1 Kafka是什么?
簡單來說,Kafka就是一個訊息系統/訊息中間件,雖然Kafka新增了流處理(統計分析計算)的新特性,但是我們一般還是使用Spark,Flink等作為流處理的軟體.
2 Kafka的作用是什么?
1)應用解耦:多個應用可通過訊息佇列對訊息進行處理,應用之間相互獨立,互不影響.
圖例:
2)異步處理:相比于串行和井行處理,異步處理可以減少處理的時間.
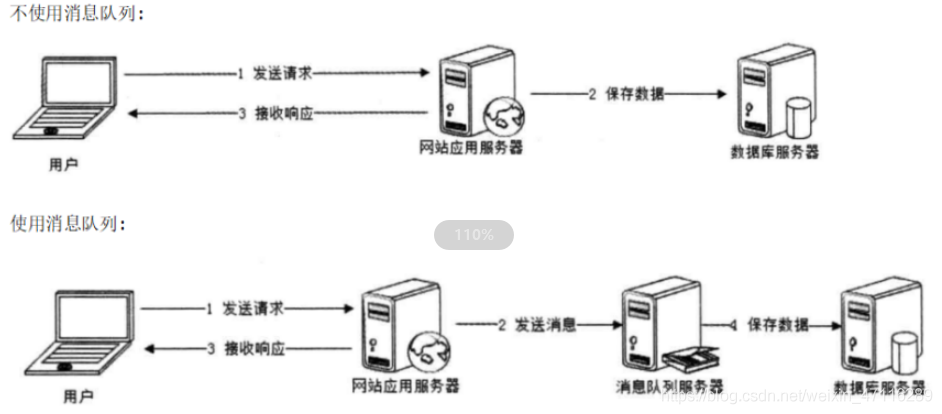
3)流量削峰:流量高峰期,可通過訊息佇列來控制流量, 避免流量過大而引起應用系統崩潰.
4)訊息通信:實作點對點訊息佇列,或者多對多的訊息佇列.
3 Kafka的生產,訊息存盤,消費流程細節
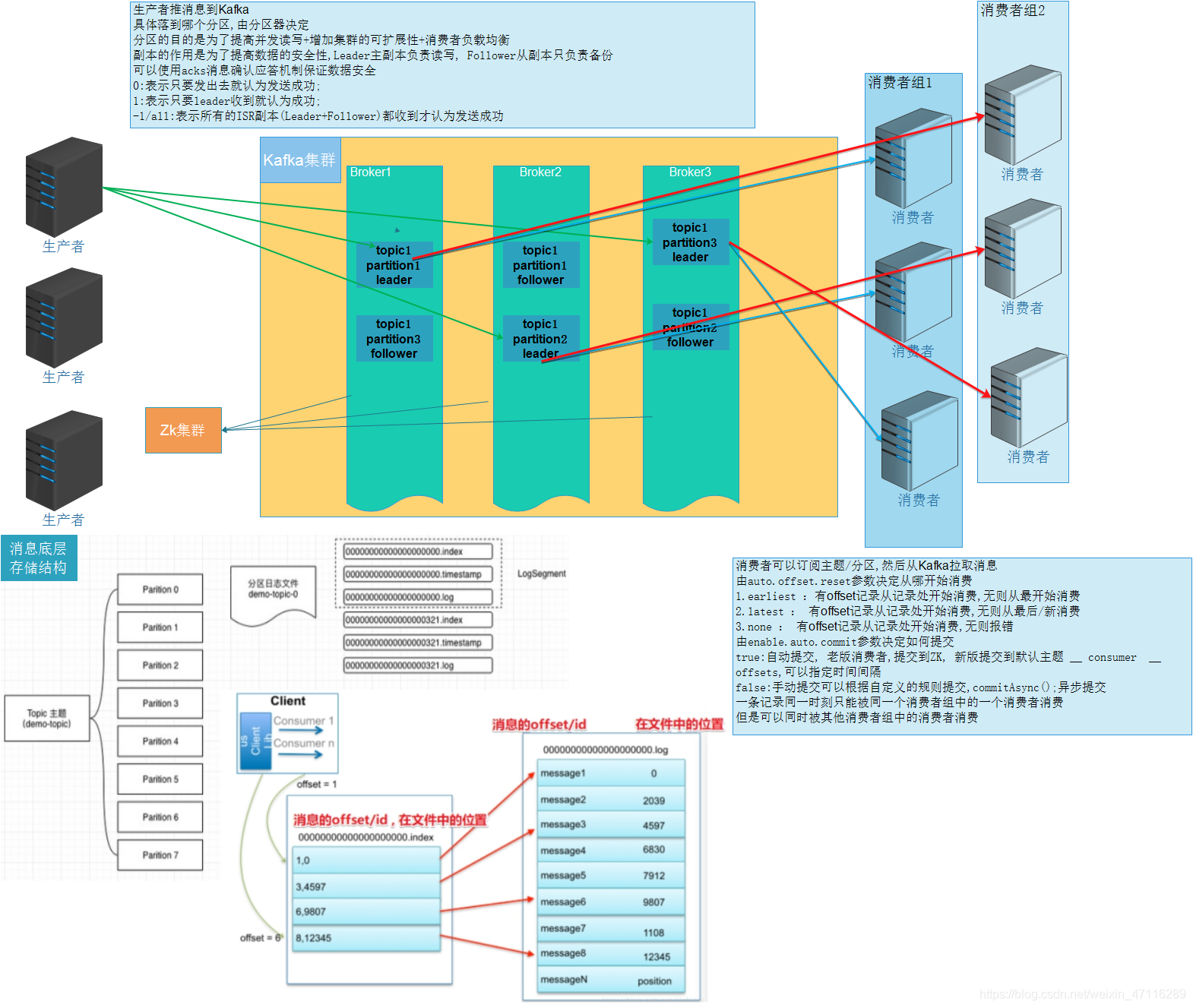
1) 生產者流程細節
1.生產者發送訊息到Kafka集群使用的是推送模式
2.生產者發送訊息到Kafka需要連接到任意一臺Kafka節點
3.每一條訊息會被封裝為一個Record記錄物件,里面可以包含主題、磁區(可選)、key(可選)、value
4.磁區規則:
-
沒有key,用的是輪詢
-
有key,沒有指定磁區用的默認的磁區器defaultPartitioner,底層使用hash
-
有key,指定磁區,那么就是指定的磁區號----優先級最高
-
可以自定義磁區器
補充:
key可以作為訊息/記錄的一個業務上的標識(但不是唯一的,也就是不同的value的key可以重復的)
value才是訊息的真正的內容
5.磁區的作用:
- 提高讀寫效率-------一個主題不同的磁區落在不同的節點上,可以并行的生產/消費主題中的訊息,否則將會生產/消費的請求到一個節點上.
- 便于集群擴容(機器擴容時增加機器同時增加磁區數)--------如果沒有磁區,我們一臺機器磁盤空間滿了之后,雖然可以再添加機器來進行擴容,但是原來的機器磁盤空間依然是滿的,有了磁區之后,我們可以將原來的機器中的主題分為2個磁區,分別負載到2臺不同的機器上,這樣原來的機器也就騰出了一半的磁盤空間.
- 方便消費者負載均衡(消費者數量==磁區數)--------如果沒有磁區,一個消費者將會消費一個主題中所有的訊息,有了磁區之后,可以讓消費者數量和磁區數量一一對應實作負載均衡,即提升了效率,也不會讓某個消費者沒活干.
6.每一條訊息/記錄發送到Kafka的時候會先到緩沖區, 然后以batch的形式發送到Kafka,落入磁盤是以順序寫的方式追加到磁盤檔案中的!-------Kafka寫入訊息只能追加!
7.每一條訊息寫到各個磁區之后會有一個訊息的唯一標識:offset
- offset是區內有序, 全域無序的(區內有序,區間無序)----kafka訊息的區域有序性
2) Broker存盤流程細節
1.訊息到底Kafka之后會根據磁區規則進入到指定的磁區(磁區是分散各個節點)
2.磁區在物理層面體現就是檔案夾
3.磁區中又會分為多個segment檔案段,每個檔案段由.log資料檔案和.index索引檔案組成
.index檔案中存盤了每個偏移量的訊息對應.log檔案中的第幾行,當我們對訊息進行查詢,會首先用二分查找法查詢對應偏移量的訊息在.log檔案中的位置,然后再根據查詢到的位置直接去.log中查詢訊息.
圖解:
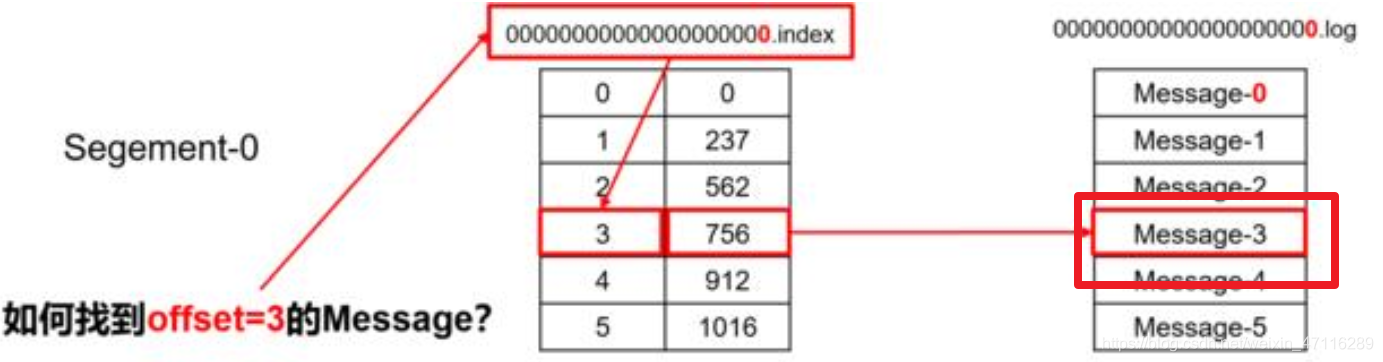
二分查找法不管資料量多大,查詢的次數都不會增加太多,效率非常高
4.查詢的時候可以根據offset去.index中的索引找到.log中對于的訊息位置
5.資料不是一直在kafka中存盤,會有洗掉策略
-
基于時間:log.retention.hours=168
-
基于大小:log.retention.bytes=1073741824
基于時間的洗掉:一個主題的每個分段中都有一個 timestamp 記錄這個分段最后寫入的訊息的時間,當這個時間已經超過7天,就會將這個分段直接洗掉.
基于大小的洗掉:當一個主題大小超過指定閾值后,就會將寫入時間最早的分段洗掉.
6.資料越來越多其實也并不會對kafka的讀寫效率產生太大的影響,因為
- 寫是各磁區順序寫/追加寫
- 讀是各磁區內根據offset對.index檔案進行二分查找Olog(N)
3) 消費者流程細節
1.消費者從Kafka中消費訊息使用的是拉取模式
2.消費者連接上Kafka集群任意一臺節點之后,需要指定要訂閱的主題或主題+磁區
3.消費從哪個偏移量開始消費,由auto.offset.reset決定
- earliest:如果有offset提交記錄,就從記錄位置開始消費,沒有則從最早的位置開始消費
- latest:如果有offset提交記錄,就從記錄位置開始消費,沒有則從最后/新的位置開始消費
- none:如果有offset提交記錄,就從記錄位置開始消費,沒有則報錯
4.消費者消費資料之后需要提交offset偏移量,可以有如下方式
- 自動提交:按照固定的時間間隔進行提交(提交到默認主題__consumer_offsets)
- 手動提交:按照自定義規則進行提交
- 注意:提交的資訊包括:哪個消費者組消費哪個主題的哪個磁區的哪個偏移量了
5.消費者組內可以有多個消費者(如果沒有設定消費者組會有默認的消費者組名稱,但建議手動設定,方便維護),某一條訊息只可以被同一個消費者組內的一個消費者消費,但可以被其他組的消費消費
6.消費者組中的消費者數量建議等于磁區數,這樣效率可以最大化.
Kafka原理圖解:
4 關于Kafka中一些問題
1)同步推送訊息和異步推送訊息
無論是kafka內部是同步還是異步推送訊息,使用kafka,都會將原來的流程從同步變為異步模式,只需要將訊息傳入kafka即可,不需要再等待資料庫或者下個組件的回應.
當使用異步模式推送訊息時,會先將訊息寫入緩沖區內,當緩沖區的大小超過一定閾值后,就不允許繼續寫入資料了,當緩沖區內的資料大小達到一個Batch或者寫入后時間超過25ms后,就會將資料寫入到磁盤中去.
2)為什么zookeeper不適合存盤offset資料
因為zookeeper本身就是一個小檔案存盤系統,不適合進行大量讀寫操作,zookeeper本身所有節點都可以進行讀,而只有主節點可以寫,如果有同時間內有大量寫操作的話,zookeeper需要將大量資料時時同步給從節點,造成zookeeper同步壓力過大,而Kafka只有主副本可以讀寫,從副本只負責同步,就不存在這個問題了.
3)消費者API中的問題
1 poll()方法只是拉取訊息,并不是消費訊息.
2 ConsumerRecords<String, String> records = consumer.poll(1000)方法一次性可以拉取多潭訓者一條訊息,因為我們撰寫的代碼是單執行緒,所以只有初次拉取訊息的時候會一次性拉取多條訊息,后續都是我們每生產一條訊息,poll方法就拉取一條,但是實際生產環境中,都是多執行緒一次性生產一個主題的多個磁區的訊息,所以poll方法都是一次性拉取多條訊息.
3 無論是自動提交還是手動提交,都是先消費后提交,自動提交也是去確認消費完成之后,才會提交讀到的偏移量,這樣雖然可能會造成多讀的情況發生,但是最起碼可以保證資料不丟失,我們后續可以通過布隆過濾器或者redis等方式去重即可.
4)攔截器中的問題
onSend()方法 生產者每推送一次訊息執行一次
onAcknowledgement()方法,訊息每發送成功或者失敗執行一次
close() 方法.當生產者停止生產訊息(producer.close())時,執行一次
5)kafka和zookeeper的關系
kafka依賴于zookeeper進行集群管理,故障轉移,kafka中有哪些主題,主題又分為哪些磁區,這些磁區都落在哪些節點上,都存在于zookeeper當中,但是新版本以后,offset偏移量不再存在zookeeper當中,而是存在Kafka的默認主題__consumer_offsets 當中,其中記錄了哪些消費者組消費到哪個磁區的哪個皮偏移量了
6)消費者組的作用
消費者組主要是方便對消費者進行分組管理的,我們往往只需要指定消費者組,至于里面的消費者數量和消費訊息時每個消費者消費哪個磁區,都由kafka自己分配決定.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240513.html
標籤:其他