目錄
- 1、概述
- 2、名詞解釋
- 3、亂數存在的安全風險
- 3.1 弱偽亂數帶來的安全風險
- 3.2 真亂數真的安全嗎
- 4、亂數
- 4.1 什么情況下才使用亂數
- 4.2 偽亂數
- 4.2.1 弱偽亂數
- 4.2.2 強偽亂數
- 4.3 真亂數
- 4.4 安全亂數
- 5、拓展場景
- 5.1* 密文密碼中的鹽值(拓展)
- 5.2* UUID的生成(拓展)
- 5.3* 驗證碼的生成(拓展)
- 【參考資料】
1、概述
本篇文章將對安全的亂數與真/偽亂數進行介紹,想必大家在編碼程序中,很少注意使用真亂數或者安全的亂數去生產亂數,那么為什么要用安全的亂數呢?(廢話,因為安全啊!!!)本篇文章將帶你探索未知的亂數領域,
(想直接了解本文結論的同學,請直接跳轉 【4.4安全亂數】 的章節)
2、名詞解釋
- 偽亂數:通過數學演算法+種子生成的亂數,存在一定的規律,并非真的亂數
- 弱偽亂數:偽亂數中的一種,易于預測的亂數
- 強偽亂數:偽亂數中的一種,難以預測的亂數
- 真亂數:通過物理系統生成的亂數,例如電壓波動、磁盤磁頭讀/寫時的尋道空間,電磁波噪聲、擲硬幣等
- 安全的亂數:具有一定強壯的亂數演算法生成的亂數,包括真亂數和強偽亂數
- 鹽值:通常在用戶注冊時,用來和用戶輸入的密碼進行組合的亂數
- 散列函式(散列化):就是我們通常說的Hash(哈希),把輸入的資訊通過一定的散列演算法生成了一種散列值的程序就是散列化,散列函式就提供了散列演算法,例如SHA
- RSA:一種非對稱加密演算法
- UUID:通用唯一識別碼,128位
- DCE:分布式計算環境
- SHA1:安全散列演算法
- 彩虹表:用于加密散列函式逆運算而進行預先計算的表,針對于破解密碼的散列值而出現的
3、亂數存在的安全風險
3.1 弱偽亂數帶來的安全風險
剛當上程式員的小新人,遇到亂數的使用場景,一般都會呼叫Random這樣的函式,通過srand(time())這樣的形式給rand函式添加隨機種子,產生亂數(有的亂數發生器默認就是用時間作為隨機種子,例如JAVA的java.util.Random),這樣的亂數只適合用于游戲、抽獎等場景,而不適用于加密、密鑰生成等重要操作場景
舉個例子:通過郵箱重置密碼的操作是很常見的,但是如果進行了不安全的設計和編碼,則容易引發安全風險,例如重置密碼時,用戶ID和當前的時間戳系結,而該時間戳作為種子用于加密密碼,
URI:https://www.xxx.com/password/find
Method:PUT
Param:[email protected]
seed=5512AADBF06182F1FEC988114385557E
將【seed】欄位解密后,時一個時間戳:1607993226,因為一般系統時間跟著標準時間同步,所以時間戳時可預測的,當匹配到了該時間戳,那么就成了一個攻擊者的突破口
3.2 真亂數真的安全嗎
計算機安全領域沒有絕對的安全,只有相對的安全(除非你不編碼,不想當個程式猿)
相對比于其他亂數,真亂數的產生條件較為苛刻,通過獲取物理條件產生,電壓波動、磁盤讀寫的尋道空間等,難以被利用,當然,存在著撞庫的風險,概率極低,破解的成本巨大,如果你使用了真亂數,仍然有攻擊者想修改你的密碼,獲取資訊,那就恭喜你了,說明在攻擊者眼里,你可是個富翁(沒有利益驅動,攻擊者將對你毫無興趣)
4、亂數
4.1 什么情況下才使用亂數
這時候你心中定有疑惑,亂數能干嘛?(一般來自新手的疑問,老司機還有這個疑惑那就unbelievable)
亂數常常與密碼演算法、ID、區塊鏈聯系在一起,再具體一點例如福利彩票、門禁藍牙隨機密碼、抽獎
舉幾個例子:
密碼學上使用的鹽值、密鑰等使用隨機的條件,加強密碼保存或傳輸的安全性;
UUID使用隨機的方法保障ID唯一性,并可以在UUID的基礎上,復用UUID拓展更多的功能,例如截取部分UUID作為虛擬機ID、使用UUID生成具有唯一性的存盤ID和用戶ID;
區塊鏈中使用私鑰加密貨幣,私鑰的產生用的就是亂數;POS隨機記賬人場景(為了公平的分配記賬券)
亂數的使用生活中處處可見,進行高危操作,例如加密場景,要使用安全的亂數
4.2 偽亂數
Q1:為什么會有“偽亂數”這個名詞?
A1:亂數中的“隨機”體現出不可預測性,沒有規律可言,而人為的,通過一定演算法生成的亂數,存在一定規律性,并不真正隨機,所以稱為“偽亂數”
Q2:偽亂數的由來
A2:起源于20世紀早期科學作業,研究人員通過物理方法采集亂數,但是通過物理方法采集的“真亂數”十分低效,實時獲取亂數的速度緩慢,保存亂數額外占用存盤空間等缺點,便開始尋求“偽亂數”的方法,來解決效率等問題
Q3:偽亂數目前分為幾類?
A3:偽亂數根據預測性的難易程度,分為弱偽亂數(易預測)和強偽亂數(難預測),
4.2.1 弱偽亂數
Q1:什么是弱偽亂數?
A1:顧名思義,這種的型別的亂數只是為了滿足隨機性,但是可以預測,舉個例子,Java編程語言Random函式,就是基于時間作為種子,去構造亂數,假如攻擊者獲取了該時間,那么就可以預測下一個亂數的結果,
Q2:常見的弱偽亂數有哪些?
A2:以下是容易產生弱偽亂數的函式,取決于隨機“種子”、隨機范圍、亂數的物件的選擇
| 編程語言 | 弱偽亂數 | 備注 |
|---|---|---|
| C/C++ | srand( time() ) + rand() | 以時間為種子,產生亂數 |
| C# | Random() System.Guid() |
|
| Perl | srand( time() ) + rand() | 以時間為種子,產生亂數 |
| Python | import numpy rng = numpy.random.RandomState( time() ) array_rand_num = rng.uniform() --------------------------- import random random.seed() |
|
| Ruby | srand( time() ) + rand() | 以時間為種子,產生亂數 |
| JAVA | Random |
|
| PHP | srand() + rand() mtstrand() + mtrand() |
安全建議:涉及到加密、CSRF Token等重要操作時
- 不要使用時間函式作為種子或者亂數:time()/microtime()
- 不要使用rand這樣的弱偽亂數生成器
- 亂數的長度要足夠長
4.2.2 強偽亂數
Q1:什么是強偽亂數?
A1:指難以預測的偽亂數,通常用于密碼學中,例如JAVA中的java.security.SecureRandom函式,其用于隨機的種子是不可預測的,比如滑鼠點擊、鍵盤點擊等物理條件
4.3 真亂數
Q1:Linux上可靠的真亂數生成方法有哪些?
A1:比較可靠的方法是讀取/dev/random或者讀取/dev/urandom(在一定程度上,/dev/urandom是強偽亂數),
Q2:/dev/random和/dev/urandom有什么區別?
A2:
- 首先,Linux環境下是根據系統的熵值來產生亂數,熵的來源是環境噪音,噪音的來源是鍵盤輸入、滑鼠移動、記憶體的使用、行程數等,
- 其次,/dev/random是真亂數生成器,通過消耗熵值來產生亂數、同時熵耗盡的情況下會造成阻塞,直到有心的熵的生成,而/dev/urandom是強偽亂數生成器,它根據初始的隨機種子(熵),來產生亂數,但是不會消耗掉熵,不會再熵消耗完的情況下阻塞,
- 這時候就有個問題了,如果系統啟動階段使用了/dev/urandom,而這時沒有任何的熵,那么這時候使用的是內置的種子,產生亂數還是存在可預測性的
- 最后,仍然建議使用 /dev/urandom,在計算機安全領域,沒有絕對的安全,只有相對的安全(除非你不編碼、不開發、不做禿頂的程式猿)
4.4 安全亂數
亂數涉及到加密等重要操作場景,推薦使用以下安全亂數
| 編程語言 | 安全亂數 | 備注 |
|---|---|---|
| C/C++ | CryptGenRandom(Windows) | 原理:依據當前行程ID、當前執行緒ID、當前時間、用戶名、計算機名、CPU計數器等,生成亂數,和/dev/random一樣,效率低,消耗資源大 |
| .NET(C#) | System.Security.Cryptography.RNGCryptoServiceProvider | 原理:和CryptGenRandom(Windows)類似 |
| Perl | Math::Random::Secure | 原理:所使用的種子種類繁多,且是隨機使用的,攻擊者可能要費勁10多年才能遍歷完成 |
| Python | os.urandomrandom.SystemRandom() | 原理:函式回傳的隨機位元組,是作業系統所帶的隨機函式產生,具有特異性這里"urandom"里"u"應該指的是"unexpected"--難以預料 |
| Ruby | Sysrandom(取代SecureRandom) | 適用于生成session token原理:使用/dev/urandom |
| JAVA | java.security.SecureRandom | 原理:提供加密強度高的亂數生成器,默認條件下(不傳其他種子的話,默認種子來源是/dev/random,但是存在熵耗盡導致阻塞的現象),就可以產生安全的亂數;解決熵值耗盡的方法要不就是不斷增加熵值,要不就種子來源換成/dev/urandom |
| PHP | mcrypt_create_iv, openssl_random_pseudo_bytes,random_bytes,random_int | 原理:random_bytes/random_int -- 不同系統上,源頭不同,Windows上使用CryptGenRandom,Linux上使用getrandom(2)或/dev/urandom |
| GNU/Linux或Unix | 讀取/dev/random or /dev/urandom | 4.3講的很清楚了 |
5、拓展場景
5.1* 密文密碼中的鹽值(拓展)
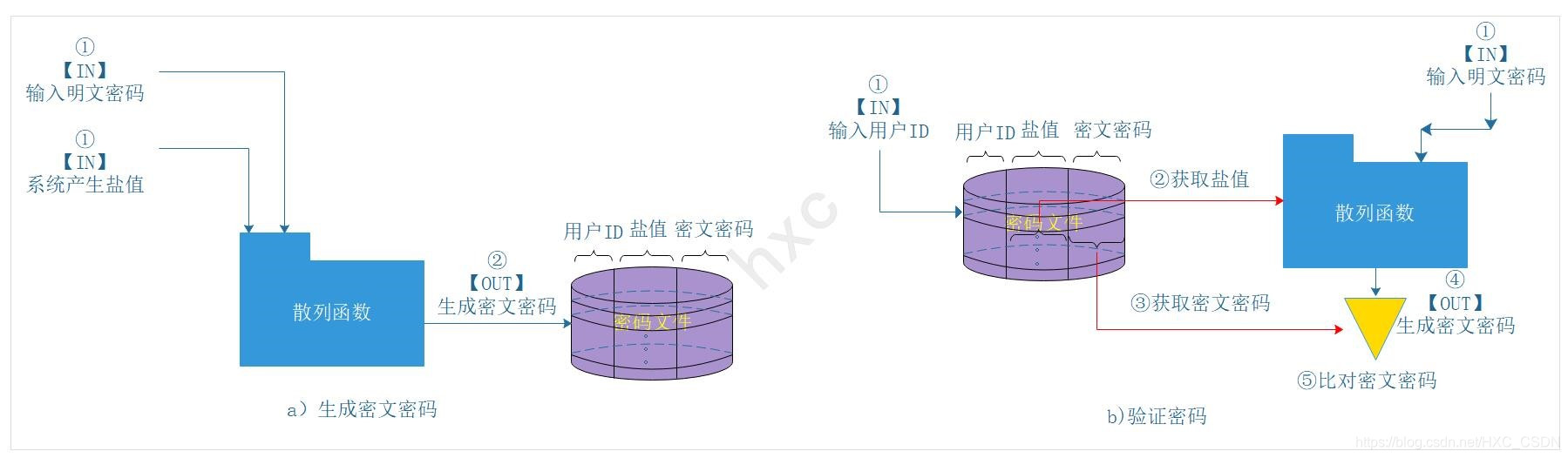
上圖是Linux常用的密碼生成與密碼驗證的原理圖,
- a)生成密文密碼:輸入明文密碼+系統產生的鹽值 =>(散列化) 密文密碼
- b)驗證密碼:輸入明文密碼+用戶ID +存盤的鹽值 =>(散列化)密文密碼,生成的密文密碼與存盤的密文密碼比對
很明顯,加入鹽值的目的如下:
- 1、防止使用的密碼存盤時以明文形式存盤,即使兩個不同的用戶使用相同的明文密碼,但是使用了不同的鹽值之后,最后的密文密碼便是不同的,
- 2、顯著增加密碼破解的難度,例如一個長度為128位的鹽值,可能產生的密文密碼數量會是2的128次方個,加大密碼猜測的難度,
- 3、讓攻擊者難以發現同一個用戶在不同的作業系統上使用相同的密碼
安全建議如下:
- 存盤密碼時要以密文密碼存盤,而不是使用明文密碼存盤
- 如果只時為了校驗密碼的目的而去使用密碼(無論是校驗自身平臺還是第三方平臺),那么使用密碼+鹽值再進行散列化后的結果形式進行存盤,這樣比較安全(因為散列化不可逆),進而進行比較時用的時密文密碼比較,而非明文密碼比較,減少了解密時候帶來的安全風險
- 如果存盤的密碼是為了解密后使用,那么通常的安全建議做法是,對密碼進行非對稱加密存盤,私鑰要進行分段加密存盤
- 使用的鹽值長度建議為128位,極大提高攻擊難度
5.2* UUID的生成(拓展)
UUID是如何保持唯一性的呢?這里將講述UUID經歷的5個版本,
| UUID Version1:基于時間的UUID |
| UUID Version2:DCE安全的UUID |
| UUID Version3:基于名字的UUID(MD5) |
| UUID Version4:隨機UUID |
| UUID Version5:基于名字的UUID(SHA1) |
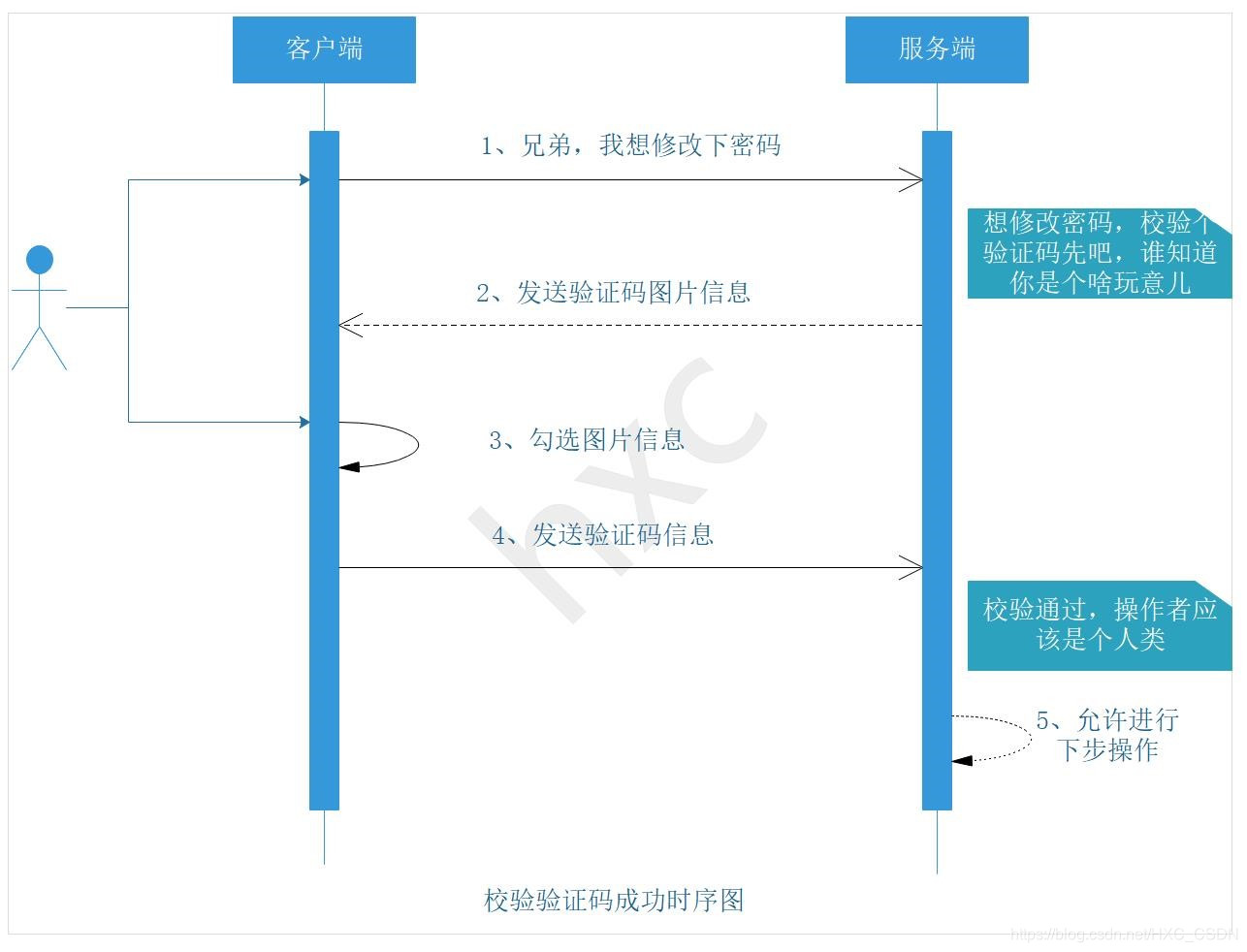
5.3* 驗證碼的生成(拓展)
驗證碼的目的,是為了區分操作者是計算機還是正常的人類,防止計算機暴力破解(計算機很笨,只會按照程式猿設定的方式進行,無法對自動生成的問題進行解答)
驗證碼形式:數字校驗、圖片校驗、拼圖校驗、語音校驗,這些校驗大同小異,無非是對資料進行校驗
舉個例子:
-
不安全的驗證碼傳輸:
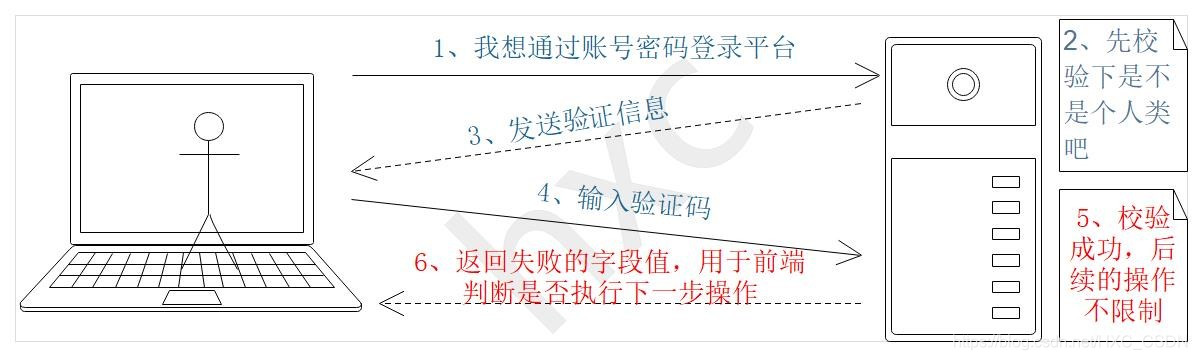
為什么說它不安全呢?上圖是將驗證碼后續的操作判斷交給了前端,由前端去控制下一步操作,這樣做有什么風險呢?
舉個例子:保存重要配置操作(驗證碼的目的就是用于校驗某次操作的安全性),在點擊保存配置的按鈕后,前端彈出驗證碼輸入框,用戶輸入完驗證碼后,點擊確定,這時候交給服務器識別驗證碼的正確性,然后回傳flag=0或flag=1告知前端驗證碼校驗失敗或成功,由前端去決定是否呼叫這次保存配置的API,如果在第6步流程,當驗證失敗,flag=0,回傳的回應資訊被截取,將flag修改成1(資料偽造,驗證成功),那么這次保存配置的操作將會成功,
安全建議:不要把一切操作都交給前端,特別時敏感操作;建議同步傳輸,在確認下發API的同時帶上驗證碼資料,由服務器統一處理,
【參考資料】
1、博客:《聊一聊亂數安全》:https://blog.csdn.net/renwotao2009/article/details/51643799
2、博客:《C#生成亂數的三種方法》:https://www.cnblogs.com/xiaowie/p/8759837.html
3、書籍:《白帽子講Web安全》
4、書籍:《計算機安全原理與實踐》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241245.html
標籤:其他
上一篇:檔案包含漏洞學習筆記