為什么使用ConcurrentHashMap
- 在并發編程中使用HashMap可能導致程式死回圈,而使用執行緒安全的HashTable效率又非常低下
執行緒不安全的HashMap
-
在多執行緒環境下,使用HashMap進行put操作會引起死回圈,導致CPU利用率接近100%
-
死回圈案例:
final HashMap<String, String> map = new HashMap<String, String>(2); Thread t = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 10000; i++) { new Thread(new Runnable() { @Override public void run() { map.put(UUID.randomUUID().toString(), ""); } }, "ftf" + i).start(); } } }, "ftf"); t.start(); t.join();原因:多執行緒會導致HashMap的Entry鏈表形成環形資料結構,一旦形成環形資料結構,Entry的next節點永遠不為空,就會產生死回圈獲取Entry
效率低下的HashTable
- HashTable容器使用synchronized來保證執行緒安全,但在激烈的情況下HashTable的效率非常低下,因為當一個執行緒訪問HashTable的同步方法時,其他執行緒會進入阻塞或輪詢狀態,所以競爭越激烈效率越低
ConcurrentHashMap提升并發訪問率的方法
- 使用的是鎖分段技術
- 訪問HashTable的執行緒都必須競爭同一把鎖,加入容器里面有多把鎖,每一把鎖用于鎖容器其中一部分資料,當多執行緒訪問容器里不同資料段的資料時,執行緒間就不會存在鎖競爭,可以有效提高并發訪問效率,這就是所分段技術,將資料分成一段一段地存盤,然后給每一段資料分配一把鎖,當一個執行緒占用鎖訪問其中一段資料的時候,其他段的資料也能被其他執行緒訪問
ConcurrentHashMap的結構
- ConcurrentHashMap是由Segment陣列結構和HashEntry陣列結構組成,Segment是一種可重入鎖(ReentrantLock);HashEntry則用于存盤鍵值對資料,一個ConcurrentHashMap里包含一個Segment陣列,Segment結構是一種陣列和鏈表結構,一個Segment里面包含一個HashEntry陣列,每個HashEntry是一個鏈表結構的元素,每個Segment守護著一個HashEntry陣列里面的元素,當對HashEntry陣列的資料結構進行修改時,必須首先獲得與它對應的Segment鎖,如圖:
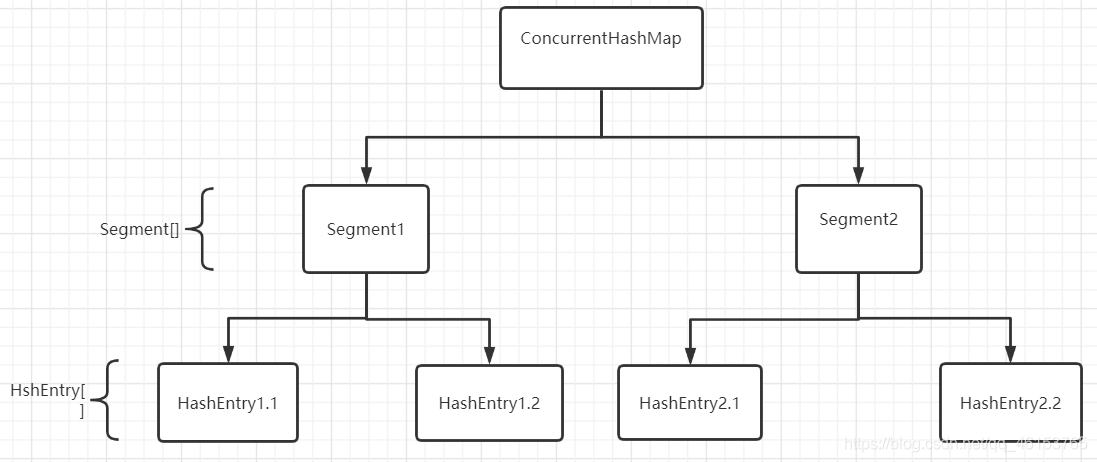
定位Segment
-
ConcurrentHashMap使用Wang/Jenkins hash的變種演算法對元素的hashCode進行一次再散列:
private static int hash(int h) { h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); }- 進行再散列的目的是減少散列沖突,是元素能夠均勻分布在不同的Segment上,從而提高容器的存取效率
ConcurrentHashMap的操作
- 三種操作:get操作、put操作和size操作
get操作
-
Segment的get操作實作非常簡單高效,先經過一個再散列,然后使用這個散列值通過散列運算定位到Segment,再通過散列演算法定位到元素
public V get(Object key) { int hash = hash(key.hashCode()); return segmentFor(hash).get(key, hash); } -
ConcurrentHashMap的get操作相比于HashTable容器的get方法不需要加鎖,除非讀到的值是空才會加鎖重讀,它是如何做到的呢? 原因是它的get方法里將要使用的共享變數都定義成volatile型別,如用于統計當前Segement大小的count欄位和用于儲存值的HashEntry的value,定義成volatile的變數,能夠在執行緒之間保持可見性,保證多個執行緒讀到的是最新的值,但是只能被單執行緒寫(有一種情況可以被多執行緒寫,就是寫入的值不依賴與原值),根據Java記憶體模型的happen before原則,對volatile欄位的寫入操作先于讀操作,即使兩個執行緒同時修改和獲取volatile變數,get操作也能拿到最新的值
transient volatile int count; volatile V value;
put操作
- 由于put方法里需要對共享變數進行寫入操作,所以為了執行緒安全,在操作共享變數時必須加鎖,put方法首先定位到Segment,然后在Segment里面進行插入操作:
- 第一步:判斷是否需要對Segment里的HashEntry陣列進行擴容
- 第二步定位添加元素的位置,然后將其放在HashEntry陣列里
- HashEntry陣列擴容
- HashEntry在插入元素前會判斷Segment里的HashEntry陣列是否超過容量,如果超過容量,再進行擴容,而HashMap是在插入元素之后判斷容量是否已經到達閾值,如果到達了閾值就進行擴容,但是很可能擴容之后沒有新元素插入,這將會是一次無效的擴容
- 首先會創建一個容量是原來容量兩倍的陣列,然后將原陣列里的元素進行再散列后插入到新的陣列里,為了高效,ConcurrentHashMap不會對整個容器進行擴容,而只是對某個segment進行擴容
seze操作
- 是不是把所有Segment的count相加就可以得到整個ConcurrentHashMap的大小呢?不是的,理由:雖然在相加時可以獲取每個Segment的count的最新值,但是可能累加前使用的count發生了變化,導致統計結果不準確,那么是不是就可以對Segment的put、remove、clean方法加鎖就行了呢?其實也不是,這種做法非常低效,于是ConcurrentHashMap采用了下面的做法:ConcurrentHashMap先嘗試2次通過不鎖住Segment的方式來統計各個Segment大小,如果統計程序中,容器的count發生了變化,則再采用加鎖的方式來統計所有Segment的大小
- 如何判斷在統計的時候容器是否發生了變化:使用modCount變數,在put、remove和clean方法操作元素前將modCount+1,在統計后比較modCount是否發生變化,發生變化,則可以判斷容器發生了變化,反之,
參考:《Java并發編程的藝術》僅供個人學習,不可用于商業用途,如有侵權,立刪
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240960.html
標籤:其他
下一篇:hashMap底層原始碼淺析