sort排序、uniq重復行整理、tr對字符集替換壓縮洗掉、正則運算式
- 一、sort命令
- 二、uniq命令
- 三、tr命令
- 四、陣列排序
- 五、正則運算式
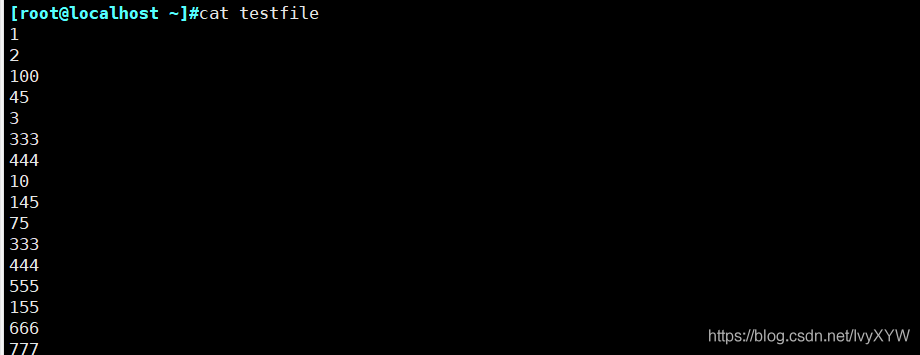
一、sort命令
-----------------------以行為單位對檔案內容進行排序,也可以根據不同的資料型別來排序-------------------------
語法格式:
sort [選項] 引數
cat file | sort 選項
常用選項:
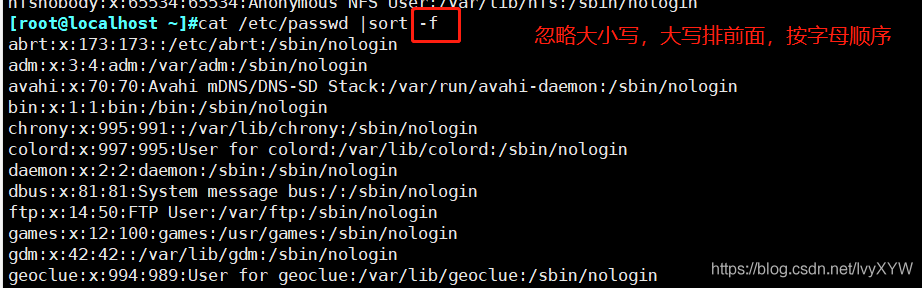
-f:忽略大小寫,默認會將大寫字母排在前面
-b:忽略前導區域的區域
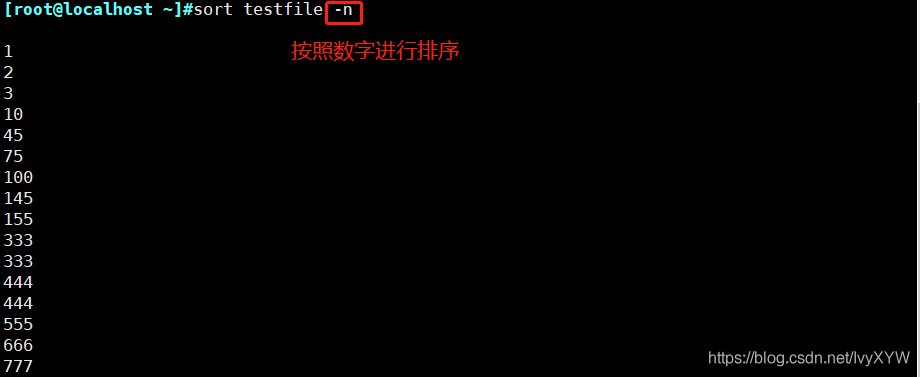
-n:按照數字進行排序
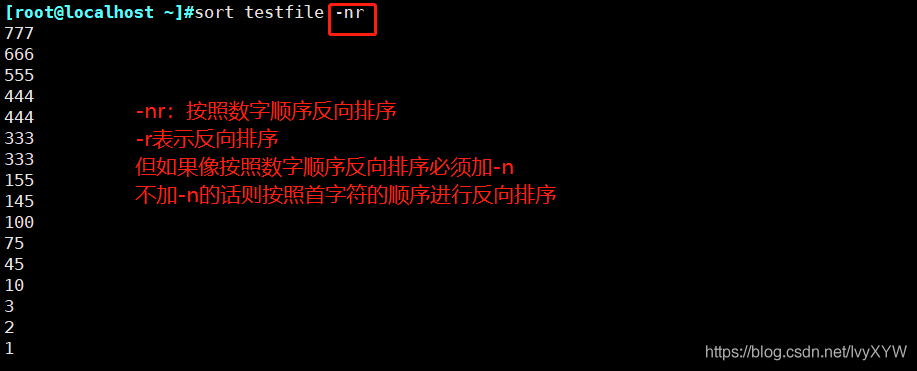
-r:反向排序
-u:等同于uniq,表示相同的資料僅顯示一行
-t:指定欄位分隔符,默認使用[Tab]鍵分隔
-k:指定排序欄位
-o<輸出檔案>:將排序后的結果轉存至指定檔案
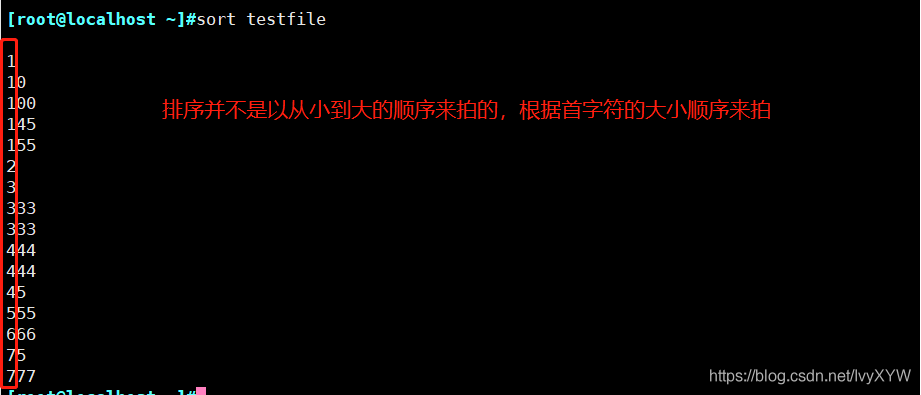
sort -n testfile2
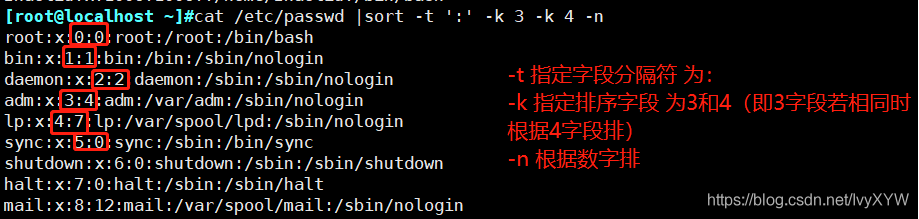
sort -t ':' -k 3 -n /etc/passwd
du -a I sort -nr -o du.txt

二、uniq命令
---------------------------用于報告或者忽略檔案中連續的重復行,常與sort命令結合使用-----------------------------
語法格式:
uniq [選項] 引數
cat file | uniq 選項
常用選項:
-c:統計連續重復的數的次數并洗掉檔案中重復出現的行,僅顯示一行
-d:僅顯示連續的重復行
-u:僅顯示出現一次的行
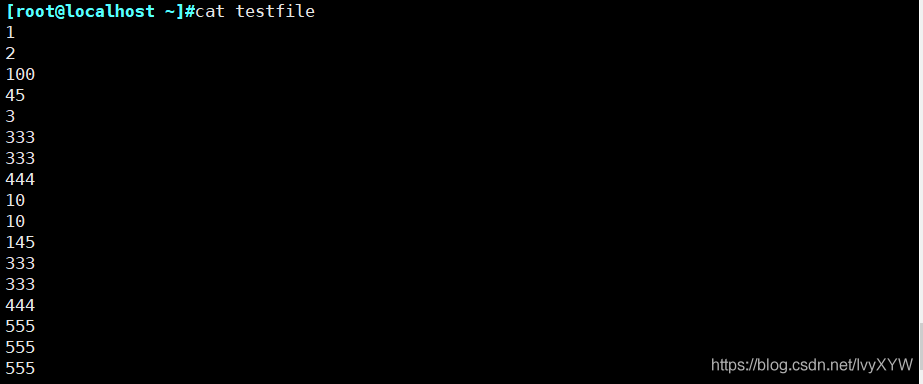
uniq testfile3
sort -n testfile3 | uniq -c



三、tr命令
---------------------------------常用來對來自標準輸入的字符進行替換、壓縮和洗掉-------------------------------------
語法格式:
tr [選項] [引數,不能是檔案]
常用選項:
-c:保留字符集1的字符,其他的字符(包括換行符\n)用字符集2替換
-d:洗掉所有屬于字符集1的字符
-s:將重復出現的字串壓縮為一個字串;用字符集2替換字符集1
-t:字符集2替換字符集1,不加選項同結果,
引數:
字符集1:指定要轉換或洗掉的原字符集,當執行轉換操作時,必須使用引數“字符集2"指定轉換的目標字符集,但執行洗掉操作時,不需要引數"字符集2";
字符集2:指定要轉換成的目標字符集,
echo "abc" | tr 'a-z' 'A-Z‘
echo -e "abc\ncabcdab" | tr -c "ab\n" "0"
echo -e "abc\ncabcdab" I tr -c "ab" "0"
echo 'hello world' | tr -d 'od'
echo "thissss is a text linnnnnnne." | tr -s 'sn'



洗掉空行
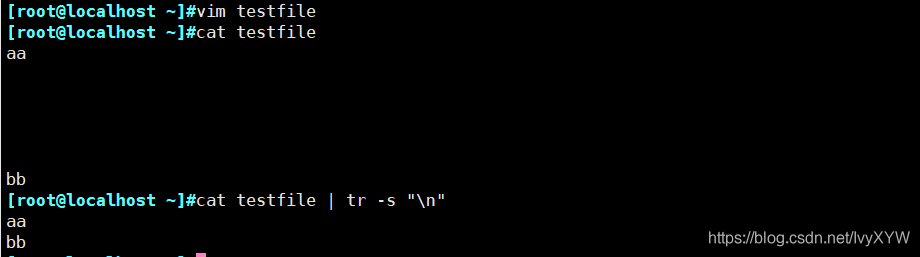
echo -e "aa\n\n\n\n\nbb" | tr -s "\n"
cat testfile4 | tr -s "\n"
把路徑變數中的冒號":",替換成換行符"\n"
echo $PATH | tr -s ":" "\n"
echo -e "aa\n\n\n\n\nbb" | tr -s "\n" ":"


洗掉Windows檔案“造成‘^M’字符:
cat file | tr -s "\r" "\n" > new_file
或
cat file | tr -d "\r" > new file
Linux中遇到換行符("\n")會進行回車+換行的操作,回車符反而只會作為控制字符('^M')顯示,不發生回車的操作,
而windows中要回車符+換行符("\r\n")才會回車+換行,缺少一個控制符或者順序不對都不能正確的另起一行,
(Linux的'^M'相當于Windows的\r,屬于不兼容的問題)
四、陣列排序
echo ${array[*]} | tr ' ' '\n' | sort -n > newfile
a=0
for i in $(cat file)
do
array[$a]
let a++
或
arrary+=($i)
done
五、正則運算式
---------------------------通常用于判斷陳述句中,用來檢查某一字串是否滿足某一格式-------------------------------
正則運算式是由普通字符與元字符組成
元字符是指在正則運算式中具有特殊意義的專用字符,可以用來規定其前導字符(即位于元字符前面的字符)在目標物件中的出現模式
基礎正則運算式常見元字符:(支持工具:grep、egrep、sed、awk)
\:轉義字符,用于取消特殊字符的含義,例:\!、\n、\$等
^:匹配字串開始的位置,例:^a、^the、^#、^[a-z]
$:匹配字串結束的位置,例:word$、^$匹配空行
.:匹配除\n之外的任意一個字符,例:go.d、g..d
*:匹配前面子運算式0次或多次,例:goo*d、go.*d
[list]:匹配list串列中的一個字符,例:go[oal]d,[abc],[a-z],[a-z0-9],[0-9]匹配任意一個字符
[^list]:匹配任意非list串列中的一個字符,例:[^0-9]、[^0-9A-Z]、[^a-z]
\{n\}:匹配前面的子運算式n次,例:go\{2\}d、'[0-9]\{2|}'匹配兩位數字
\{n,\}:匹配前面的子運算式不少于n次,例:go\{2,\}d、'[0-9]\{2\}'匹配兩位即兩位以上數字
\{n,m\}:匹配前面的子運算式n到m次,例:go\{2,3}d、'[0-9]\{2,3\}'匹配兩到三位數字
注:egrep、awk使用(n)、(n,)、(n,m)匹配時“{}”前不用加“\”
擴展正則運算式元字符:(支持的工具:egrep、awk)
+:匹配前面子運算式1次以上,例:go+d,將匹配至少一個o,如god、good、goood等
?:匹配前面子運算式0次或者1次,例:go?d,將匹配到gd或god
():將括號中的字串作為一個整體,例:g(oo)+d,將匹配oo整體1次以上,如good、gooood等
|:以或得方式匹配字串,例:g(oo|la)d,將匹配good或者glad
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240148.html
標籤:其他
上一篇:shell編程規范與變數