啟動HBase Shell,運行這個命令:hbase shell
1.一般操作
(1)查詢服務器狀態:status

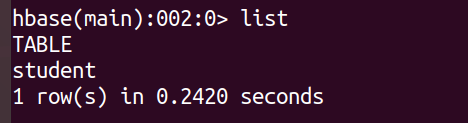
(2)查看所有表:list
2、增刪改
注意:為了避免沖突,下面的表名規則為:member + 學號,比如學號001,表名為member001,列族為address和info列族
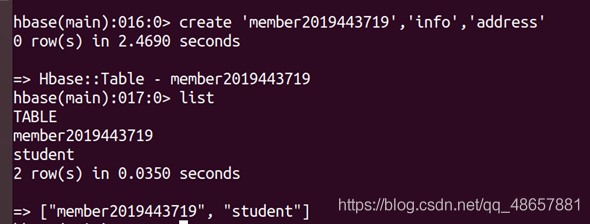
(1) 創建一個表
create ‘member2019443719’,‘info’,‘address’
(2) 獲得表的描述
describe ‘member2019443719’

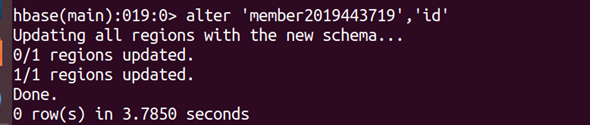
(3) 添加一個id列族
alter ‘member2019443719’,‘id’
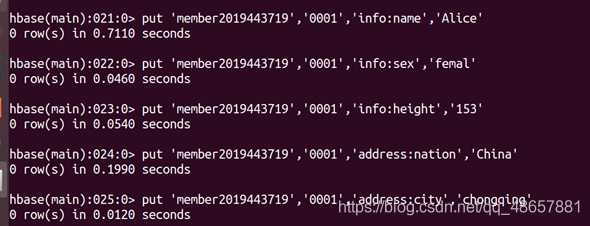
(4) 添加資料
put ‘member2019443719’,‘0001’,‘info:name’,‘Alice’
put ‘menber2019443719’,‘0001’,‘info:sex’,‘femal’
put ‘member2019443719’,‘0001’,‘info:height’,‘153’
put ‘member2019443719’,‘0001’,‘address:nation’,‘Chia’
put ‘member2019443719’,‘0001’,‘address:city’,‘chongqing’
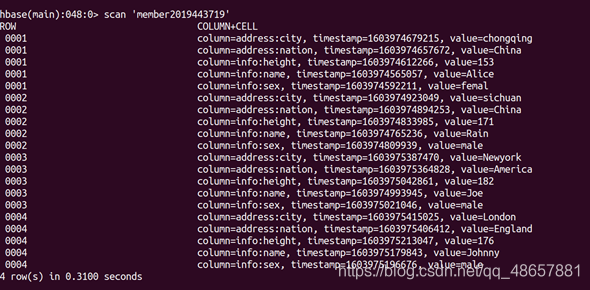
(5) 查看整張表的資料
scan ‘member2019443719’
(6) 洗掉一個id列族
alter ‘member2019443719’,{NAME=>‘id’,METHOD=>‘delete’}

(7) 洗掉資料
a) 洗掉0001行中的city列
delete ‘member2019443719’,‘0001’,‘address:city’

b) 洗掉的0004整行資料
deleteall ‘member2019443719’,‘0004’

3、查詢
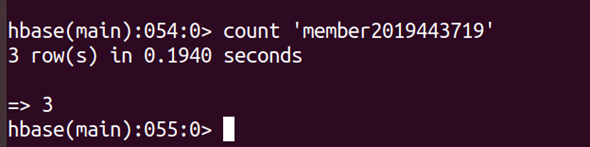
(1)查詢表中有多少行,用count命令:
count ‘member001’
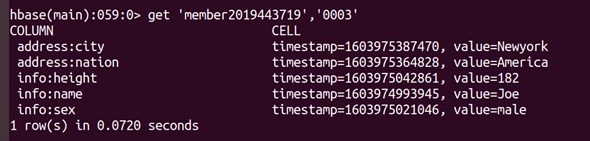
(2)get
a)獲取Joe的所有資料:
get ‘member2019443719’,‘0003’
b)獲得一個joe的address列簇中的所有資料:
get ‘member2019443719’,‘0003’,‘address’

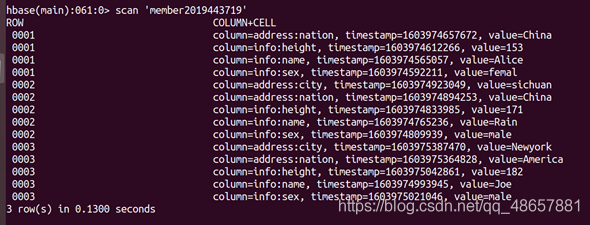
(3)查詢整表資料
scan ‘member2019443719’
(4)指定掃描其中的某個列
scan ‘member2019443719’,{COLUMN=>‘info:name’}

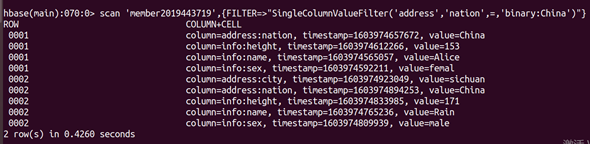
(5)Filter是一個非常強大的修飾詞,可以設定一系列條件來進行過濾,獲取國籍為中國的所有資訊,
scan ‘member2019443719’,{fILTER=>“SingleColumnValueFilter(‘address’,‘nation’,=,‘binary:China’)”}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240508.html
標籤:其他
上一篇:kafka基礎知識