益,就像我們人類的思考方式一樣,都要考慮狀態的價值是否符合我的要求,
從上圖最后一句話可以看出,這就是為什么值函式定義為識訓的期望而非單純識訓,,因為前者能更準確的反映狀態的價值,
舉個例子:
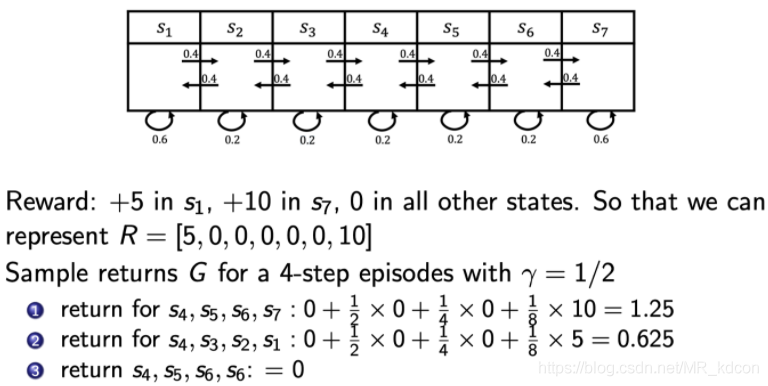
我們需要考量S4的價值高低,以便我們做出動作去選擇它,我們可以這么做,在馬爾科夫鏈中采樣多條軌跡,比如圖中采樣了3條軌跡,獲得了3次的累計獎賞,但是如何計算V(S4)呢? 所以接下來要引入計算值函式的方法:
1、動態規劃
2、蒙特卡洛采樣
3、時序差分方法(TD)
2.3.3、貝爾曼等式:
貝爾曼等式:他是根據值函式的定義推匯出來的,第一部分是到達狀態s后獲取的即時獎勵,第二部分是用狀態轉移矩陣乘以狀態s的下個狀態的值函式大小,最后再乘以折扣因子進行衰減,s'可以看出是未來任意一種狀態,
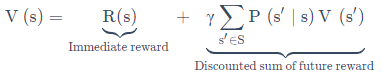
貝爾曼等式表明:當前狀態值函式取決于當前獎勵與未來狀態的值函式,表示了狀態之間的迭代關系,
貝爾曼等式的推導:

舉例子:
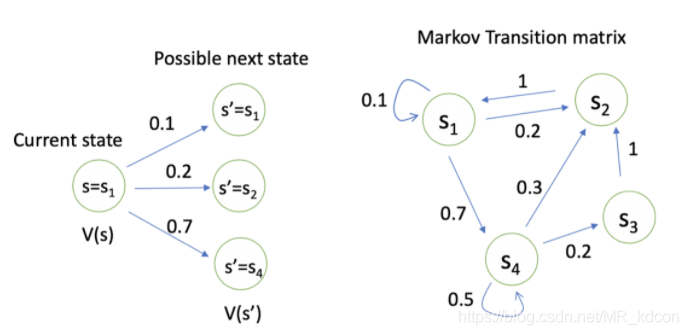
比如我們要用值函式來衡量S1的好壞,可以看出S1未來有三個狀態可以去,因此用S1、S2、S4的價值乘以狀態轉移向量,用它們的和加上即時獎勵,就是狀態S1的價值,
如果用矩陣來表示值函式的話:

通過基礎的線性代數知識,我們可以獲得V(s)的決議解:
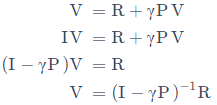
但是矩陣求逆會產生O(N^3)的復雜度,即狀態越多,計算量會很大,因此決議解只能適用于小規模的MRP,
2.3.4、蒙特卡洛采樣法:
Note:蒙特卡洛采樣不需要貝爾曼等式,要用到矩估計法(EX=X平均),
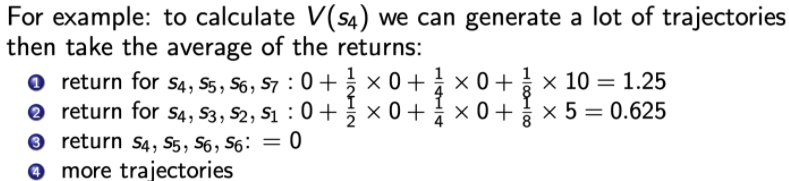
就像之前那樣,對馬爾科夫鏈多次采樣,比如如上圖所示,我們想要衡量S4的價值,因此對于每一條軌跡,計算它的累計獎勵,最后對這么多條從S4開始的軌跡產生的結果求取平均來估計期望累計獎勵,該估計值就代表了V(S4),這就是蒙特卡洛采樣法,
2.3.4、動態規劃:
狀態的值函式亦可以通過用動態規劃去求解貝爾曼等式來做,其偽代碼如下:

首先需要對每個狀態進行初始化為0,然后就是對貝爾曼等式進行有限次的迭代程序 ,直到某一次計算出來的值函式和上一次計算出來的值函式相差不大,比如差距小于我們預先定義的某個值,
1、動態規劃需要遍歷每個狀態,
2、值函式的更新需要用的上個時間段的未來狀態的值,用估計值估計估計值的方式叫bootstrapping(拔靴自助) ,
2.3.4、時序差分法(TD):
TD方法是蒙特卡洛采樣法與動態規劃法的結合,這個之后再介紹
2.4、馬爾科夫決策程序(MDP):

特別需要注意的是,在MRP中我們需要選擇哪個狀態具有更高的價值,而在MDP中,我們需要選擇哪個行為更具有價值,
可以用一個五元tuple來表示:(S,P,R,A ,),

這里的獎勵R(s,a)表示,當我在狀態s執行動作a后,獲取環境對我這個狀態動作對的獎勵,比如下圖中的r就表示R(s,a):
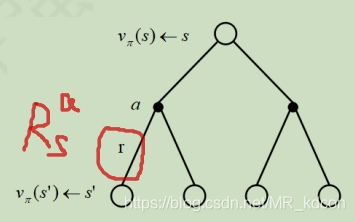
舉個例子,比如格子世界中(除了中止狀態,其余狀態獎勵都是-1),下個狀態是中止狀態,那么Rt+1=0,
上圖表明:
1、在MDP中,下一時刻的狀態,不僅僅像MRP和MP一樣,取決于當前狀態 ,還取決于動作(或者該狀態的決策).,
2、在MDP中,下一時刻的即時獎勵,不僅僅像MRP一樣,取決于當前狀態,還取決于動作(或者該狀態的決策),
3、在MDP中,狀態擁有可以在行為集中選擇一個動作的權力,而選擇動作后,狀態的轉移則由環境決定,
4、可以看出,MDP比MRP僅僅多了一個動作空間A,直接會影響到狀態轉移矩陣P和即時獎賞R
5、MP->MRP->MDP:(S,P)->(S,P,R ,)->(S,P,R,A ,
)
2.4.1、Policy function
狀態從行為集中選擇某個動作的依據稱為策略,
此外,MDP中用一個policy function(簡稱策略)來描述這個動作空間A,如下所示:
![]()
1、策略產生的動作僅有當前狀態有關,而與歷史狀態無關,
2、這個policy function表示一個概率(隨機性策略),即當前狀態為s時,輸出動作a的概率,比如60%的概率往左走,40%概率往右走,
3、還有另外一種表示法(確定性策略): a = (s) ,表明當前狀態為s時,直接輸出一個決策動作a,比如當前處于位置s=s5時,向上走,
4、對于同一個狀態,依據相同的策略,也能產生不同的動作,
5、我們通常所說的策略,大的來說,是一個完整Episode中,統計所有遍歷過的狀態的動作合集;小的來說,就是當前狀態下,依據這個合集應該采取的動作,
2.4.2、MDP與MRP的轉換
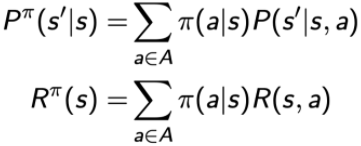
這里要用到全概率公式,
這2個公式告訴我們,在MDP中,一個策略對應一個MRP程序,一個MP程序,不同的策略會產生不同的MRP,從而產生不同的狀態值函式V(s),因此MDP需要重新定義值函式,
2.4.3、MP(或MRP)與MDP的不同決議:
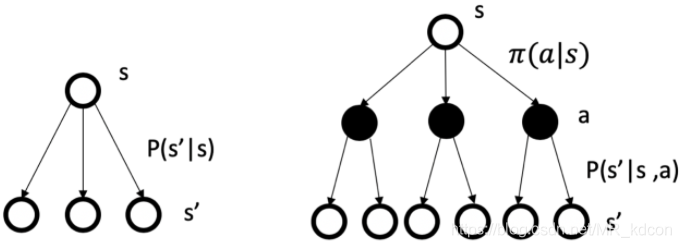
如上圖所示:左圖是馬爾科夫程序,或者也可以看成馬爾科夫獎勵程序,右邊是MDP
MP在已知當前狀態會直接輸出下個狀態的概率,
MDP多了一層決策層,當前狀態和下個狀態之間需要經過決策,通過對決策函式進行第一次采樣采樣(決策函式也是個概率分布),輸出一個動作,動作和下個狀態之間又是一個概率分布,因此需要進行第二次采樣來獲取下個狀態,總之,和MRP不同,輸入狀態和輸出狀態之間需要求決策程序Decition progress,
第一個程序是由決策函式決定的,是可以人為調整的;第二個程序是環境決定的,或者說,狀態擁有可以在行為集中選擇一個動作的權力,而選擇動作后,狀態的轉移則由環境決定,
2.4.4、狀態值函式與動作-狀態值函式:
與MRP不同,MDP中對于狀態值函式進行了更改,以及引入了動作-狀態值函式(或者叫Q函式),
2.4.4.1、狀態值函式:![]()
定義:![]()
回憶MRP中的狀態值函式,沒有上標π,,表示在狀態s所獲得的識訓的期望值,
那么在MDP中呢,如定義一樣,除了多了上標π以及一層決策層以外,其余原理都和MRP一樣,
在MDP中,狀態價值函式表明在策略π下,從狀態s開始,所獲得的識訓的期望,
2.4.4.2、狀態-動作值函式:
為了衡量同一狀態下不同動作的價值,引入Q函式,
定義:![]()
這里的狀態值函式表示在策略π下,狀態s執行動作a,所獲得的識訓的期望值,
Note:
狀態值函式多用于單純表示基于狀態的價值大小,
2.4.5、貝爾曼方程:
①:
![]()
②:
![]()
④:
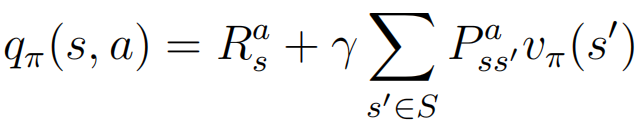
一般來說,q代表了執行動作a的價值,q越大表示執行該動作后所到達的狀態的價值更大,
⑤:
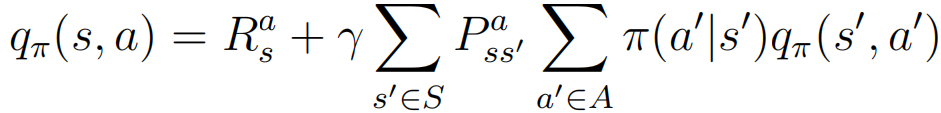
⑥:
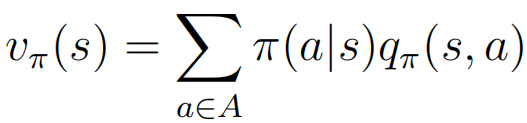
⑦:
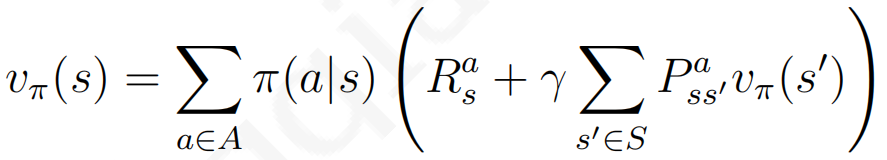
下圖5個公式是MDP中有關貝爾曼等式的基本公式,推導如下:

2.4.6、值函式的求解:
2.4.6.1、![]() 的求解:
的求解:
有了貝爾曼方程這個工具,我們就可以通過不斷迭代來求取某個狀態的價值![]() ,以及某個狀態動作對的價值
,以及某個狀態動作對的價值![]() ,
,
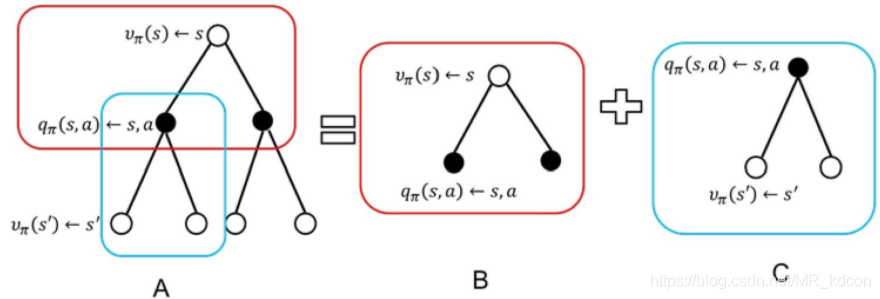
如上圖所示,空心點為狀態s,s',實心點為狀態動作對(s,a),![]() 衡量了狀態s的價值,
衡量了狀態s的價值,
那么![]() 是如何計算的呢?
是如何計算的呢?
A = B+ C
其中B:公式⑥所示->
其中C:公式④所示->
其中A為公式④帶入⑥的疊加:公式⑦所示->
這個backup程序揭示了狀態s的價值與未來狀態s'的價值是迭代的關系,
舉個例子:
下圖是學生上課的MDP,策略函式是每個動作均有50%的概率被選中,=1,
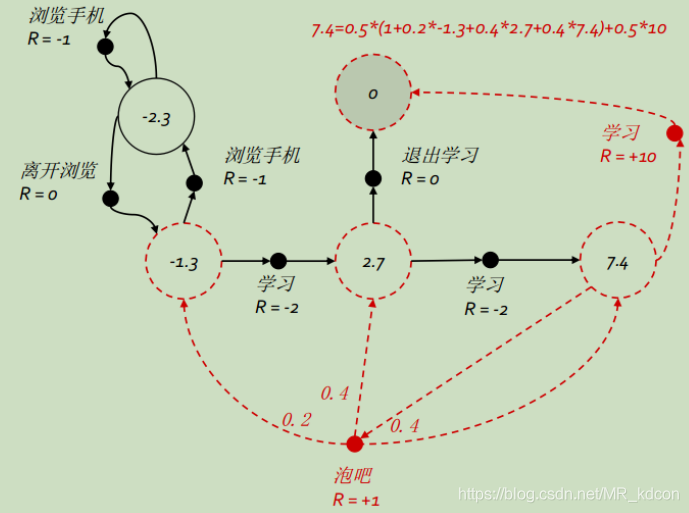
然后來求解最右邊空心點的狀態值函式 ![]() ,看看他的價值有多少?
,看看他的價值有多少?
根據公式⑦所示:
![]() = 0.5 * (1 + (0.2 * -1.3 + 0.4 * 2.7 + 0.4 * 7.4)) + 0.5 * 10 = 7.4
= 0.5 * (1 + (0.2 * -1.3 + 0.4 * 2.7 + 0.4 * 7.4)) + 0.5 * 10 = 7.4
2.4.6.2、![]() 的求解:
的求解:
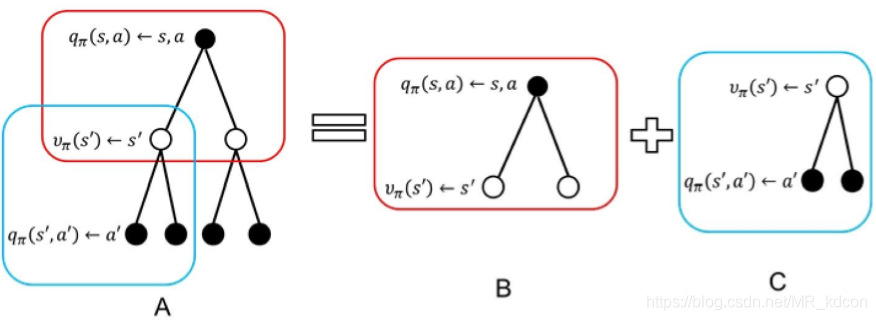
如上圖所示,空心點為狀態s',實心點為狀態動作對(s,a),![]() 衡量了狀態s的價值,
衡量了狀態s的價值,
那么![]() 是如何計算的呢?
是如何計算的呢?
A = B + C
其中B:公式④所示->![]()
其中C:公式⑥所示->![]()
其中A:公式⑥帶入④:公式⑤所示->![]()
這個backup程序揭示了狀態動作對的價值與未來狀態狀態動作對的價值是迭代的關系,
2.4.7、動態規劃:
2.4.7.1、定義:
規劃的定義:

動態規劃的定義:

動態規劃需要滿足2個結構:
1、最優子結構:
在 Bellman equation 里面,我們可以把它分解成一個遞回的結構,當我們把它分解成一個遞回的結構的時候,如果我們的子問題子狀態能得到一個值,那么它的未來狀態因為跟子狀態是直接相連的,那我們也可以繼續推算出來,
2、重疊子問題:
貝爾曼等式的解就是值函式,因此值函式存盤了子問題的解,
Note:動態規劃應用于 MDP 的規劃問題(planning)而不是學習問題(learning),我們必須對環境是完全已知的(Model-Based),才能做動態規劃,直觀的說,就是狀態轉移概率P和對應的獎賞R是已知的,
MDP中,預測和控制是規劃的兩個核心問題,
預測:給定MDP、策略π,去求解每一個狀態的值函式,
控制:不同的策略會輸出不同的值函式,因此控制contorl就是給定MDP,去求解最優值函式V*和最優策略π*,
求解方式:動態規劃
舉個例子:
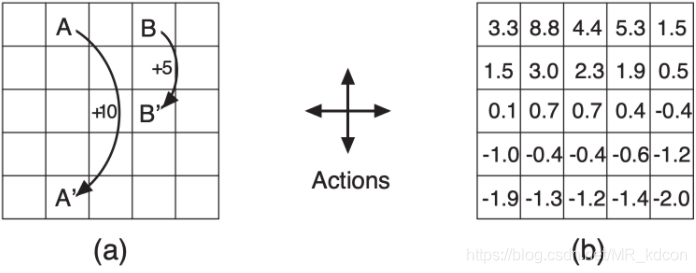
上圖就是個預測程序,給定的策略π是隨機采樣,即上下左右各25%的概率被選中,圖(b)是各個狀態的的價值函式,通過求取價值函式的程序就是預測,
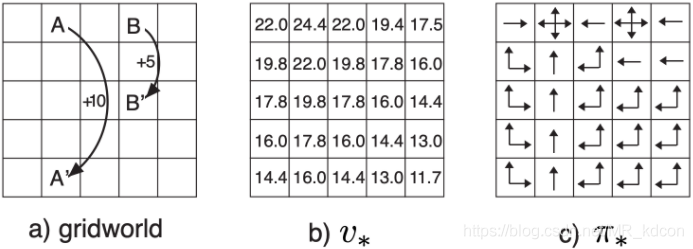
上圖就是個控制程序,控制程序沒有像預測程序那樣有個固定的策略,而是將預測作為一個子程序,通過比較不同策略帶來的每一個狀態的值函式,并找出每個狀態最大值函式作為最優值函式,而最優策略產生的值函式比任何策略產生的值函式都高,
2.4.7.2、預測(策略評估):
策略評估:計算一個策略π下產生的狀態價值函式的程序,就是規劃中的預測問題,
可以使用同步迭代+動態規劃(即同步動態規劃)的方法求解:從任意一個狀態開始,利用貝爾曼公式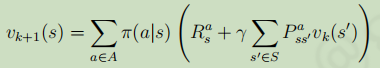 ,對k+1步的每一個狀態值函式用第k步的狀態轉移函式值去計算(符合馬爾科夫性質),如下圖所示,
,對k+1步的每一個狀態值函式用第k步的狀態轉移函式值去計算(符合馬爾科夫性質),如下圖所示,
直至收斂,得到該策略下的最終的狀態價值函式,且可以確保能收斂到一個穩定的值,我們也可以迭代到對任意狀態的值函式,與上個時間步的狀態值函式相差很小時,認為其收斂完成,
Note:
1、同步迭代:每一次迭代,都需要更新所有的狀態,異步迭代:通過某種方式,每次迭代只更新一部分狀態,節省了許多計算資源,
2、之前有說過,一個策略函式對應了一個MRP、MP,因此當π確定時,MDP可以簡化成MRP,即去掉動作a,改掉獎勵與狀態轉移矩陣P:![]()
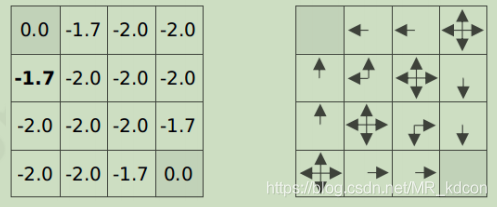
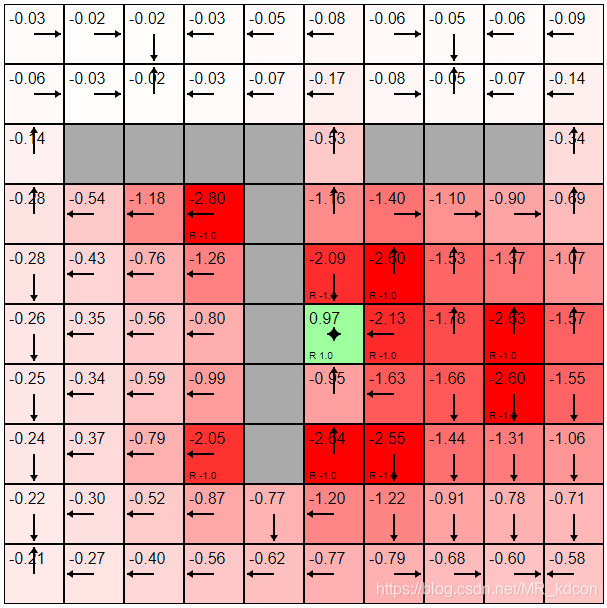
例1:如下圖所示,假設我們現在有一個4*4的方格世界,1號和16號為終止狀態,到達終止狀態獎勵為0,其余狀態獎勵為-1:,初始化16個狀態的狀態值函式為0,動作空間為上下左右:
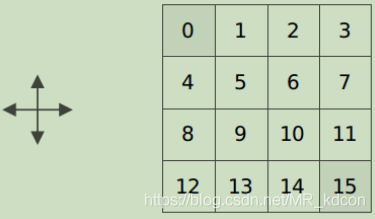
規定初始策略為均一策略,即各有25%概率選擇其中一個動作,每次迭代都需要利用上述貝爾曼公式對16個狀態值同步進行更新,
容易想到:
1、最終到一定程度會穩定下來后,此外,每個狀態的值函式都是不同的,如下圖所示:
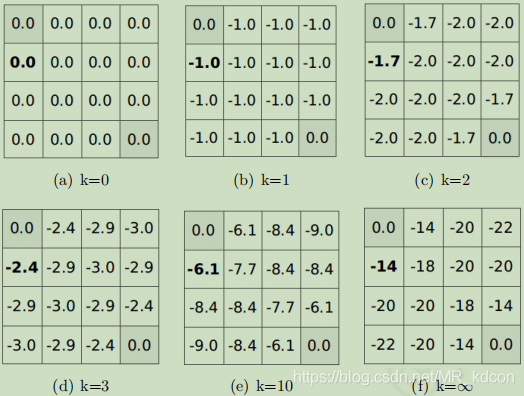
2、每個狀態的值都反映了該狀態的價值,或者說是Agent對這個環境的理解,
3、越是中間地帶,其值函式越低,因為中間地帶一直在扣分,只有2個角落分數高(不扣分其實也是反向加分)
例2:為了更好地描述出k=0到k=inf,格子世界狀態值函式的變化,使用斯坦福大學的一個網站:GridWorld: Dynamic Programming Demo 去模擬這個程序:
初始狀態:每個狀態(格子)都標注了獎勵值R,可執行方向、狀態值函式的值![]()
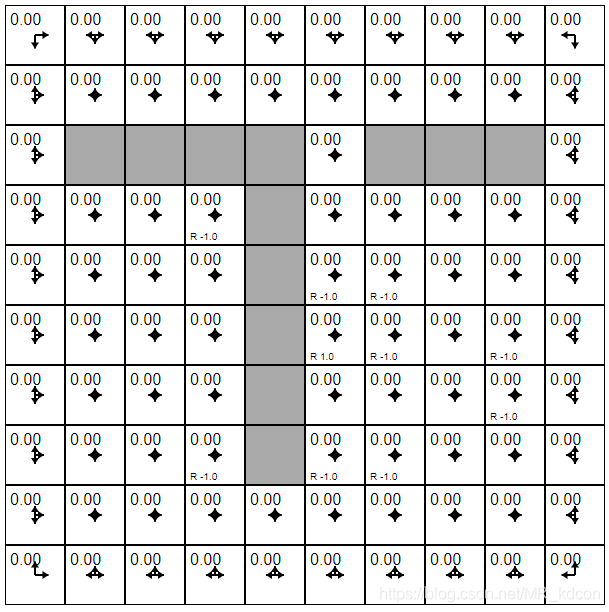
k=1:根據上述貝爾曼等式,可以容易口算出:
k=2:
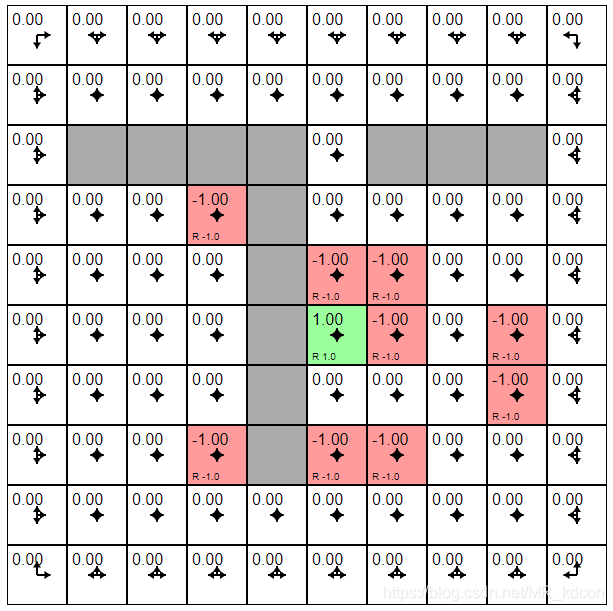
重點關注下黃色的值,為啥會有值呢,他不是獎勵為0嗎,那是因為他的右邊這個狀態值函式非0,即![]() 非0,通過
非0,通過![]() ,可以至少推斷出,黃色狀態必小于0:
,可以至少推斷出,黃色狀態必小于0:
Note:從這里也可以看出值函式是如何擴散的,
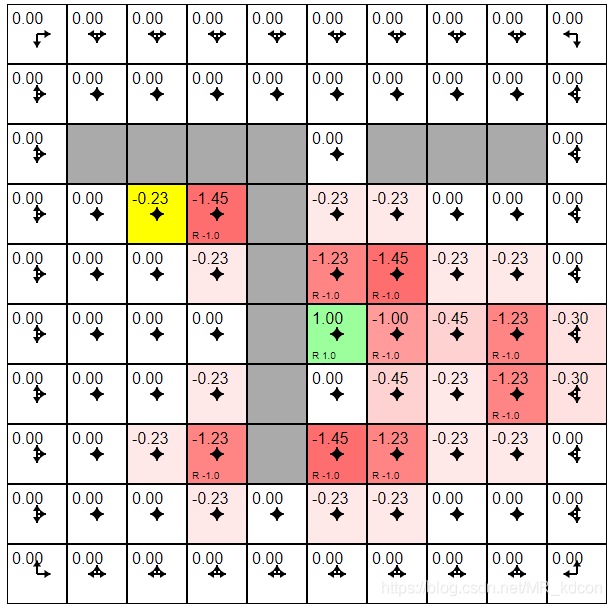
k=10:
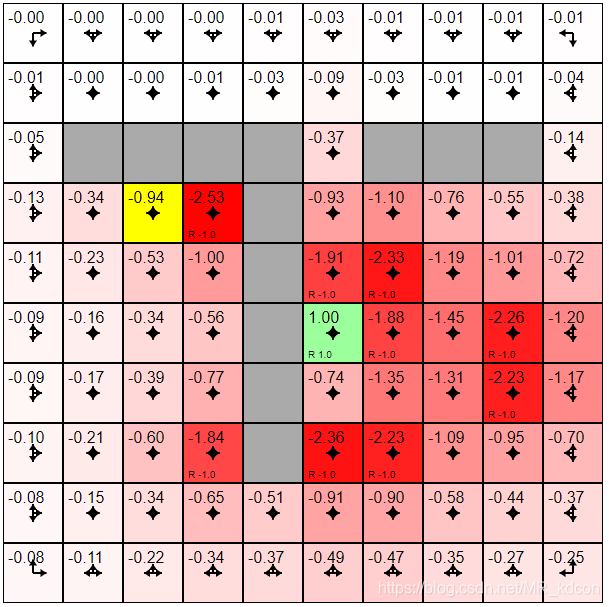
k=20:
如下圖所示,隨著迭代加深,在均一策略下,非0值的狀態在擴散,獎勵為-1的狀態其狀態值函式始終比獎勵為0的狀態值函式低很多,同時,所有狀態值函式都在隨著迭代加深而不斷降低,
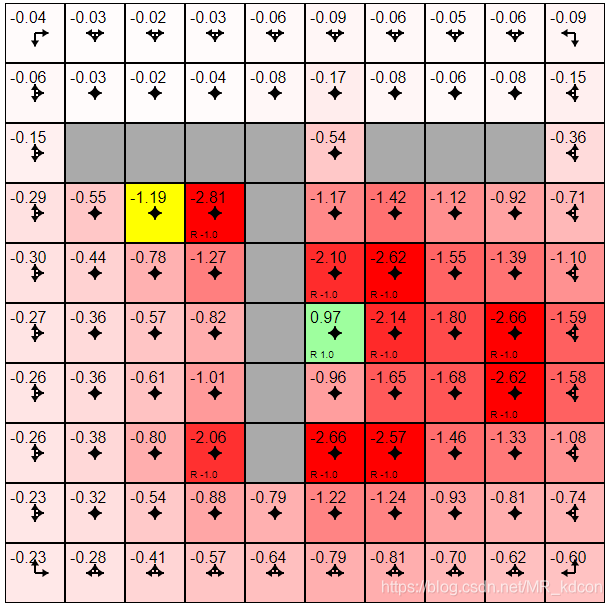
k=30:
當k在30之后,狀態值函式開始穩定了,這樣符合我們之前的結論:
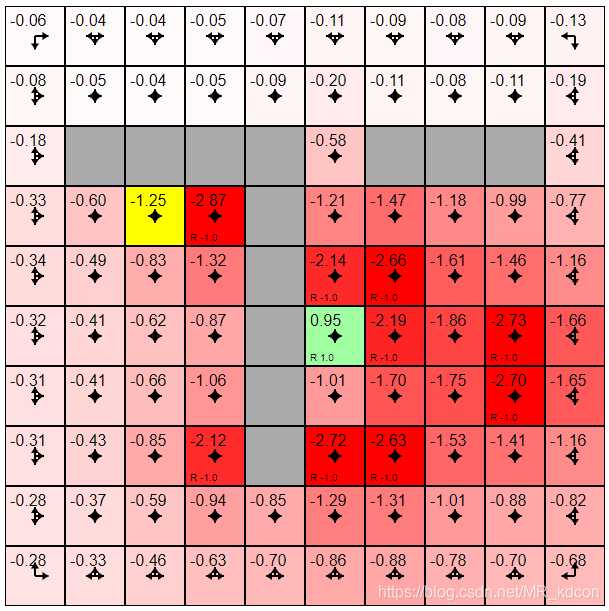
k=inf的話,讀者自己去玩吧,,,,,
2.4.7.3、控制
最優值函式定義:由于不同策略會得到不同的值函式,因此所有策略中,產生最高值函式即為最優值函式:![]() 、
、![]() ,
,
最優值函式可以由最優動作值函式求得:公式⑧:![]() ,他表示狀態s的最優值函式是該狀態下所有動作對應的最優狀態動作值函式中的最大值,
,他表示狀態s的最優值函式是該狀態下所有動作對應的最優狀態動作值函式中的最大值,
最優策略定義:輸出最優值函式的那個策略為最優策略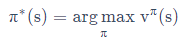 ,最優策略使得每個狀態的值函式最大,每個狀態動作對的值函式最大,
,最優策略使得每個狀態的值函式最大,每個狀態動作對的值函式最大,
如下圖所示,最優策略可通過最大化最優狀態動作值函式所對應的的動作求得:

這意味著:
1、若知道最優狀態動作值函式,就知道了最優策略,因此求解強化學習的問題就轉變成了尋求最優狀態動作值函式的問題,
2、最優策略是確定性策略,
補充:

舉個栗子:這里的值函式是經過預測后的,意味著已經是穩定的值,

如上圖所示,假設我們需要求狀態S1的最優值函式、以及(s1,a1)(s1,a2)(s1,a3)的最優狀態動作值函式,and最優策略,
Note:
1、最后求得在s1下的最優策略是100%執行動作a2,可見強化學習任務最終的策略將會被更新為執行最優動作,
2、要想求得最優策略,必須先求出當前狀態每個動作的最優狀態動作值函式,然后通過取argmax來找到當前狀態的最優策略,接下來對每個狀態都這樣做來達到目標,
那么如何搜尋最優狀態動作值函式呢?

Note:
1、窮舉法就是根據最優策略的定義![]() 而來的,即搜尋一種策略π,讓每一個狀態的值函式最大,比如會輸出下圖這種策略:
而來的,即搜尋一種策略π,讓每一個狀態的值函式最大,比如會輸出下圖這種策略:
2、這種方式毫無效率,因此常用策略迭代和值迭代,
2.4.9.4、策略迭代:
經過策略評估后,每個狀態都有了穩定的值函式,接下來可以利用這個值去調整自己的策略,
回憶下,RL任務設計的初衷是想最大化期望累計獎勵來誘導Agent完成目標,而期望累計獎勵用值函式來表示,因此我們的目標就是去選擇前往值函式最大的那個狀態,于是就有了貪心策略(![]() ),
),
貪心策略(策略改善):
1、選擇所有能到達的狀態中價值最大的那個狀態,我們在每一次策略評估完成后(達到收斂),得到了狀態值函式,
2、然后利用狀態值函式求取狀態動作值函式,即公式④:,
3、使用貪心策略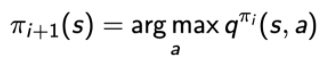 ,這里可以把Q函式看成Q表(類似下圖所示),貪心策略就是在狀態s時,執行最大值時對應的動作a,
,這里可以把Q函式看成Q表(類似下圖所示),貪心策略就是在狀態s時,執行最大值時對應的動作a,
4、基于貪心策略又會產生新的狀態值函式,如此回圈下去,最終就會獲得最優價值函式和最優策略π*,
5、貪心策略是確定性策略,
如下圖所示,在完成第一次策略評估后,使用貪心策略:
可以看出,在使用貪心策略后,Agent的靠近兩邊的行為更加接近目標,因此這是一個策略改善的程序,策略在不斷迭代程序中進行改善,這就是策略迭代程序,
Note:
1、除了初始策略外,迭代程序中的策略均為基于狀態價值函式的貪心策略π',
2、要把貪心策略和區分開來,后者是用于求取某個狀態的最優策略,
如下圖所示策略迭代就是策略評估和策略改善不斷交替進行的程序:
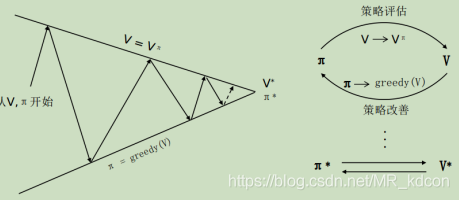
整個策略迭代程序:
1、首先從一個初始策略π出發,計算一次完整(直到收斂為止)的策略評估,獲取每個狀態的值函式,
2、對每個狀態值函式求取狀態動作值函式,并基于貪心策略更改為π',
3、基于新策略π',再次進行完整的策略評估,獲取每個狀態的值函式,
4、對每個狀態值函式求取狀態動作值函式,并基于貪心策略更改為π'',
5、重復3、4,直至收斂為止,
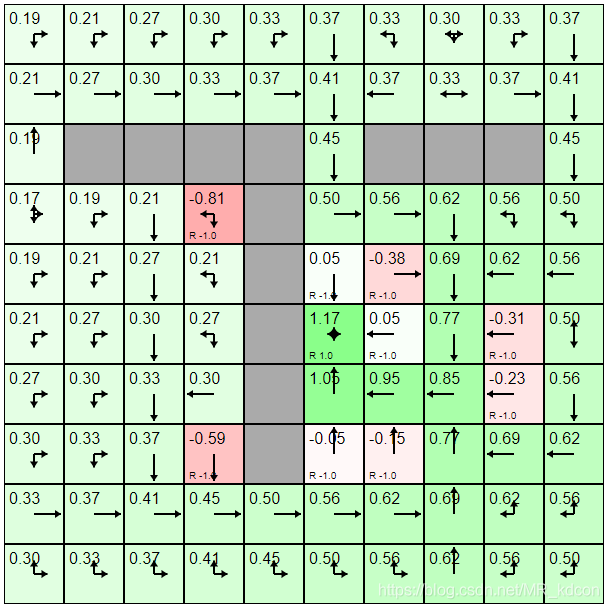
如下圖所示,這是策略迭代產生的最優策略,可以看出,對每個狀態,最優策略都指出了通往目標的最優動作,這是因為設計時,我們將最優策略指向的目標價值最大的狀態,
左圖是最優策略,右圖為非最優策略:可以看出,最優策略使得每個狀態的值函式達到最大,
策略迭代的偽代碼:
為什么一直迭代下去就能得到最優策略呢?證明如下:(這個證明還沒看明白,以后有時間再看)


從這個證明可以看出:策略每次改善,每個狀態的值函式都在單調遞增,
2.4.9.5、值迭代
在介紹值迭代之前,先說下最優貝爾曼等式:
其實也簡單,最優貝爾曼方程就是在貝爾曼方程的基礎上將值函式替換成了最優值函式:
根據公式④:進行改編->公式⑨: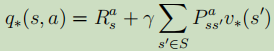
又因為公式⑧![]() ,所以,
,所以,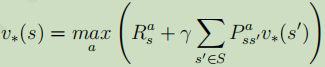 ,
,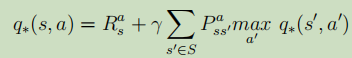
Note:貝爾曼等式的解是值函式,那么最優貝爾曼等式的解就是最優值函式,
舉個栗子:
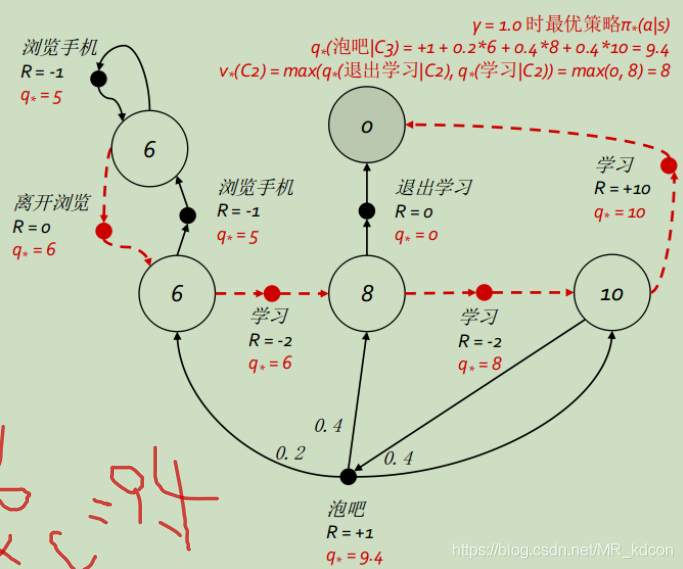
紅線就是最優策略,那么如何得到這條紅線呢?
最優值函式均已求得,我們來驗證下,選擇最右邊那個狀態C2、C3來說明:
它有2個動作,分別是學習和泡吧,為了得到最優策略,我們要先得到最優狀態動作值函式q*,
根據最優狀態動作值函式的定義,需要比較q(C3,泡吧)和q(C3,學習)的大小
根據公式⑨:
假設=1:
q*(C3,泡吧)= 1 + (0.2 * 6 + 0.4 * 8 + 0.4 * 10) = 9.4
q*(C3,學習)= 10
q*(C2,學習)= -2 + 10 = 8
q*(C2,退出學習)= 0
根據,顯然10>9.4,故狀態C3的最優策略是執行學習,即右上角粗虛紅線部分,
顯然8>0,故狀態C2的最優策略是執行學習,
根據![]() ,顯然C3狀態的最優狀態值函式是10,C2的最優狀態值函式是8,
,顯然C3狀態的最優狀態值函式是10,C2的最優狀態值函式是8,
值迭代程序:
首先需要理解一個結論:
最優化策略<==>當一個策略使當前狀態s獲得最高價值當且僅當該策略同樣獲得狀態s之后的任意狀態s“的最優價值,
值迭代程序需要用到最優貝爾曼等式的一個公式:
從該公式可以推斷出:
1、如果我們知道最終狀態的價值和獎勵函式,我們就能知道其前一個狀態s'的最優價值,由于一般我們不知道最終狀態是哪一個,故需要對每個狀態進行更新,
2、值迭代的目標是為了尋找最優策略,通過最優貝爾曼等式,根據前一步的最優值函式推出當前時間步的最優值函式,
不斷迭代至收斂后,通過公式,輸出狀態動作值函式Q,此時的Q其實是個最優值函式,然后對這個狀態動作值函式使用一次貪心策略argmaxQ,來輸出最優策略,
值迭代的偽代碼:
舉個栗子:
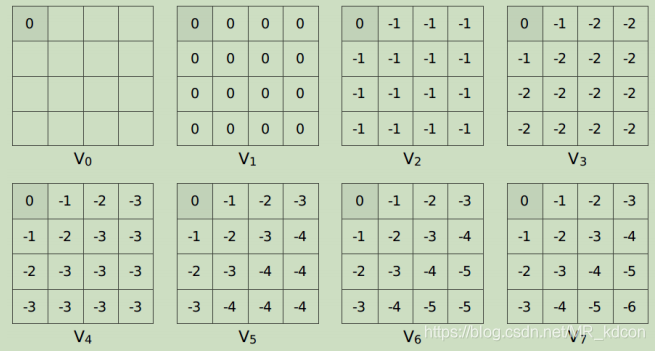
說明:最終狀態為左上角(Agent并不知道這個位置),獎勵為0,其余為-1,初始化狀態值函式為0,=1
step1:根據公式,我們從最終狀態的最優值函式0推出V2所示的各個狀態的值函式,
step2:根據公式![]() ,我們從最終狀態的最優值函式0推出V3所示的各個狀態的值函式,
,我們從最終狀態的最優值函式0推出V3所示的各個狀態的值函式,
step3:根據公式![]() ,我們從最終狀態的最優值函式0推出V4所示的各個狀態的值函式,
,我們從最終狀態的最優值函式0推出V4所示的各個狀態的值函式,
step4:根據公式![]() ,我們從最終狀態的最優值函式0推出V5所示的各個狀態的值函式,
,我們從最終狀態的最優值函式0推出V5所示的各個狀態的值函式,
step5:根據公式![]() ,我們從最終狀態的最優值函式0推出V6所示的各個狀態的值函式,
,我們從最終狀態的最優值函式0推出V6所示的各個狀態的值函式,
step6:根據公式![]() ,我們從最終狀態的最優值函式0推出V7所示的各個狀態的值函式,
,我們從最終狀態的最優值函式0推出V7所示的各個狀態的值函式,
step7:根據公式,求出最優Q表,然后使用貪心策略輸出最優策略,
至此,值迭代的整個程序就結束了,
栗2:同樣是斯坦福那個例子,此次值迭代的最終生成的最優策略和策略迭代的結果是一樣的,如下圖所示,左圖是值迭代,右圖是策略迭代:
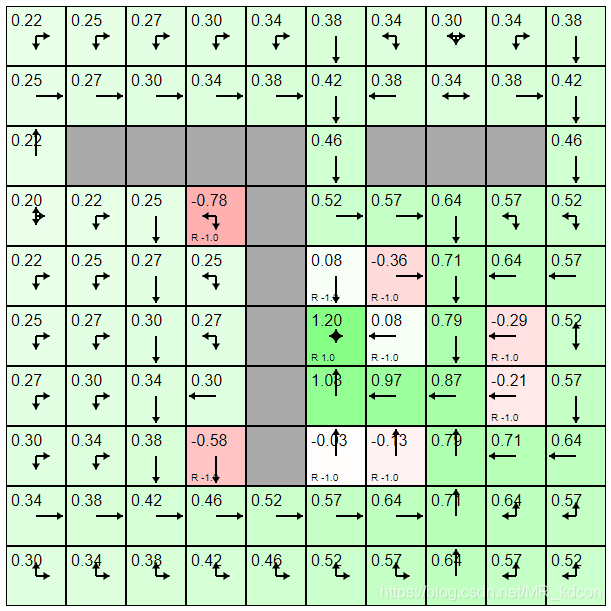
Note:以上的動態規劃演算法屬于同步動態規劃,對所有狀態同步更新,但是比較浪費計算資源,而異步動態規劃則根據一定原則有選擇性的更新部分狀態,
2.4.9.5、MDP總結:
通過一個例子來總結下MDP的整個程序:

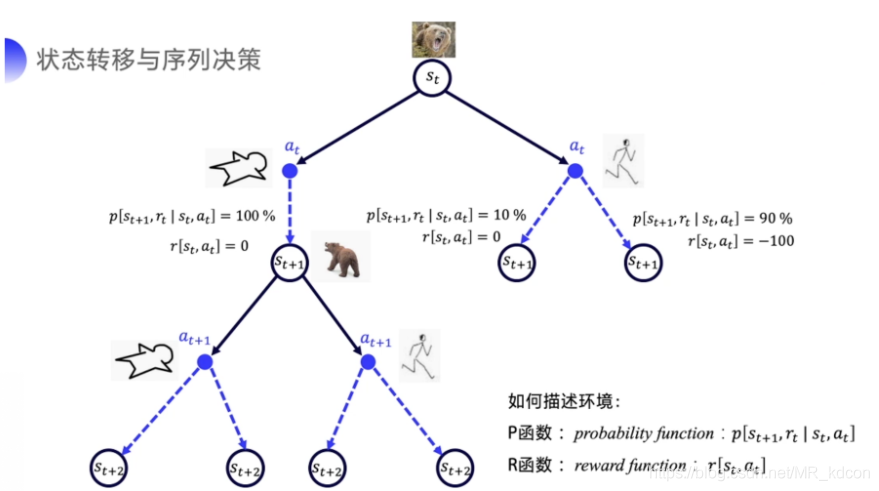

Part3、Model-free的規劃
model-free是不基于模型的RL方法,其可以認為是MDP,但卻不掌握MDP的具體資訊,如狀態轉移矩陣P和獎勵函式R,通過Agent與環境的互動來進行策略評估和策略
還是以熊的例子:
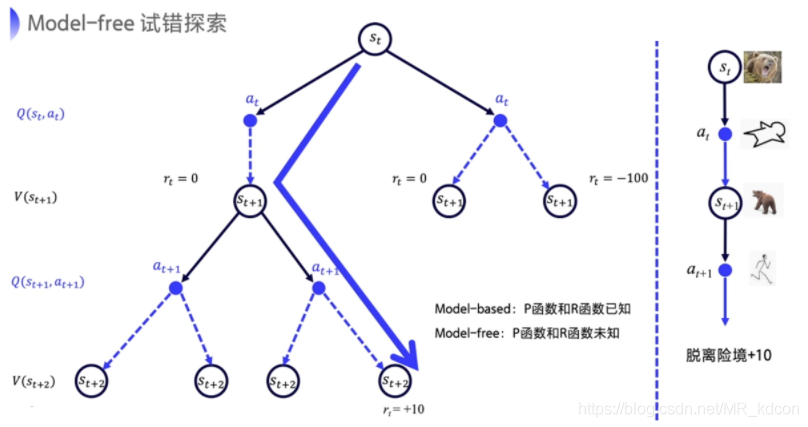

3.1、model-free的預測問題(重點放在MC、Sarsa、TD(0)):
3.1.1、蒙特卡洛學習(MC):
MC學習中的策略評估本質是利用了狀態值函式的定義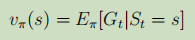 ,其中G為識訓
,其中G為識訓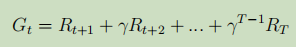 ,根據概率論中矩估計的概念,隨機變數的期望用隨機變數的平均來估計,因此狀態值函式可以用該狀態的多個識訓通過取平均來估計,可以通過Agent與環境多次采樣來實作同個狀態的多個識訓值,理論上根據大數定律(大數定律通俗一點來講,就是樣本數量很大的時候,樣本均值和真實均值充分接近),采樣次數越多,結果越精確,每一條的采樣軌跡如下:
,根據概率論中矩估計的概念,隨機變數的期望用隨機變數的平均來估計,因此狀態值函式可以用該狀態的多個識訓通過取平均來估計,可以通過Agent與環境多次采樣來實作同個狀態的多個識訓值,理論上根據大數定律(大數定律通俗一點來講,就是樣本數量很大的時候,樣本均值和真實均值充分接近),采樣次數越多,結果越精確,每一條的采樣軌跡如下:
![]()
MC學習中,軌跡必須是完整的序列,即不要求起始狀態一致,但是必須都達到終止狀態,
這就是MC的策略評估,顯然MC不需要像model-based一樣,依賴狀態轉移概率P去評估策略,而是通過不斷與環境交流,通過對同一狀態的多個識訓取平均來估計,
在MC的策略評估中,還有個小技巧,即對均值進行增量式學習:具體如下

如上圖所示,累進更新平均值從原來需要存盤k個識訓,到現在只需存盤當前軌跡的識訓以及軌跡條數2個變數,所以存盤量大大減少,
或者,更為簡潔的表示:
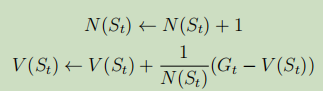
對于一些實時或者軌跡條數難以準確估計的情況下,可以將(1/k)用一個系數來代替,這個
就叫學習率,
![]()
增量式計算表明:這是個軟更新程序,即V通過學習率,一點一點靠近目標G的程序,而V本身就是G的估計值,因此軌跡條數越多,V的估計結果越精確,
另外要補充一點:我們發現,也許一條軌跡中同一個狀態會多次出現,那么根據識訓的定義,其值和另一個同軌跡的同狀態的識訓不一致,根據要不要將同軌跡同狀態的多個識訓加入到均值計算中,MC的策略評估學習分為首次訪問MC評估和每次訪問MC評估,
3.1.2、時序差分學習(TD):
物理意義:
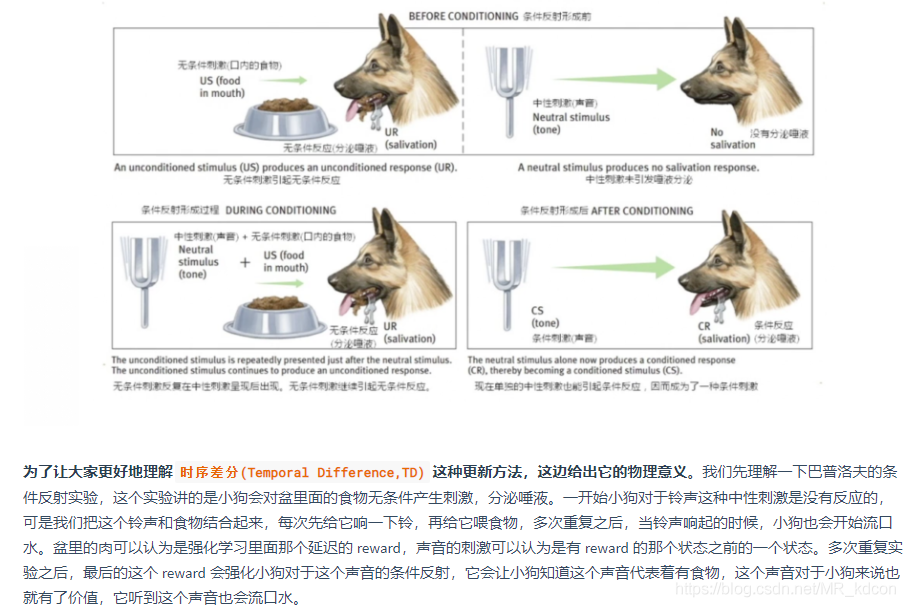

TD學習中的策略評估是指在序列不完整的情況下,通過引導,先估計序列完整時的識訓,然后通過不斷采樣,每一次采樣完后就用上述累進更新平均值的方式更新狀態的值函式,
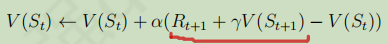
如上圖所示,就是TD學習的策略評估,TD用![]() 去代替了MC學習中的識訓,其中
去代替了MC學習中的識訓,其中![]() 稱為TD目標值,
稱為TD目標值,![]() 稱為TD誤差,
稱為TD誤差,
根據增量式學習,每次只需記錄當前軌跡的TD目標值,
引導:用TD目標值代替識訓的程序,
小結:MC和TD學習中策略評估都是根據采樣的一系列軌跡來更新狀態值函式,
MC和DP的差別:
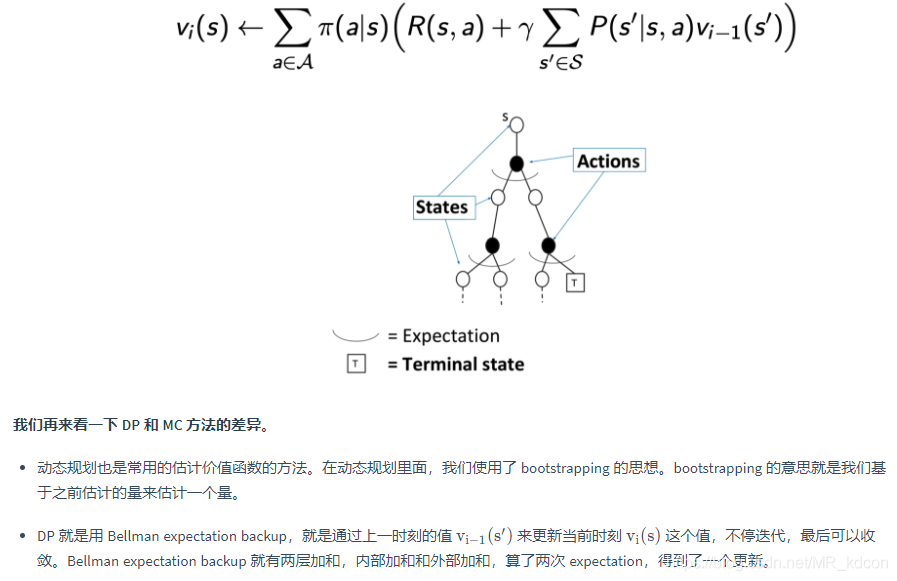
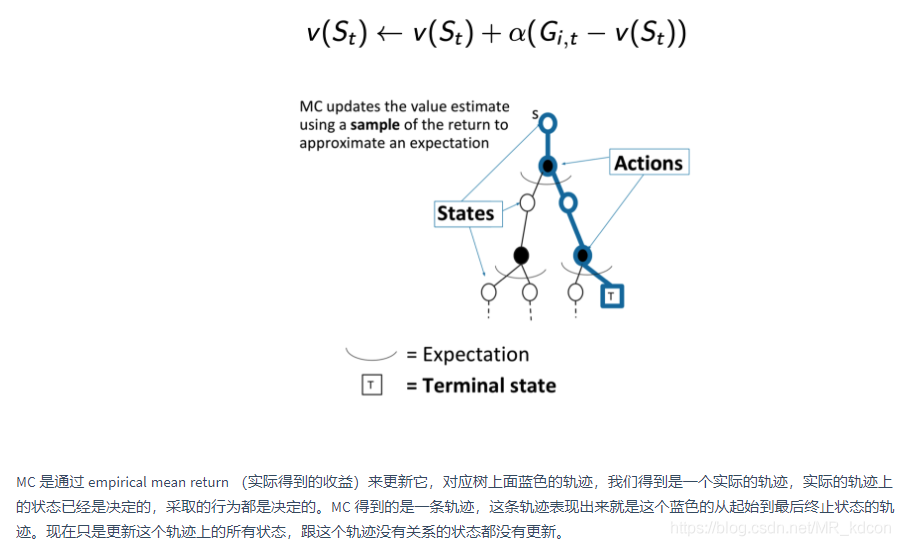
小結:
1、DP每次都要更新所有狀態,MC每完成一條軌跡后更新軌跡中出現的狀態,當狀態數很多時,DP相對更加耗時,
2、DP是model-based,MC是model-free,
MC和TD的差別:
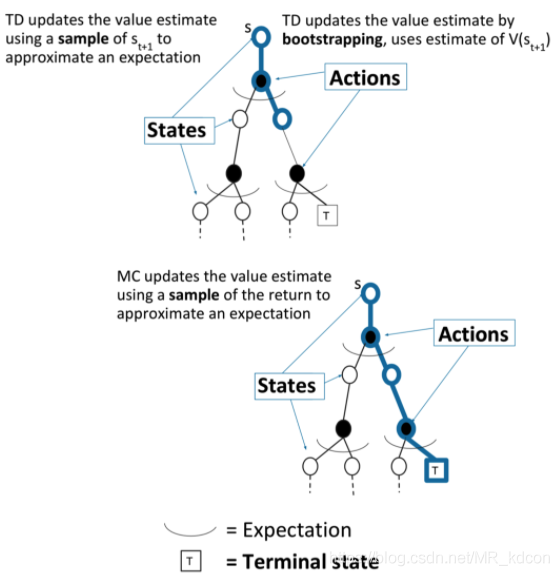
小結:
1、MC將當前軌跡的識訓Gt當做目標值,在完成一條軌跡后,計算真實的識訓來更新狀態價值,
2、TD每走一步就更新一下狀態價值,
3、TD可以在知道結果之前就學習,而MC要在知道結果后才學習,因此TD學習更加快速,
接下來用2個例子來進一步加深理解MC和TD的差別:
例1:
假如Agent要下班回家,在回家途中會遇到6種不同的狀態,要經過取車、高速、非高速、街區路面等路況,正常情況下,Agent估計30mins就能回家;取車時下雨,道路濕滑,Agent根據過往的經驗,估計再過35mins就能回家;駛離高速的時候,路上很順暢,Agent估計再過15mins就能回家;來到非高速路面,被卡車擋在了前面,Agent估計還要10mins才能到家;開到家附近的時候,Agent估計再過3mins就能到家;最后是終于到家了,下表是Agent根據往常的軌跡得出來的各個狀態的價值,為了對各個狀態的預估時間更加精確,Agent還需要繼續嘗試各種路況來更新各個狀態的價值,即各個狀態下的仍需耗時,接下里分別采用MC和DT進行策略評估(即求值函式),
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
MC&TD:
MC的更新方式,是經過完整的序列之后,再更新每個狀態的值函式,即回到家才會進行更新,為了表現這個程序,每個狀態的更新我都用一張表來表示:
TD的更新方式,是每經過一個狀態,都會用后一個狀態的耗時來更新當前狀態的耗時,為了表現這個程序,每個狀態的更新我都用一張表來表示:
當離開辦公室的時候,按照既往經驗估計,狀態值函式表如下:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
TD按照既往經驗對下個狀態的估計開始更新當前狀態的價值,
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
當取車時下雨:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取車時下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
駛離高速:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取車時下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 駛離高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
跟在卡車后:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取車時下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 駛離高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡車后 | 30 | 10 | 40 | 13 | 43 | ||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
家在附近街區:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | ||||||
| 取車時下雨 | 5 | 35 | 40 | ||||||
| 駛離高速 | 20 | 15 | 35 | ||||||
| 跟在卡車后 | 30 | 10 | 40 | ||||||
| 家在附近街區 | 40 | 3 | 43 | ||||||
| 回傳家中 | 43 | 0 | 43 | ||||||
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取車時下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 駛離高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡車后 | 30 | 10 | 40 | 13 | 43 | ||||
| 家在附近街區 | 40 | 3 | 43 | 3 | 43 | ||||
| 回傳家中 | 43 | 0 | 43 | ||||||
回傳家中,可見MC是在整個流程結束之后再更新各個狀態的價值,最后的結果基本上相差不大:
| 狀態 | 已耗時(mins) | 既往經驗預計 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | 仍需耗時 | 總耗時 | ||||
| 離開辦公室 | 0 | 30 | 30 | 43 | 43 | 40 | 40 | ||
| 取車時下雨 | 5 | 35 | 40 | 38 | 43 | 30 | 35 | ||
| 駛離高速 | 20 | 15 | 35 | 23 | 43 | 20 | 40 | ||
| 跟在卡車后 | 30 | 10 | 40 | 13 | 43 | 13 | 43 | ||
| 家在附近街區 | 40 | 3 | 43 | 3 | 43 | 3 | 43 | ||
| 回傳家中 | 43 | 0 | 43 | 0 | 43 | 0 | 43 | ||
小結:
1、從這個例子我們可以得出,TD在策略評估時,每經過一個狀態,都會用下個狀態的預估計值來更新當前狀態的值函式,而MC則不同,它是在一個完整狀態序列結束后,再去更新各個狀態的值函式,
2、可見TD的更新速度更快,
3、TD可以在不知道結果下學習,或沒有結果下學習,還可以在持續進行的狀態中學習,
4、TD學習是用TD目標值,即離開當前狀態時的獎勵+下個狀態的預估價值V(s')來代替當前狀態在序列結束時可能的識訓,TD目標值的樣本均值是當前狀態價值的有偏估計(有偏估計是因為TD目標值中下個狀態的預估計值使用的也是后續狀態的待評估值),而MC是用真實識訓來作為目標值,真實識訓的樣本均值是當前狀態價值的無偏估計,(估計量的期望等于總體的期望(總體的均值),則估計量為總體期望的無偏估計,如樣本均值就是總體期望EX(總體均值)的無偏估計)
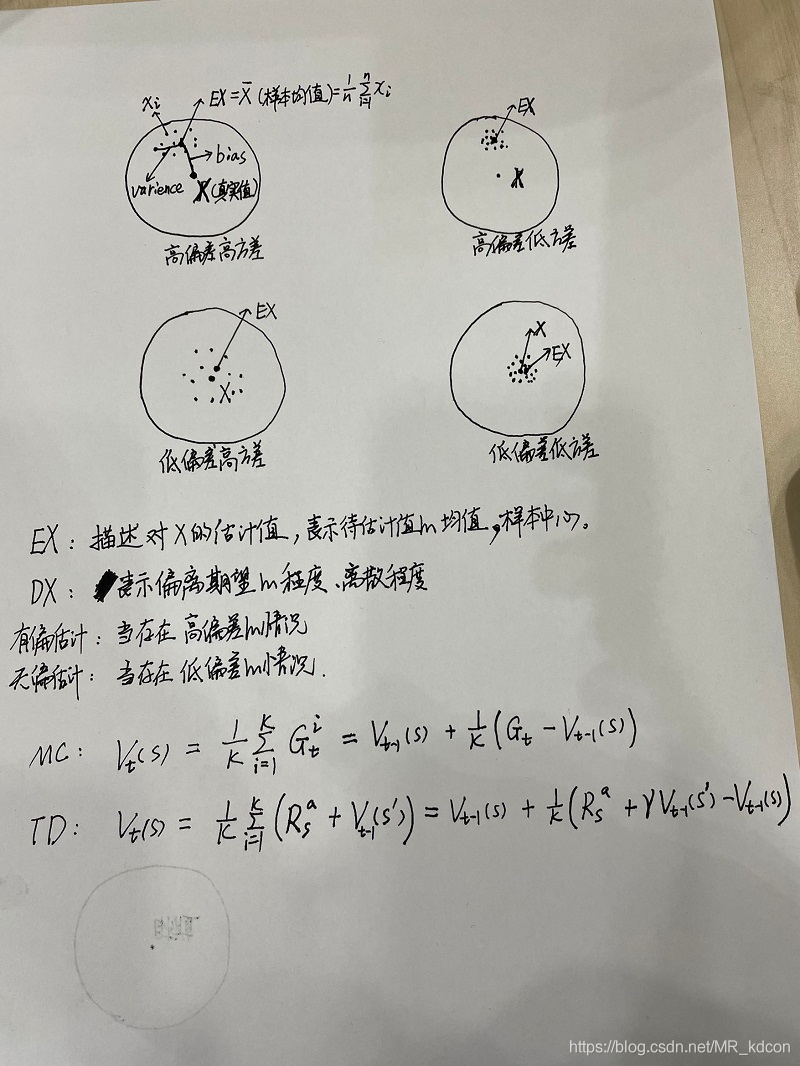
關于有偏無偏估計,可參考:什么是無偏估計? - 知乎 (zhihu.com)
5、TD學習比MC學習有更低的方差,期望就是平均值,我們可以用樣本均值來估計期望,即約等于,且樣本數N越多,樣本均值越接近于平均值(大數定律),樣本均值是總體的無偏估計,
6、value-based方法的值函式主要用TD 或 MC 來估計,用 TD 比較穩,用 MC 比較精確,
MC比較精確是因為穩定MC直接使用衰減G為Q估計值的更新目標,而TD用的是G的替代版r+Q(s'),當迭代次數無限大的時候,兩者才相等,否則只能說接近G,
TD比較穩是因為TD的方差小,MC的方差大,因為MC使用G為目標,而G這個值是不穩定的,對同一個s,采用動作a,產生軌跡的G=100,有時候G=-10,故Q的更新是不穩定的,為了解決這個問題,可采用G的期望來解決,G的均值相對而言會減小這種方差大的不穩定性,而恰好Q就是G的期望,而我們當初在做TD的時候,把G=r+γ*Gt+1中的Gt+1換成Q(s')這個操作使得MC不穩定(方差大)的問題得到了解決,
7、TD結合MC和DP,使用MC的增量式格式,使用動態規劃方法來提高采樣的效率,即從狀態 s 開始的總回報可以通過當前動作的即時獎勵 r(s,a,s') 和下一個狀態 s's的值函式來近似估計,
例2:
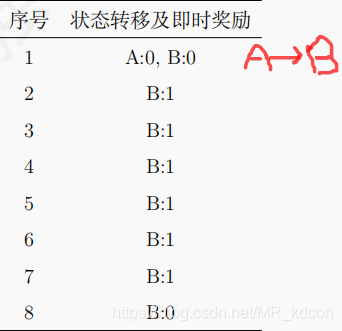
如上圖所示,目前采樣了8條完整序列,除了第一條有2個狀態的轉移以外,其余7條均只有1個狀態,求A、B的值函式(本例假設忽略策略、動作):

從題目中可知,狀態A一定會轉移到B,且狀態B有75%的概率會獲得獎勵1,25%概率獲得獎勵0,因此TD相當于構建了一個MDP程序,如下圖所示:
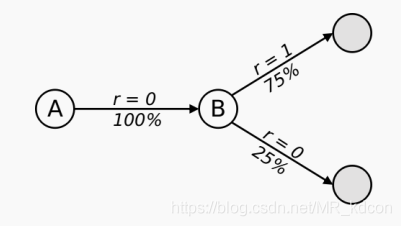
TD演算法試圖構建一個MDP程序(S A P R ),使得這個MD盡可能符合當前的采樣序列,具體的,TD會根據采樣序列得出狀態轉移概率P和獎勵函式R:
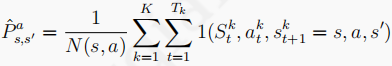
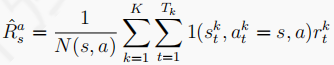
然后計算該MDP的狀態值函式,
而MC是根據真實識訓來計算狀態值函式,通過不斷縮小真目標與狀態值函式的差來達到目標,
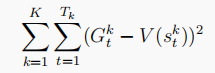
小結:TD演算法適用于馬爾科夫環境下,MC不限于馬爾科夫環境下,
DP、MC、TD三者差別:

Note:bootstrapping(拔靴自助):就是用估計去估計另一個估計值,
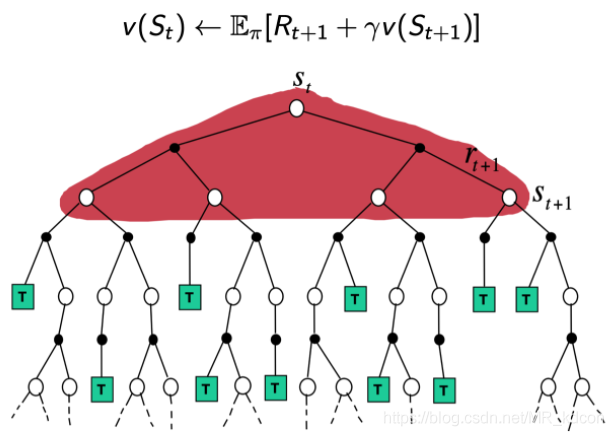
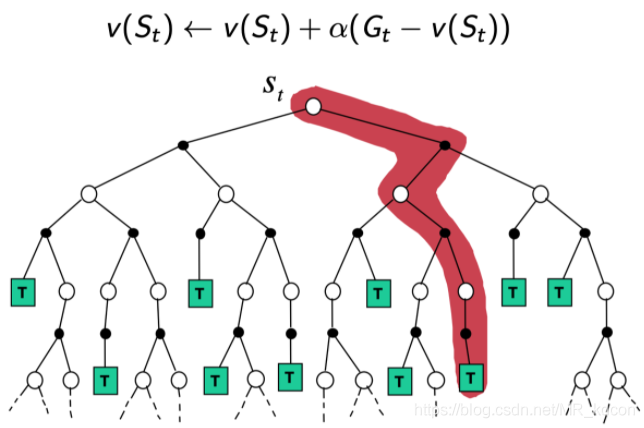
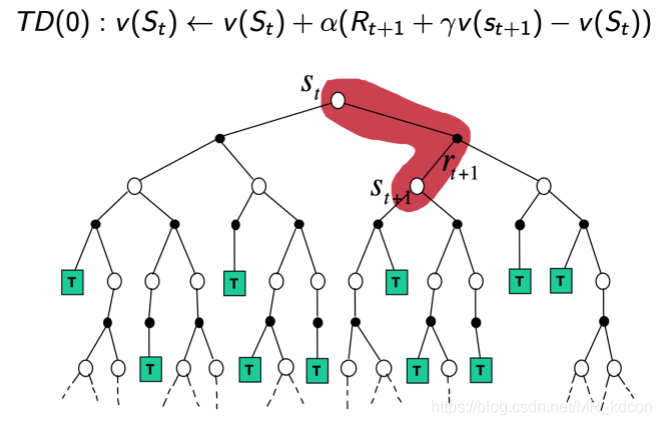
上圖三者分別是DP、MC、TD的更新價值函式的方式,DP是廣度的極端,MC是深度的極端,TD是介于DP與MC之間的方式,
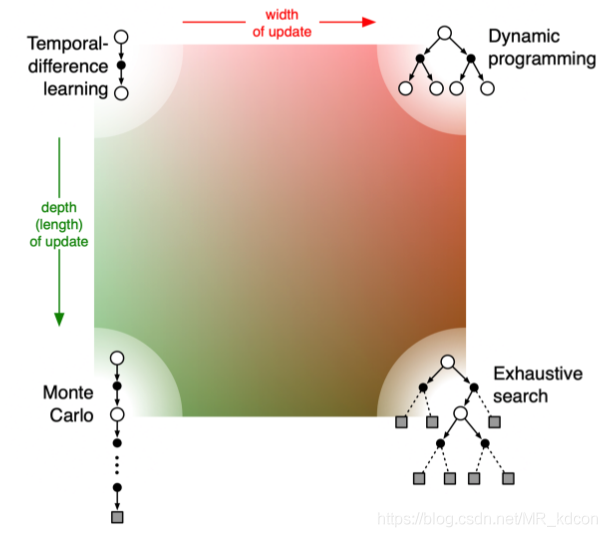
上圖說明了DP、MC、TD、窮舉四種方式的關系:
TD在廣度上擴展就是DP,TD在深度上擴展就是MC,TD同時在深度和廣度上擴展就是窮舉,
3.1.3、
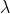 時序差分學習TD():
時序差分學習TD():
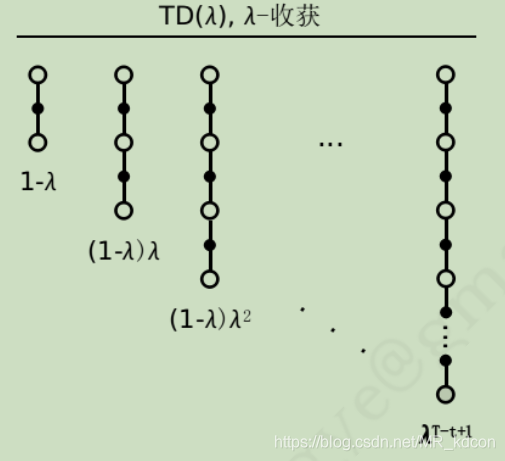
一般的時序差分學習是每走一步,就更新價值函式,即TD(0),那么我們還可以推廣到1步、2步,,,,,
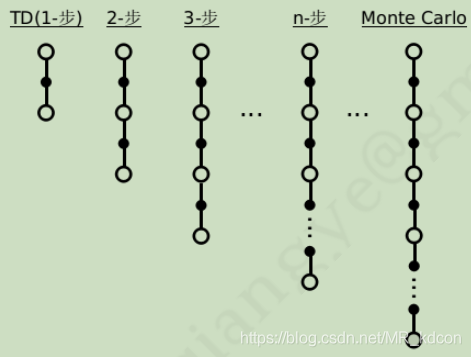

如上圖所示,當步伐為inf時,TD就變成了MC,當n=1時候,TD就變成了TD(0),那么是否存在一個n,使得其兼具TD和MC的優點呢?
這個n是個超引數,需要根據不同問題去制定這個值,
為了綜合考量不同步的識訓,引入引數,定義
識訓為(
是個介于0-1之間的數):
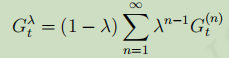 ,對應的更新公式為:
,對應的更新公式為: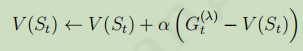
n步識訓的權重為:
3.2、model-free的控制問題(重點放在MC、Sarasa、TD):
在model-based中,我們采用策略迭代和值迭代的方式去尋優:
但MC和TD是基于model-free的方式,即不知道環境中的P和R,因此不能使用上述方法去求解,
model-based中的貪心策略也無法再使用,為什么呢?
因為MC、TD演算法都是在采樣有限次下、遍歷狀態數有限下進行的策略評估,因此會有存在一些實際存在高價值得狀態但未被搜尋到的,以及一些低價值的,因為遍歷次數少,所以價值估計不準確,如果仍采用貪婪策略,那么這兩種情況的狀態將被忽視,低價值遍歷少的那些狀態將無法被提高(最優策略下每個狀態的值函式必定達到最高),因此就無法形成最優策略,model-based可以使用貪婪策略是因為動態規劃考慮到了所有的狀態,
因此,還需要引入-greedy策略,就是之前提過的奶茶店的例子,在這里我們重新再說明一下,如下圖所示:

這個策略就是貪心策略和均一策略的一個trade-off,其中這個是用于選擇均一策略的概率,在一開始的時候,Q表被初始化為全0,因此需要較大的探索,即
較大,隨著采樣的進行,各個狀態動作對的價值也摸得差不多了,就逐漸減小
,更加注重利用,
如下圖所示,當使用MC和-greedy策略時,和DP中一樣,我們確保值函式是單調遞增的,證明如下:

還有一個關于on-policy和off-policy的概念:

那么MC和TD用什么方式去解決控制問題呢?
在說明之前,由于DP中最后求出最優策略都需要用狀態值函式轉換成Q函式,然后得出最優動作,那是因為有P和R,而MC和TD沒有直接用于轉換的P和R,因此在TD和MC中我們直接采用動作狀態值函式(以下簡稱Q函式),而不再使用V去更新價值,
現實策略MC中策略迭代的偽代碼如下:

與DP中類似,只是換了一種方式更新值函式,同理,MC學習可以收斂至最優,獲取最優狀態動作值函式,
MC策略迭代出最優策略,必須要滿足GLIE條件(Greedy in the limit with the infinite exploration),即:
1、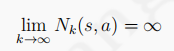 :每個狀態動作對都被無限次訪問到,意味著采樣次數多,那么Q和目標target就能無限接近,
:每個狀態動作對都被無限次訪問到,意味著采樣次數多,那么Q和目標target就能無限接近,
2、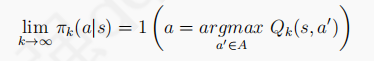 :策略最終趨向于貪婪策略,借鑒MDP中最優策略的產生是使用了純貪婪策略,當探索到一定的時候,
:策略最終趨向于貪婪策略,借鑒MDP中最優策略的產生是使用了純貪婪策略,當探索到一定的時候,最好為0以保持純貪婪策略,
滿足GLIE條件,MC才能收斂至最優策略: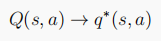
在MC的控制問題中,Q同樣也不是單調遞增的,例如,根據MC演算法,s狀態是走向終點經過的一個狀態,從Q(s,)開始,走到終點,最后計算G1,Q(s,a1)通過軟更新靠近G1=100,由于ε=1/k,接下來策略改變了,比如說從Q(s,)開始,走到終點,最后計算G2,Q(s,a2)通過軟更新靠近G2=10,本來在狀態s,他會隨機性探索每個動作,當貪心策略出現的時候,他就會選擇動作a1,因為a1產生的G更大,但就算是從a1這個方向走出去,在通向終點的路上也會出現岔路口,就會出現不同的G(由于這時候不同的G可能相差很大,即方差很大,所以Q(s,a1)的更新就會不穩定),這時候貪心策略的出現就會擺脫Q(s,a1)跑來跑去的狀況,他會選擇G最大的那個岔路口,然后讓Q(s,a1)慢慢一步步增大至最大那個G,這就是貪心策略增大Q值的原因,不過這只是區域最大,當探索足夠深的話,最侄訓找到全域最大,也就是屬于Q(s,a1)的最優值函式,
Sarsa演算法:on-policy TD演算法:
Sarsa演算法就是將TD(0)中的狀態值函式改成了Q函式,
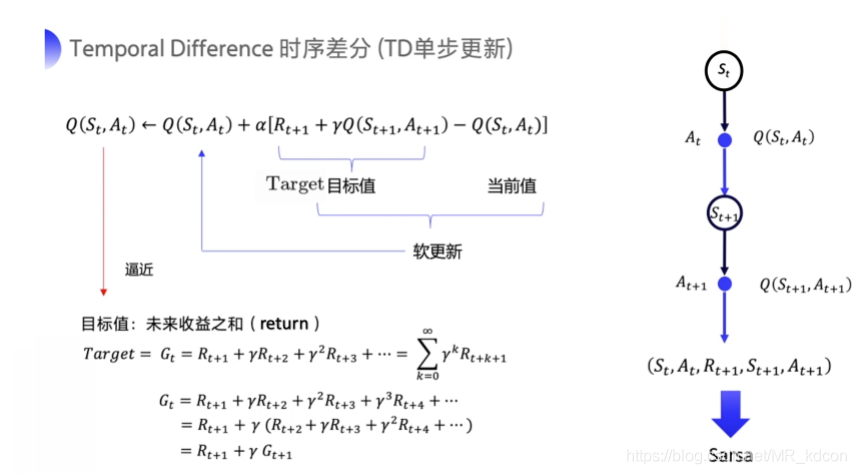
如何理解這個公式呢?
用后一個狀態動作值函式來更新當前的狀態動作值函式,
為什么用R(s,a) + * Q(s',a')來作為目標值呢?
TD演算法結合了MC和動態規劃的思想,在MC中,我們用G的樣本均值去估計Q,用Q去逼近G,這在TD中行不通,那是因為TD基于不完整序列,他并不知道未來識訓具體值,因此G是未知的,那怎么辦呢?那就得找人代替G的位置,我們的初衷是想讓G的樣本均值去估計TD的Q(s,a),然后以軟更新的方式讓Q(s,a)去逼近G,接下來我去就要去找新目標T,這個T雖然不完全等于G,但也逼近于G,接下去仔細看G=R(s,a) + * G'這個式子,R(s,a)是環境給的,我們動不了,那只能動G’了,想一想我們的最終目標是讓Q(s,a)去逼近G,那Q(s',a')不就逼近G'了嗎,那只需要把G‘改成Q(s',a')不就行了嗎,因此G的替代品就是R(s,a) +
* Q(s',a'),但由于一般Q表初始化均為0,故剛開始R(s,a) +
* Q(s',a')并不能準確代替G的大小,也就是說R(s,a) +
* Q(s',a')的樣本均值是Q(s,a)的有偏估計,有偏bias是不好的,
那如何才能變成無偏呢?或者說R(s,a) + * Q(s',a')啥時候較為準確的能代表G呢?
想一下,當某一次探索走到最終狀態,只有終止狀態前的最后一個狀態的R(s,a) + * Q(s',a')才是準確的,因為終止狀態的R(s,a) +
* Q(s',a')就是它本身的識訓R(s,a),而中止狀態的G就是R(s,a),這個值一定是準確的,那么倒退回去,終止狀態前的最后一個狀態的R(s,a) +
* Q(s',a')也就是準確的,通過軟更新來拉近不準確Q與目標的差距,此時的Q也算得上是個比較準確的評估值,然后接下來的episode中,可以將剛才那個狀態看成終止狀態,以類似的方法得出,到達這個“終止狀態”前的Q也算得上是個比較準確的評估值了,然后用這種方式慢慢倒退回去,經過許多許多個epoch之后,每一個狀態的Q都算得上比較準確的評估值了,那么他當別的狀態的Q(s',a')的時候,其實這個是動態程序,每個狀態的Q在從后往前不斷成為更加準確的評估值的同時,后面那些很早就到達一定準確度的Q又通過軟更新的方式不斷精確化自身,向著G逼近,意圖完全代替G的位置,顯然,到達一定的程度,這些Q的值就會收斂到穩定的值,即R(s,a) +
* Q(s',a')的樣本均值最終成為Q(s,a)真實值的無偏估計,Q(s,a)也接近它的真實值,這就是一整個策略評估程序,
Note:
1、我們這里最后算出來的Q(s,a)并不是Q的真實值,我們只能通過軟更新無限逼近TD目標值,而TD目標值在最后收斂的時候是Q真實值的無偏估計,因此我們實際算出來的Q只能說無限接近Q真實值,另外Q本身的定義就是識訓的期望值,是一個估計值,不完全等于識訓,是識訓的均值,
2、到了DDQN的時候,該論文的作者就會提出,在Q-learning中,其實最后穩定的Q(s,a)并不是像我們理論上接近R(s,a) + * Q(s',a'),而是高于它,即過估計,
3、就是因為GILE的原因,才會出現上述Q(s,a)越來越靠近真值的現象,Q(s,a)由小慢慢變大至收斂到最優,為什么能收斂呢?因為Q = EGt<EGt(無衰減)=Gt(無衰減),Gt(無衰減)是個常數,因此值函式是有上限的,不會倒無窮大,
4、從上面的分析也可以看出:TD演算法其實是基于值迭代的方式求出最優路徑,而MC是基于策略迭代的方式,理論上,值迭代會讓每一個狀態的值直接到達最大,但是TD對環境陌生,需要用隨機性策略去探索,Q-lerning是用2個策略相互靠近的方式達到確定性策略,確定性策略本身在值迭代程序中是最為最后一步去求出最優策略的,并不適用于加大值函式,但是在TD中,由于TD是以學習率α慢慢靠近的,用確定性策略可以加大Q值,從而加快收斂到最大值的速度,即加快了收斂,具體來說,如下圖所示:
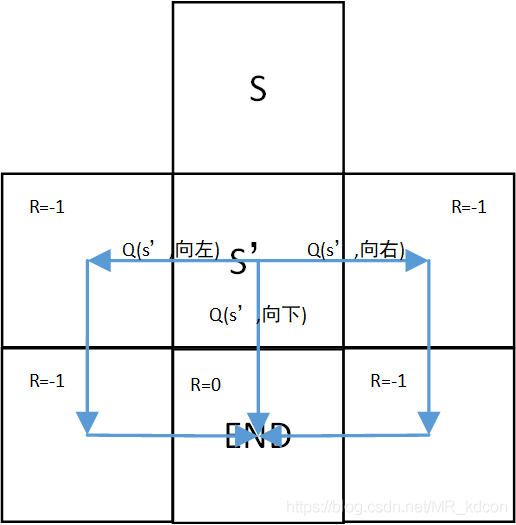 ,在TD中,顯然對于S'下的幾個動作狀態值函式都已經接近了最大值(因為離終點很近),根據確定性策略即一般說的貪心策略,Q(s,向下)就會采用S'的幾個最大值中的最大值+r來作為靠近的物件,最終Q(s,向下)就會達到他的最大值,即最優值函式,要是不用貪心策略,那么Q(s,向下)至少沒這么快到達最優值函式,
,在TD中,顯然對于S'下的幾個動作狀態值函式都已經接近了最大值(因為離終點很近),根據確定性策略即一般說的貪心策略,Q(s,向下)就會采用S'的幾個最大值中的最大值+r來作為靠近的物件,最終Q(s,向下)就會達到他的最大值,即最優值函式,要是不用貪心策略,那么Q(s,向下)至少沒這么快到達最優值函式,
5、對于Q值,不能像V值一樣保證單調遞增,但是隨著探索的加深,遍歷狀態越來越多,到達終點次數越來越多的時候,Q值就會越來越接近其執行動作a(這里指的是狀態s的所有動作)后能取得的價值Gt(帶γ的),
6、在一個策略π下,Gt的平均值是Q真實值的無偏估計,隨著值迭代,導致策略逐漸優化成最優策略的程序中,策略π雖然一直在改變,但是Gt的平均值是Q真實值的無偏估計這句話一直是對的,Gt的平均值造就了Q真實值,這個值不一定是最優Q真實值,隨著Gt的逐漸max化以及單一化,Q真實值也就成了最優Q真實值,也就是Q估計值的最終目標,唯一改變的就是方差,且最優策略的方差更小,
7、Q值不一定單調遞增,也不一定總體遞增,得看具體環境,但是最侄訓穩定下來是確定的,尋路問題,他就是總體先下降然后再上升,比如其他環境,上圖的6種游戲,那它就是逐漸上升,此外,最終的最優Q值不一定從頭到尾都是幾個動作中的最大,
8、一定要分清楚,哪怕ε-greedy中含有貪心策略,但他只是用于探索,而不是將Q值增大化,Q值的增大(優化)來源于其目標策略,
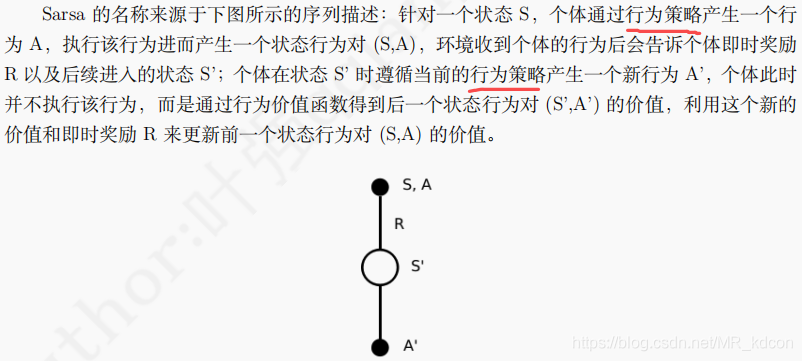
Note:
1、由于值函式的更新需要用到當前狀態s,執行動作a,然后獲取獎勵r,下一個狀態s',下一個狀態的執行動作a',因此連起來可叫Sarsa,
2、可以看出行為策略和目標策略是一個策略,因此Sarsa是on-policy的,
Sarsa演算法偽代碼如下圖:

Sarsa收斂至最優策略的條件:滿足GILE條件,并且學習率α滿足:
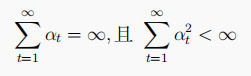
Sarsa()演算法:

Sarsa()偽代碼如下:

Q-learning演算法,off-policy演算法:
相比于on-policy演算法,off-policy有如下優點:
其中off-policy的代表就是Qlearning演算法,
Q-learning和Sarsa不同,這是一種借鑒策略學習演算法,其行為策略為-greedy策略,用于與環境互動產生動作,目標策略為貪婪策略,用于更新Q表實作最優策略,
Q-learning演算法的Q表按如下更新: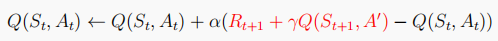 ,
,
其中A'來自于貪婪策略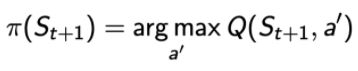
將上面個式子合成一個式子:
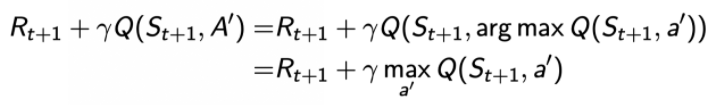 ,
,
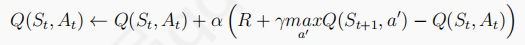
Q-learning演算法的偽代碼如下:

從上述代碼中我們可以得出Sarsa月Q-learning的不同之處:
1、Sarsa產生的A'在優化完成后的下一步一定也會被執行,而Q-learning用于更新Q表的A'在下一個step不一定會被執行,因此執行策略是-greedy策略,可能會產生隨機動作,
2、Sarsa用同一個策略產生了樣本<s,a,r,s',a'>,然后用s'和a'去更新Q表,而Q-learning只需要知道<s,a,r,s'>,不需要知道a'是什么,只要取argmaxQ(s')那個動作來更新Q表,
3、在尋找最優路徑中上,Q-learning可以表現的比Sarsa更好,或者說Q-learning比Sarsa更快找到最佳路徑,以懸崖尋路問題為例,掉進懸崖獎賞-100分,到達終點0分,其余每一步-1分,如下圖所示,當-greedy策略中的
固定時候,即還在探索階段,還沒有隨隨episode下降時,其Q-learning和Sarsa找到的路徑如下圖所示,從圖中看出,Sarsa傾向于保守路線(注意,由于
并沒有趨于0,由于還有隨機策略,故只能說大部分情況下路線如下圖所示,當
逐漸趨于0后,兩者均會收斂至最優策略),這是怎么導致的呢?

分析:
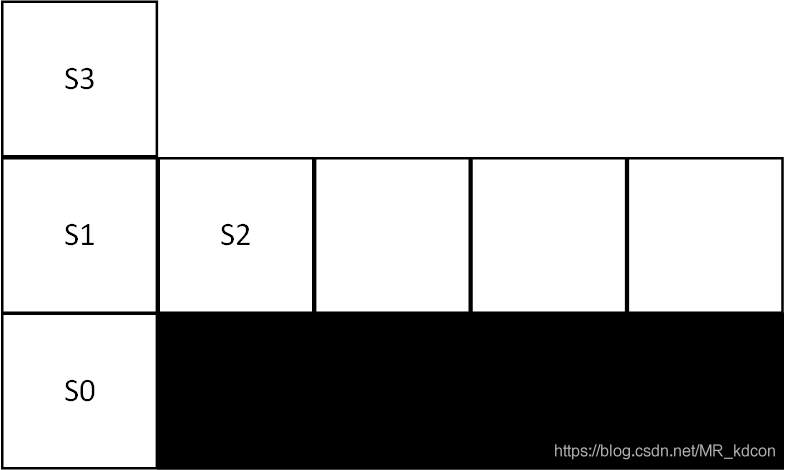
如上圖所示,我截取了前面幾個狀態來分析Sarsa和Q-learning在選擇路徑上的不同之處,(α=-0.5,=1)
首先對于Sarsa:
如上圖偽代碼所示:
1、在S0時,根據 -greedy策略,選擇a=向上,獲得s'=S1,R=-1,根據
-greedy策略,在s'=S1處選擇a'=向右,更新Q(S0,向上)=0+1/2*(-1+0-0)=-0.5,s=S1,a=向右,來到S1,
2、獲得s'=S2,R=-1,根據-greedy策略,選擇a'=向下,更新Q(S1,向右)=0+1/2*(-1+0-0)=-0.5,s=S2,a=向下,來到S2,
3、獲得s'=end,R=-100,更新Q(S2,向下)=0+1/2*(-100+0-0)=-50,s=end,重新啟動,
4、在S0時,根據 -greedy策略,選擇a=向上,獲得s'=S1,R=-1,根據
-greedy策略,在s'=S1處選擇a'=向右,更新Q(S0,向上)=-0.5+1/2*(-1-0.5+0.5)=-1,s=S1,a=向右,來到S1,
5、獲得s'=S2,R=-1,根據-greedy策略,選擇a'=向下,更新Q(S1,向右)=-0.5+1/2*(-1-50+0.5)=-25.75,
,,,
換一種探索方式:
6、在S0時,根據 -greedy策略,選擇a=向上,獲得s'=S1,R=-1,根據
-greedy策略,在s'=S1處選擇a'=向上,更新Q(S0,向上)=-1+1/2*(-1+0+1)=-1,s=S1,a=向上,來到S1,
7、獲得s'=S3,R=-1,根據-greedy策略,選擇a'=向上,更新Q(S1,向上)=0+1/2*(-1+0-0)=-0.5,s=S3,a=向上,來到S3,(對比2中,此時S1不管
-greedy策略中選用隨機策略還是貪心策略,2種方向都能被選擇,但是對比5,此時若使用
-greedy策略中的貪心策略,則Agent會避開S2,選擇S3,即避開懸崖,)
其次對于Q-learning:
1、S0,根據-greedy策略,a=向上,獲得s'=S1,R=-1,根據greedy策略,Q(S0,向上)=0+1/2*(-1+0-0)=-0.5,s=S1,來到S1,
2、根據-greedy策略,a=向右,獲得s'=S2,R=-1,根據貪心策略,Q(S1,向右)=0+1/2*(-1+0-0)=-0.5,s=S2,來到S2,
3、根據-greedy策略,a=向下,獲得s'=end,R=-100,根據貪心策略,Q(S2,向下)=0+1/2*(-100+0-0)=-50,s=end,重新啟動,
4、S0,根據-greedy策略,a=向上,獲得s'=S1,R=-1,根據greedy策略,Q(S0,向上)=-0.5+1/2*(-1+0+0.5)=-0.75,s=S1,來到S1,
5、根據-greedy策略,a=向右,獲得s'=S2,R=-1,根據貪心策略,Q(S1,向右)=-0.5+1/2*(-1+0+0.5)=-0.75,s=S2,來到S2,
換一種探索方式:
6、S0,根據-greedy策略,a=向上,獲得s'=S1,R=-1,根據greedy策略,Q(S0,向上)=-0.5+1/2*(-1+0+0.5)=-0.75,s=S1,來到S1,
7、根據-greedy策略,a=向上,獲得s'=S3,R=-1,根據貪心策略,Q(S1,向上)=0+1/2*(-1+0-0)=-0.5,s=S3,來到S3,
.,,,重新啟動
8、S0,根據-greedy策略,a=向上,獲得s'=S1,R=-1,根據greedy策略,Q(S0,向上)=-0.75+1/2*(-1+0+0.75)=-7/8,s=S1,來到S1,
9、根據-greedy策略,a=向上,獲得s'=S3,R=-1,根據貪心策略,Q(S1,向上)=-0.5+1/2*(-1+0+0.5)=-0.75,s=S3,來到S3,(對比5中,S1處此時不管
-greedy策略是均一策略還是貪心策略,Agent都有可能去選擇向右行走,不畏懼懸崖邊)
從上面段分析我們可以得出:
1、Q-learning,在已知Q(S2,向下)很小的情況下,在S1時,若選到了向右動作a(行為policy),和環境互動產生s'和R,然后呢目標policy將根據s'產生具有最大動作值函式對應的動作a',而a與a‘并沒有直接關系,即目標policy和行為policy獨立,Q(S2,向下)這個糟糕的值(很小)一定不會影響到Q(S1,向右),
2、而Sarsa,在已知Q(S2,向下)很小的情況下,在S1時,執行向右(行為policy),由于行為policy和目標policy是一體的,若接下來行為policy在S2選中向下,則目標policy跟著完蛋,即行為策略要是不好,會直接導致目標策略不好,從而使得值函式的評估出現問題,比如此時Q(S2,向下)會直接影響到Q(S1,向右)大幅下降,Q(S1,向右)大幅下降,直接導致了Q(S1,向上)>Q(S1,向右),因此只有在-greedy策略為均一策略的時候,Agent才會走到S2狀態上去,其余情況都往S3走,從而錯失了最優路徑,
3、同理,對于后續情況,Sarsa還是會采取避開懸崖邊的方案,
Q-learning較于Sarsa的好處:
1、能更快速的找到最優策略,
2、行為策略是用于探索環境,采集狀態,理解環境的策略,因為Q-learning的行為策略和目標策略獨立,行為策略并不影響目標策略,因此只要某個行為策略可以用于探索環境,則都可以充當Q-learning的行為策略,故Q-learning可以學習別的Agent的行為、老的策略產生的軌跡(探索程序需要很多計算資源,這樣可以節省資源),
3、隨著的逐漸減小,雙方都收斂至演算法層面的最優策略,但顯然Q-learning的才是真的最優策略,所以Q-learning更符號RL的目標,
Q-learning收斂的條件:
1、根據![]() 可知,St根據行為策略確定的行為價值將朝著S'狀態下貪婪策略確定的最大行為價值的方向做一定比例的更新,因此行為策略將逐漸靠近目標策略,但在實際操作程序中,比如ε-greedy策略,我們還是要手動去衰減ε的值,讓2個策略相互靠近,
可知,St根據行為策略確定的行為價值將朝著S'狀態下貪婪策略確定的最大行為價值的方向做一定比例的更新,因此行為策略將逐漸靠近目標策略,但在實際操作程序中,比如ε-greedy策略,我們還是要手動去衰減ε的值,讓2個策略相互靠近,
2、其次,該演算法也可以遍歷足夠多的狀態,
3、學習率α滿足
綜合1、2、3,Q-learning滿足GILE條件與學習率條件時,必定收斂至最優策略及最優值函式,
Part4、值函式近似
前面part3中我們用Q表來實作model-free中規劃問題的預測和控制,將Q函式定義成一張Q表,用二維陣列來存盤,index是狀態,column是動作,這種Q表最大的局限性就是當RL問題的狀態行為數過多或者動作連續的時候,就失效了,尤其當狀態數賊多的時候,Q表的存盤空間以及搜索速度都是欠考慮的,因此必須要引入值函式近似來代替Q表,
值函式近似:就是引入引數W,選取特征,通過構建一個線性(或非線性)函式去近似求出狀態(狀態動作)值函式,這樣一來,規劃的預測和控制問題都將轉變成引數的優化求解問題,
常用值函式近似:線性擬合、神經網路
三種求解價值函式的架構:
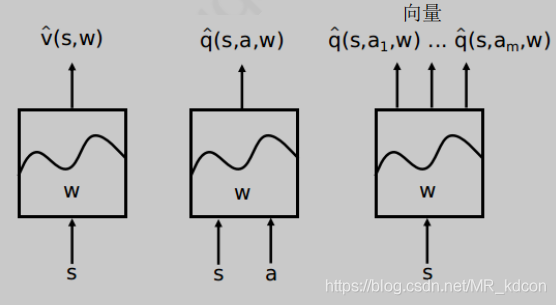
TD中價值更新:
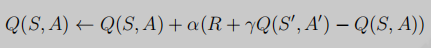
值函式近似中價值更新:
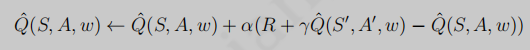
但上述值函式近似很難實作,但我們可以通過定義loss function,然后通過梯度下降完成策略評估,
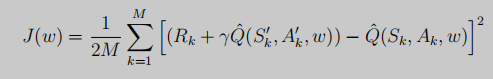
用Q-target來表示:
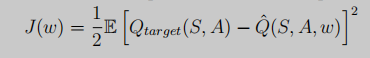
Part5、DQN:
DQN(Deep Q-Network) 是強化學習與深度學習的一個結合,即將Q-learning演算法與深度網路進行聯合,從而讓智能體agent進行學習,DL為agent提供學習的大腦,RL提供了計算機制,從而達到真的AI,
5.1、DQN提出的原因:
Q-learning演算法,使用Q表來存盤動作狀態值函式,通過不斷嘗試來更新Q表,最終達到收斂,找到了最優策略,但是其缺陷在于Q表的容量和搜索范圍,當一個任務的狀態數目賊多,比如圍棋、影像,那么對Q表的存盤量是個考驗,此外,搜索也是個問題,另一方面,若任務的狀態值是個連續值,比如接下去的小車位置、速度,Q表是不夠用的,因此需要用值函式近似的方法,用一個非線性函式去擬合動作狀態值函式,達到升級版Q表的角色,擬合這件事neual network就很擅長,輸入是個狀態,輸出則是狀態對應的各個動作的值,這不就相當于是Q表了嗎,這就是通過nn來做值函式近似,并且nn不怕你輸入繁多的狀態,也不怕你輸入是連續值,故Q-learning將Q值存盤的方式改成神經網路,那么DQN初步就形成了,當然DQN強大的原因,并不在于此,
5.2、DQN演算法(Nature DQN):
5.2.1、演算法:
首先來一波論文率先提出的偽代碼:(下圖是2013年提出的第一代NIPS DQN,2015年在原有基礎上增加了Target-Q-network,就是下面翻譯部分)

翻譯一下:(2015年Nature DQN演算法)
1、初始化引數N(記憶庫),學習率lr,貪心策略中的
,衰減引數
,更新步伐C
2、初始化記憶庫D
3、初始化網路Net(本實驗選擇一個2層的網路,其中隱藏層為50個神經元的FC層),將引數W和W_指定為服從均值為0,方差為0.01高斯分布,并例化出2個相同的網路eval_net(以下簡稱Q1)和target_net(以下簡稱Q2),
4、for episode in range(M):
5、 初始化狀態observation
6、 for step in range(T):
7、 通過貪心策略選中下個動作action,其中Q(s, a)來自于eval_net的前向推理,
8、 通過環境的反饋獲得observation'以及獎勵值reward,
9、 將observation、observation'、action、reward打包存入記憶庫D中,
10、 當記憶庫存滿之后,抽取batch個大小的資料(sj, sj', aj, rj)送入2個網路中
11、 以損失函式L = *
( rj +
* max(Q2(sj';W_)) - Q1(sj,aj;W))^2 進行訓練
12、 每隔C步,更新target_net的引數W_ = W
下面這張博主畫的圖可以很好實作上述的偽代碼程序:
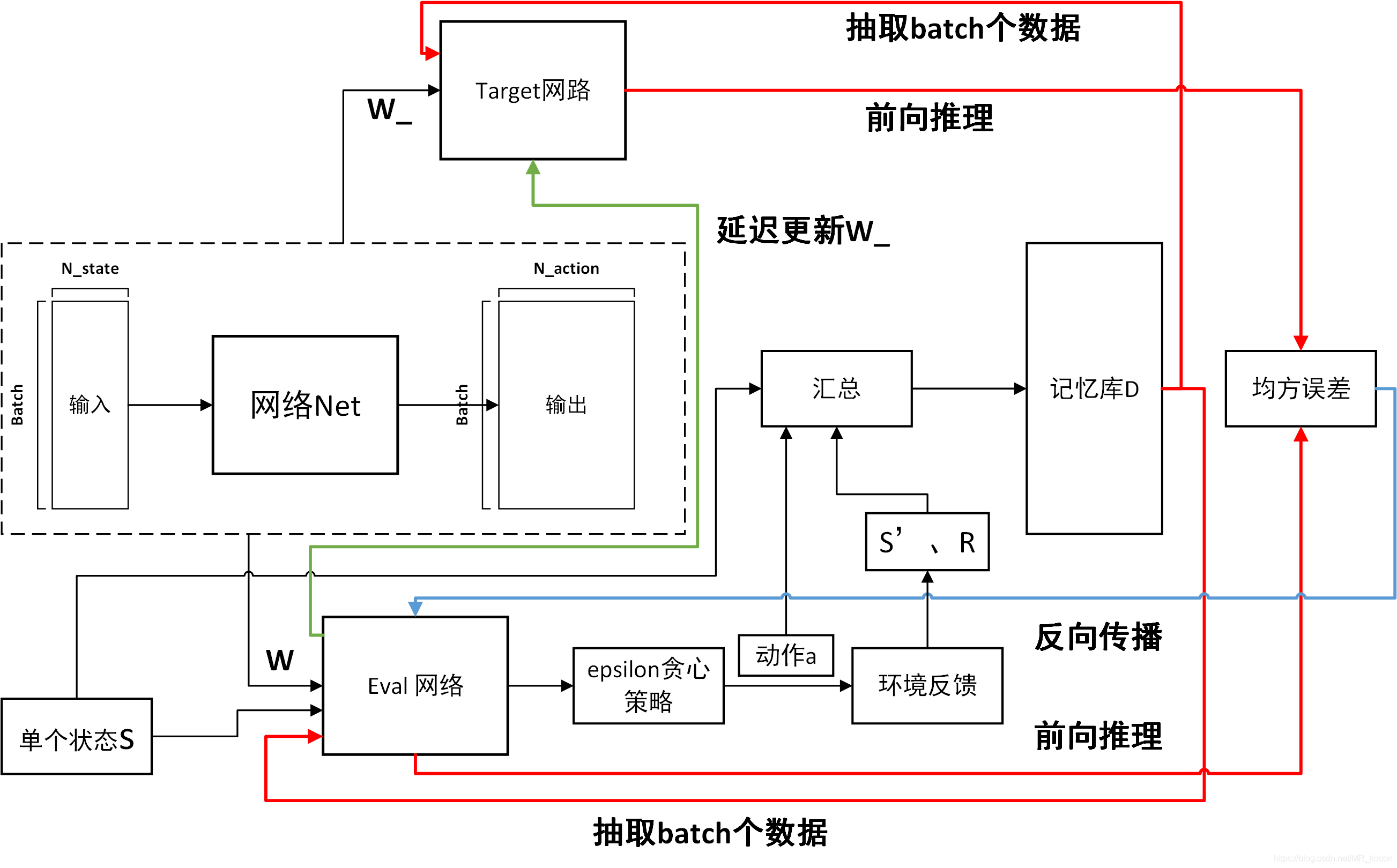
Note:
1、target_net是不需要參加訓練的,其引數的更新來源于eval_net的復制,
2、探索率要隨著迭代行程不斷減小,以到達收斂至最優策略的效果,
5.2.2、DQN強大的原因:
5.2.2.1、引入經驗池:就是用一個二維陣列將過去的樣本存盤起來,這個過去的樣本包括不同不同episode的樣本,包括不同策略的樣本(ε一直在變),供之后網路訓練用,具體來說,經驗池的引入:
a、首先Q-learning為off-policy演算法(異策略演算法,Sarsa為同策略,on-policy演算法),也就是說,其生成樣本<s,s_,r,a>的策略值函式更新的策略不一樣,生成策略是-greedy 策略,值函式更新的策略為原始策略,故可以學習以往的、當前的、別人的樣本,而經驗池放的就是過去的樣本,或者說過去的經驗、記憶,一方面,和人類學習知識依靠于過去以往的記憶相吻合,另一方面,隨機加入過去的經驗會讓nn更加有效率,
b、其實在做RL的時候,往往最花時間的 step 是在跟環境做互動,train network 反而是比較快的,因為你用 GPU train 其實很快, 真正花時間的往往是在跟環境做互動,用 replay buffer 可以減少跟環境做互動的次數,因為在做 training 的時候,你的 experience 不需要通通來自于某一個policy,一些過去的 policy 所得到的 experience 可以放在 buffer 里面被使用很多次,被反復的再利用,
c、在訓練nn的時候,其實我們希望一個 batch 里面的 data 越分散越好,如果你的 batch 里面的 data 都是同樣性質的,這樣的訓練是容易壞掉的,如果 batch 里面都是一樣的 data,訓練的時候,performance 會比較差,我們希望 batch data 越 diverse 越好,那如果 經驗池里面的那些 experience 通通來自于不同的 policy ,那你 sample 到的一個 batch 里面的 data 會是比較分散的 ,
d、打亂樣本之間的時間相關性,回顧nn中輸入樣本之間是無關的(除了RNN比較特殊),隨機性抽取有利于消除輸出結果對時間連續的偏好,
e、每次抽取batch個資料正適合nn的前向和后向傳播,
5.2.2.2、引入Target-Q-network
a、這個網路的輸出通過取max,乘以,加上reward,作為標簽y,這是由于Q-learning是值迭代演算法,r +
* max(Q2(s_,a')是target Q,與Q-learning一樣,DQN用這個作為標簽,讓Q(s,a)去無限接近標簽,從而找到最優策略,
b、延遲更新網路,第一代的NIPS DQN是和Q(s,a)同時更新的,這就使得演算法的穩定性降低,Q值可能一直就靠近不了target Q,就如貓捉老鼠的栗子一樣:
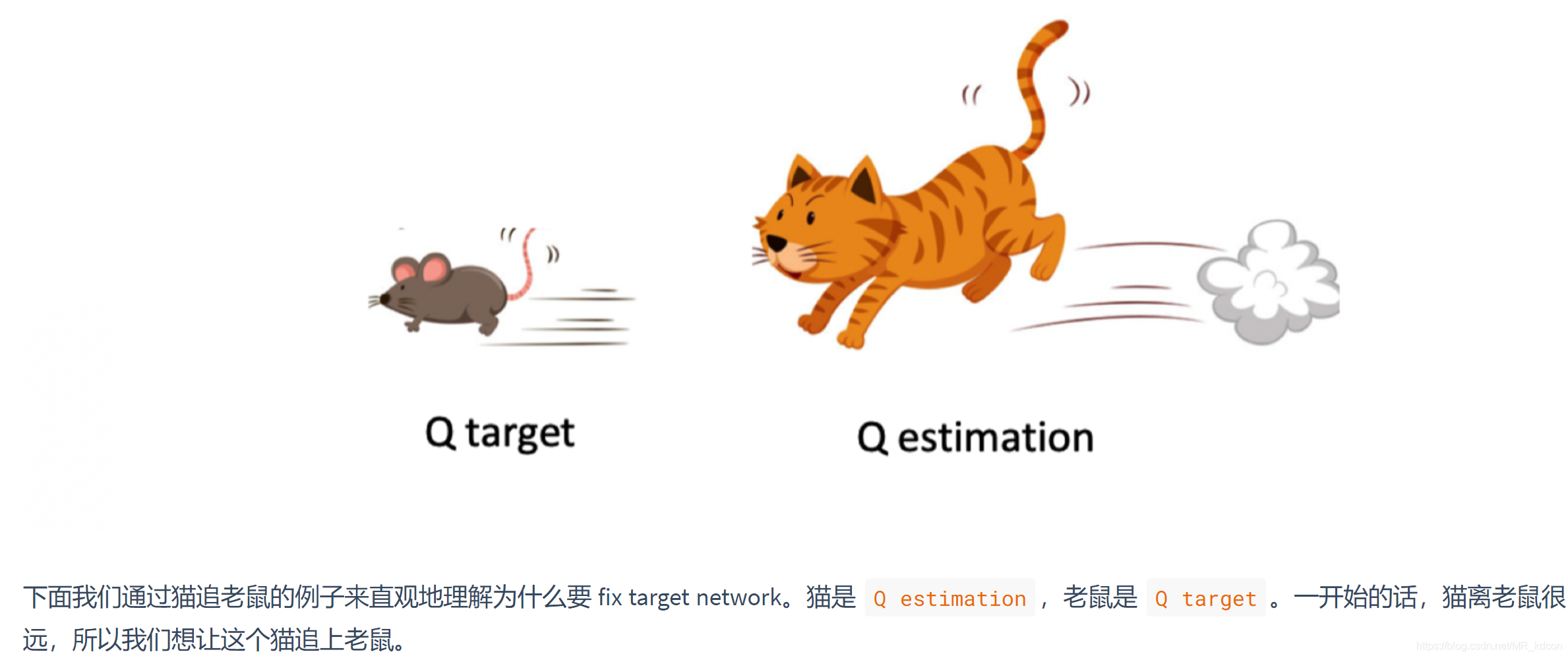


但也不能不變,比如Target-Q-network剛初始化后,其產生的Q(s',a')是不準確的,就像Q-learning中Q(s',a')由于剛開始時候,也不住準確,都是0,但接下去會不斷更新Q表,一段時間后,下一嘗試同一個Q(s',a')出現時,此時Q(s',a')已經更新了,從第0次嘗試->收斂程序中,Q(s',a')一定是在不斷更新,從0到最優值,因此Target-Q-network中的網路引數不能一塵不變,一段時間后,也需要更新,
c、另外,回顧下監督學習中,標簽是個不隨網路引數W變動的值,因此,一定時間內,需要維持不變,既為了穩定,又為了符合監督學習的特性,
5.3、DDQN:
用于解決Q-learning和DQN中Q值被過高估計的問題,
5.3.1、DDQN提出的原因:
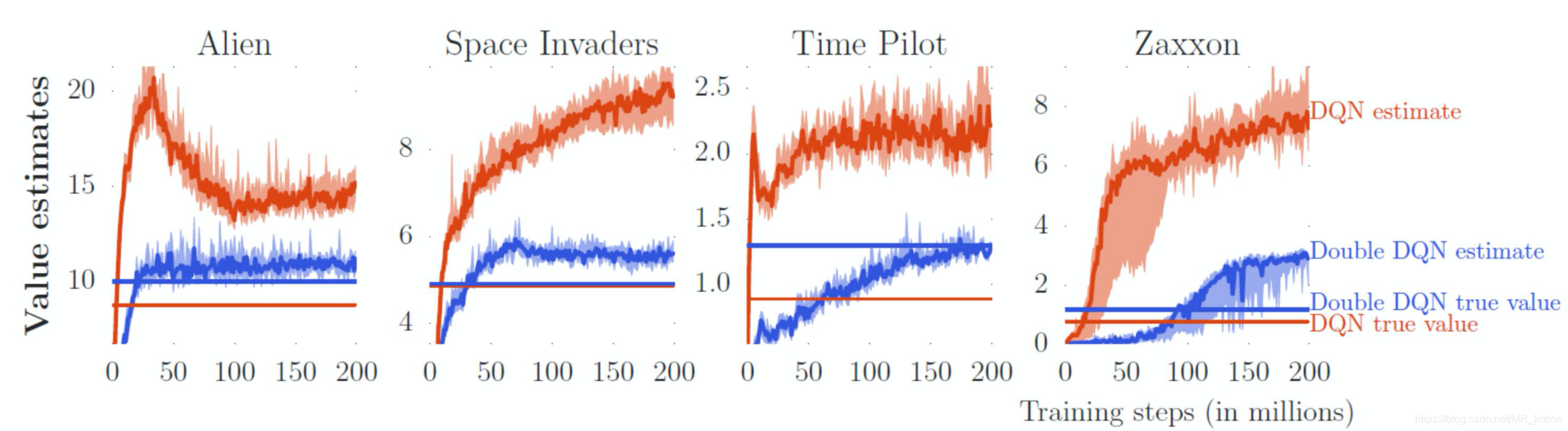
如上圖所示,提出DDQN的作者發現DQN演算法會導致Q-eval-net的結果Q值被過度估計,也就是說通過這個網路出來的Q值比真實Q值要高出很多,
上圖是論文中基于游戲Atari的實驗:
1、用訓練好的policy在游戲中不斷積累R,然后求取平均值來計算DQN和DDQN的Q(s,a)真實值true value(而且是最優值函式),
2、2條不同顏色的曲線是DQN和DDQN在訓練時,從Q_eval網路中輸出的Q值,不斷變高是因為隨著迭代加深,策略在優化,值函式在變大,最后趨于平穩說明達到收斂,
3、如果沒有過高估計的話,訓練到收斂之后,Q(s,a)應該是和真實值true value是無限接近的,
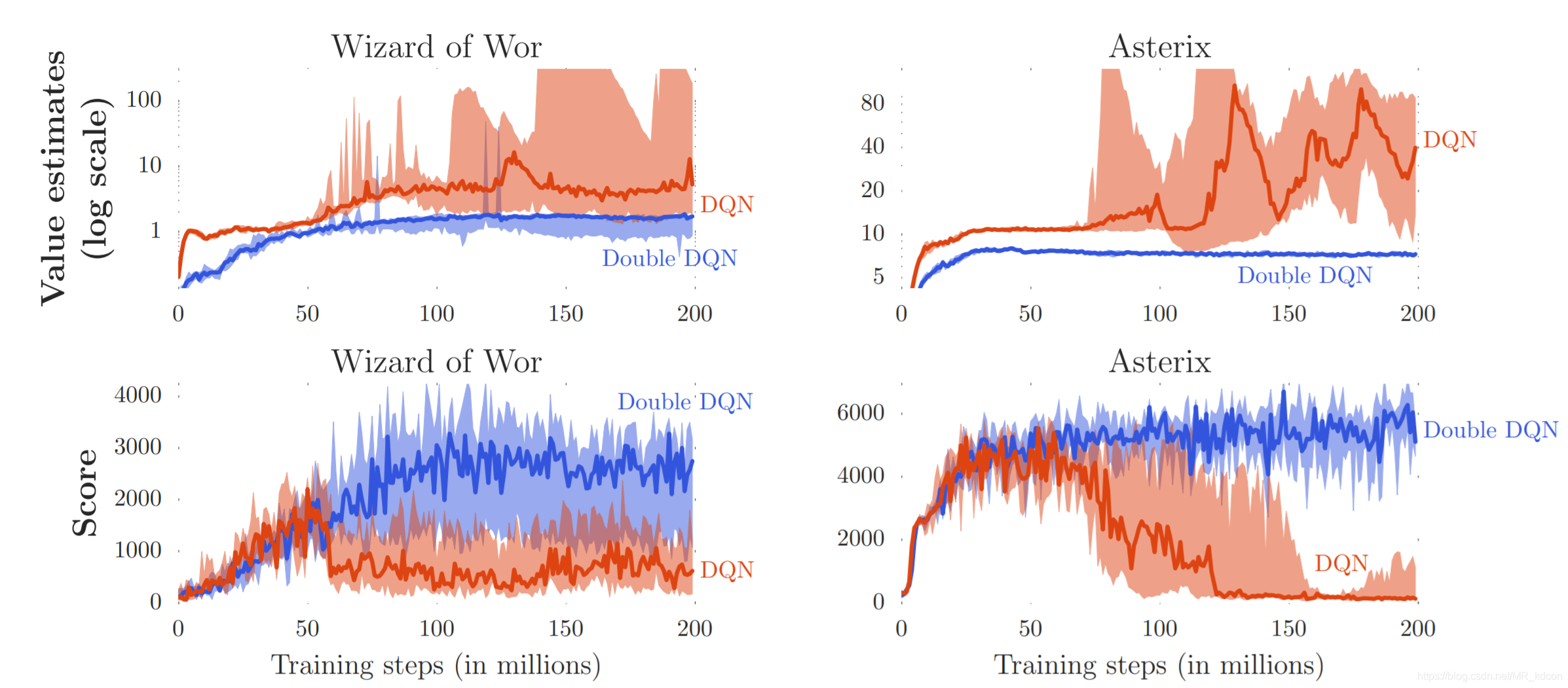
如上圖所示,Wizard of Wor和Asterix這兩個游戲中,DQN的結果比較不穩定,也表明過高估計會影響到學習的性能的穩定性(DDQN打電動顯然更強),因此不穩定的問題的本質原因還是對Q值的過高估計,
5.3.2、產生過估計的原因:
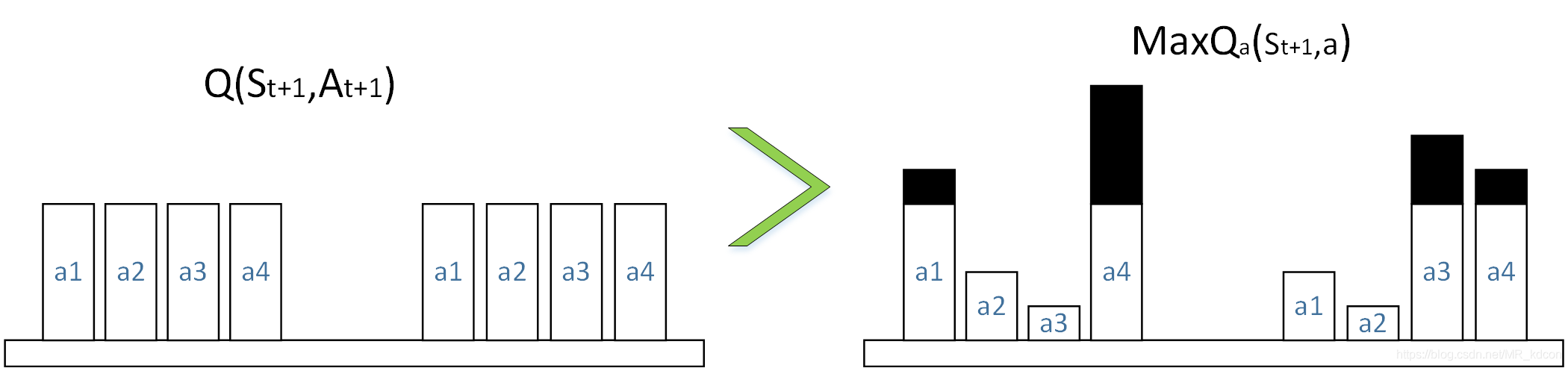
根本原因就是從Q-learning延續到DQN一直存在的->TD目標值中取max操作:
TD目標值:![]()
Q-learning(DQN):![]()
以DQN為例,如上圖所示,假設Q表中Q(s',a')的四個值相等,對比DQN采用值函式近似,TD目標值的產生是通過Target-neural-network產生的,因此其值會上下有所波動,通過取max操作后,DQN的目標值變成了過大的那個柱子,
根據公式 ,Q(s,a)通過軟更新靠近TD目標值,而TD目標值現在已經偏大,故Q(s,a)的結果也會偏高,
,Q(s,a)通過軟更新靠近TD目標值,而TD目標值現在已經偏大,故Q(s,a)的結果也會偏高,
5.3.3、DDQN演算法的改進:
DDQN在DQN的基礎上,僅僅只是改變了Q-target的計算方式,其余均沒有改變,
DQN:
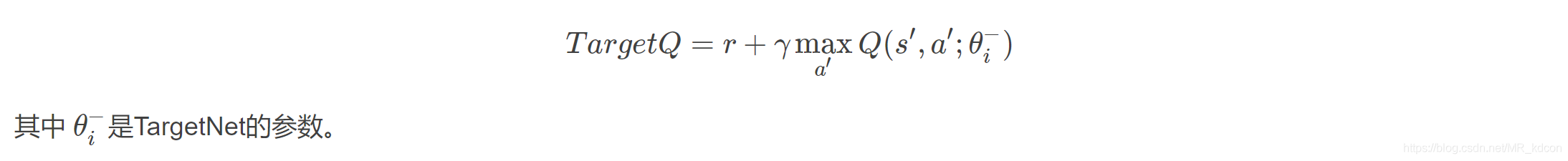
DDQN:
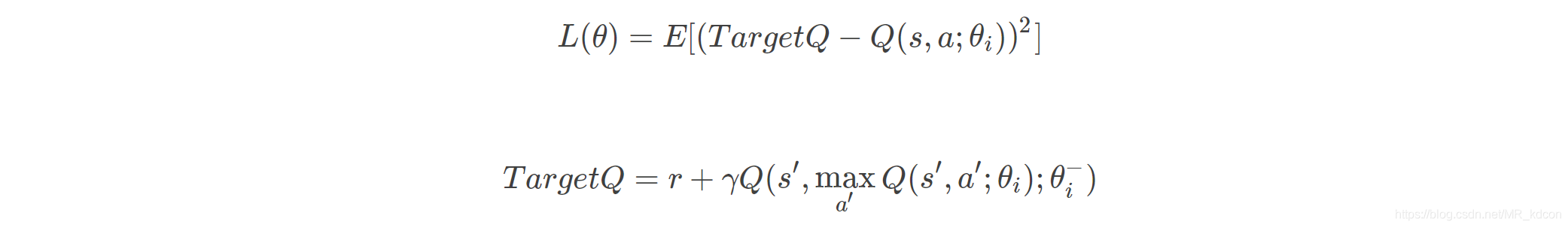
即:
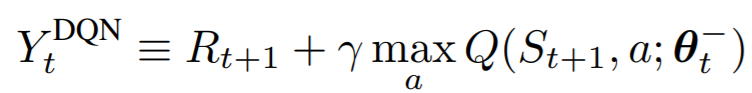
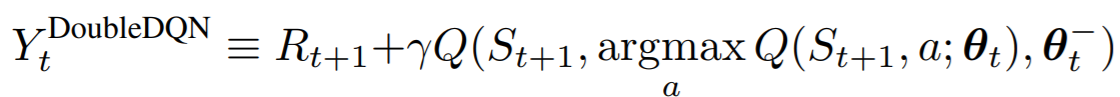
可見DDQN的好處在于:
1、當Q_eval高估了,只要Target Q不高估,結果就正常,
2、當Target Q高估了,只要Q_eval不選那個動作,結果就正常,
5.3.4、DDQN演算法:
和DQN的偽代碼一樣,區別僅僅在第11步
1、初始化引數N(記憶庫),學習率lr,貪心策略中的
,衰減引數
,更新步伐C
2、初始化記憶庫D
3、初始化網路Net(本實驗選擇一個2層的網路,其中隱藏層為50個神經元的FC層),將引數W和W_指定為服從均值為0,方差為0.01高斯分布,并例化出2個相同的網路eval_net(以下簡稱Q1)和target_net(以下簡稱Q2),
4、for episode in range(M):
5、 初始化狀態observation
6、 for step in range(T):
7、 通過-貪心策略選中下個動作action,其中Q(s, a)來自于eval_net的前向推理,
8、 通過環境的反饋獲得observation'以及獎勵值reward,
9、 將observation、observation'、action、reward打包存入記憶庫D中,
10、 當記憶庫存滿之后,抽取batch個大小的資料(sj, sj', aj, rj)送入2個網路中
11、 以損失函式L = *
( rj +
* max(Q2(sj',argmax(Q1(sj',aj';W));W_)) - Q1(sj,aj;W)) ^2 進行訓練
12、 每隔C步,更新target_net的引數W_ = W
論文地址:https://arxiv.org/pdf/1509.06461.pdf
參考:https://blog.csdn.net/ygp12345/article/details/109113322
參考:https://blog.csdn.net/OsgoodWu/article/details/78923053?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.control
參考:https://www.cnblogs.com/pinard/p/9778063.html
參考:https://zhuanlan.zhihu.com/p/97853300
更詳細的內容見我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
5.4、Prioritized experience replay:
對DQN(或DDQN)經驗回放部分按權重采樣來做優化,原則上采樣那些TD誤差值大的樣本,放棄TD誤差小的樣本,加速網路的學習,從而加快RL收斂,
主要思想:
1、改變經驗回放池的采樣方式,引入SumTree(一種樹結構),
2、改變損失函式,
3、其余結構都與DQN類似,
參考:https://www.cnblogs.com/pinard/p/9797695.html
更詳細的內容見我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
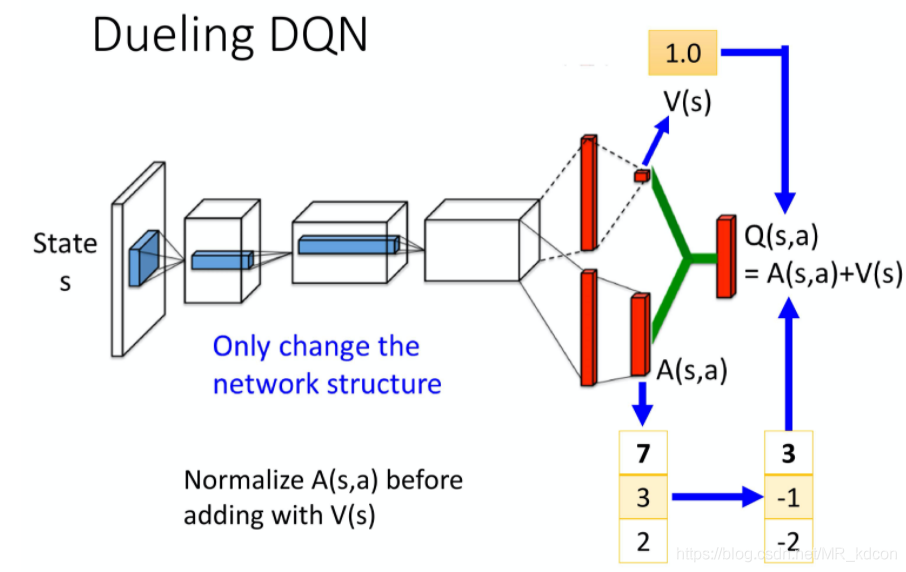
5.5、Dueling DQN:
目標:優化神經網路結構來優化目標,
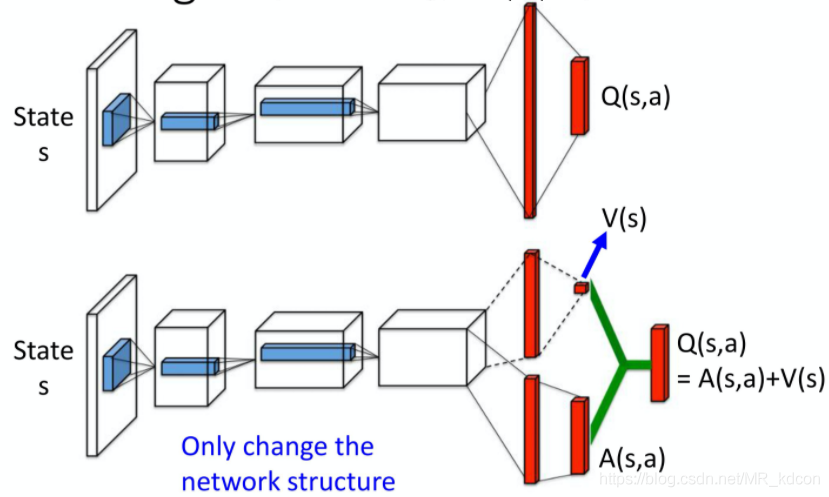
5.5.1、主要思想:
1、將Q網路分解成價值函式子網路+優勢函式子網路,價值函式子網路輸出只關于輸入特征(狀態)的標量(對不同的狀態都有一個值),因為只和狀態有關,所以叫V(S);優勢函式子網路輸出格式和之前的Q一樣(對不同狀態動作對都有一個值),換個寫法叫A(s,a),
2、Q網路的輸出由價格函式網路的輸出和優勢函式網路的輸出線性組合得到: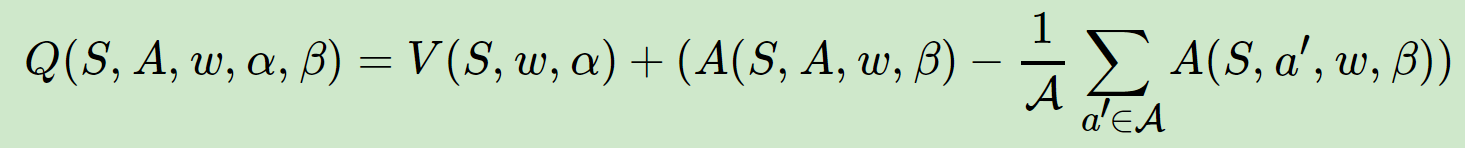
3、僅僅改變了網路結構,其余均和DQN一樣,不要動,
5.5.2、Dueling DQN帶來的好處:
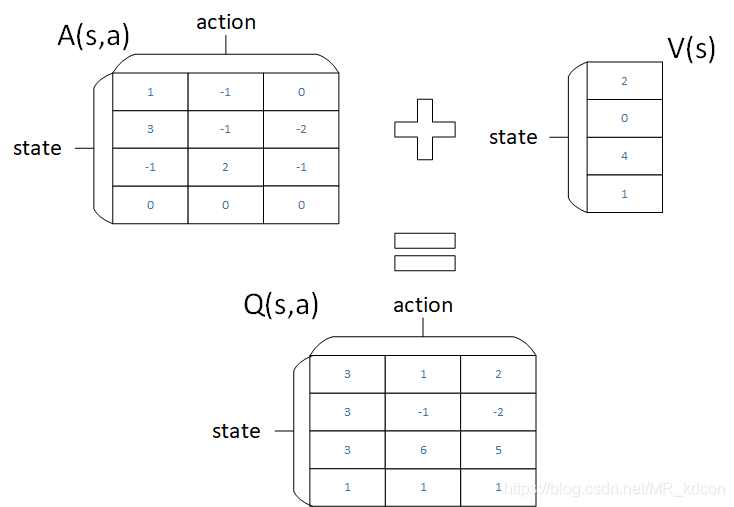
如上圖所示,假設我們將net的輸出看成是一張Q表的話,Dueling DQN的網路輸出端就是這么計算的,
如上圖所示,假如某一次從經驗池中取出來的資料只有<s1,s1',r,a0>、<s1,s2',r,a1>,而并沒有采樣到<s1,s2',r,a2>,根據L = *
( rj +
* max(Q2(sj';W_)) - Q1(sj,aj;W))^2 (Q2指Target網路,Q1指eval網路),只有A(s1,a0)、A(s1,a1)被訓練到了,A(s1,a2)由于沒有被采樣故不會被訓練,這是原本DQN的演算法,那么Dueling的改進在哪呢?在A(s,a)的基礎上增加V(S),我們通過訓練V(S),即使A(s1,a2)沒有被訓練,而由于V(S1)的存在,Q(s1,a2)就會有值的更新,這樣其實就相當于<s1,s2',r,a2>也被采樣了,其實在做RL的時候,往往最花時間的 step 是在跟環境做互動(即采樣),通過這種方式,一定程度上增加了RL的效率,那我這是只舉了3個動作,當動作很多的時候,而采樣的個數又不充分,那么這種只要一改所有的值就會跟著改的特性,就會是一個比較有效率的方法,
5.5.3、中心化處理
實際上的輸出結構并不是像5.5.2中的簡單相加,而是,這是為什么呢?
因為有一種情況下,V(S)一直都是0,那么Dueling就和DQN一樣了,毫無優勢可言,為了避免這種case,我們需要A進行限制,
如何限制呢?
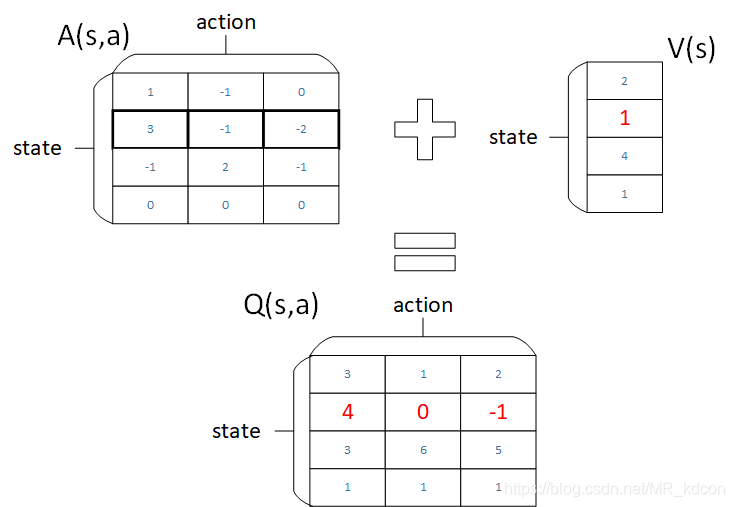
就和上面這個綠色公式一樣,將A做中心化處理,就是讓A減去他的平均值,這樣一來,你會發現,經過中心化后,A的每一行(即某個狀態的所有動作值函式)之和為0,如下圖所示:
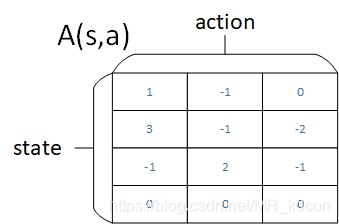
然后你根據上圖綠色公式,就會發現V的值就是Q每一行的平均值,也就是說這個平均值加上A,就是Q,
所以假設要讓整個一行一起被更新,你就不會想要更新A的某一行,因為你不會想要update A,因為 A 的每一行的和都要是 0,所以你沒有辦法說,讓這邊的值,通通都+1,這件事是做不到的,因為它的 constrain 就是你的和永遠都是要 0,所以不可以都 +1,這時候就會強迫network去更新 V 的值,然后讓你可以用比較有效率的方法,去使用你的 data,
舉個栗子:
如上圖所示,原來A(s,a) = (7 3 2),先來個中心化->A(s,a) = (3 -1 -2),然后加上V=1,最后的Q就是Q=(4 0 -1)
參考:https://www.cnblogs.com/pinard/p/9923859.html
參考:第七章 Q 學習 (進階技巧) (datawhalechina.github.io)
更詳細的內容見我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
5.6、還有一些可以改進的小技巧:
比如Noisy-net、Distributional Q-function、Rainbow
具體可參考:第七章 Q 學習 (進階技巧) (datawhalechina.github.io)
實戰演練6篇:
1、Q-learning實作一維二維迷宮探寶:
https://blog.csdn.net/MR_kdcon/article/details/109612413
2、Q-learning、Sarsa實作懸崖尋路問題
https://blog.csdn.net/MR_kdcon/article/details/110648885
3、Q-learning實作 gym 的有風格子世界及個體
https://blog.csdn.net/MR_kdcon/article/details/110600819
4、DQN實作平衡車立桿、小車爬坡(Pytorch):
https://blog.csdn.net/MR_kdcon/article/details/109699297
https://blog.csdn.net/MR_kdcon/article/details/111245496(這篇更完善)
5、基于 PyTorch 實作 DQN 求解 PuckWorld 問題
https://blog.csdn.net/MR_kdcon/article/details/110871917
6、Dueling DQN、Prioritized experience reply實作CartPole-v0、MoutainCar:
https://blog.csdn.net/MR_kdcon/article/details/111245496
總結:從實戰效果來看,對于離散狀態、動作問題,Q-learning比DQN系列的更好;對于連續狀態、離散動作可采用DQN系列演算法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240129.html
標籤:其他