2.1 數學基礎
演算法分析需要一套正式的系統架構,我們先從一些數學定義和法則開始:
這些定義的目的是要在函式間建立一種相對的級別
定義1:如果存在正常數c和n0,使得當N≥n0時 T \boldsymbol{T} T(N) ? \leqslant ?c f \boldsymbol{f} f(N),則記為 T \boldsymbol{T} T(N)=O( f \boldsymbol{f} f(N))
定義2:如果存在正常數c和n0,使得當N≥n0時 T \boldsymbol{T} T(N) ? \geqslant ?c g \boldsymbol{g} g(N),則記為 T \boldsymbol{T} T(N)= Ω \Omega Ω( g \boldsymbol{g} g(N))
定義3: T \boldsymbol{T} T(N)= Θ \Theta Θ( h \boldsymbol{h} h(N)),當且僅當 T \boldsymbol{T} T(N)=O( h \boldsymbol{h} h(N))和 T \boldsymbol{T} T(N)= Ω \Omega Ω( h \boldsymbol{h} h(N))
定義4:如果對所有的常數c存在n0使得當N>n0時 T \boldsymbol{T} T(N)<c p \boldsymbol{p} p(N),則記為 T \boldsymbol{T} T(N)=o( p \boldsymbol{p} p(N)),非正式的定義為:如果 T \boldsymbol{T} T(N)=O( p \boldsymbol{p} p(N))且 T \boldsymbol{T} T(N) ≠ \neq ?= Θ \Theta Θ( p \boldsymbol{p} p(N)),則 T \boldsymbol{T} T(N)=o( p \boldsymbol{p} p(N))
法則1:如果 T 1 \boldsymbol{T_{1}} T1?(N)=O( f \boldsymbol{f} f(N))且 T 2 \boldsymbol{T_{2}} T2?(N)=O( g \boldsymbol{g} g(N)),那么
(a) T 1 \boldsymbol{T_{1}} T1?(N)+ T 2 \boldsymbol{T_{2}} T2?(N)=O( f \boldsymbol{f} f(N)+ g \boldsymbol{g} g(N)) \quad\quad (直觀非正式表達為max(O( f \boldsymbol{f} f(N),O( g \boldsymbol{g} g(N)))
(b) T 1 \boldsymbol{T_{1}} T1?(N) T 2 \boldsymbol{T_{2}} T2?(N)=O( f \boldsymbol{f} f(N) g \boldsymbol{g} g(N))
法則2:如果 T \boldsymbol{T} T(N)是一個k次多項式,則 T \boldsymbol{T} T(N)= Θ \Theta Θ(Nk)
法則3:對任意常數,logkN=O(N)
下表為比較后的函式增長率:
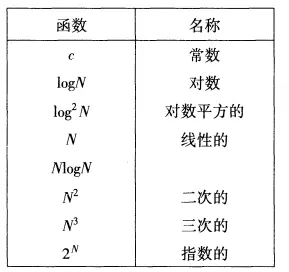
注意:
1、將常數項和低階項放進大O是不好的習慣,低階項一般可以被忽略,常數可以丟棄
2、可以通過計算極限
lim
?
N
→
∞
\lim_{N\to\infty }
limN→∞?
f
\boldsymbol{f}
f(N)/
g
\boldsymbol{g}
g(N)來確定兩個函式相對增長率,必要的時候可以使用洛必達法則,該極限有四種可能的值:
- 極限為0:意味著 f \boldsymbol{f} f(N)=o( g \boldsymbol{g} g(N))
- 極限為c ≠ \neq ?= 0,意味著 f \boldsymbol{f} f(N)= Θ \Theta Θ( g \boldsymbol{g} g(N))
- 極限為 ∞ \infty ∞,意味著 g \boldsymbol{g} g(N)=o( f \boldsymbol{f} f(N))
- 極限擺動
2.2 模型
為了便于分析問題,我們假設一個模型計算機,它執行任何一個基礎指令都消耗一個時間單元,并且假設它有無限的記憶體,
2.3 要分析的問題
演算法要分析的最重要資源就是運行時間,我們這里考慮的影響運行時間的因素主要是所使用的演算法和演算法的輸入,演算法對于輸入N所花費的時間一般定義為平均情形和最壞情形的運行時間,平均情形常常反應典型的結果,最壞情形則代表對任何可能的輸入在性能上的一種保證,若無特別說明,我們所需要的量是最壞情況下的運行時間(提供界限并且計算相對容易),
2.4 運行時間計算
2.4.1 一般法則
為了簡化分析,約定:不存在特定的時間單位,所要做的就是計算大O運行時間
for回圈: 一個for回圈運行時間至多是該回圈內陳述句的運行時間乘以迭代次數
嵌套回圈:從里向外分析這些回圈,
順序陳述句:將各個陳述句的運行時間求和即可,可用法則1的(a)
If/Else陳述句:不超過判斷再加上不同條件下運行時間較長者的總運行時間
2.4.2 例子
// 書上例程
// 計算i^3的累加求和
int sum (int N)
{
int i, PartialSum;
PartialSum = 0; /*1*/
for(i = 1; i <= N; i++) /*2*/
PartialSum += i * i * i;/*3*/
return PartialSum; /*4*/
}
這里針對每行進行分析:
- 花費1個時間單元:1個賦值
- 花費1+N+1+N=2N+2個時間單元:1個賦值、N+1次判斷、N次加法
- 花費N(2+1+1)=4N個時間單元:2個乘法、1個加法、1個賦值,執行N次
- 花費1個時間單元:1個回傳
合計花費1+2N+2+4N+1=6N+4個時間單元,
但是實際上我們不用每次都這樣分析,因為面對成百上千行的程式時,我們不可能每一行都這樣分析,只需計算最高階,能夠看出for回圈占用時間最多,因此時間復雜度為O(N)
2.4.3 最大子序列和問題的解
最大子序列和問題:給定整數A1,A2,…,AN(可能有負數),求
∑
k
=
1
j
\sum_{k=1}^{j}
∑k=1j?Ak的最大值(為方便起見,當所有整數均為負數時,則最大子序列和為0)
例如,-2,11,-4,13,-5,-2,答案為20(從A2到A4)
演算法1:三個for回圈,窮舉式地嘗試所有可能
O(N3)
int maxsubsum1(const vector<int> &a)
{
int maxsum = 0;
for(int i = 0;i < a.size(); i++) //定義子序列起點
{
for (int j = i; j < a.size(); j++) //定義子序列終點
{
int thissum = 0;
for (int k = i; k <= j; k++) //子序列元素依次相加
thissum += a[k];
if (maxsum < thissum)
maxsum = thissum;
}
}
return maxsum;
}
演算法2:與演算法1相比,根據
∑
k
=
i
j
\sum_{k=i}^{j}
∑k=ij?Ak=Aj+
∑
k
=
i
j
?
1
\sum_{k=i}^{j-1}
∑k=ij?1?Ak,可以去除了k的回圈
O(N2)
int maxsubsum(const vector<int>& a)
{
int maxsum = 0;
for (int i = 0; i < a.size(); i++)
{
int thissum = 0;
for (int j = i; j < a.size(); j++)
{
thissum += a[j]; //可以使用之前得到的結果,避免二次計算
if (maxsum < thissum)
maxsum = thissum;
}
}
return maxsum;
}
演算法3:使用分治策略,‘分’為將資料分為左右兩部分,即將問題分成兩個大致相等的子問題,然后遞回的將他們求解;‘治’為將兩個子問題的解合并到一起,并可能再做少量的附加作業,最后得到整個問題的解,這個問題中,最大子序列和可能出現三種情況:左半部分,右半部分,跨越左半部分和右半部分,第三種情況的最大子序列和為包含左半部分最后一個元素的最大子序列和加上包含右半部分第一個元素的最大子序列和的總和,
大致計算時間復雜度:定義T(1)為單位時間長度
T(1)=1
T(N)=2
×
\times
×T(N/2)+N
\quad
T(N/2)=2
×
\times
×T(N/4)+N/2
→
\quad\rightarrow\quad
→T(N)=4
×
\times
×T(N/4)+2N
依次類推,T(N)=常數+N
×
\times
×logN,便知T(N)=O(NlogN)
O(NlogN)
int maxsumr(const vector<int>& a, int left, int right) //遞回函式
{
if (left == right) //基準情形
if (a[left] < 0)
return 0;
else
return a[left];
int center = (left + right) / 2;
int maxleftsum = maxsumr(a, left, center); //遞回左半部分
int maxrightsum = maxsumr(a, center + 1, right); //遞回右半部分
//兩個for回圈分別計算跨越左半部分和右半部分
int maxleftbordersum = 0, leftbordersum = 0;
for (int i = center; i >= left; i--)
{
leftbordersum += a[i];
if (leftbordersum > maxleftbordersum)
maxleftbordersum = leftbordersum;
}
int maxrightbordersum = 0, rightbordersum = 0;
for (int j = center+1; j <= right; j++)
{
rightbordersum += a[j];
if (rightbordersum > maxrightbordersum)
maxrightbordersum = rightbordersum;
}
return max3(maxleftsum, maxleftsum, maxleftbordersum + maxrightbordersum);
}
int maxsubsum(const vector<int>& a)
{
return maxsumr(a, 0, a.size()-1);
}
int max3(int a, int b, int c)
{
return (a > b ? a : b) > c ? (a > b ? a : b) : c;
}
演算法4:如果a[i]是負的,那么它不可能代表最有序列的起點;同理,任何負的子序列不可能是最優子序列的前綴,如果某一次回圈,檢測到 a[i] 到 a[j] 的子序列突然從非負變為負的,則我們不僅能把 i 推進到 i+1,實際上可以推進到 j+1,
附帶優點:此演算法只對資料進行一次掃描,一旦讀入并被處理,它就不需要被記憶,如果陣列存盤在磁盤上,它就可以被順序讀入,在主存中不必存盤陣列的任何部分,而且任意時刻,演算法能對它已經讀入的資料給出子序列問題的正確答案,具有這種特性的演算法也叫做聯機演算法(在線演算法),僅需要常量空間并以線性時間運行的在線演算法幾乎是完美的演算法
O(N)
int maxsubsum(const vector<int> &a)
{
int maxsum = 0, thissum = 0;
for (int j = 0; j <= a.size() - 1; j++)
{
thissum += a[j];
if (thissum < 0) //子序列小于0,便拋棄前面序列,直接置0
thissum = 0;
else if (thissum > maxsum)
maxsum = thissum;
}
return maxsum;
}
2.4.4 運行時間中的對數
對數中最常出現的規律一般可概括為以下一般法則:
1、如果一個演算法用常數時間(O(1))將問題的大小消減為其一部分(通常是1/2),那么該演算法就是O(logN),
2、如果使用常數時間只是把問題減少一個常數(如將問題減少1),那么這種演算法就是O(N)的,
二分搜索
問題:給定一個整數X和整數A0,A1,…,AN-1,后者已經預先排序并在記憶體中,求下標 i 使得Ai=X,如果X不在資料中,回傳 i=-1.
解法:比較X與居中元素,X小,則將相同策略應用到左邊排好序的子序列,X大時同理
O(logN)
int binarysearch(const vector<int>& a, const int& x)
{
int left = 0, right = a.size() - 1;
while (left <= right) //left等于right時,可能剛好在這個點上,也需要進行回圈判斷下
{
int center = (left + right) / 2;
if (x > a[center])
left = center + 1; //由if的判斷條件可知,center可以加 1
else if (x < a[center])
right = center - 1;
else
return center;
}
return -1;
}
歐幾里得演算法
問題:計算最大公因數
解法:歐幾里得演算法,通過連續計算余數直到余數為0為止,最后的非零余數就是最大公因數,
定理:如果M>N,則M mod N < N/2,
\quad\quad
可根據定理計算O()
O(logN)
long gcd(long m, long n)
{
while(n != 0)
{
long rem = m % n;
m = n;
n = rem;
}
return m;
}
冪運算
問題:處理整數的冪
解法:可以用遞回,求解YN,N為偶數時YN =YN/2
×
\times
× YN/2,N為奇數時YN =YN/2
×
\times
× YN/2
×
\times
× Y
O(logN)
long pow(long x, int n)
{
if(n == 0)
return 1;
if(n == 1)
return x;
if(isEven(n))
return pow(x * x, n / 2);
else
return pow(x * x, n / 2) * x;
}
2.4.5 檢驗你的分析
- 實際編程,觀察運行時間結果與分析預測出的運行時間是否匹配,如果N擴大一倍時,線性程式的運行時間乘以系數2,二次程式的運行時間乘以系數4,O(logN)的運行時間知識多加一個常數,
- 對N的某個范圍(通常是2的倍數隔開)計算比值T(N)/f(N),其中T(N)是觀察到的運行時間,f(N)則是理論推匯出的運行時間,如果所算出的值收斂于一個正常數,則代表f(N)是運行時間的理想近似;如果收斂于0,則代表f(N)估計過大;如果結果發散,則代表f(N)估計過小,
參考:https://www.cnblogs.com/CrazyCatJack/p/12688582.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241325.html
標籤:其他