目錄
1 直播流程概述
2.資料采集
2.1 視頻資料的采集
2.1.1 SurfaceHolder
2.1.2 SurfaceView類
2.1.3 Camera
2.2 獲取相機資料
2.3 音頻采集
3 編碼
3.1 常見編碼格式
3.2 h264原理概述
3.2.1 劃分宏塊
3.2.2 劃分子塊
3.2.3 幀分組
3.2.4 運動估計與補償
3.2.5 幀內預測
3.2.6 對殘差資料做DCT
3.2.7 CABAC
直播涉及到音視頻技術,想要深入研究,需要對音頻和視頻有一定的了解,這里我們會討論直播中的技術實作,涉及到必要的底層實作或者必要的音視頻知識會有一些相關鏈接或者概念上的闡述,
1 直播流程概述
先來看下開啟一場直播,中間的流程是怎樣的,如圖:
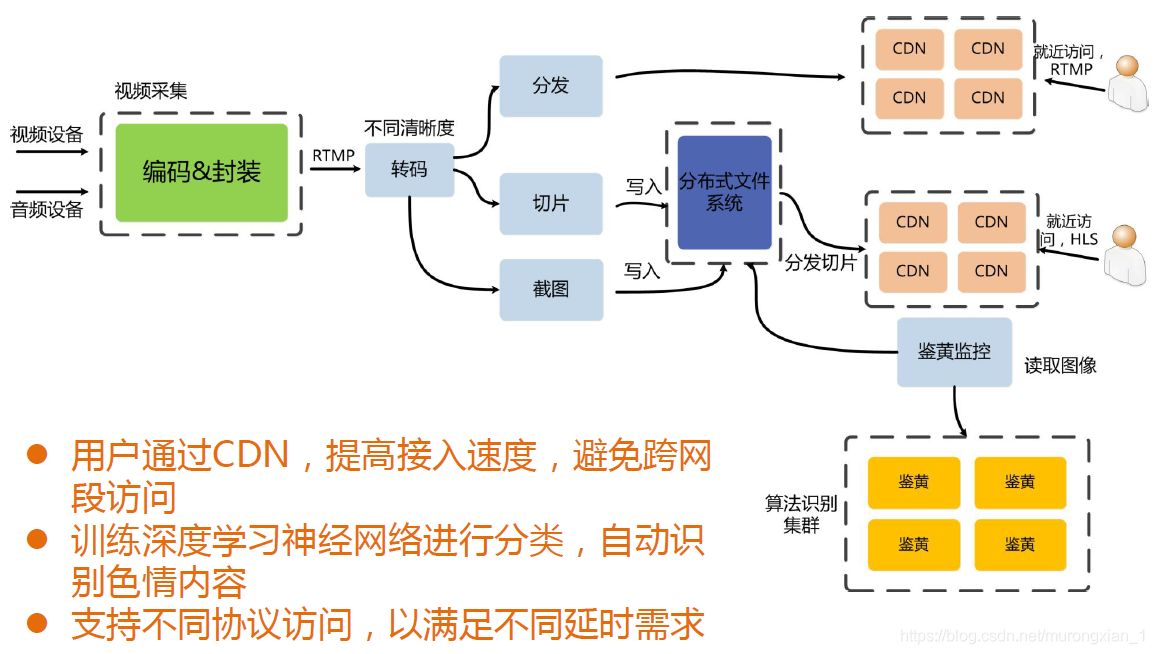
從上圖可以看到,一場直播的流程為:
(1)移動端視頻設備、音頻設備采集到音視頻資料
(2)將采集到的音頻資料和視頻資料進行編碼和封裝
(3)將封裝后的資料通過網路傳輸到后端
再經過轉碼、分發、寫入分布式系統等,以及經過CDN(content delivery net,內容分發網)傳輸給觀眾端,轉碼,分發,切片等程序是將資料傳給后端,后端進行的一系列操作,而CDN是將處理的音視頻資料內容進行分發的網路,這里不討論,我們只討論屬于移動端的音視頻資料處理及傳輸的1),2),3)程序,
2.資料采集
直播流程中,主播端的資料處理包括:資料采集、編碼和封裝,資料的采集和處理包括視頻和音頻的采集處理,
2.1 視頻資料的采集
相機的采集及預覽可以通過兩個方式實作:
(1)SurfaceView+Camera
(2)TextureView+Camera
這里我們詳細討論第一種實作方案,
在Android層,實作從打開相機到得到影像資料以及預覽的程序大致可以分為兩部分:從硬體得到Camera預覽資料、SurfaceView(也可以是TextureView)顯示畫面,如下圖所示,
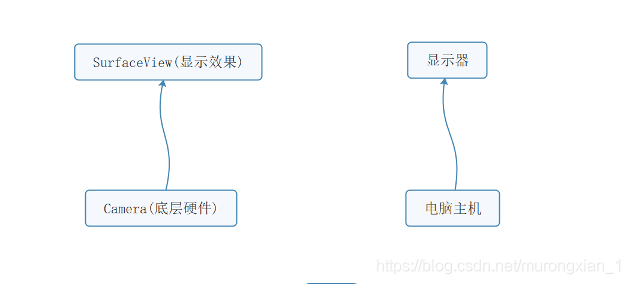
SurfaceView是Camera資料的顯示界面,想要將SurfaceView和Camera聯系起來,需要用到Surface和SurfaceHolder,它們之間的關系是:
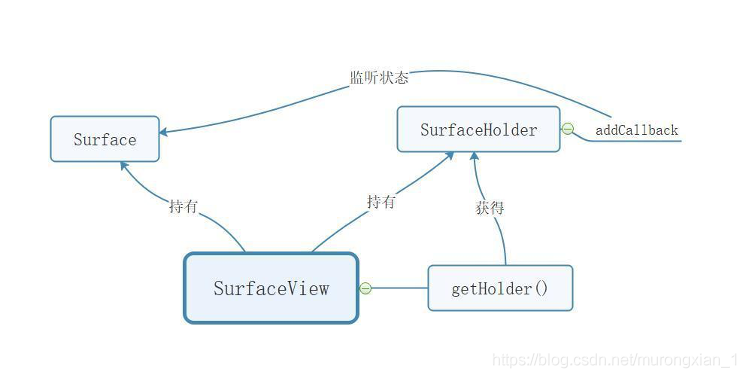
這里,Surface是用來處理螢屏顯示內容合成器所管理的原始快取區的工具,它通常由影像緩沖區的消費者來創建(如:SurfaceTexture,MediaRecorder,編解碼時的MediaCodec),然后被移交給生產者(如:MediaPlayer)或者是顯示到其上(如:CameraDevice),正如Fig.3所示,Google提供了一個SurfaceHolder類來對Surface的屬性進行控制,
接下來,分別對這三個部分進行介紹,
2.1.1 SurfaceHolder
一個抽象介面,給持有surface的物件使用,它可以控制surface的大小和格式,編輯surface中的像素格式,以及監聽surface的變化,這個介面通常通過SurfaceView類獲得,它有3個回呼方法:
//surface第一次創建時回呼
surfaceCreated(SurfaceHolder holder)
//surface變化的時候回呼(格式/大小),如設定橫豎屏
surfaceChanged(SurfaceHolder holder, int format, int width, int height)
//surface銷毀的時候回呼
surfaceDestroyed(SurfaceHolder holder)
2.1.2 SurfaceView類
SurfaceView繼承自View,其中有兩個成員變數,一個是Surface物件,一個是SuraceHolder物件,surfaceView用這兩個物件實作什么目的呢?
· SurfaceView把Surface顯示在螢屏上,Surface是處理原始緩沖區的工具,可以理解為一塊“還未看見”的畫布,即在SurfaceView顯示前一幀的畫面時,Surface在準備即將要展示的下一幀的畫面,等到下一幀準備好,就可以進行重繪,
· SurfaceView通過SuraceHolder告訴我們Surface的狀態(創建、變化、銷毀)
· 通過getHolder()方法獲得當前SurfaceView的SuraceHolder物件,然后就可以對SuraceHolder物件添加回呼來監聽Surface的狀態
即SuffaceView.getHolder().addCallBack(SurfaceHolder.Callback);
2.1.3 Camera
從Camera得到資料這部分來看,Camera初始化需要做的:
//1. 打開攝像頭,這里,引數id是指開啟前置還是后置攝像頭,1代表前置,0代表后置
camera=android.hardware.Camera.open(int id);
//2. 設定各個引數,例如:
Camera.Parameters parameters = mCamera.getParameters(); //獲取攝像頭引數
// 可以根據情況設定引數
// 鏡頭縮放
parameters.setZoom();
// 設定預覽照片的大小
parameters.setPreviewSize(200, 200);
// 設定預覽照片時每秒顯示多少幀的最小值和最大值
parameters.setPreviewFpsRange(4, 10);
// 設定圖片格式
parameters.setPictureFormat(ImageFormat.JPEG);
// 設定JPG照片的質量 圖片的質量[0-100],100最高
parameters.set("jpeg-quality", 85);
// 設定照片的大小
parameters.setPictureSize(200, 200);
camera.setDisplayOrientation(90);// 預覽方向,一般是通過相機設定方向來實作,
最后,將引數傳給Camera
mCamera.setParameters(parameters);此外還需要注意一個問題,即相機影像資料來自于相機硬體的影像傳感器,這個傳感器有一個默認的取景方向,前置攝像頭需要設定展示方向為270度(camera.setDisplayOrientation(270)),后置攝像頭需要設定展示方向90度(camera.setDisplayOrientation(90)),
以上就是camera的初始化,想要將camera采集到的資料展示出來,還需要一個必不可少的將Surface和Camera聯系起來的環節:
mCamera.setPreviewDisplay(holder);然后,將camera開啟預覽:
mCamera.startPreview();此程序在創建Surface成功后即可添加,一般可以添加在SurfaceHolder.Callback介面的surfaceCreated方法或者surfaceChanged介面中,
最后,記得將Camera釋放:
mCamera.release();至于相機開啟后,相機初始化,native層變化的程序,可以參考:
blog:
https://blog.csdn.net/qq_38907791/article/details/87987591
2.2 獲取相機資料
上述程序是直接將相機得到的資料展示在螢屏上,然而,在開發程序中,有些需求是獲取相機得到的像素資料,以實作其他需求,那么如何在android中獲取相關影像資料呢?
Google提供了Camera的相關介面:Camera.PreviewCallback
在介面的方法中即可獲得byte[]陣列,這個陣列是將像素(Android 中Google支持的 Camera Preview Callback的YUV常用格式有兩種:一個是NV21,一個是YV12,Android一般默認使用YCbCr_420_SP的格式(NV21))按照一定規則排列得到的一維陣列,如果想要得到某個格式下的像素byte陣列,可以通過相機引數設定來實作:
Camera.Parameters parameters = camera.getParameters();
parameters.setPreviewFormat(ImageFormat.NV21);
camera.setParameters(parameters);之后,通過Camera.PreviewCallback介面的onPreviewFrame方法中獲取到像素陣列并展示,具體代碼如下:
mCamera.setPreviewCallback(new Camera.PreviewCallback() {
@Override
public void onPreviewFrame(byte[] data, Camera camera) {
// 處理data,這里面的data資料就是NV21格式的資料,將資料顯示在ImageView控制元件上面
mPreviewSize = camera.getParameters().getPreviewSize();// 獲取尺寸,格式轉換的時候要用到
// 取發YUVIMAGE
YuvImage yuvimage = new YuvImage(
data,
ImageFormat.NV21,
mPreviewSize.width,
mPreviewSize.height,
null);
mBaos = new ByteArrayOutputStream();
// yuvimage轉換成jpg格式
yuvimage.compressToJpeg(new Rect(0, 0, mPreviewSize.width, mPreviewSize.height), 100, mBaos);// 80--JPG圖片的質量[0-100],100最高
mImageBytes = mBaos.toByteArray();
// 將mImageBytes轉換成bitmap
BitmapFactory.Options options = new BitmapFactory.Options();
options.inPreferredConfig = Bitmap.Config.RGB_565;
mBitmap = BitmapFactory.decodeByteArray(mImageBytes, 0, mImageBytes.length, options);
mImageView.setImageBitmap(rotateBitmap(mBitmap, getDegree()));以上,就是通過camera實作預覽以及獲取資料后轉換為Bitmap的全程序,
2.3 音頻采集
Android一般有兩種方式進行音頻采集:MediaRecorder和AudioRecord,二者的區別在于,MediaRecorder是經過編碼壓縮的,而AudioRecord得到的是PCM(脈沖編碼調制)資料,也就是原音頻檔案,想要對音頻檔案進行處理,比如變聲、變速等,就需要使用AudioRecord進行音頻采集,再對得到的音頻資料進行變聲變速等處理,
關于音頻的介紹及應用可參考文章:https://www.jianshu.com/p/125b94af7c08
3 編碼
通過以上程序,我們就得到音頻資料,影像紋理,接下來,就需要將得到的音頻和視頻進行編碼,那么為什么要進行編碼呢?
眾所周知,視頻是由一張張的圖片快速連續播放才形成的影片效果,一般來說,每秒鐘最少15張影像,即幀率為15fps,人眼不會感覺到卡頓,每張彩色影像有RGB三通道,每個通道的數值范圍是0-255,用8個二進制來表示,也就是說,每個像素點都包含3*8個二進制數值,如果一張影像的解析度是1280*720,它的像素點個數為1280*720個,那么在沒有經過編碼壓縮的情況下,傳輸或者保存一張影像需要的空間是1280*720*3*8bit.而每秒鐘按照最少的15張來計算,在直播中,每秒鐘就需要傳送1280*720*3*8*15/8=41 472 000byte=41472kB.一秒鐘最少傳輸41MB的資料量,現在的網路帶寬明顯是不能滿足這個需求的,編碼壓縮就是利用影像的時間和空間的相關性,將影像大小壓縮到遠小于原影像的目的,直播中用到的視頻編碼有H264編碼格式,音頻編碼格式為aac,
除了編碼之外,還需要對音視頻進行封裝,常見的有flv,ts,mpeg4,mkv等,我們這里討論的封裝格式是flv,
3.1 常見編碼格式
編碼實質上就是將音視頻資料進行壓縮,以減少音視頻資料在網路上傳輸的壓力,
相應地,在播放端也要進行解碼,以恢復出音視頻資料,
編碼分為軟編碼和硬編碼,二者最主要的區別在于是否使用cpu進行編碼,使用cpu進行編碼的編碼方式是軟編碼,比如FFMPEG,使用GPU,FPGA等硬體進行編碼的稱為硬編碼,軟編碼是可以適配多個平臺,但是記憶體占用率相對較高,硬編碼記憶體占用率相對較低,但是不像軟編碼可以適配多個平臺,有局限性,
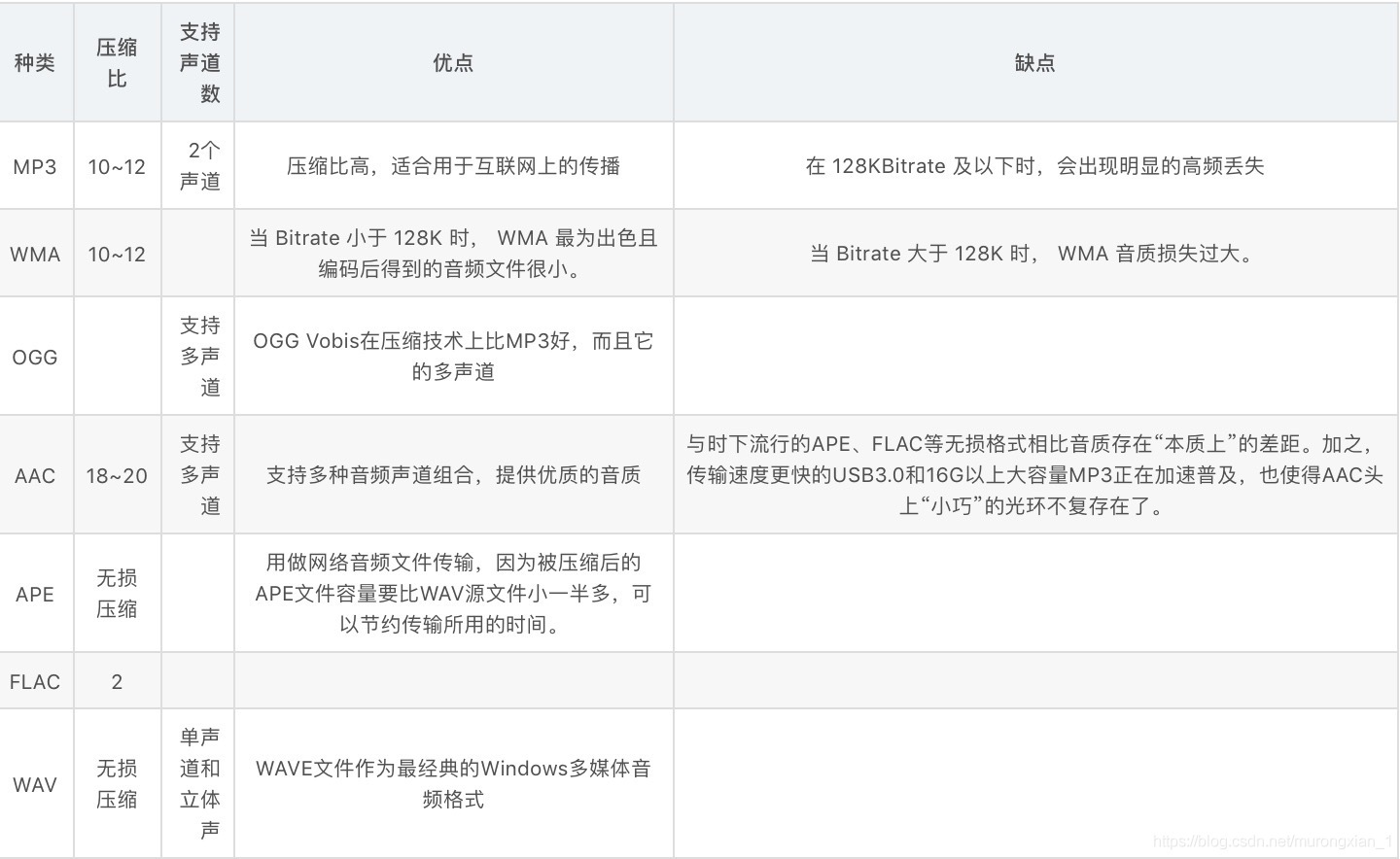
無論是軟編碼還是硬編碼,都需要對音頻和視頻編碼,現有多種視頻編碼格式和音頻編碼格式,下圖為常見音頻編碼格式比較:
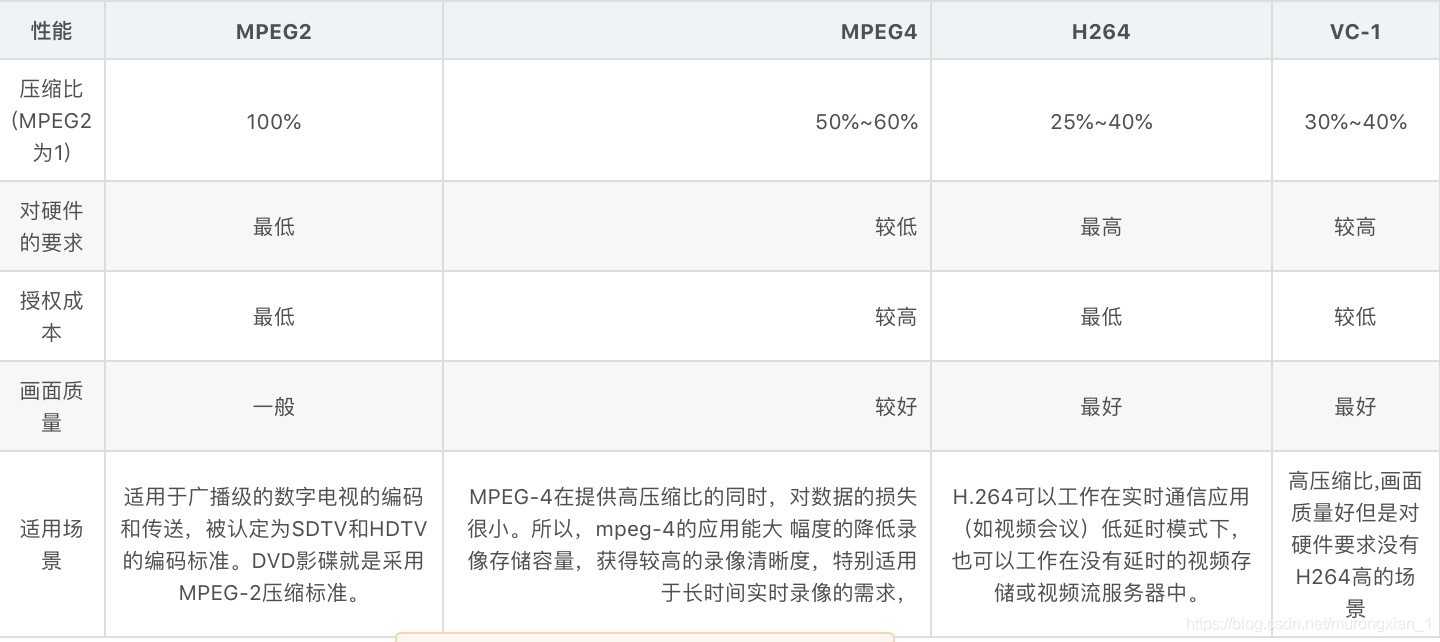
下圖為常見視頻編碼格式比較:
這里我們重點討論h264視頻編碼格式,
3.2 h264原理概述
H264編碼壓縮技術主要采用了以下幾種方法對視頻資料進行壓縮,包括:
-
幀內預測壓縮,解決的是空域資料冗余問題,
-
幀間預測壓縮(運動估計與補償),解決的是時域資料冗余問題,
-
整數離散余弦變換(DCT),將空間上的相關性變為頻域上無關的資料然后進行量化,
-
CABAC壓縮,
經過壓縮后的幀分為:I幀,P幀和B幀:
-
I幀:關鍵幀,采用幀內壓縮技術,
-
P幀:向前參考幀,在壓縮時,只參考前面已經處理的幀,采用幀音壓縮技術,
-
B幀:雙向參考幀,在壓縮時,它即參考前而的幀,又參考它后面的幀,采用幀間壓縮技術,
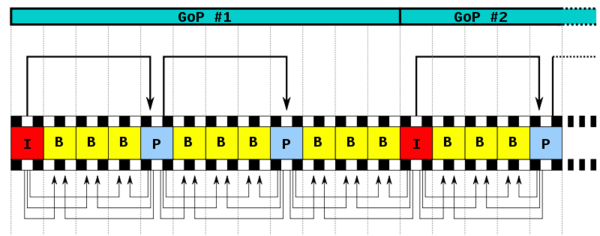
除了I/P/B幀外,還有影像序列GOP,
GOP:兩個I幀之間是一個影像序列,在一個影像序列中只有一個I幀,如下圖所示:
下面我們就來詳細描述一下H264壓縮技術,
H264的基本原理其實非常簡單,下我們就簡單的描述一下H264壓縮資料的程序,通過攝像頭采集到的視頻幀(按每秒 30 幀算),被送到 H264 編碼器的緩沖區中,編碼器先要為每一幀圖片劃分宏塊,
以下面這張圖為例:
3.2.1 劃分宏塊
H264默認是使用 16X16 大小的區域作為一個宏塊,也可以劃分成 8X8 大小,

劃分好宏塊后,計算宏塊的象素值,

以此類推,計算一幅影像中每個宏塊的像素值,所有宏塊都處理完后如下面的樣子,

3.2.2 劃分子塊
H264對比較平坦的影像使用 16X16 大小的宏塊,但為了更高的壓縮率,還可以在 16X16 的宏塊上更劃分出更小的子塊,子塊的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4非常的靈活,

上幅圖中,紅框內的 16X16 宏塊中大部分是藍色背景,而三只鷹的部分影像被劃在了該宏塊內,為了更好的處理三只鷹的部分影像,H264就在 16X16 的宏塊內又劃分出了多個子塊,
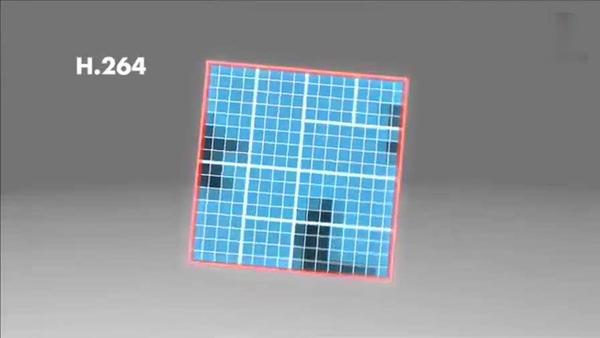
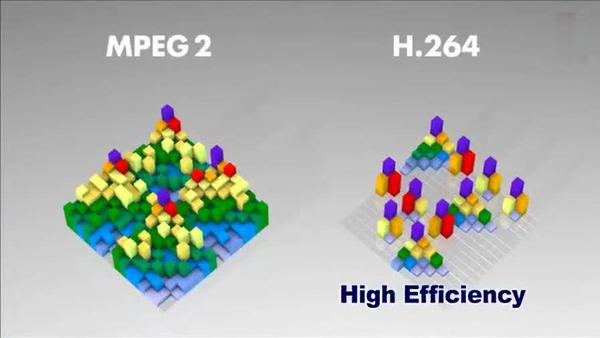
這樣再經過幀內壓縮,可以得到更高效的資料,下圖是分別使用mpeg-2和H264對上面宏塊進行壓縮后的結果,其中左半部分為MPEG-2子塊劃分后壓縮的結果,右半部分為H264的子塊劃壓縮后的結果,可以看出H264的劃分方法更具優勢,
宏塊劃分好后,就可以對H264編碼器快取中的所有圖片進行分組了,
3.2.3 幀分組
對于視頻資料主要有兩類資料冗余,一類是時間上的資料冗余,另一類是空間上的資料冗余,其中時間上的資料冗余是最大的,下面我們就先來說說視頻資料時間上的冗余問題,
為什么說時間上的冗余是最大的呢?假設攝像頭每秒抓取30幀,這30幀的資料大部分情況下都是相關聯的,也有可能不止30幀的的資料,可能幾十幀,上百幀的資料都是關聯特別密切的,
對于這些關聯特別密切的幀,其實我們只需要保存一幀的資料,其它幀都可以通過這一幀再按某種規則預測出來,所以說視頻資料在時間上的冗余是最多的,
為了達到相關幀通過預測的方法來壓縮資料,就需要將視頻幀進行分組,那么如何判定某些幀關系密切,可以劃為一組呢?我們來看一下例子,下面是捕獲的一組運動的臺球的視頻幀,臺球從右上角滾到了左下角,

H264編碼器會按順序,每次取出兩幅相鄰的幀進行宏塊比較,計算兩幀的相似度,如下圖:

通過宏塊掃描與宏塊搜索可以發現這兩個幀的關聯度是非常高的,進而發現這一組幀的關聯度都是非常高的,因此,上面這幾幀就可以劃分為一組,其演算法是:在相鄰幾幅影像畫面中,一般有差別的像素只有10%以內的點,亮度差值變化不超過2%,而色度差值的變化只有1%以內,我們認為這樣的圖可以分到一組,
在這樣一組幀中,經過編碼后,我們只保留第一帖的完整資料,其它幀都通過參考上一幀計算出來,我們稱第一幀為IDR/I幀,其它幀我們稱為P/B幀,這樣編碼后的資料幀組我們稱為GOP,
3.2.4 運動估計與補償
在H264編碼器中將幀分組后,就要計算幀組內物體的運動矢量了,還以上面運動的臺球視頻幀為例,我們來看一下它是如何計算運動矢量的,
H264編碼器首先按順序從緩沖區頭部取出兩幀視頻資料,然后進行宏塊掃描,當發現其中一幅圖片中有物體時,就在另一幅圖的鄰近位置(搜索視窗中)進行搜索,如果此時在另一幅圖中找到該物體,那么就可以計算出物體的運動矢量了,下面這幅圖就是搜索后的臺球移動的位置,

通過上圖中臺球位置相差,就可以計算出臺圖運行的方向和距離,H264依次把每一幀中球移動的距離和方向都記錄下來就成了下面的樣子,

運動矢量計算出來后,將相同部分(也就是綠色部分)減去,就得到了補償資料,我們最終只需要將補償資料進行壓縮保存,以后在解碼時就可以恢復原圖了,壓縮補償后的資料只需要記錄很少的一點資料,如下所示:

我們把運動矢量與補償稱為幀間壓縮技術,它解決的是視頻幀在時間上的資料冗余,除了幀間壓縮,幀內也要進行資料壓縮,幀內資料壓縮解決的是空間上的資料冗余,下面我們就來介紹一下幀內壓縮技術,
3.2.5 幀內預測
人眼對圖象都有一個識別度,對低頻的亮度很敏感,對高頻的亮度不太敏感,所以基于一些研究,可以將一幅影像中人眼不敏感的資料去除掉,這樣就提出了幀內預測技術,
H264的幀內壓縮與JPEG很相似,一幅影像被劃分好宏塊后,對每個宏塊可以進行 9 種模式的預測,找出與原圖最接近的一種預測模式,

下面這幅圖是對整幅圖中的每個宏塊進行預測的程序,

幀內預測后的影像與原始影像的對比如下:

然后,將原始影像與幀內預測后的影像相減得殘差值,

再將我們之前得到的預測模式資訊一起保存起來,這樣我們就可以在解碼時恢復原圖了,效果如下:

經過幀內與幀間的壓縮后,雖然資料有大幅減少,但還有優化的空間,
3.2.6 對殘差資料做DCT
可以將殘差資料做整數離散余弦變換,去掉資料的相關性,進一步壓縮資料,如下圖所示,左側為原資料的宏塊,右側為計算出的殘差資料的宏塊,
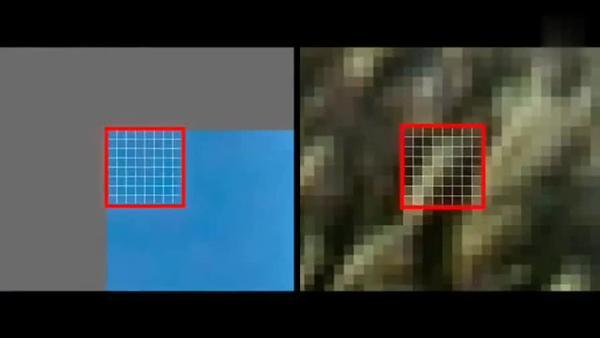
將殘差資料宏塊數字化后如下圖所示:
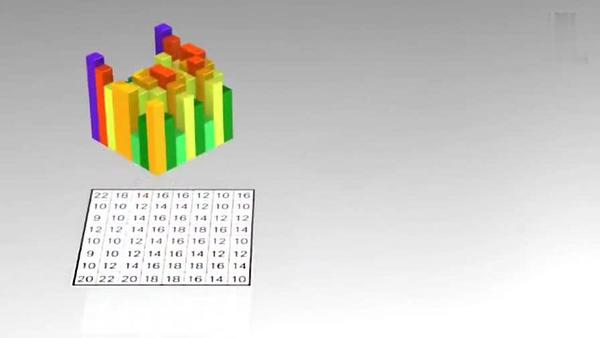

將殘差資料宏塊進行 DCT 轉換,

去掉相關聯的資料后,我們可以看出資料被進一步壓縮了,

做完 DCT 后,還不夠,還要進行 CABAC 進行無損壓縮,
3.2.7 CABAC
上面的幀內壓縮是屬于有損壓縮技術,也就是說影像被壓縮后,無法完全復原,而CABAC屬于無損壓縮技術,
無損壓縮技術大家最熟悉的可能就是哈夫曼編碼了,給高頻的詞一個短碼,給低頻詞一個長碼從而達到資料壓縮的目的,MPEG-2中使用的VLC就是這種演算法,我們以 A-Z 作為例子,A屬于高頻資料,Z屬于低頻資料,看看它是如何做的,

CABAC也是給高頻資料短碼,給低頻資料長碼,同時還會根據背景關系相關性進行壓縮,這種方式又比VLC高效很多,其效果如下:

現在將 A-Z 換成視頻幀,它就成了下面的樣子,

從上面這張圖中明顯可以看出采用 CACBA 的無損壓縮方案要比 VLC 高效的多,
以上是h264編碼原理,接下來查看具體的編碼實作方式:https://blog.csdn.net/murongxian_1/article/details/111224953
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240911.html
標籤:其他
下一篇:什么是面向物件