期望,概率分布
- 一. 期望
- 二. 概率分布
- 三. 結語
一. 期望
根據數學計算,期望值(Expected Value)即為隨機變數的結果乘以其的概率的總和,這么看的話其實期望值也是均值,例如班里共10個人,1米8的人有3個,1米7的人有7個,那么抽到1米8的人概率為3/10, 1米7的人概率為7/10,那么這個班的身高期望值也就是這個班的平均身高即1.8*
3
10
\frac{3}{10}
103?+1.7*
7
10
\frac{7}{10}
107? .所以期望值也是均值,
當然了期望值或均值自然會被例外值干擾,例如有一個學生身高3米8,那么我們這個班的平均身高會被拉高,所以我們也可以發現,其實期望值或均值是可以不存在這個班級里的真實身高,
離散變數的期望值:
E
[
X
]
=
∑
x
∈
X
x
p
(
x
)
E[X]=\sum_{x∈X} xp(x)
E[X]=x∈X∑?xp(x)
E
[
f
(
X
)
]
=
∑
x
∈
X
f
(
x
)
p
(
x
)
E[f(X)]=\sum_{x∈X} f(x)p(x)
E[f(X)]=x∈X∑?f(x)p(x)
連續變數的期望值:
E
[
X
]
=
∫
x
p
(
x
)
d
x
E[X]=\int xp(x)dx
E[X]=∫xp(x)dx
E
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
E[f(x)]=\int f(x)p(x)dx
E[f(x)]=∫f(x)p(x)dx
舉個例子:
P(X=1)=0.5, P(X=2)=0.4, P(X=3)=0.1
那么:
E[X]=1x0.5+2x0.4+3x0.1
E[log(X)]=log1x0.5+log2 x 0.4+log3x0.1
對于兩個變數來說
E
[
f
(
X
,
Y
)
]
=
∑
x
∈
X
∑
y
∈
Y
f
(
x
,
y
)
p
(
x
,
y
)
\ E[f(X,Y)]=\sum_{x∈X} \sum_{y∈Y} f(x,y)p(x,y)
E[f(X,Y)]=x∈X∑?y∈Y∑?f(x,y)p(x,y)
E [ f ( X ) + g ( Y ) ] = E [ f ( X ) ] + E [ g ( Y ) ] E[f(X)+g(Y)]=E[f(X)]+E[g(Y)] E[f(X)+g(Y)]=E[f(X)]+E[g(Y)]
若兩個變數獨立:
E
[
f
(
X
,
Y
)
]
=
E
[
f
(
X
)
f
(
Y
)
]
=
E
[
f
(
X
)
]
E
[
f
(
Y
)
]
E[f(X,Y)]=E[f(X)f(Y)]=E[f(X)] E[f(Y)]
E[f(X,Y)]=E[f(X)f(Y)]=E[f(X)]E[f(Y)]
1.方差(Variance):
V
[
X
]
=
E
[
(
X
?
E
[
X
]
)
2
]
=
∑
x
∈
X
(
x
?
E
[
X
]
)
2
p
(
x
)
V[X]=E[(X-E[X])^2]=\sum_{x∈X} (x-E[X])^2 p(x)
V[X]=E[(X?E[X])2]=x∈X∑?(x?E[X])2p(x)從這個公式中我們可以看到,方差也是種期望(很重要),它是關于你隨機變數的值和隨機變數均值的“距離”的期望或均值,換句話說,方差是用來度量隨機變數和其數學期望(即均值)之間的偏離程度,所以我們經常說方差是看該點的離散程度,方差越大點的離散越大,方差越小點的離散度越小,在預測方面,我們也經常會說你對于未來的預測是否有信心,方差越大,說明你預測的點離散程度越大即你預測的點飄忽不定,你越沒信心,方差越小,說明你預測的點離散程度越小即你預測的點不會飄忽不定,你越有信心,這里要明確一點,有信心是否意味著你預測的準么,顯然不,這里稍微提一下偏差(bias)的概念,后續會細講,偏差即你預測的值和真值的差距,方差即你預測值的離散程度,偏差的計算有很多種,我們舉個最簡單的平均偏差,即單項測定值與平均值的偏差(取絕對值)之和,除以測定次數,你會發現,它的演算法和方差完全不一樣,不是因為距離是否被平方或被絕對值的關系,而是因為期望,是否乘以隨機變數對應的概率,總的一句話,偏差是計算預測值和均值的差距,而方差是計算差距的期望或差距的均值 =>離散度,
方差的計算轉化為
V
[
X
]
=
E
[
(
X
?
E
[
X
]
)
2
]
=
E
[
X
2
?
2
X
E
[
X
]
+
E
[
X
]
2
]
=
E
[
X
2
]
?
2
E
[
X
]
E
[
X
]
+
E
[
X
]
2
=
E
[
X
2
]
?
E
[
X
]
2
\ V[X]=E[(X-E[X])^2]= E[X^2-2XE[X]+E[X]^2]=E[X^2]-2E[X]E[X]+E[X]^2=E[X^2]-E[X]^2
V[X]=E[(X?E[X])2]=E[X2?2XE[X]+E[X]2]=E[X2]?2E[X]E[X]+E[X]2=E[X2]?E[X]2
所以
V
[
X
]
=
E
[
X
2
]
?
E
[
X
]
2
V[X]=\ E[X^2]-E[X]^2
V[X]= E[X2]?E[X]2, 這里有個小演算法E[ E[X] ]=E[X],也很簡單理解E[X]是個數值,數值的期望是它本身,例如E[3]=3 ,
方差還有一個運演算法則,即
V
[
a
X
]
=
a
2
V
[
X
]
V[aX]=a^2V[X]
V[aX]=a2V[X],這個推導也很簡單,
V
[
a
X
]
=
E
[
a
2
X
2
]
?
E
[
a
X
]
2
=
a
2
(
E
[
X
2
]
?
E
[
X
]
2
)
=
a
2
V
[
X
]
V[aX]=\ E[a^2X^2]-E[aX]^2=a^2( E[X^2]-E[X]^2)=a^2V[X]
V[aX]= E[a2X2]?E[aX]2=a2(E[X2]?E[X]2)=a2V[X]
2.協方差(Covariance)
兩個變數X,Y,則這倆個變數的協方差為:
c
o
v
(
X
,
Y
)
=
E
[
(
X
?
E
[
X
]
)
(
Y
?
E
[
Y
]
)
]
=
E
[
X
Y
]
?
E
[
X
]
E
[
Y
]
\ cov(X,Y)=E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y]
cov(X,Y)=E[(X?E[X])(Y?E[Y])]=E[XY]?E[X]E[Y]
協方差表示兩個變數的總體誤差的期望,我們從協方差的公式中可以看到,其實是方差X乘方差Y,
如果Y=X,則變化為
V
[
X
]
=
E
[
X
2
]
?
E
[
X
]
2
\ V[X]=E[X^2]-E[X]^2
V[X]=E[X2]?E[X]2兩個變數相同那就是該變數的方差,也就是說方差是協方差的一種特殊情況,數學好的同學會明白這種特殊情況本質就是:X的數學期望E(X)是X的一階原點矩,方差D(X)是X的二階中心矩,協方差Cov(X,Y)是X和Y的二階混合中心矩,再看回協方差的公式,如果X和Y這兩個變數的變化趨勢相同那么(X-E[X])和(Y-E[Y])的正負符號相同那么最后結果協變數的值為正值,如果X和Y兩個變化趨勢相反,那么(X-E[X])和(Y-E[Y])的正負符號不同,則協變數的值為負值,若X和Y互相獨立,則E[XY]=E[X]E[Y],也就說
c
o
v
(
X
,
Y
)
=
0
\ cov(X,Y)=0
cov(X,Y)=0. 但是,反過來說,如果
c
o
v
(
X
,
Y
)
=
0
\ cov(X,Y)=0
cov(X,Y)=0,那么X和Y不一定獨立,如果
c
o
v
(
X
,
Y
)
\ cov(X,Y)
cov(X,Y)不為0,則X和Y必然不獨立,
這里有幾個推導:
根據方差公式
V
[
X
]
=
E
[
X
2
]
?
E
[
X
]
2
V[X]=\ E[X^2]-E[X]^2
V[X]= E[X2]?E[X]2,我們將X+Y或者X-Y帶換X,我們將得到:
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
+
2
c
o
v
(
X
,
Y
)
V[X+Y]=V[X]+V[Y]+2cov(X,Y)
V[X+Y]=V[X]+V[Y]+2cov(X,Y), 若X,Y獨立則,
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X+Y]=V[X]+V[Y]
V[X+Y]=V[X]+V[Y]
V
[
X
?
Y
]
=
V
[
X
]
+
V
[
Y
]
?
2
c
o
v
(
X
,
Y
)
V[X-Y]=V[X]+V[Y]-2cov(X,Y)
V[X?Y]=V[X]+V[Y]?2cov(X,Y),若X,Y獨立則,
V
[
X
?
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X-Y]=V[X]+V[Y]
V[X?Y]=V[X]+V[Y]
還有幾個推導也很簡單,這里不在贅述推導程序了:
c
o
v
(
a
X
,
Y
)
=
a
c
o
v
(
X
,
Y
)
cov(aX,Y)=acov(X,Y)
cov(aX,Y)=acov(X,Y)
c
o
v
(
a
X
,
b
Y
)
=
a
b
c
o
v
(
X
,
Y
)
cov(aX,bY)=abcov(X,Y)
cov(aX,bY)=abcov(X,Y)
c
o
v
(
X
+
Z
,
Y
)
=
c
o
v
(
X
,
Y
)
+
c
o
v
(
Z
,
Y
)
cov(X+Z,Y)=cov(X,Y)+cov(Z,Y)
cov(X+Z,Y)=cov(X,Y)+cov(Z,Y)
c
o
v
(
∑
i
=
1
n
X
i
,
∑
j
=
1
m
Y
j
)
=
∑
i
=
1
n
∑
j
=
1
m
c
o
v
(
X
i
,
Y
j
)
cov(\sum_{i=1}^{n}Xi,\sum_{j=1}^{m}Yj)=\sum_{i=1}^{n}\sum_{j=1}^{m}cov(Xi,Yj)
cov(∑i=1n?Xi,∑j=1m?Yj)=∑i=1n?∑j=1m?cov(Xi,Yj)
V
[
∑
i
=
1
n
X
i
]
=
∑
i
=
1
n
V
[
X
i
]
+
∑
i
=
1
n
∑
j
=
1
,
j
!
=
i
n
c
o
v
(
X
i
,
X
j
)
V[\sum_{i=1}^{n}Xi]=\sum_{i=1}^{n}V[Xi]+\sum_{i=1}^{n}\sum_{j=1,j!=i}^{n}cov(Xi,Xj)
V[∑i=1n?Xi]=∑i=1n?V[Xi]+∑i=1n?∑j=1,j!=in?cov(Xi,Xj),j!=i,否則變成方差了
與協方差關系很緊密的概念是相關系數,相關系數(Correlation) 公式為:
c
o
r
r
(
X
,
Y
)
=
c
o
v
(
X
,
Y
)
V
[
X
]
V
[
Y
]
corr(X,Y)=\frac{cov(X,Y)}{\sqrt{V[X] V[Y]}}
corr(X,Y)=V[X]V[Y]
?cov(X,Y)?為什么會有相關系數這個概念,如果我們單單有協方差,我們會發現當協方差是會受到量綱的影響,什么意思,若你X和Y本身單位是m(米),你計算完后假如是100米的協方差,若你把X和Y的單位換成厘米,那么對應的協方差將會至少擴大100倍,所以為了避免量綱的影響從而引入相關系數,我們從相關系數的公式里也會發現,分母和分子量綱將會約掉,使相關系數的結果但但是一個值,無單位,容易比較,這種方法很常見,之后我們會在高等資料分析里講到計算風險,風險的值也是無量綱的,
切回正題,
c
o
r
r
(
X
,
Y
)
\ corr(X,Y)
corr(X,Y)的值∈[0,1],值越靠近1,則說明X,Y這兩個變數關系越大且趨勢相同例如正比,否則越靠近0則說明X,Y這里變數沒有關系,
3.弱大數理論(weak law of large numbers)
假如從一個變數X里面取n個樣本,即x1,x2,…xn
那么樣本均值為:
x
 ̄
=
1
n
∑
i
=
1
n
x
i
\overline{x}=\frac{1}{n} \sum_{i=1}^{n} xi
x=n1?i=1∑n?xi
當n增加時,
x
 ̄
\overline{x}
x會收斂于X的期望 E[X].
假如這邊有n個i.i.d變數(獨立同分布變數),X1,X2,…Xn,既然同分布,那么假設該分布期望E[Xi]=
μ
\mu
μ, 當n越大,則這些變數的均值(
X
1
+
X
2
+
.
.
.
X
n
n
\frac{X1+X2+...Xn}{n}
nX1+X2+...Xn?)會向其分布的期望
μ
\mu
μ收斂. 我們用數學公式寫的好看一點,即
P
{
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
?
μ
∣
>
ε
}
→
0
,
當
n
→
∞
\ P\{ |\frac{X1+X2+...+Xn}{n} -\mu| >\varepsilon \} →0,當n→∞
P{∣nX1+X2+...+Xn??μ∣>ε}→0,當n→∞
這個公式在說,當n→
∞
∞
∞時,
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
?
μ
∣
|\frac{X1+X2+...+Xn}{n} -\mu|
∣nX1+X2+...+Xn??μ∣的值比
ε
\varepsilon
ε(一個特別小的數值,也叫做誤差例如0.001)大的概率趨近于0,也就是說
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
?
μ
∣
|\frac{X1+X2+...+Xn}{n} -\mu|
∣nX1+X2+...+Xn??μ∣的值比
ε
\varepsilon
ε還小,側面說明
X
1
+
X
2
+
.
.
.
+
X
n
n
\frac{X1+X2+...+Xn}{n}
nX1+X2+...+Xn?幾乎等于
μ
\mu
μ.
這就是大數定律里弱大數定律的一個概念,大數定律還有很多定律在總結大數所產生的規律,我在此僅把老師所講的弱大數理論和推導給大家分享下,因為該推導涉及了切比雪夫不等式,而切比雪夫不等式涉及了馬爾可夫不等式,所以在此簡略的帶大家回顧溫習下這倆個不等式,
馬爾可夫不等式(Markov’s inequality)
馬爾可夫不等式:
X 為非負數的隨機變數, a>0的任何值,則
P
{
X
>
=
a
}
<
=
E
[
X
]
a
\ P\{ X \ >=a \} <= \frac{E[X]}{a}
P{X >=a}<=aE[X]?
證明:
在此利用連續變數X和該概率分布p(x)來證明,離散變數證明大同小異,
E
[
X
]
=
∫
0
∞
x
p
(
x
)
d
x
=
∫
0
a
x
p
(
x
)
d
x
+
∫
a
∞
x
p
(
x
)
d
x
>
=
∫
a
∞
x
p
(
x
)
d
x
>
=
∫
a
∞
a
p
(
x
)
d
x
=
a
∫
a
∞
p
(
x
)
d
x
=
a
P
{
X
>
=
a
}
E[X]=\int_{0}^{∞}xp(x)dx=\int_{0}^{a}xp(x)dx+\int_{a}^{∞}xp(x)dx >=\int_{a}^{∞}xp(x)dx >=\int_{a}^{∞}ap(x)dx=a\int_{a}^{∞}p(x)dx=a P\{ X>=a \}
E[X]=∫0∞?xp(x)dx=∫0a?xp(x)dx+∫a∞?xp(x)dx>=∫a∞?xp(x)dx>=∫a∞?ap(x)dx=a∫a∞?p(x)dx=aP{X>=a}
切比雪夫不等式(Chebyshev’s inequality)
切比雪夫不等式:
假如一個X隨機變數它的E[X]=
μ
\mu
μ, V[X]=
σ
2
\sigma ^2
σ2, 那么對于任何 k>0, 則
P
{
∣
X
?
μ
∣
>
=
k
}
<
=
σ
2
k
2
\ P\{ |X-\mu |>=k \} <= \frac{\sigma^2}{k^2}
P{∣X?μ∣>=k}<=k2σ2?
證明:
我們可以把
(
X
?
μ
)
2
(X-\mu)^2
(X?μ)2看做一個非負數的隨機變數,帶入a=
k
2
\ k^2
k2,利用馬爾可夫不等式,則
P
{
(
X
?
μ
)
2
>
=
k
2
}
<
=
E
[
(
X
?
μ
)
2
]
k
2
\ P\{ (X-\mu)^2 >=k^2 \} <= \frac{E[(X-\mu)^2]}{k^2}
P{(X?μ)2>=k2}<=k2E[(X?μ)2]?
因為
(
X
?
μ
)
2
(X-\mu)^2
(X?μ)2 與
∣
X
?
μ
∣
>
=
k
|X-\mu|>=k
∣X?μ∣>=k是充分必要條件,則
P
{
∣
X
?
μ
∣
>
=
k
}
<
=
E
[
(
X
?
μ
)
2
]
k
2
=
σ
2
k
2
\ P\{ |X-\mu| >=k \} <= \frac{E[(X-\mu)^2]}{k^2}=\frac{\sigma ^2}{k^2}
P{∣X?μ∣>=k}<=k2E[(X?μ)2]?=k2σ2?
弱大數理論(weak law of large numbers)
證明:
已知這些隨機變數為i.i.d獨立同分布,那么假設這些隨機變數有有限的方差
σ
2
\sigma^2
σ2
即:
V[
X
1
+
X
2
+
.
.
.
.
+
X
n
n
\frac{X1+X2+....+Xn}{n}
nX1+X2+....+Xn?]=
σ
2
n
\frac{\sigma^2}{n}
nσ2? 和E[
X
1
+
X
2
+
.
.
.
.
+
X
n
n
\frac{X1+X2+....+Xn}{n}
nX1+X2+....+Xn?]=
μ
\mu
μ
那么利用切比雪夫不等式得:
P
{
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
?
μ
∣
>
ε
}
<
=
σ
2
n
ε
2
\ P\{ |\frac{X1+X2+...+Xn}{n} -\mu| >\varepsilon \}<=\frac{\sigma^2}{n\varepsilon^2}
P{∣nX1+X2+...+Xn??μ∣>ε}<=nε2σ2?, 當n越大時,
σ
2
n
ε
2
→
0
\frac{\sigma^2}{n\varepsilon^2}→0
nε2σ2?→0.
4.期望值的存在(Existence of expected values)
①期望值不一定總是存在的
②如果X作為我們的總體是有限的,那么E[X]總是存在,但通常情況下X作為總體一般是無窮的,
③X作為總體一般由整數或者實陣列成的,這樣的話不能保證期望值的存在,相反,四分位總是存在,
5.估計方程關于隨機變數的期望值和方差(Approximate Expectations of Functions of RVs)
假設這里有個方程f(x)和隨機變數X,我們要明確一點E[f(X)]!=f(E[X]),
假設我們已知E[X]=
μ
\mu
μ,V[X]=
σ
2
\sigma^2
σ2當然了具體的E[X]和V[X]需要你自己找,這里僅僅利用
μ
\mu
μ和
σ
2
\sigma^2
σ2做個例子,
那么:
E
[
f
(
X
)
]
≈
f
(
μ
)
+
[
d
2
f
(
X
)
d
X
2
∣
X
=
μ
]
?
σ
2
2
E[f(X)]≈f(\mu)+[\frac{d^2f(X)}{dX^2}|_{X=\mu}] ?\frac{\sigma^2}{2}
E[f(X)]≈f(μ)+[dX2d2f(X)?∣X=μ?]?2σ2?
V
[
f
(
X
)
]
≈
[
d
f
(
X
)
d
x
∣
X
=
μ
]
2
σ
2
V[f(X)]≈[\frac{df(X)}{dx}|_{X=\mu}]^2\sigma^2
V[f(X)]≈[dxdf(X)?∣X=μ?]2σ2
我們可以利用該公式找到方程的期望值和方差,這公式的本質其實是泰勒函式展開的形式,
舉個例子:
假設E[X]=
μ
\mu
μ,V[X]=
σ
2
\sigma^2
σ2,該方程f(X)=a
X
2
X^2
X2+c
那么我們能得到:
d
f
(
X
)
d
x
\frac{df(X)}{dx}
dxdf(X)?=2aX和
d
2
f
(
X
)
d
X
2
\frac{d^2f(X)}{dX^2}
dX2d2f(X)?=2a
那么帶入上述公式得:
E[f(X)]≈a
μ
2
\mu^2
μ2+c+a
σ
2
\sigma^2
σ2
V[f(X)]≈
4
(
a
μ
)
2
σ
2
4(a\mu)^2 \sigma^2
4(aμ)2σ2
二. 概率分布
講概率分布之前,先說明下寫法和基本的概念:
p
(
x
∣
θ
)
,
x
∈
X
,
θ
∈
Θ
p(x|\theta), x∈X,\theta∈Θ
p(x∣θ),x∈X,θ∈Θ
θ
\theta
θ=(
θ
1
,
θ
2
,
.
.
.
θ
k
\theta1,\theta2,...\theta k
θ1,θ2,...θk)為引數,一般引數的數量k要遠小于X總體的數量,
舉個例子:
p(x|a=1,b=2),那么該概率分布由引數a=1,和引數b=2控制該分布的形狀,Θ意味著a和b能取得值,例如a和b只能是正整數,也稱為有效引數空間,所以a,b∈Θ,
另外要提得一點是,E[X]=f(θ),V[X]=g(θ),如果隨機變數符合某個分布,那么它得期望值和方差其實可以寫成關于該分布引數的一個函式數學運算式的,
Ⅰ.高斯分布(也稱正態分布,Normal distribution)
在資料分析模型這課里,不涉及多元高斯分布,而我會在高等資料分析的課里講解,正態分布以X=
μ
\mu
μ對稱,中間高兩邊低,正態分的隨機變數是連續的,不是離散的,
正態分布的公式:
p
(
x
∣
μ
,
σ
2
)
=
(
1
2
π
σ
2
)
1
2
e
x
p
(
?
(
x
?
μ
)
2
2
σ
2
)
p(x|\mu,\sigma^2)=(\frac{1}{2\pi\sigma^2})^{\frac{1}{2}}exp({-\frac{(x-\mu)^2}{2\sigma^2}})
p(x∣μ,σ2)=(2πσ21?)21?exp(?2σ2(x?μ)2?)
這里θ=(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),
μ
\mu
μ是該分布的均值,
σ
2
\sigma^2
σ2是該分布的方差,如下是正態分布的圖: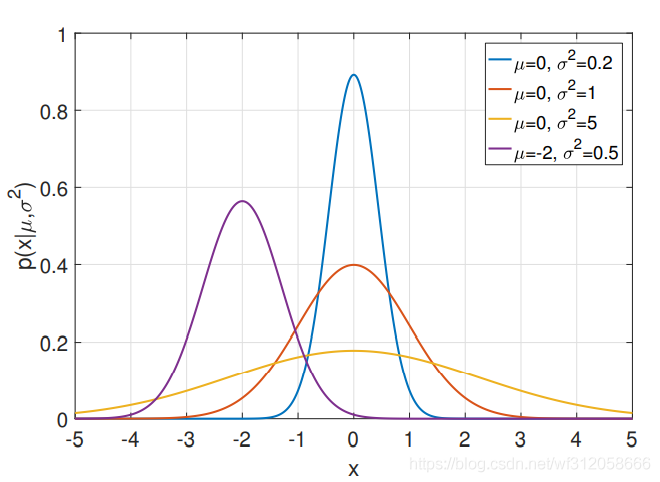
如果一個隨機變數X服從正態分布,我們的寫法是:
X
~
N
(
μ
,
σ
2
)
X ~N(\mu,\sigma^2)
X~N(μ,σ2)
E
[
X
]
=
μ
,
V
[
X
]
=
σ
E[X]=\mu, V[X]=\sigma
E[X]=μ,V[X]=σ
N(0,1)為標準正態分布(standard normal distribution)
如果Z~N(0,1), X~N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),那么:
X
=
σ
Z
+
μ
X=\sigma Z+\mu
X=σZ+μ
如果X~N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),那么:
E
[
X
]
=
μ
,
V
[
X
]
=
σ
2
E[X]=\mu,V[X]=\sigma^2
E[X]=μ,V[X]=σ2
對于任意正態分布N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),68.27%的概率會落在(
μ
?
σ
,
μ
+
σ
\mu -\sigma ,\mu+\sigma
μ?σ,μ+σ)即下圖藍色區域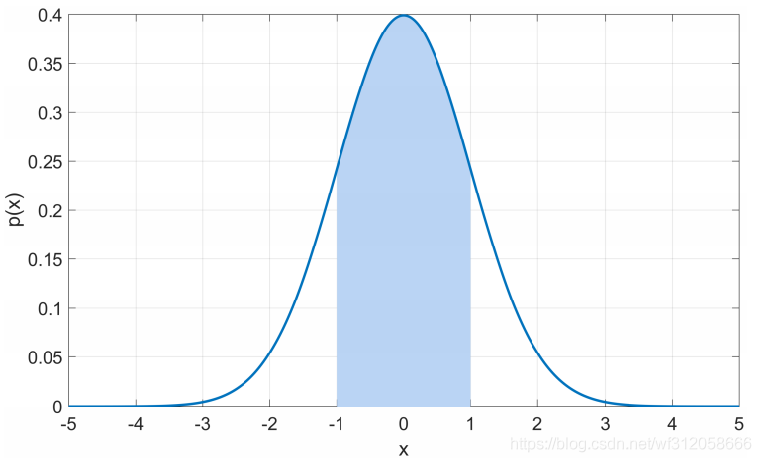
對于任意正態分布N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),95.45%的概率會落在(
μ
?
2
σ
,
μ
+
2
σ
\mu -2\sigma ,\mu+2\sigma
μ?2σ,μ+2σ)即下圖藍色區域
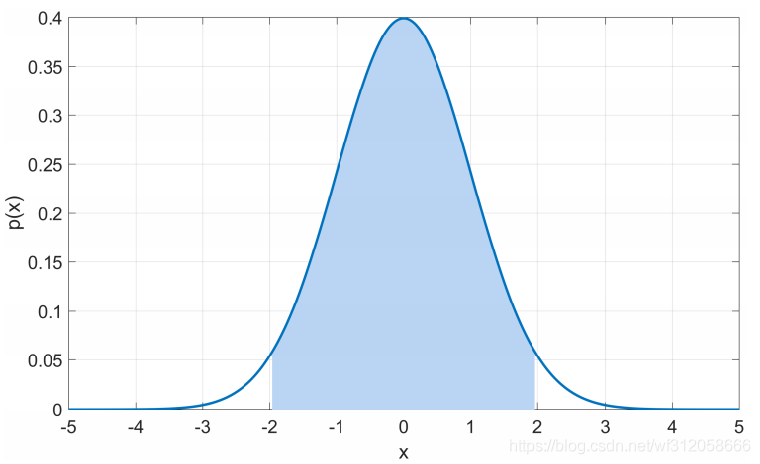
正態分布還有最后一個性質,即正態分布的可加性,
如果X1~N(
μ
1
,
σ
1
2
\mu_1,\sigma^2_1
μ1?,σ12?), X2~N(
μ
2
,
σ
2
2
\mu_2,\sigma^2_2
μ2?,σ22?)
那么,X1+X2~N(
μ
1
+
μ
2
\mu_1+\mu_2
μ1?+μ2?,
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12?+σ22?)
如果X~N(
μ
,
σ
2
\mu, \sigma^2
μ,σ2), X=
∑
i
=
1
n
X
i
\sum_{i=1}^{n}X_i
∑i=1n?Xi?,
X
i
X_i
Xi?~N(
μ
i
,
σ
i
2
\mu_i,\sigma^2_i
μi?,σi2?)
那么,
∑
i
=
1
n
μ
i
=
μ
\sum_{i=1}^{n}\mu_i=\mu
∑i=1n?μi?=μ,
∑
i
=
1
n
σ
i
2
=
σ
2
\sum_{i=1}^{n}\sigma^2_i=\sigma^2
∑i=1n?σi2?=σ2
其證明也很簡單,如果X1~N(
μ
1
,
σ
1
2
\mu_1,\sigma^2_1
μ1?,σ12?), X2~N(
μ
2
,
σ
2
2
\mu_2,\sigma^2_2
μ2?,σ22?),那么E[X1]+E[X2]=E[X1+X2]=
μ
1
+
μ
2
\mu_1+\mu_2
μ1?+μ2?, V[X1]+V[X2]=V[X1+X2]=
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12?+σ22?, 所以X1+X2~N(
μ
1
+
μ
2
\mu_1+\mu_2
μ1?+μ2?,
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12?+σ22?),
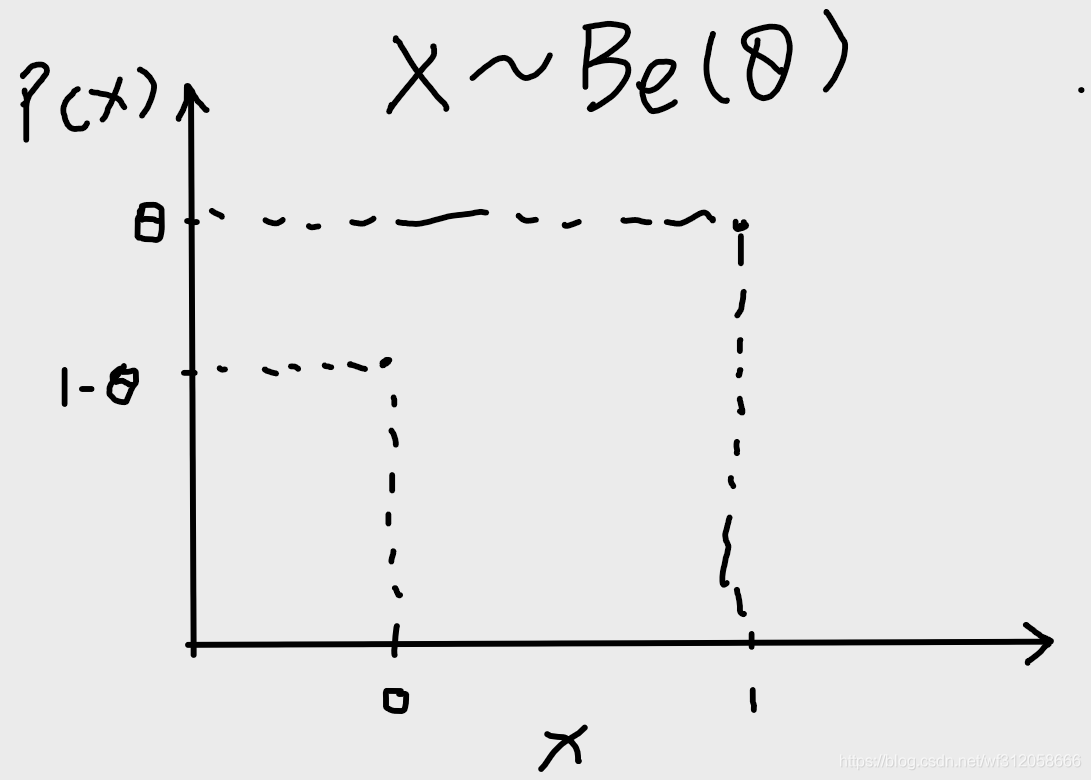
Ⅱ伯努利分布(Bernoulli distribution)
伯努利分布的隨機變數是離散的,即X={0,1}
伯努利分布公式:
P
(
X
=
1
∣
θ
)
=
θ
,
θ
∈
[
0
,
1
]
P(X=1|\theta)=\theta, \theta∈[0,1]
P(X=1∣θ)=θ,θ∈[0,1]
當X=1是代表成功,而一般我們定義
θ
\theta
θ是成功的概率,X=0是失敗,那么
1
?
θ
1-\theta
1?θ為失敗的概率,
這樣我們又可以把該公式寫成:
p
(
x
∣
θ
)
=
θ
x
(
1
?
θ
)
(
1
?
x
)
,
θ
∈
[
0
,
1
]
,
x
∈
{
0
,
1
}
p(x|\theta)=\theta^x(1-\theta)^{(1-x)} ,\theta∈[0,1],x∈\{0,1\}
p(x∣θ)=θx(1?θ)(1?x),θ∈[0,1],x∈{0,1}
如果X服從伯努利分布,那么我們可以寫成X~Be(
θ
\theta
θ).
E
[
X
]
=
θ
,
V
[
X
]
=
θ
(
1
?
θ
)
E[X]=\theta, V[X]=\theta(1-\theta)
E[X]=θ,V[X]=θ(1?θ)
推導也很簡單,因為
E
[
X
]
=
0
?
(
1
?
θ
)
+
1
?
θ
=
θ
,
V
[
X
]
=
E
[
X
2
]
?
E
[
X
]
2
=
θ
?
θ
2
=
θ
(
1
?
θ
)
E[X]=0*(1-θ)+1*θ=θ,V[X]=E[X^2]-E[X]^2=\theta-\theta^2=\theta(1-\theta)
E[X]=0?(1?θ)+1?θ=θ,V[X]=E[X2]?E[X]2=θ?θ2=θ(1?θ).
伯努利分布影像為:
我們利用伯努利分布的方差畫圖如下:
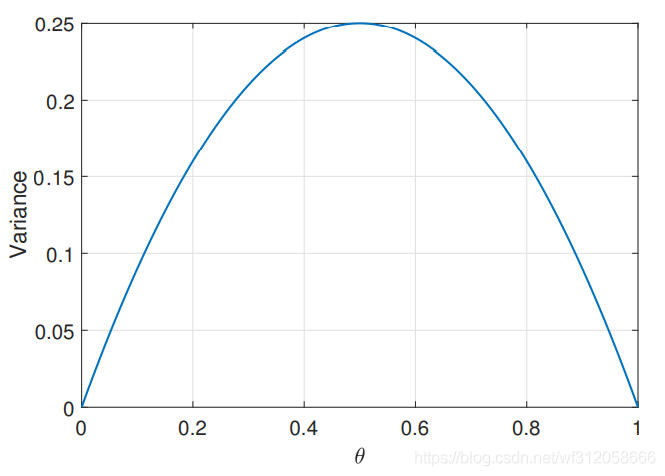
我們可以看到,當
θ
=
1
2
\theta=\frac{1}{2}
θ=21?時,方差最大,在數學意義上
θ
(
1
?
θ
)
\theta(1-\theta)
θ(1?θ)這就是個一元二次函式算極值而已,但在哲學含義上卻很值得我們思考,假設有這么A,B,C三種硬幣,A硬幣正面為人頭,反面為花色,B硬幣正反兩面均為人頭,C硬幣正反兩面均為花色,這三種硬幣都僅僅拋一次,你覺得僅靠拋這一次硬幣得到人頭的概率,我們對哪種硬幣擲出人頭的概率更有信心,當然是B和C硬幣,B硬幣擲出人頭的概率為1,C硬幣擲出人頭的概率是0.這也就是為什么
θ
\theta
θ=1或者0時,它的方差為0. 這里在稍微提一下二項式分布,二項式分布僅僅是做了n次伯努利實驗而已,假設我們做了5次拋各A,B,C硬幣的實驗,人頭為1,花色為0,我們得到A硬幣結果[0,0,0,1,1],B硬幣結果[1,1,1,1,1], C硬幣結果[0,0,0,0,0],我們當然對B硬幣和C硬幣得到人頭概率更有信心,而A硬幣人頭的概率我們卻拿不準, 從這我們也可以明白A硬幣雖然
θ
=
1
2
\theta=\frac{1}{2}
θ=21?但它的方差是很大的,預測結果很離散,你可以說它是
2
5
\frac{2}{5}
52?也可能下次你再拋5次概率又變成其它值,甚至你拋五次有可能全人頭或全花色,
Ⅲ.二項式分布(Binomial distribution)
二項式分布是做了n次伯努利試驗,即有n個隨機變數X=(X1,X2,…,Xn),Xi∈{0,1}舉個例子X=(0,1,1,1,0,1,0,0)
我們一般用n來表示有多少個隨機變數即為多少次伯努利試驗,而m來表示成功的次數,那么根據上述例子,n=8,m=4.θ是一次伯努利試驗的成功概率.
那么實驗n次,成功m次的概率即為二項式分布公式:
p
(
m
∣
θ
)
=
(
n
m
)
∏
j
=
1
n
p
(
x
i
∣
θ
)
=
(
n
m
)
θ
m
(
1
?
θ
)
(
n
?
m
)
p(m|\theta)=\begin{pmatrix}n\\m\\\end{pmatrix} \prod_{j=1}^{n} p(x_i|\theta) =\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}
p(m∣θ)=(nm?)j=1∏n?p(xi?∣θ)=(nm?)θm(1?θ)(n?m)
(
n
m
)
=
n
!
(
n
?
m
)
!
m
!
\begin{pmatrix}n\\m\\\end{pmatrix}=\frac{n!}{(n-m)!m!}
(nm?)=(n?m)!m!n!?這里涉及高中數學的排列組合,在此不再贅述,
二項式分布為離散函式,如下圖:
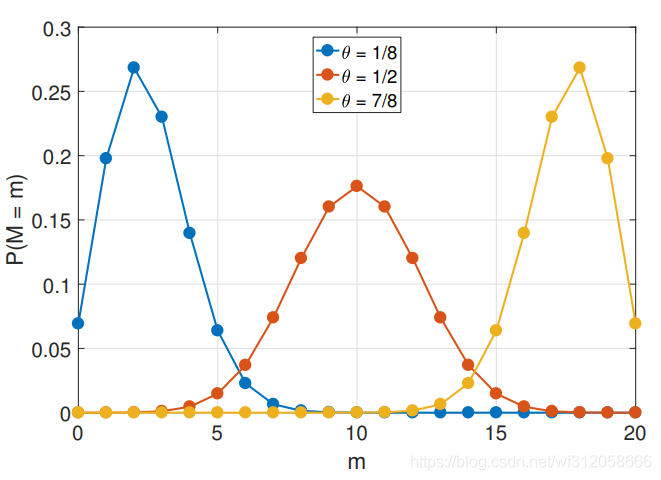
若M服從二項式分布,我們寫法為
M
~
B
i
n
(
θ
,
n
)
M~Bin(\theta,n)
M~Bin(θ,n),M為一共成功的次數.
E
[
M
]
=
n
θ
,
V
[
M
]
=
n
θ
(
1
?
θ
)
E[M]=n\theta, V[M]=n\theta(1-\theta)
E[M]=nθ,V[M]=nθ(1?θ)
推導也很簡單,因為進行了n次伯努利分布實驗,每次實驗獨立,則E[M]=n*(0*(1-θ)+1*θ)=nθ,根據我們之前講的若
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
+
2
c
o
v
(
X
,
Y
)
V[X+Y]=V[X]+V[Y]+2cov(X,Y)
V[X+Y]=V[X]+V[Y]+2cov(X,Y), 若X,Y獨立則,
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X+Y]=V[X]+V[Y]
V[X+Y]=V[X]+V[Y], 那么進行n次伯努利實驗,每次實驗獨立,X~Be(θ),V[M]=nV[X]=nθ(1-θ),當然了這里還有一個計算量很大的方法,那就是利用我們最早說的離散變數期望值公式來計算
E
[
M
]
E[M]
E[M]和
E
[
M
2
]
E[M^2]
E[M2],即:
E
[
M
]
=
∑
m
=
0
n
m
(
n
m
)
θ
m
(
1
?
θ
)
(
n
?
m
)
=
n
θ
E[M]=\sum_{m=0}^{n}m\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}=n\theta
E[M]=∑m=0n?m(nm?)θm(1?θ)(n?m)=nθ
E
[
M
2
]
=
∑
m
=
0
n
m
2
(
n
m
)
θ
m
(
1
?
θ
)
(
n
?
m
)
=
n
(
n
?
1
)
θ
2
+
n
θ
E[M^2]=\sum_{m=0}^{n}m^2\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}=n(n?1)\theta^2+n\theta
E[M2]=∑m=0n?m2(nm?)θm(1?θ)(n?m)=n(n?1)θ2+nθ
再利用
V
[
M
]
=
E
[
M
2
]
?
E
[
M
]
2
V[M]=E[M^2]-E[M]^2
V[M]=E[M2]?E[M]2得出V[M]=nθ(1-θ),
二項式分布的最后一個性質是連加性
如果
M
1
~
B
i
n
(
θ
,
n
1
)
M_1~Bin(\theta,n_1)
M1?~Bin(θ,n1?),
M
2
~
B
i
n
(
θ
,
n
2
)
M_2~Bin(\theta,n_2)
M2?~Bin(θ,n2?)
那么:
M
1
+
M
2
~
B
i
n
(
θ
,
n
1
+
n
2
)
M_1+M_2~Bin(\theta,n_1+n_2)
M1?+M2?~Bin(θ,n1?+n2?)
推導也很簡單,因為
M
1
~
B
i
n
(
θ
,
n
1
)
M_1~Bin(\theta,n_1)
M1?~Bin(θ,n1?),
M
2
~
B
i
n
(
θ
,
n
2
)
M_2~Bin(\theta,n_2)
M2?~Bin(θ,n2?),那么
E
[
M
1
]
+
E
[
M
2
]
=
E
[
M
1
+
M
2
]
=
(
n
1
+
n
2
)
θ
E[M_1]+E[M_2]=E[M_1+M_2]=(n_1+n_2)\theta
E[M1?]+E[M2?]=E[M1?+M2?]=(n1?+n2?)θ,
V
[
M
1
]
+
V
[
M
2
]
=
V
[
M
1
+
M
2
]
=
(
n
1
+
n
2
)
θ
(
1
?
θ
)
V[M_1]+V[M_2]=V[M_1+M_2]=(n_1+n_2)\theta(1-\theta)
V[M1?]+V[M2?]=V[M1?+M2?]=(n1?+n2?)θ(1?θ),所以
M
1
+
M
2
~
B
i
n
(
θ
,
n
1
+
n
2
)
M_1+M_2~Bin(\theta,n_1+n_2)
M1?+M2?~Bin(θ,n1?+n2?)
大家可能會問,伯努利分布是否有連加性質,答案是沒有,大家可以嘗試這個方法自己證明下,這個連加性的證明方法是小弟我當時給我老師提出的,老師的回答是默許了,但告訴小弟我有一套更復雜的官方證明,感興趣的同學可以查查并告訴小弟我,在此感謝了,
Ⅳ.離散均勻分布(Discrete Uniform Distribution)
不像二項式分布一樣,m的取不同的值有唯一的概率對應,當然這些概率會隨著n的增大,向nθ收斂,但是離散均勻分布則是,隨機變數取不同的值可以有相同的概率,例如擲色子,隨機變數X=1,2,3,4,5,6的概率均為
1
6
\frac{1}{6}
61?這就是一種均勻分布(uniform distribution)
那么離散均勻分布的公式:
P
(
X
=
k
∣
a
,
b
)
=
1
b
?
a
+
1
P(X=k|a,b)=\frac{1}{b-a+1}
P(X=k∣a,b)=b?a+11?
X∈{a,…,b},且b>=a. 例如骰子X∈{1,2,3,4,5,6},a=1,b=6.其實這里的兩個引數a,b其實可以看做一個引數即b-a+1, b-a+1的含義是有多少個元素在隨機變數里,例如骰子有b-a+1=6-1+1=6個面,
如果一個隨機變數X服從離散均勻分布
X
~
U
(
a
,
b
)
X~U(a,b)
X~U(a,b):
E
[
X
]
=
a
+
b
2
,
V
[
X
]
=
(
b
?
a
+
1
)
2
?
1
12
E[X]=\frac{a+b}{2}, V[X]=\frac{(b-a+1)^2-1}{12}
E[X]=2a+b?,V[X]=12(b?a+1)2?1?
這里注意的是E[X]不一定是整數,
Ⅴ.連續均勻分布(Continuous Uniform Distribution)
如果隨機變數是連續的,那么如果X服從連續均勻分布
X
~
U
(
a
,
b
)
,
a
>
b
X~U(a,b),a>b
X~U(a,b),a>b:
p
(
x
∣
a
,
b
)
=
{
0
,
x
<
a
1
b
?
a
,
a
<
=
x
<
=
b
0
,
x
>
b
p(x|a,b) = \begin{cases} \ 0, & x<a \\ \frac{1}{b-a}, & a<=x<=b \\ \ 0,& x>b \\ \end{cases}
p(x∣a,b)=?????? 0,b?a1?, 0,?x<aa<=x<=bx>b?
E
[
X
]
=
a
+
b
2
=
a
+
w
2
,
V
[
X
]
=
(
b
?
a
)
2
12
=
w
2
12
E[X]=\frac{a+b}{2}=a+\frac{w}{2}, V[X]=\frac{(b-a)^2}{12}=\frac{w^2}{12}
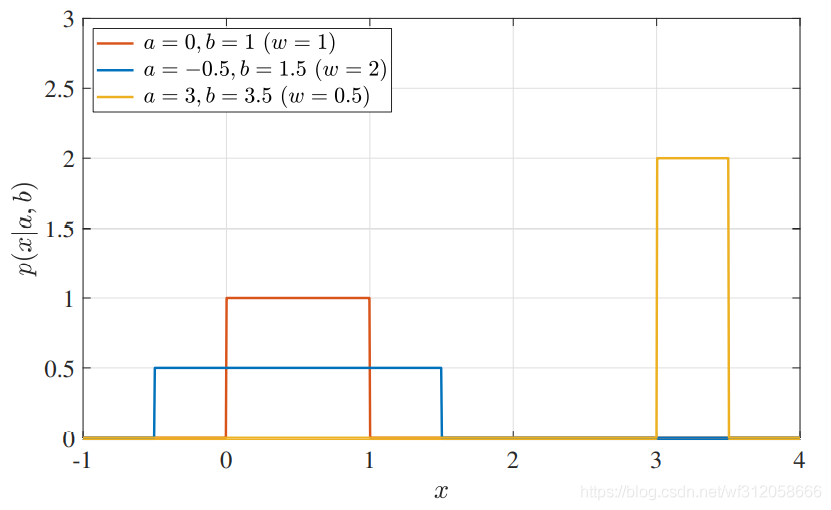
E[X]=2a+b?=a+2w?,V[X]=12(b?a)2?=12w2?
a:決定了分布從哪里開始
w=b-a:決定了分布的寬度
如下圖關于連續均勻分布:
Ⅵ.泊松分布(Poisson Distribution)
如果離散隨機變數X服從泊松分布,我們寫成X~Poi(
λ
\lambda
λ),
λ
\lambda
λ的含義是在單位時間內發生事件的次數,也稱為率(rate),X的含義是在一段時間內(一段周期)內發生事件的次數,
泊松分布的公式:
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
?
λ
)
k
!
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}
p(X=k∣λ)=k!λkexp(?λ)?
E
[
X
]
=
λ
,
V
[
X
]
=
λ
E[X]=\lambda, V[X]=\lambda
E[X]=λ,V[X]=λ
泊松分布得期望和方差推導,依舊按照離散隨機變數期望公式來算
E
[
X
]
,
E
[
X
2
]
E[X],E[X^2]
E[X],E[X2].
E
[
X
]
=
∑
k
=
1
∞
k
λ
k
e
x
p
(
?
λ
)
k
!
=
λ
e
?
λ
∑
k
=
1
∞
λ
k
?
1
(
k
?
1
)
!
E[X]=\sum_{k=1}^{∞} k \frac{\lambda^{k} exp(-\lambda)}{k!}=\lambda e^{-\lambda} \sum_{k=1}^{∞} \frac{\lambda^{k-1}}{(k-1)!}
E[X]=∑k=1∞?kk!λkexp(?λ)?=λe?λ∑k=1∞?(k?1)!λk?1?
∑
k
=
1
∞
λ
k
?
1
(
k
?
1
)
!
=
e
λ
\sum_{k=1}^{∞} \frac{\lambda^{k-1}}{(k-1)!}=e^\lambda
∑k=1∞?(k?1)!λk?1?=eλ泰勒展開式
所以
E
[
X
]
=
λ
e
?
λ
e
λ
=
λ
E[X]=\lambda e^{-\lambda} e^{\lambda}=\lambda
E[X]=λe?λeλ=λ
因為
E
[
X
2
]
=
∑
k
=
1
∞
k
2
λ
k
e
x
p
(
?
λ
)
k
!
=
λ
(
λ
+
1
)
E[X^2]=\sum_{k=1}^{∞} k^2 \frac{\lambda^{k} exp(-\lambda)}{k!}=\lambda (\lambda +1)
E[X2]=∑k=1∞?k2k!λkexp(?λ)?=λ(λ+1)
所以V[X]=
E
[
X
2
]
?
E
[
X
]
2
=
λ
E[X^2]-E[X]^2=\lambda
E[X2]?E[X]2=λ
如下圖關于泊松分布: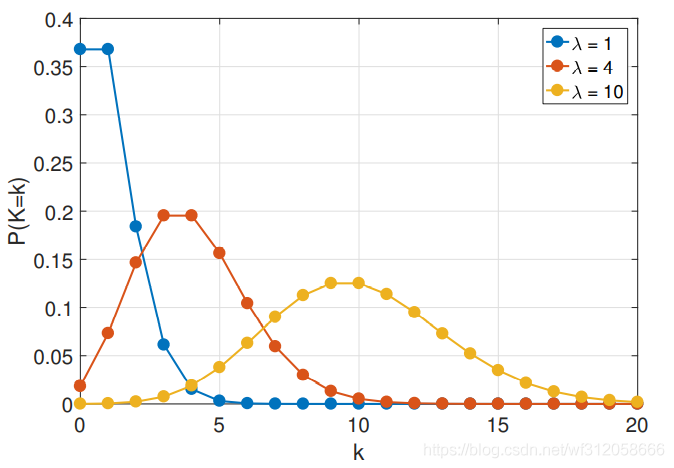
泊松分布也有連加性:
如果X1∈Poi(
λ
1
\lambda_1
λ1?), X1∈Poi(
λ
2
\lambda_2
λ2?),那么X1+X2∈Poi(
λ
1
+
λ
2
\lambda_1+\lambda_2
λ1?+λ2?)
另外,如果
X
T
X_T
XT?意味著發生多少事情在一段時間或者周期
T
T
T內,那么將這段時間縮短k倍,那么會發生
X
T
/
k
X_{T/k}
XT/k?個事情,且
X
T
/
k
X_{T/k}
XT/k?~Poi(
λ
k
\frac{\lambda}{k}
kλ?).
因為我們的
λ
\lambda
λ本質是單位時間T=1乘以發生事件的期望,如果單位時間變成T=
1
k
\frac{1}{k}
k1?那么我們
λ
\lambda
λ*
1
k
\frac{1}{k}
k1?.
根據泊松分布的影像,我們可以看出泊松分布好像和二項式分布很像,沒錯,當二項式的n足夠多,二項式將近似為泊松,當泊松的 λ \lambda λ足夠大時,從離散函式變成連續函式時,它將變化為正態分布,所以正態分布其實是所有分布的樣子,當樣本趨于極限總體時,
二項式分布推導泊松分布(
n
→
∞
n→∞
n→∞時)
lim
?
n
→
∞
p
(
m
∣
θ
)
=
(
n
m
)
θ
m
(
1
?
θ
)
(
n
?
m
)
\lim_{n\to ∞}p(m|\theta)=\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}
limn→∞?p(m∣θ)=(nm?)θm(1?θ)(n?m)
令 θ \theta θ= λ n \frac{\lambda}{n} nλ?
= lim ? n → ∞ ( n m ) ( λ n ) m ( 1 ? λ n ) n ? m =\lim_{n\to ∞}\begin{pmatrix}n\\m\\\end{pmatrix}(\frac{\lambda}{n})^m(1-\frac{\lambda}{n})^{n-m} =limn→∞?(nm?)(nλ?)m(1?nλ?)n?m
當n→∞,θ→∞ 時.
= lim ? n → ∞ n ! ( n ? m ) ! m ! ( λ n ) m ( 1 ? λ n ) n ( 1 ? λ n ) ? m =\lim_{n\to ∞}\frac{n!}{(n-m)!m!}(\frac{\lambda}{n})^m(1-\frac{\lambda}{n})^n(1-\frac{\lambda}{n})^{-m} =limn→∞?(n?m)!m!n!?(nλ?)m(1?nλ?)n(1?nλ?)?m
因為n無窮大時, ( 1 ? λ n ) ? m (1-\frac{\lambda}{n})^{-m} (1?nλ?)?m=1, n ! ( n ? m ) ! ( 1 n m ) \frac{n!}{(n-m)!} (\frac{1}{n^m}) (n?m)!n!?(nm1?)=1, ( 1 ? λ n ) n (1-\frac{\lambda}{n})^n (1?nλ?)n=exp(- λ \lambda λ)
所以
=
lim
?
n
→
∞
λ
m
m
!
e
x
p
(
?
λ
)
=\lim_{n\to ∞}\frac{\lambda^m}{m!}exp(-\lambda)
=limn→∞?m!λm?exp(?λ),泊松分布
泊松分布推導正態分布(當
λ
\lambda
λ→
∞
∞
∞):
先澄清一點,正常情況的泊松分布是推不到正態分布的,中心極限定理的泊松分布可以推導正態分布,中心極限定理是說當樣本足夠大時,樣本均值的分布逐漸變化成正態分布.中心極限定理后續章節還會細說,
泊松分布公式:
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
?
λ
)
k
!
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}
p(X=k∣λ)=k!λkexp(?λ)?
令k= λ ( 1 + δ ) \lambda(1+\delta) λ(1+δ), δ \delta δ<<1, ( 1 + δ ) (1+\delta) (1+δ)意味著單位時間,當 λ \lambda λ→ ∞ ∞ ∞, k → ∞ k→∞ k→∞,泊松分布的隨機變數逐漸變成連續的,
利用斯特林公式(Stirling’s formula)
k
!
→
2
π
k
e
?
k
k
?
k
k!→\sqrt{2\pi k} e^{-k}k^{-k}
k!→2πk
?e?kk?k, 當
k
→
∞
k→∞
k→∞
那么
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
?
λ
)
k
!
=
λ
λ
(
1
+
δ
)
e
?
λ
2
π
e
?
λ
(
1
+
δ
)
[
λ
(
1
+
δ
)
]
λ
(
1
+
δ
)
+
1
2
=
e
?
λ
δ
2
2
2
π
λ
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}=\frac{\lambda^{\lambda(1+\delta)}e^{-\lambda}}{\sqrt{2\pi}e^{-\lambda(1+\delta)}[\lambda(1+\delta)]^{\lambda(1+\delta)+\frac{1}{2}}}=\frac{e^\frac{-\lambda \delta^2}{2}}{\sqrt{2\pi \lambda}}
p(X=k∣λ)=k!λkexp(?λ)?=2π
?e?λ(1+δ)[λ(1+δ)]λ(1+δ)+21?λλ(1+δ)e?λ?=2πλ
?e2?λδ2??
再將
δ
\delta
δ=(k-
λ
\lambda
λ)/
λ
\lambda
λ,帶入,得
=
e
?
(
k
?
λ
)
2
2
λ
2
π
λ
=\frac{e^{\frac{-(k-\lambda)^2}{2\lambda}}}{\sqrt{2\pi \lambda}}
=2πλ
?e2λ?(k?λ)2??
令
λ
=
σ
2
=
μ
\lambda=\sigma^2=\mu
λ=σ2=μ, k=x
則為
p
(
x
∣
μ
,
σ
2
)
=
(
1
2
π
σ
2
)
1
2
e
x
p
(
?
(
x
?
μ
)
2
2
σ
2
)
p(x|\mu,\sigma^2)=(\frac{1}{2\pi\sigma^2})^{\frac{1}{2}}exp({-\frac{(x-\mu)^2}{2\sigma^2}})
p(x∣μ,σ2)=(2πσ21?)21?exp(?2σ2(x?μ)2?) 正態分布,
最后,這里有張分布的關系圖(轉載https://www.zhihu.com/question/21756860),大家可以清晰的看到各個分布的關系
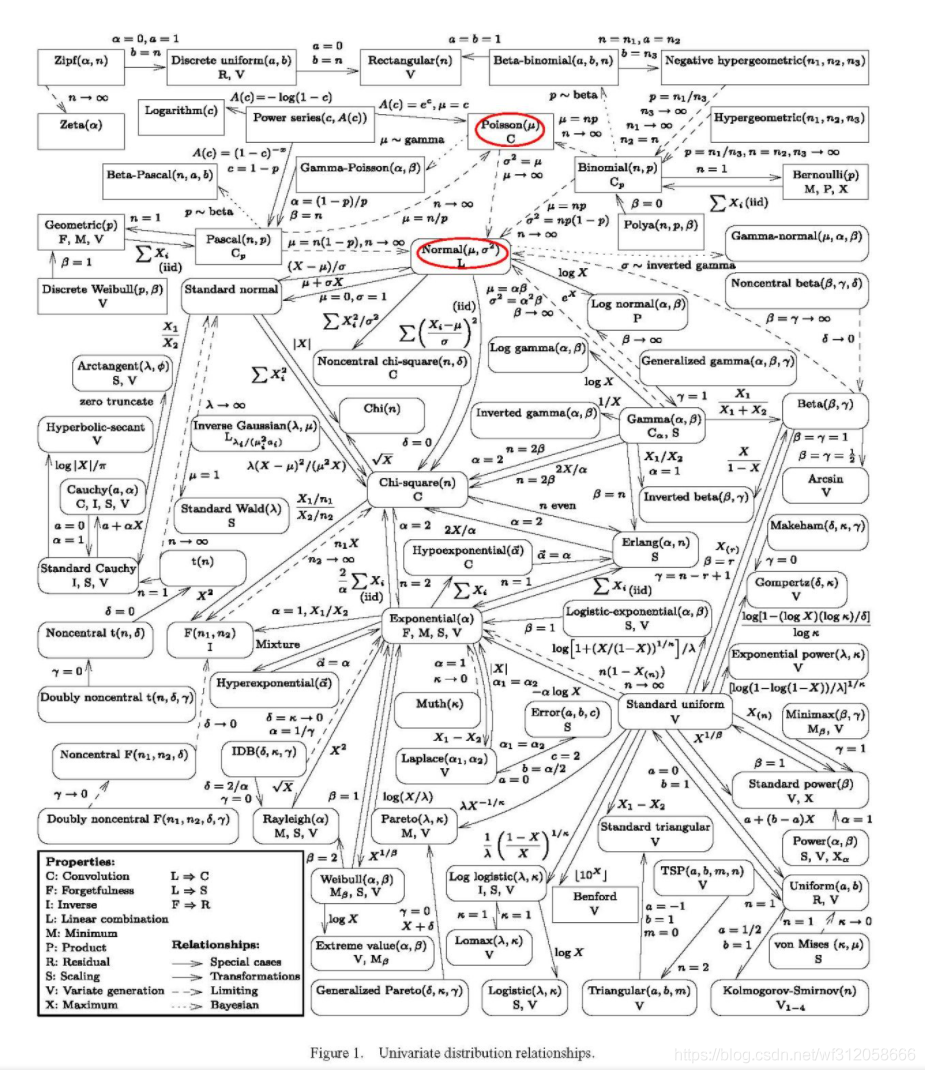
在資料分析模型這課里面暫且不涉及過多分布,畢竟小弟專業是資料科學,研究生是機器學習和計算機視覺,對數學方面雖有涉及但不夠深入,也希望大家多多點出小弟的不足或有謬誤的地方,在此感謝了,至于像伽馬分布,柯西分布,半柯西分布等均為貝葉斯統計先驗里需要用上的,這些內容在后續更新高等資料分析博客會提到,
三. 結語
小弟我畢竟不是數學專業,有公式推導錯誤的或理論有謬誤的,請大家指出,我好及時更正,
自習的同學可以參考Ross, S.M. (2014) Introduction to Probability and Statistics for Engineers and Scientists, 5th ed. Academic Press. 第4章-5章
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240510.html
標籤:其他
下一篇:Hadoop基礎概念知識(干貨)