文章目錄
- Hadoop集群配置
- 前置準備
- 網路配置
- 修改主機名(主機和從機都要操作)
- 將虛擬機改為靜態IP(主機和從機都要操作)
- 修改losts
- 配置SSH無密碼登陸節點
- 安裝及啟動SSH服務(主機和從機都要操作)
- 生成SSH公鑰
- 傳輸公鑰(程序中需要輸入從機的密碼)
- 把公鑰加入授權(在從機操作)
- 配置分布式集群環境
- 修改組態檔
- 修改slaves:
- 修改core-site.xml:
- 修改hdfs-site.xml:
- 修改mapred-site.xml:
- 修改yarn-site.xml:
- 將主機的/usr/local/hadoop檔案夾傳輸到從機:
- 在主機執行:
- 在從機執行:
- 啟動Hadoop
- 附錄
- 從機沒有DataNode行程解決方案
- 原因
- 解決方法
- WARNING: An illegal……原因
Hadoop集群配置
本檔案演示采用Ubuntu 18.04系統,下載地址:http://mirrors.aliyun.com/ubuntu-releases/18.04
桌面虛擬計算機軟體采用VMware workstation 15.5.0
參考:https://www.cnblogs.com/guangluwutu/p/9705136.html
Java和Hadoop安裝及環境變數配置請參考其他教程 (注意jdk及Hadoop版本不同導致的安裝目錄不同的問題),請完成后再進行Hadoop集群配置,
如無特別說明,則該操作是在主機上完成
前置準備
可選:拍攝快照,如配置失敗可方便回滾
更新apt:
sudo apt-get update
安裝net-tools:
sudo apt install net-tools
完整克隆若干份已經安裝配置好java和Hadoop的虛擬機作為從機
網路配置
修改主機名(主機和從機都要操作)
sudo gedit /etc/hostname
洗掉原本的主機名
將主機的主機名修改為master或其他
將從機1的主機名修改為slave1或其他
以此類推
例:
master
保存后重啟
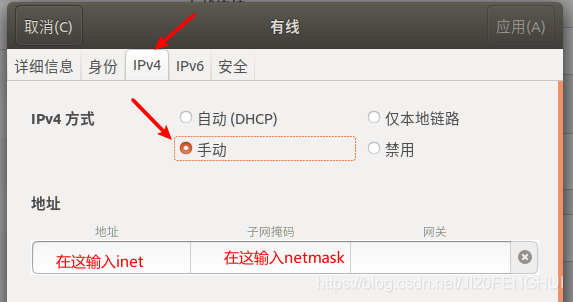
將虛擬機改為靜態IP(主機和從機都要操作)
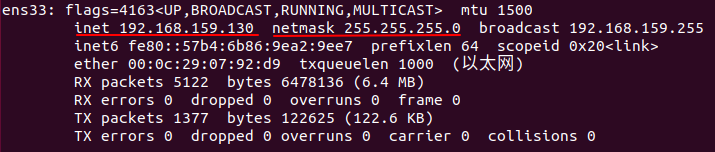
ifconfig
記錄下inet和netmask
依次點擊
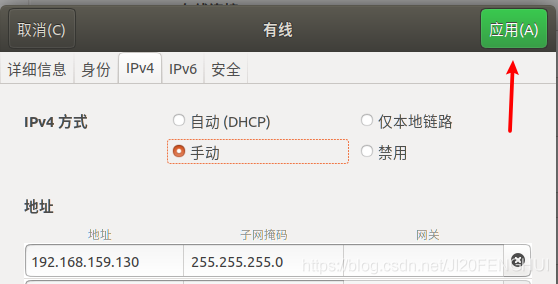
修改losts
sudo gedit /etc/hosts
在末尾添加:
主機inet 主機主機名
從機1inet 從機1主機名
……
例:
192.168.159.130 master
192.168.159.131 salve1
配置SSH無密碼登陸節點
安裝及啟動SSH服務(主機和從機都要操作)
安裝服務(一路回車即可):
sudo apt-get install openssh-server
啟動服務:
sudo /etc/init.d/ssh restart
關閉防火墻:
sudo ufw disable
執行以下命令看是否成功運行:
ps -e | grep ssh
如果成功會出現如下倆個行程:

生成SSH公鑰
cd ~/.ssh # 如果沒有該目錄,先執行一次ssh localhost
rm ./id_rsa* # 洗掉之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回車就可以
讓 master 節點可以無密碼 SSH 本機:
cat ./id_rsa.pub >> ./authorized_keys
驗證:
ssh 主機主機名
如成功會出現如下字符:
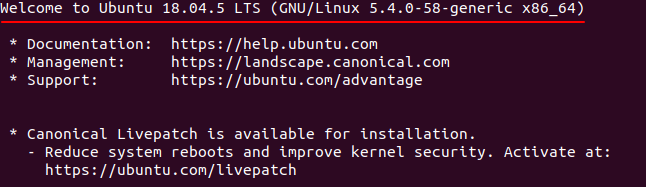
退出:
exit
傳輸公鑰(程序中需要輸入從機的密碼)
scp ~/.ssh/id_rsa.pub 從機用戶名@從機主機名:/home/從機用戶名/
例:
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/
把公鑰加入授權(在從機操作)
mkdir ~/.ssh # 如果不存在該檔案夾需先創建,若已存在則忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub
驗證:
ssh 從機主機名
如成功會出現如下字符:
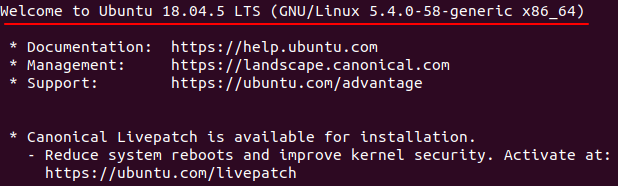
退出:
exit
配置分布式集群環境
修改組態檔
修改slaves:
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/slaves
此檔案記錄的是將要作為 Datanode 節點的名字,將從機主機名寫入,如果想讓主機同時作為 Datanode 節點則保留localhost,
從機1主機名
從機2主機名
……
例:
slave1
修改core-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/core-site.xml
覆寫<configuration>標簽:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
修改hdfs-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
dfs.replication為從機數量,請根據實際更改
覆寫<configuration>標簽:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改mapred-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/mapred-site.xml
可能默認檔案名為 mapred-site.xml.template ,此時需要重命名:
mv mapred-site.xml.template mapred-site.xml
覆寫<configuration>標簽:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
修改yarn-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/yarn-site.xml
覆寫<configuration>標簽:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
將主機的/usr/local/hadoop檔案夾傳輸到從機:
在主機執行:
cd /usr/local
sudo rm -r ./hadoop/tmp # 洗掉 Hadoop 臨時檔案
sudo rm -r ./hadoop//hadoop-2.9.2/logs/* # 洗掉日志檔案
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再復制
cd ~ #跳轉到有壓縮包的路徑下
scp ./hadoop.master.tar.gz 從機主機名:/home/從機用戶名
例:
scp ./hadoop.master.tar.gz slave1:/home/hadoop
在從機執行:
sudo rm -r /usr/local/hadoop
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R 從機用戶名 /usr/local/hadoop
例:
sudo chown -R hadoop /usr/local/hadoop
啟動Hadoop
首次啟動需要格式化:
hdfs namenode -format
啟動:
start-all.sh
mr-jobhistory-daemon.sh start historyserver
驗證(主機和從機都要操作):
jps
如成功,NameNode節點應有NameNode、ResourceManager、SecondrryNameNode、JobHistoryServe 4個行程,DataNode節點應有DataNode、 NodeManager 2個行程,缺一不可,
主機:
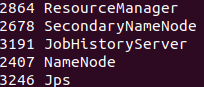
從機:
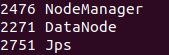
檢查DataNode節點數量:
hdfs dfsadmin -report
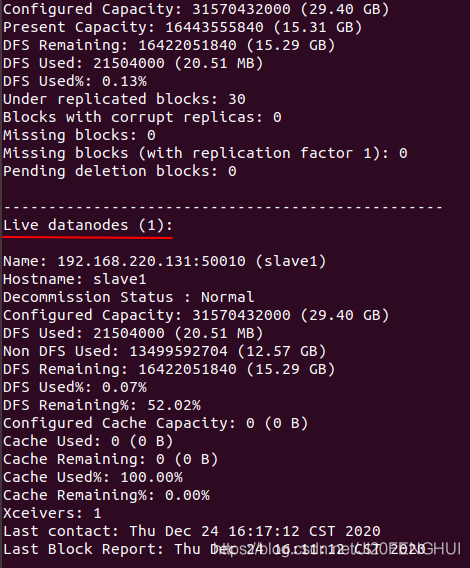
若成功,則Live datanode數量與實際數量相等,
附錄
從機沒有DataNode行程解決方案
原因
主機和從機的clusterID不一致
解決方法
將主機和從機的/usr/local/hadoop/tmp檔案夾和/usr/local/hadoop/hadoop-2.9.2/logs檔案夾洗掉,主機再次格式化即可解決問題
WARNING: An illegal……原因
JDK版本過新導致,可以不用理會
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240973.html
標籤:其他
上一篇:阿里P82個月整合最全PDF:Tomcat+虛擬機+Spring全家桶+MyBatis原始碼等
下一篇:CKA-題庫-簡潔參考答案