jdk1.8( jdk11代碼有所不同) 的Integer包裝類中提供了已經封裝好的進制轉換函式 toBinaryString(), toOctalString(), toHexString(),下面分析一下它們的原始碼,
//轉二進制
public static String toBinaryString(int i) {
return toUnsignedString0(i, 1);
}
//轉八進制
public static String toOctalString(int i) {
return toUnsignedString0(i, 3);
}
//轉十六進制
public static String toHexString(int i) {
return toUnsignedString0(i, 4);
}從以上原始碼可以看出,它們都呼叫了toUnsignedString0()這個函式,只是第二個引數shift的值不同.
1. toUnsignedString()
接下來我們看看 toUnsignedString()是怎么實作的.
private static String toUnsignedString0(int val, int shift) {
// assert shift > 0 && shift <=5 : "Illegal shift value";
// 第一步: 計算出用于表示二/八/十六進制的字符陣列的長度,并創建字符陣列.
int mag = Integer.SIZE - Integer.numberOfLeadingZeros(val);
int chars = Math.max(((mag + (shift - 1)) / shift), 1);
char[] buf = new char[chars];
//第二步 使用formatUnsignedInt方法填充字符陣列,得到所需進制表示的字串并回傳
formatUnsignedInt(val, shift, buf, 0, chars);
return new String(buf, true);
} 第一步中最關鍵的字符陣列長度的計算是通過numberOfLeadingZeros()方法計算int變數的計算機二進制表示的高位連續0位的數量,進而獲得最高非0位到最低位的長度,也就是需要表示的位數, 負數的最高位是1,例如整數18在計算機中的二進制存盤為0000,0000,0000,0000,0000,0000,0001,0010,那么需要表示的部分便是1,0010,前面的28位均為0,不用表示,而-18在計算機中的二進制存盤為 11111111111111111111111111101110, 都須要表示.
2. numberOfLeadingZeros()
這個函式一般給出的解決方案是通過判斷高位是否為0,然后移位重復判斷,記錄連續的0的個數,如下列代碼:
public static int numberOfLeadingZeros0(int i){
if(i == 0) {
return 32; // i為0,則32位全為0
}
int n = 0;
int mask = 0x80000000; // 即 1000 0000 0000 0000 0000 0000 0000 0000
int j = i & mask; //取出符號位,如符號位為 1,表示負數,則直接回傳n=0.
//從高位向低位搜索連續出現的0的個數
while(j == 0){
n++; // 計數0出現的次數
i <<= 1; // <<表示左移移位,不分正負數,低位補0
j = i & mask; // 取出左移后最高位的值,
}
return n;
}以上方法的平均時間復雜度是o(k),k為變數i的位數,如果i為int,k就是32,這種很基本的庫函式會經過很多次的呼叫,需要進一步的優化.
java原始碼中的寫法更加優秀:
//求從高位向低,連續出現的0的個數
public static int numberOfLeadingZeros(int i) {
if (i == 0)
return 32;
int n = 1;
// >>>表示無符號右移,也叫邏輯右移,即若該數為正,則高位補0,而若該數為負數,則右移后高位同樣補0
if (i >>> 16 == 0) { n += 16; i <<= 16; } // <<表示左移移,不分正負數,低位補0
if (i >>> 24 == 0) { n += 8; i <<= 8; }
if (i >>> 28 == 0) { n += 4; i <<= 4; }
if (i >>> 30 == 0) { n += 2; i <<= 2; }
n -= i >>> 31;
return n;
}
這個地方采用的是分治法. (可以想想二分搜索的程序)
意思就是通過劃分16,8,4,2等逐步縮小的四個區間進行判斷和移位,不管if的代碼塊是否執行,需要判斷的位的區間也在隨著代碼的推進而逐步縮減,它通過分層次的縮小需要求解的域的范圍,減少計算次數.
分析程序如下:
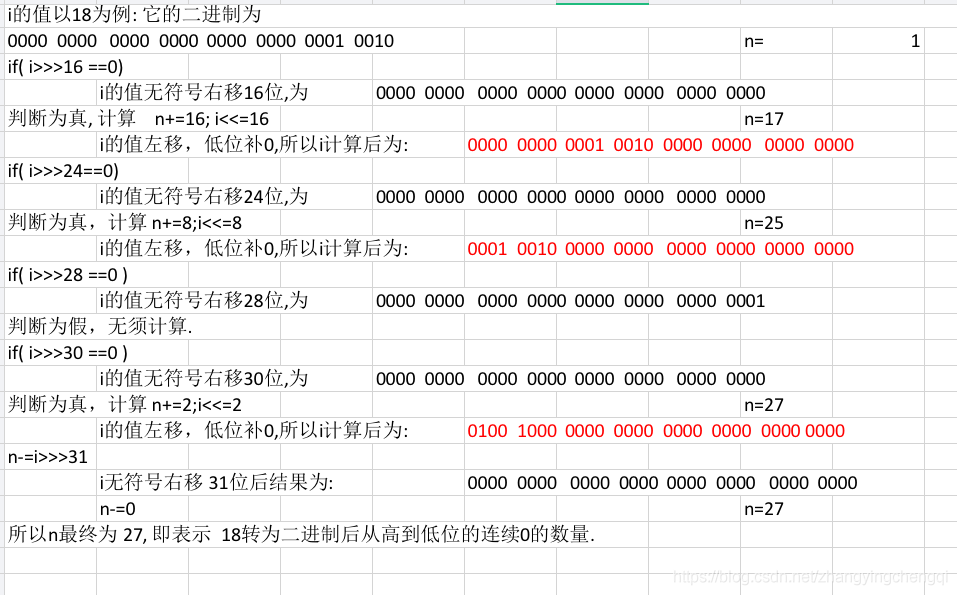
if( i>>>30==0 )判斷完后還有兩位,為什么最后 n-= i>>>31, 這里i 右移了31位,等于只留下了最高位,那么第二高位怎么沒有處理呢?
因為,在方法的開始已經判斷并回傳了變數為0即所有的位均為0的情況,所以能進行到后面的代碼部分,說明變數不為0,即必然存在至少一個位為1,而我們在選擇需要討論的位區間時,始終選擇的是包含位為1的區間進行討論,所以,在最后區間長度變為2時,區間中必然至少存在一位是1,而我們討論的是高位連續的0的個數,如果區間第一位為1,那么第二位自然不用討論,如果區間第一位是0,那么第二位必然是1,也不需要討論,所以這里只用討論第一位的情況
3. formatUnsignedInt()
經過上面的以數字18為例的計算后,我們可以得到18的二進制高位會出現連續的 27個0, 接下來我們回到toUnsignedString()函式看程式.
//以18為例
private static String toUnsignedString0(int val, int shift) {
int mag = Integer.SIZE - Integer.numberOfLeadingZeros(val); // mag=5
int chars = Math.max(((mag + (shift - 1)) / shift), 1); // chars=5
char[] buf = new char[chars];
formatUnsignedInt(val, shift, buf, 0, chars);
// Use special constructor which takes over "buf".
return new String(buf, true);
}它宣告了buf字符陣列,長度為 5. 接著呼叫 formatUnsignedInt( 18, 1, buf, 0, 5); 下面分析這個函式的原始碼:
// val=18 shift=1 offset=0 len=5
static int formatUnsignedInt(int val, int shift, char[] buf, int offset, int len) {
int charPos = len; // 5
int radix = 1 << shift; // 左移位,將運算元的二進制整體左移指定位數,低位用0補齊
//這樣二進制的radix為 10(對應10進制為2) 八進制為 1000 (對應10進制為8) 十六進制為 1 0000(對應10進制為16)
int mask = radix - 1;
// mask為掩碼
// 如要轉為二進制時mask為1 轉為八進制為7 轉為十六進制為15
// 用二進制表示分別為 1 111 1111
do {
buf[offset + --charPos] = Integer.digits[val & mask];
// val & mask 相當于一個%(mask+1)運算,它計算出 val對應 mask 這個進制的余數,這個數正好可以對應到 digits中的下標,, 接著通過 Integer.digits取出它的值. 存到 buf陣列對應位置
val >>>= shift; //再將 val 右移shift位,相當于 /(shift+1).
//以上對應的就是十進制轉n進制的 模n取余法的演算法實作了.
} while (val != 0 && charPos > 0);
return charPos;
}
以上呼叫了 Integer.digits 靜態陣列. 如下:
final static char[] digits = {
'0' , '1' , '2' , '3' , '4' , '5' ,
'6' , '7' , '8' , '9' , 'a' , 'b' ,
'c' , 'd' , 'e' , 'f' , 'g' , 'h' ,
'i' , 'j' , 'k' , 'l' , 'm' , 'n' ,
'o' , 'p' , 'q' , 'r' , 's' , 't' ,
'u' , 'v' , 'w' , 'x' , 'y' , 'z'
};
八進制和十六進制的原理一樣,大家可以自行分析.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241843.html
標籤:其他
上一篇:2020-12-28